1 SIMD指令集在PostgreSQL中的应用详解
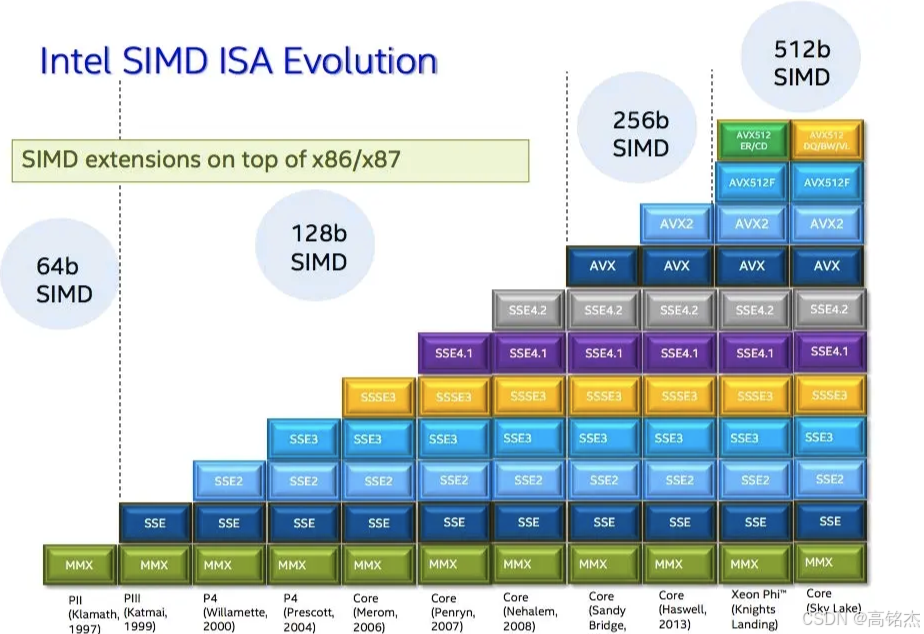
SIMD是一种能够同时处理多个数据元素的CPU指令集技术,通过向量寄存器实现单条指令对多个数据的操作,可显著提高计算密集型任务性能。
SIMD在PG中主要应用于x86和ARM架构的CPU,针对事务ID数组的线性搜索、JSON字符串处理以及子事务搜索等场景进行了优化,性能提升可达20%以上 。
PostgreSQL中SIMD的应用场景
确定某个事务ID是不是InProgress状态。
c
bool
TransactionIdIsInProgress(TransactionId xid)
{
...
...
if (!TransactionIdEquals(topxid, xid) &&
pg_lfind32(topxid, xids, nxids))
return true;
cachedXidIsNotInProgress = xid;
return false;
} 确定某个xid是不是在快照的xip或subxip数组中(运行中的事务)
c
bool
XidInMVCCSnapshot(TransactionId xid, Snapshot snapshot)
{
/* Any xid < xmin is not in-progress */
if (TransactionIdPrecedes(xid, snapshot->xmin))
return false;
/* Any xid >= xmax is in-progress */
if (TransactionIdFollowsOrEquals(xid, snapshot->xmax))
return true;
if (!snapshot->takenDuringRecovery)
{
if (!snapshot->suboverflowed)
{
/* we have full data, so search subxip */
if (pg_lfind32(xid, snapshot->subxip, snapshot->subxcnt))
return true;
...
...
}2 SIMD在PostgreSQL中的具体实现
pg_lfind8
bool
lfind8(uint8 key, uint8 *base, uint32 nelem)
{
uint32 i;
/* round down to multiple of vector length */SIMD向量化处理,下面这行代码将数组长度向下舍入到向量长度(16字节__m128i)的倍数:
uint32 tail_idx = nelem & ~(sizeof(Vector8) - 1);
Vector8 chunk;一次操作可以同时比较16个,不逐个比较
c
for (i = 0; i < tail_idx; i += sizeof(Vector8))
{
vector8_load(&chunk, &base[i]);
if (vector8_has(chunk, key))
return true;
}
/* Process the remaining elements one at a time. */
for (; i < nelem; i++)
{
if (key == base[i])
return true;
}
return false;
}pg_lfind32
c
bool
pg_lfind32(uint32 key, uint32 *base, uint32 nelem)
{
uint32 i = 0;- keys=vector32_broadcast:将要查找的key值广播到整个向量中(比如把5变成5,5,5,5)
- nelem_per_vector: 每个向量能容纳多少个uint32,4个!
