文章目录
ARM 扩展功能介绍
在ARM架构中,随着各个版本的进化,引入了多种技术和扩展来增强处理能力,特别是针对浮点运算、向量计算和矩阵运算。以下是ARMv8和ARMv9中与这些相关的一些关键技术和扩展的概述:
VFP (Vector Floating Point)
VFP 是矢量浮点 处理单元,用于提升浮点运算性能,它支持单精度和双精度浮点数的运算。之所以被称为"矢量"浮点,是因为不仅对处理浮点数的支持,而且还支持将浮点数作为SIMD运算的矢量处理。
在这种情况下"向量 "是将多个数据项打包到一个更大的数据容器中(例如,连续存储在单个寄存器中的多个独立值)。这是Armv8之前Arm体系结构浮点扩展的名称。
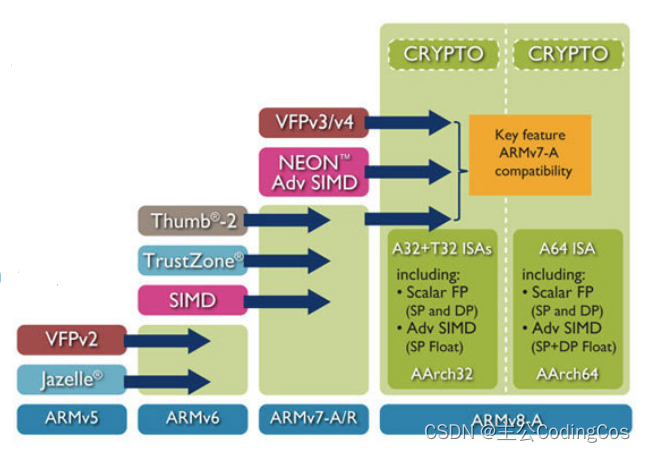
在Armv7体系结构中,不推荐使用VFP扩展来处理矢量中的浮点数,因为此功能已被"高级SIMD"扩展所取代。有不同版本的VFP(VFPv1、VFPv2、VFPv3、VFPv4)引入了对新功能和数据类型的支持。VFPv2是Armv5和Armv6架构的扩展,VFPv3和VFPv4是Armv7架构的扩展。
- 例子:在需要进行大量浮点运算的图形处理或科学计算应用中,VFP可以提供加速。
SIMD (Single Instruction, Multiple Data)
SIMD 技术允许一条指令同时对多个数据进行操作。在ARMv8中,这是通过NEON实现的,NEON提供了丰富的指令对浮点和整数数据进行并行处理。
一些现代软件,尤其是多媒体编解码软件和图形加速软件,有大量的少于机器字长的数据参与运算。例如,在音频应用中16位以内数据是频繁的,在图形与视频领域8位以内数据是频繁的。
当在32位微处理器上执行这些操作时,相当一部分计算单元没有被利用,但是依然消耗着计算资源。为了更好的利用这部分闲置的资源,SIMD技术使用一个单指令来并行地在同样类型和大小的多个数据元素上执行相同的操作。通过这种方法,硬件可以在同样时间消耗内用并行的4个8位数值加法运算来替代通常的两个32位数值加法运算
Figure1.1 展示了 UADD8 R0,R1, R2 指令操作。这个操作展示了以向量形式存储在通用寄存器R1和R2中的4个8位数值的并行加法运算。最终结果也以向量形式存储到寄存器R0。
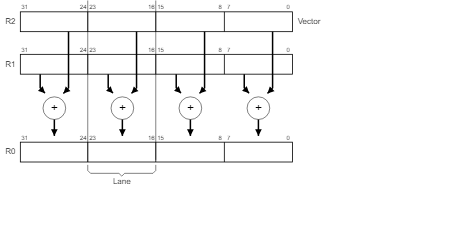
Figure1.1
NEON
ARMv7 架构引入了高级 SIMD 扩展作为 ARMv7-A 和 ARMv7-R 配置文件的可选扩展。NEON通过定义存储在 64 位双字长的寄存器D 和128 位四字长的寄存器Q中的向量操作指令组来扩展 SIMD 概念。
用在ARM处理器上的高级SIMD扩展的实现称为NEON,这是架构规范之外使用的通用术语。NEON技术在当前所有ARM Cortex-A系列处理器上得到了实现。
NEON 指令作为 ARM 或 Thumb 指令流的一部分执行。相比使用额外的加速器,这简化了软件的开发,调试和集成。传统的ARM或Thumb指令管理所有程序流程和同步。NEON指令涉及以下管理:
- 内存访问
NEON与通用寄存器之间的数据复制- 数据类型转换
- 数据处理
Figure1.2 展示了VADD.I16 Q0, Q1, Q2 指令如何并行地执行存储在Q1,Q2中的8通道16位数值的加法运算,最终结果存储到了Q0。

Figure1.2
SVE (Scalable Vector Extension)
SVE是ARMv8-A架构的一个扩展,它是针对高性能计算(HPC)和机器学习等领域开发的一套全新的矢量指令集,它是下一代SIMD指令集实现,而不是NEON指令集的简单扩展 。SVE指令集中有很多概念与NEON指令集类似 ,例如矢量、通道、数据元素等。SVE指令集也提出了一个全新的概念:可变矢量长度编程模型(VectorLength Agnostic,VLA)。
