墨菲定律与康威定律
在系统设计的时候,可以依据于墨菲定律
- 任何事情都没有表面上看起来那么简单
- 所有的事情都会比你预计的时间长
- 可能出错的事总会出错
- 担心的某一个事情的发送,那么它就更有可能发生
在系统划分的时候,可以依据康威定律
- 系统架构与公司的组织架构是相似的
- 应按照业务闭环进行系统拆分/组织架构拆分,实现闭环/高内聚/低耦合,减少沟通成本
核心关键点
- 可伸缩性(Scalability):系统应该能够根据需要进行水平或垂直扩展,以应对不断增长的用户量和负载。可伸缩性的实现可以通过使用负载均衡、分布式计算、缓存等技术手段。
- 高可用性(High Availability):系统应该具备高可用性,即在面对故障或部分组件失效时,仍能保持正常运行。为了实现高可用性,可以采用冗余备份、故障转移、容灾等策略。
- 弹性(Resilience):系统应该具备弹性,能够在面对异常情况时快速恢复正常状态。弹性的实现可以通过监控、自动化故障恢复、灾难恢复等方式。
- 可扩展性(Extensibility):系统应该具备可扩展性,能够方便地添加新功能或模块,以满足不断变化的需求。可扩展性的实现可以通过模块化设计、松耦合、插件化等方式。
- 安全性(Security):系统应该具备安全性,能够保护用户数据和系统资源免受未经授权的访问、攻击或滥用。安全性的实现可以包括身份认证、访问控制、数据加密等措施。
- 可管理性(Manageability):系统应该具备良好的可管理性,使得系统的部署、监控、维护和调试都能够方便进行。可管理性的实现可以通过日志记录、性能监控、自动化运维等方式。
- 性能(Performance):系统应该具备良好的性能,能够在可接受的时间内响应用户请求并处理大量的并发操作。性能的实现可以通过优化算法、缓存、异步处理等手段。
- 可靠性(Reliability):系统应该具备可靠性,即能够在长时间运行中保持稳定的状态,不会出现系统崩溃或数据丢失等问题。可靠性的实现可以通过容错设计、数据备份、错误处理等方式。
设计原则
幂等设计
幂等性对大多数同志来说是容易忽视的问题,但无论是单体还是微服务都会考虑这个问题,相对而言微服务项目在项目运行中是非常需要关注的问题。在项目中如服务与服务之间的消息通讯,目标服务没有及时处理或者返回,调用方服务可能会采取重试机制,此时可能就会造成服务端对同一个任务处理两次的情况,顾需要考虑幂等性的设计防止这种情况的产生。
无状态
如果服务存在状态对整个系统而言就会降低扩展,如果服务无状态,那么应用比较容易进行水平扩容。实际生成环境中可能是应用无状态,配置文件是有状态的,那么我们就可以考虑通过配置中心指定。
消息队列
