CogVLM2多模态开源大模型部署与使用
项目简介
- CogVLM2 是由清华大学团队发布的新一代开源模型系列。
- 2024年5月24日,发布了Int4版本模型,只需16GB显存即可进行推理。
- 2024年5月20日,发布了基于llama3-8b的CogVLM2,性能与GPT-4V相当或更优。
模型特点
- 显著提升关键指标,如TextVQA, DocVQA。
- 支持8K文本长度和1344*1344图像分辨率。
- 提供中英文双语模型版本。
模型详细信息
- 基座模型:Meta-Llama-3-8B-Instruct
- 语言:英文和中英文双语
- 模型大小:19B
- 任务:图像理解,对话模型
- 文本长度:8K
- 图片分辨率:1344*1344
模型使用
最低配置要求
CogVlM2 Int4 型号需要 16G GPU 内存就可以运行,并且必须在具有 Nvidia GPU 的 Linux 上运行。
| Model Name | 19B Series Model | Remarks |
|---|---|---|
| BF16 / FP16 Inference | 42GB | Tested with 2K dialogue text |
| Int4 Inference | 16GB | Tested with 2K dialogue text |
| BF16 Lora Tuning (Freeze Vision Expert Part) | 57GB | Training text length is 2K |
| BF16 Lora Tuning (With Vision Expert Part) | > 80GB | Single GPU cannot tune |
部署步骤
模型下载
- 这里从 huggingface 上下载模型
- 如果使用AutoDL算力平台可以使用
source /etc/network_turbo进行学术加速 ,unset http_proxy && unset https_proxy取消加速
shell
# 创建文件夹
mkdir cogvlm2
# 按照huggingface_hub 工具下载模型
pip install -U huggingface_hub
# 下载模型到当前文件夹
huggingface-cli download THUDM/cogvlm2-llama3-chinese-chat-19B-int4 --local-dir .
# 也可以使用
git clone https://huggingface.co/THUDM/cogvlm2-llama3-chinese-chat-19B-int4下载代码
shell
git clone https://github.com/THUDM/CogVLM2安装依赖