传统的SIMD指令集采用固定 大小的向量寄存器,例如NEON指令集采用固定的128位长度的矢量寄存器。而支持VLA编程模型的SVE指令集则支持可变长度的矢量寄存器。这样允许芯片设计者根据负载和成本来选择一个合适的矢量长度。SVE指令集的矢量寄存器的长度最小支持128位,最大可以支持2048位,以128位为增量。SVE设计确保同一个应用程序可以在支持不同矢量长度的SVE指令机器上运行,而不需要重新编译代码,这是VLA编程模型的精髓。
SME (Scalable Matrix Extension)
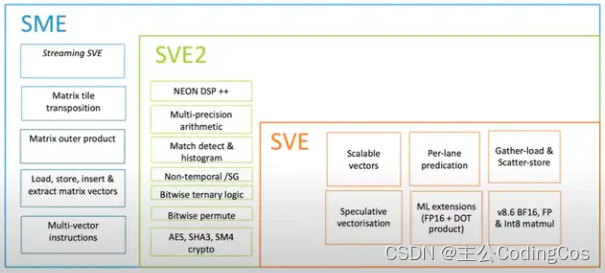
ARMv9 引入了 SME (Scalable Matrix Extension),SME 是基于 SVE2 定义的,旨在加速AI和机器学习应用,特别是对于大型生成式AI模型。SME通过增强矩阵操作,提供了更高的灵活性和效率,以应对日益复杂的AI需求。它建立在SVE2的基础上,新增了对矩阵tile的高效存取、向量插入提取以及矩阵转置等功能。SME还引入了Streaming SVE模式,支持高吞吐量的数据流处理,并通过ZA存储优化了硬件资源的使用。这些特性共同确保了Arm架构在AI领域的持续竞争力和创新能力。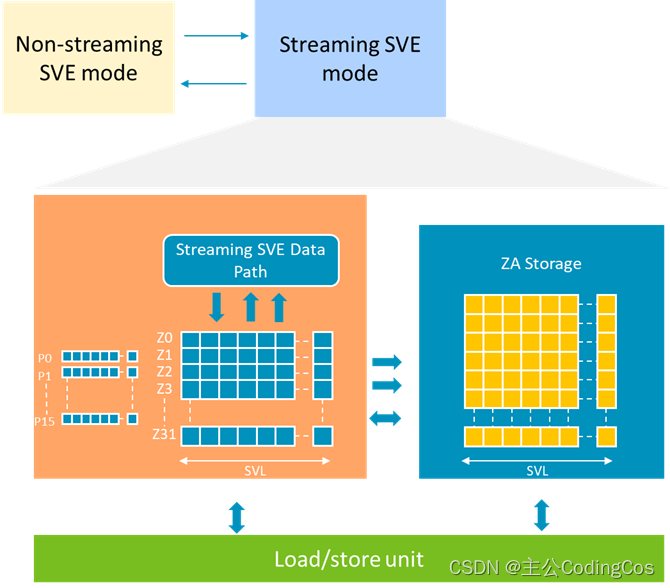
CME (Compute Matrix Engine)
计算矩阵引擎 是执行可扩展矩阵扩展(SME)操作逻辑的名称。CME的设计使得在多个处理元件(PE)上执行的指令可以共享功能,其中"PE "是我们通常称之为集群内核心的架构术语。
MVE (M-profile Vector Extension)
- 简介 :MVE是针对ARM Cortex-M系列处理器的向量处理扩展,旨在提高能效和处理效率,特别适用于微控制器和嵌入式系统。它提供对各种SIMD操作的支持。类似于NEON作为A级高级SIMD扩展的产品名称,"Helium"是用于M-配置文件矢量扩展的产品名。
MVE有两种变体,MVE-I 和MVE-F。MVE-I仅支持整数矢量,MVE-F支持浮点数矢量。在处理器核心中包含MVE-F还要求处理器支持MVE-I和浮点扩展。
MPE (Media Processing Engine)
媒体处理引擎 (MPE) 是用于多个 Armv7A 处理器上的高级 SIMD 逻辑的名称:Cortex-A5、Cortex-A7 和 Cortex-A9。它也经常/通常称为"NEON MPE"或"NEON 媒体处理引擎",它是实现 ASE/NEON 支持的处理器部分的另一个名称。
Structure of the MPE
总结
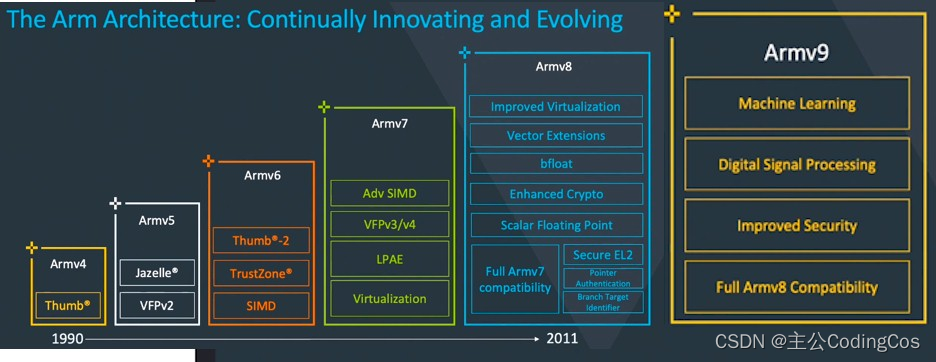
从VFP到SVE、SME等,ARM架构通过引入一系列技术和扩展持续在浮点运算、向量处理和矩阵计算等方面提升性能。这些技术使得ARM处理器能够广泛应用于从低功耗的嵌入式设备到高性能计算场景。随着ARMv9的推出,对AI、机器学习等领域的支持将进一步加强,标志着处理能力和效率的又一次重大提升。
推荐阅读 :
https://blog.csdn.net/AngelLover2017/article/details/124309644
https://aijishu.com/a/1060000000466399
https://baijiahao.baidu.com/s?id=1798716186152062162&wfr=spider&for=pc
https://blog.csdn.net/weixin_42135087/article/details/125269850