常用数据处理
主要是四种方式:正则表达式、AC自动机、困惑度过滤低质文本、最小哈希算法实现文本去重
1. 正则表达式,去做一些模式匹配
ex:
论文的评审内容有时会存在大量列举reference(参考文献)的情况
这些reference会占据大量的评审内容篇幅
且多数情况下仅为参考文献的标题、年份等无意义信息
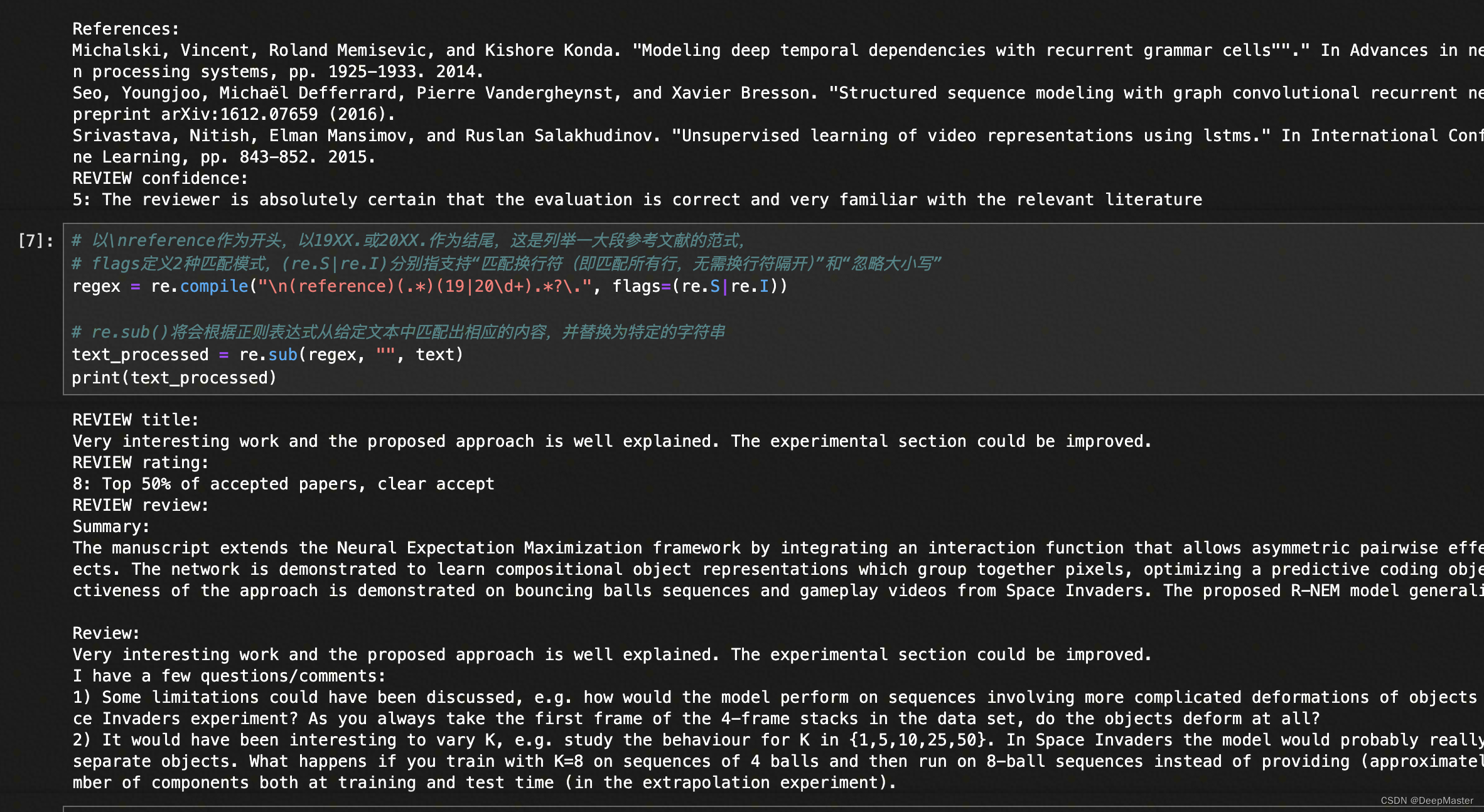
比如将数据集中,每条评审中reference部分给替换成""
2. AC自动机词库匹配
应用场景:
-
从大量文本中匹配出预设词库中的敏感词。
-
从大量文本中判断是否存在预设词库中的某些词。
传统的低效做法是:遍历词库,对于词库中每个词都在目标文本中查询一遍。
AC自动机的方法是,对于词库中的内容构建一个前缀树,对于目标文本只需要过一遍就能知道是否存在词库中的词
