清除标注错误的数据
监督学习问题的数据由输入\(x\)和输出标签 \(y\) 构成,如果观察一下的数据,并发现有些输出标签 \(y\) 是错的。的数据有些标签是错的,是否值得花时间去修正这些标签呢?

看看在猫分类问题中,图片是猫,\(y=1\);不是猫,\(y=0\)。所以假设看了一些数据样本,发现这(倒数第二张图片)其实不是猫,所以这是标记错误的样本。用了这个词,"标记错误的样本"来表示的学习算法输出了错误的 \(y\) 值。但要说的是,对于标记错误的样本,参考的数据集,在训练集或者测试集 \(y\) 的标签,人类给这部分数据加的标签,实际上是错的,这实际上是一只狗,所以 \(y\) 其实应该是0,也许做标记的那人疏忽了。如果发现的数据有一些标记错误的样本,该怎么办?

首先,来考虑训练集,事实证明,深度学习算法对于训练集中的随机错误是相当健壮的(robust)。只要的标记出错的样本,只要这些错误样本离随机错误不太远,有时可能做标记的人没有注意或者不小心,按错键了,如果错误足够随机,那么放着这些错误不管可能也没问题,而不要花太多时间修复它们。
当然浏览一下训练集,检查一下这些标签,并修正它们也没什么害处。有时候修正这些错误是有价值的,有时候放着不管也可以,只要总数据集总足够大,实际错误率可能不会太高。见过一大批机器学习算法训练的时候,明知训练集里有\(x\)个错误标签,但最后训练出来也没问题。
这里先警告一下,深度学习算法对随机误差很健壮,但对系统性的错误就没那么健壮了。所以比如说,如果做标记的人一直把白色的狗标记成猫,那就成问题了。因为的分类器学习之后,会把所有白色的狗都分类为猫。但随机错误或近似随机错误,对于大多数深度学习算法来说不成问题。
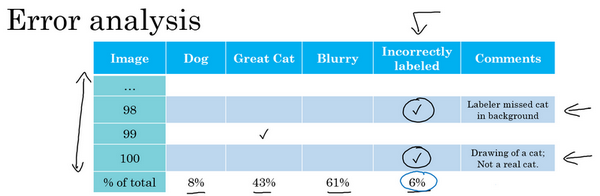
现在,之前的讨论集中在训练集中的标记出错的样本,那么如果是开发集和测试集中有这些标记出错的样本呢?如果担心开发集或测试集上标记出错的样本带来的影响,他们一般建议在错误分析时,添加一个额外的列,这样也可以统计标签 \(y=1\)错误的样本数。所以比如说,也许统计一下对100个标记出错的样本的影响,所以会找到100个样本,其中的分类器的输出和开发集的标签不一致,有时对于其中的少数样本,的分类器输出和标签不同,是因为标签错了,而不是的分类器出错。所以也许在这个样本中,发现标记的人漏了背景里的一只猫,所以那里打个勾,来表示样本98标签出错了。也许这张图实际上是猫的画,而不是一只真正的猫,也许希望标记数据的人将它标记为\(y=0\),而不是 \(y=1\),然后再在那里打个勾。当统计出其他错误类型的百分比后,就像在之前的博客中看到的那样,还可以统计因为标签错误所占的百分比,的开发集里的 \(y\) 值是错的,这就解释了为什么的学习算法做出和数据集里的标记不一样的预测1。
所以现在问题是,是否值得修正这6%标记出错的样本,如果这些标记错误严重影响了在开发集上评估算法的能力,那么就应该去花时间修正错误的标签。但是,如果它们没有严重影响到用开发集评估成本偏差的能力,那么可能就不应该花宝贵的时间去处理。
给看一个样本,解释清楚的意思。所以建议看3个数字来确定是否值得去人工修正标记出错的数据,建议看看整体的开发集错误率,在以前的博客中的样本,说也许系统达到了90%整体准确度,所以有10%错误率,那么应该看看错误标记引起的错误的数量或者百分比。所以在这种情况下,6%的错误来自标记出错,所以10%的6%就是0.6%。也许应该看看其他原因导致的错误,如果的开发集上有10%错误,其中0.6%是因为标记出错,剩下的占9.4%,是其他原因导致的,比如把狗误认为猫,大猫图片。所以在这种情况下,说有9.4%错误率需要集中精力修正,而标记出错导致的错误是总体错误的一小部分而已,所以如果一定要这么做,也可以手工修正各种错误标签,但也许这不是当下最重要的任务。