- nelem_per_iteration: 每轮 处理的元素数,16个!
c
const Vector32 keys = vector32_broadcast(key); /* load copies of key */
const uint32 nelem_per_vector = sizeof(Vector32) / sizeof(uint32);
const uint32 nelem_per_iteration = 4 * nelem_per_vector;计算每轮处理范围:
将总元素数向下舍入到16的倍数,如果有100个元素,tail_idx = 96(6×16)
c
/* round down to multiple of elements per iteration */
const uint32 tail_idx = nelem & ~(nelem_per_iteration - 1);
for (i = 0; i < tail_idx; i += nelem_per_iteration)
{
Vector32 vals1, // 存储数据的4个向量
vals2,
vals3,
vals4,
result1, // 存储比较结果的4个向
result2,
result3,
result4,
tmp1, // 临时合并向量
tmp2,
result; // 最终结果向量一次vector32_load加载4个uint32到vals1中,共四次,共加载16个uint32进行计算。
c
/* load the next block into 4 registers */
vector32_load(&vals1, &base[i]);
vector32_load(&vals2, &base[i + nelem_per_vector]);
vector32_load(&vals3, &base[i + nelem_per_vector * 2]);
vector32_load(&vals4, &base[i + nelem_per_vector * 3]);计算
c
/* compare each value to the key */
result1 = vector32_eq(keys, vals1);
result2 = vector32_eq(keys, vals2);
result3 = vector32_eq(keys, vals3);
result4 = vector32_eq(keys, vals4);
/* combine the results into a single variable */
tmp1 = vector32_or(result1, result2);
tmp2 = vector32_or(result3, result4);
result = vector32_or(tmp1, tmp2);
/* see if there was a match */
if (vector32_is_highbit_set(result))
return true;
}处理不能被16整除的剩余元素
c
/* Process the remaining elements one at a time. */
for (; i < nelem; i++)
if (key == base[i])
return true;
return false;
}3 PG SIMD X86性能测试
https://github.com/mingjiegao/libsimd/tree/main
执行make check后,会自动做性能对比,结果如下:
=== Performance Tests ===
libsimd Performance Tests
=========================
System Information:
- Compiler: 8.5.0 20210514 (Tencent 8.5.0-26)
- AVX2 support: Enabled
- SSE4.2 support: Enabled
Performance Test Results
========================
Test Configuration:
- Iterations per test: 1000
- Warmup runs: 10
- Key distribution: 75% existing, 25% non-existing
Test Name | Size | SIMD (ms) | Linear (ms) | Speedup | Status
--------------------------------------------------------------------------------
lfind8_small | 10000 | 0.03 | 0.10 | 3.92x | PASS
lfind8_medium | 100000 | 0.03 | 0.10 | 4.16x | PASS
lfind8_large | 1000000 | 0.03 | 0.11 | 4.08x | PASS
lfind8_xlarge | 10000000 | 0.03 | 0.10 | 3.96x | PASS
lfind32_small | 10000 | 0.67 | 2.06 | 3.06x | PASS
lfind32_medium | 100000 | 6.73 | 20.72 | 3.08x | PASS
lfind32_large | 1000000 | 102.91 | 209.44 | 2.04x | PASS
lfind32_xlarge | 10000000 | 1986.14 | 3120.74 | 1.57x | PASS
--------------------------------------------------------------------------------
Performance Summary:
- Total tests: 8
- Passed tests: 8
- Failed tests: 0
- Average speedup: 3.23x
- SIMD implementation is 3.23x faster on average
Notes:
- Speedup values > 1.0 indicate SIMD is faster
- Results may vary based on CPU architecture and compiler optimizations
- All tests include correctness verification
Worst Case Performance Analysis
===============================
Worst case (key not found):
- SIMD time: 0.45 ms
- Linear time: 7.01 ms
- Speedup: 15.68x
Performance testing completed.