消息队列在项目中多以处理耗时任务、异步任务为主,但也可以用于流量削峰/缓冲等。但在使用消息队列的时候需要考虑生产消息失败,以及消息重复接收的场景。目前的一些消息队列机制如rabbitmq、kafka等都有相关的应对方案。但在设计的时候对系统来说如果不能容忍失败的时候,一定要做好数据的后续处理,比如将数据持久化,设置警告。

在使用了消息队列的情况下还可能存在数据丢失的情况,因此需要考虑对数据进行校验来保证数据的一致性和完整性。可以通过worker定期检查对应日志,对数据校验,如果存在问题进行补尝。
数据异构/聚合
此项主要应用在高并发的场景,比如以课程详情为例,它所要展示的课程详情信息需要从多个服务中获取,然后再汇总返回给用户。
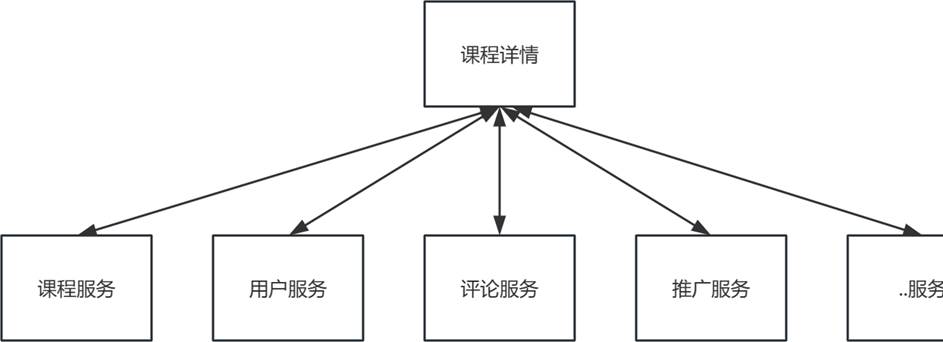
如果每次都是从多个服务中获取,这样读性能会降低。此时我们可以将课程所需要的数据进行异构到课程服务中,然后对相关的数据进行聚合存储,形成数据的闭环,
-
数据异构:通过
mq机制接收数据的变更,然后序列化存储到合适的存储引擎中 -
数据聚合:把多个服务的数据源拿过来,提前就根据业务组装好数据结构存储到
kv存储中 -
前端展示:前端通过一次或少量调用就可以获取到所有需要的数据。
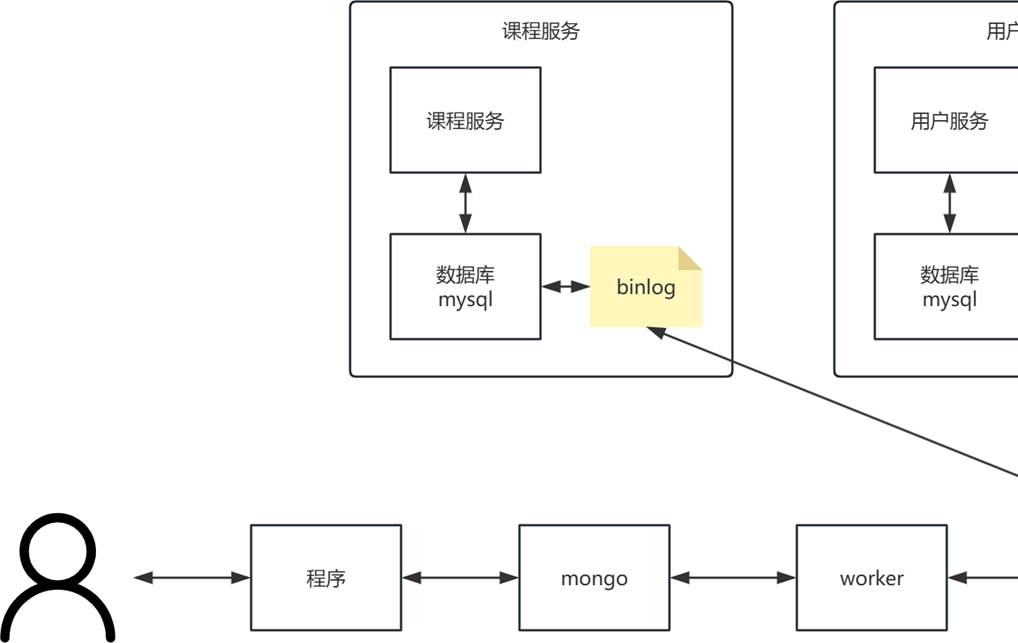
如下示例:可以基于cannal监听各个服务mysql的binlog日志,然后通过worker同步并聚合到mongodb中,用户获取课程信息就可以从mongodb中获取到数据。
多级缓存
在系统中:我们可以根据服务的数据情况,在各个层级之间合理设置缓存。节点有:客户端→客户端网络→CDN→接入层→应用层→分布式缓存
客户端如果为APP则可以将一些素材缓存到客户端里,而浏览器则可以缓存一些实时不高的数据,如评价、广告词、logo等。
在接入层往往应用的是nginx,我们可以设置nginx的代理缓存来实现。
对应用层和分布式缓存而言主要缓存具有变化性的,并且要是实时较高并访问频率高的数据。
在运用缓存的时候需考虑缓存的更新时间点。
并发化
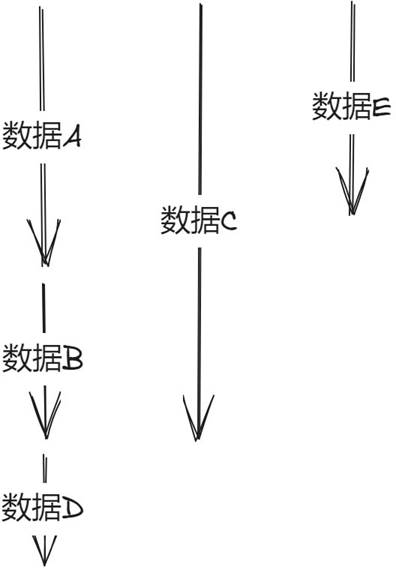
假设我们有如下数据
css
目标数据 数据A 数据B 数据C 数据D 数据E
获取时间 20ms 10ms 30ms 5ms 15ms
依赖关系 无 依赖A 无 依赖A、B 无如果程序串联执行则需要80ms。
如果我们并发化获取,则需要35ms,能提升一倍的性能。
限流
限流的目的是防止恶意请求流量、恶意攻击,或者防止流量超出峰值。
- 流量的控制可以用
nginx的limit模块,或者自己在应用层采用的限流算法处理如:令牌桶算法 - 对恶意请求的
ip可以用nginx的deny进行处理。