再看另一个样本,假设在学习问题上取得了很大进展,所以现在错误率不再是10%了,假设把错误率降到了2%,但总体错误中的0.6%还是标记出错导致的。所以现在,如果想检查一组标记出错的开发集图片,开发集数据有2%标记错误了,那么其中很大一部分,0.6%除以2%,实际上变成30%标签而不是6%标签了。有那么多错误样本其实是因为标记出错导致的,所以现在其他原因导致的错误是1.4%。当测得的那么大一部分的错误都是开发集标记出错导致的,那似乎修正开发集里的错误标签似乎更有价值。

如果还记得设立开发集的目标的话,开发集的主要目的是,希望用它来从两个分类器\(A\)和\(B\)中选择一个。所以当测试两个分类器\(A\)和\(B\)时,在开发集上一个有2.1%错误率,另一个有1.9%错误率,但是不能再信任开发集了,因为它无法告诉这个分类器是否比这个好,因为0.6%的错误率是标记出错导致的。那么现在就有很好的理由去修正开发集里的错误标签,因为在右边这个样本中,标记出错对算法错误的整体评估标准有严重的影响。而左边的样本中,标记出错对算法影响的百分比还是相对较小的。
现在如果决定要去修正开发集数据,手动重新检查标签,并尝试修正一些标签,这里还有一些额外的方针和原则需要考虑。首先,鼓励不管用什么修正手段,都要同时作用到开发集和测试集上,之前讨论过为什么,开发和测试集必须来自相同的分布。开发集确定了的目标,当击中目标后,希望算法能够推广到测试集上,这样的团队能够更高效的在来自同一分布的开发集和测试集上迭代。如果打算修正开发集上的部分数据,那么最好也对测试集做同样的修正以确保它们继续来自相同的分布。所以雇佣了一个人来仔细检查这些标签,但必须同时检查开发集和测试集。

其次,强烈建议要考虑同时检验算法判断正确和判断错误的样本,要检查算法出错的样本很容易,只需要看看那些样本是否需要修正,但还有可能有些样本算法判断正确,那些也需要修正。如果只修正算法出错的样本,对算法的偏差估计可能会变大,这会让的算法有一点不公平的优势,就需要再次检查出错的样本,但也需要再次检查做对的样本,因为算法有可能因为运气好把某个东西判断对了。在那个特例里,修正那些标签可能会让算法从判断对变成判断错。这第二点不是很容易做,所以通常不会这么做。通常不会这么做的原因是,如果的分类器很准确,那么判断错的次数比判断正确的次数要少得多。那么就有2%出错,98%都是对的,所以更容易检查2%数据上的标签,然而检查98%数据上的标签要花的时间长得多,所以通常不这么做,但也是要考虑到的。

最后,如果进入到一个开发集和测试集去修正这里的部分标签,可能会,也可能不会去对训练集做同样的事情,还记得在其他博客里讲过,修正训练集中的标签其实相对没那么重要,可能决定只修正开发集和测试集中的标签,因为它们通常比训练集小得多,可能不想把所有额外的精力投入到修正大得多的训练集中的标签,所以这样其实是可以的,用于处理的训练数据分布和开发与测试数据不同的情况,对于这种情况学习算法其实相当健壮,的开发集和测试集来自同一分布非常重要。但如果的训练集来自稍微不同的分布,通常这是一件很合理的事情,会在本晚些时候谈谈如何处理这个问题。
最后讲几个建议:
首先,深度学习研究人员有时会喜欢这样说:"只是把数据提供给算法,训练过了,效果拔群"。这话说出了很多深度学习错误的真相,更多时候,把数据喂给算法,然后训练它,并减少人工干预,减少使用人类的见解。但认为,在构造实际系统时,通常需要更多的人工错误分析,更多的人类见解来架构这些系统,尽管深度学习的研究人员不愿意承认这点。
其次,不知道为什么,看一些工程师和研究人员不愿意亲自去看这些样本,也许做这些事情很无聊,坐下来看100或几百个样本来统计错误数量,但经常亲自这么做。当带领一个机器学习团队时,想知道它所犯的错误,会亲自去看看这些数据,尝试和一部分错误作斗争。想就因为花了这几分钟,或者几个小时去亲自统计数据,真的可以帮找到需要优先处理的任务,发现花时间亲自检查数据非常值得,所以强烈建议这样做,如果在搭建的机器学习系统的话,然后想确定应该优先尝试哪些想法,或者哪些方向。