cd basic_demo
pip install -r requirements.txt
- 如果安装出现依赖库冲突的错误,可以采用下面
requirements.txt
shell
xformers>=0.0.26.post1
#torch>=2.3.0
#torchvision>=0.18.0
transformers>=4.40.2
huggingface-hub>=0.23.0
pillow>=10.3.0
chainlit>=1.0.506
pydantic>=2.7.1
timm>=0.9.16
openai>=1.30.1
loguru>=0.7.2
pydantic>=2.7.1
einops>=0.7.0
sse-starlette>=2.1.0
bitsandbytes>=0.43.1代码修改
vim web_demo.py
shell
# 修改模型路径为本地路径
MODEL_PATH = '/root/autodl-tmp/cogvlm2/cogvlm2-llama3-chinese-chat-19B-int4'启动WebDemo
shell
chainlit run web_demo.py访问
本地则访问 : http://localhost:8000
如果是AutoDL 使用ssh代理来访问 , 输入yes, 如何粘贴密码即可
shell
ssh -CNg -L 8000:127.0.0.1:8000 root@connect.cqa1.xxxx.com -p 46671- 页面
效果
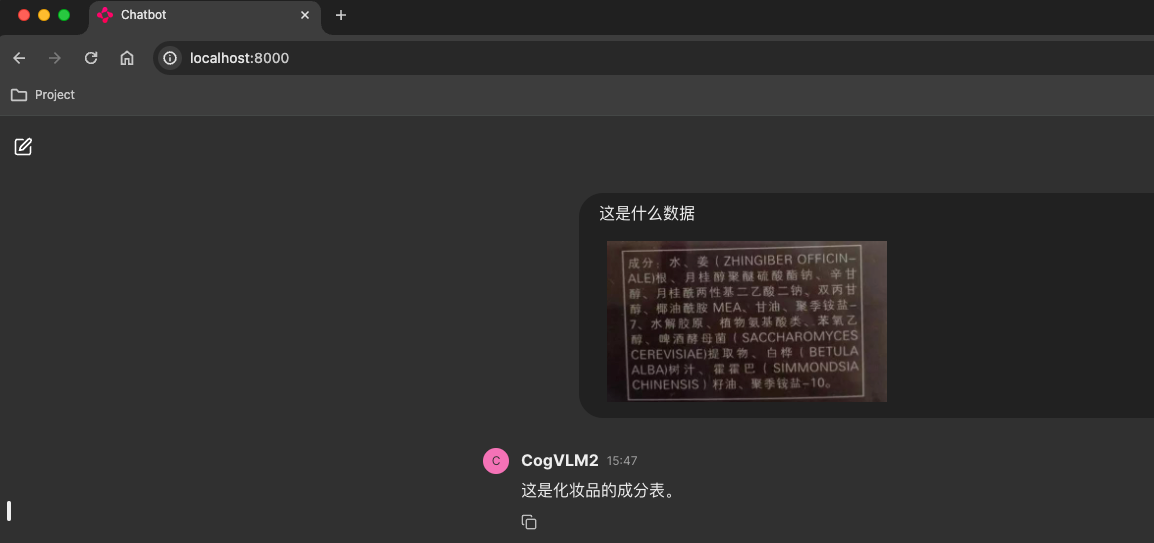
- 成份表
- 火车票
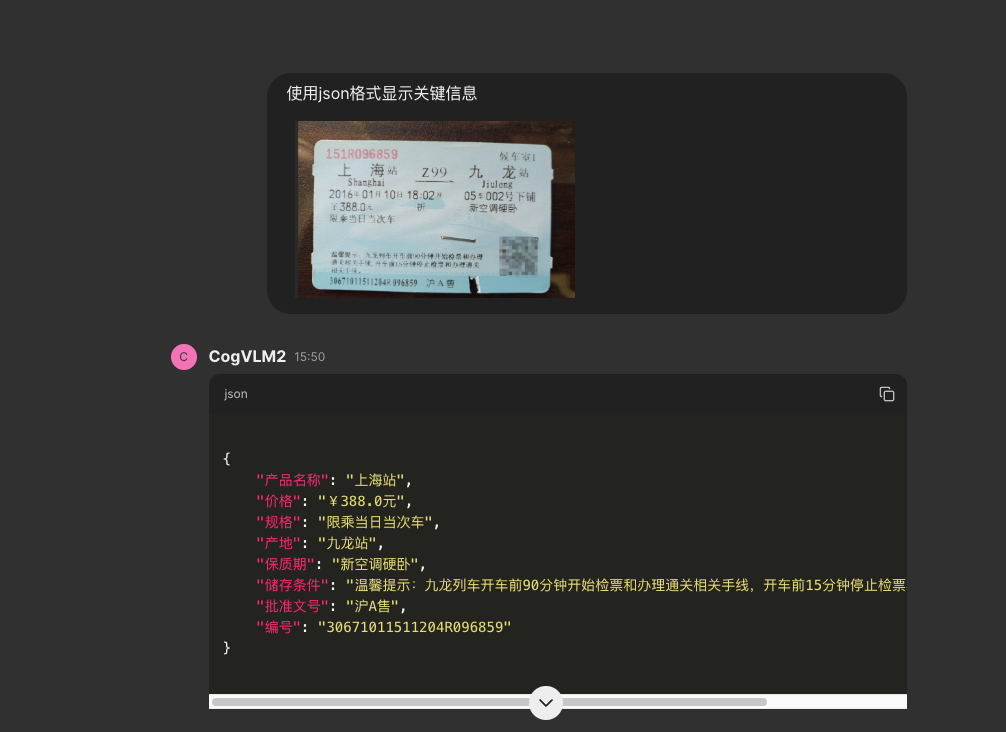
这里键的含义不对, int4 估计会有性能损失导致的
- 盖了章的报价表


OpenAI API
使用 OpenAI API格式的方式请求和模型的对话。
shell
python openai_api_demo.py错误解决
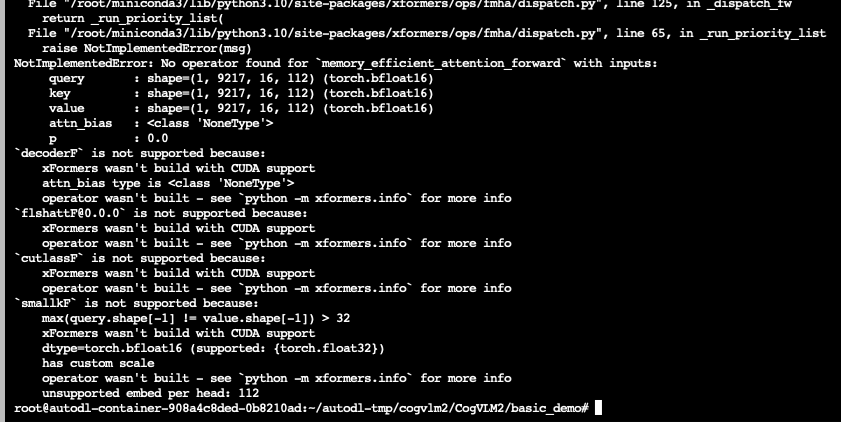
解决办法 :
使用下面
requirements.txt重新安装依赖
shellxformers>=0.0.26.post1 #torch>=2.3.0 #torchvision>=0.18.0 transformers>=4.40.2 huggingface-hub>=0.23.0 pillow>=10.3.0 chainlit>=1.0.506 pydantic>=2.7.1 timm>=0.9.16 openai>=1.30.1 loguru>=0.7.2 pydantic>=2.7.1 einops>=0.7.0 sse-starlette>=2.1.0 bitsandbytes>=0.43.1