EX:
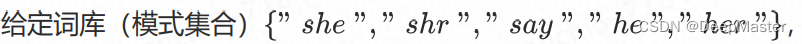
- 构建树
通过这些模式字符串的公共前缀来进行构造
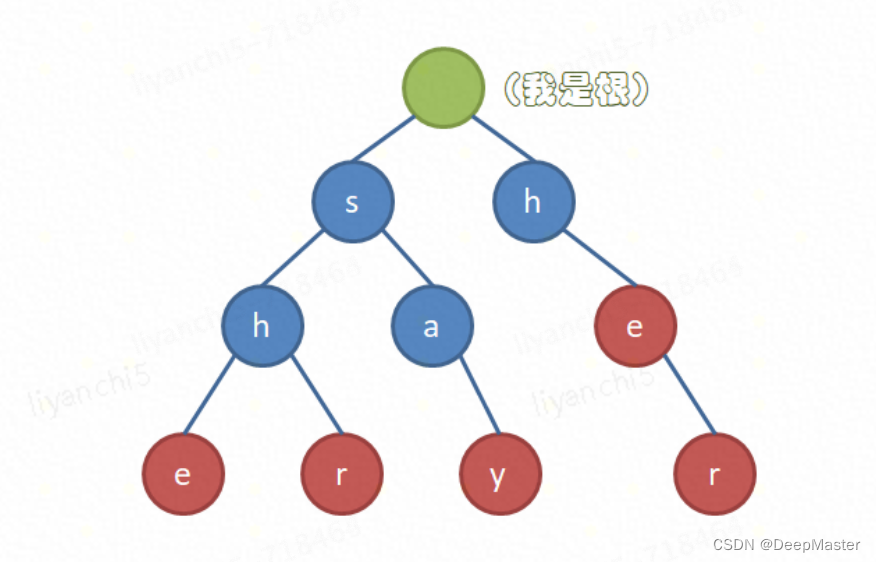
- 在相应节点定义接收态。
每当能构成一个模式,那么这个模式对应的最后一个节点就是接收态,图中红色就是接收态,
每个接收态会存储其对应的回溯长度
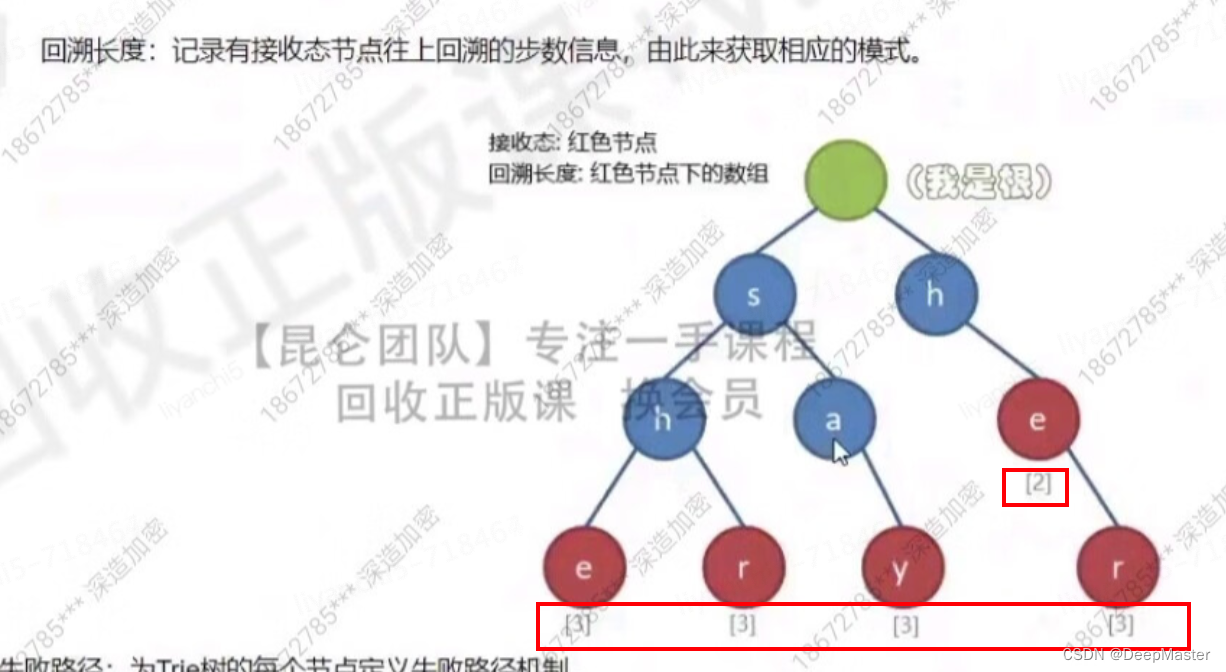
3.为树的每个节点定义失败路径机制。
失败路径机制:
位于当前节点无法再进一步往下匹配时,将指向其"节点路径的最大后缀同值节点"(如下图的橙色箭头),
如果 不存在"节点路径的最大后缀同值节点",则指向根节点(如下图的紫色箭头代表指向根节点)。
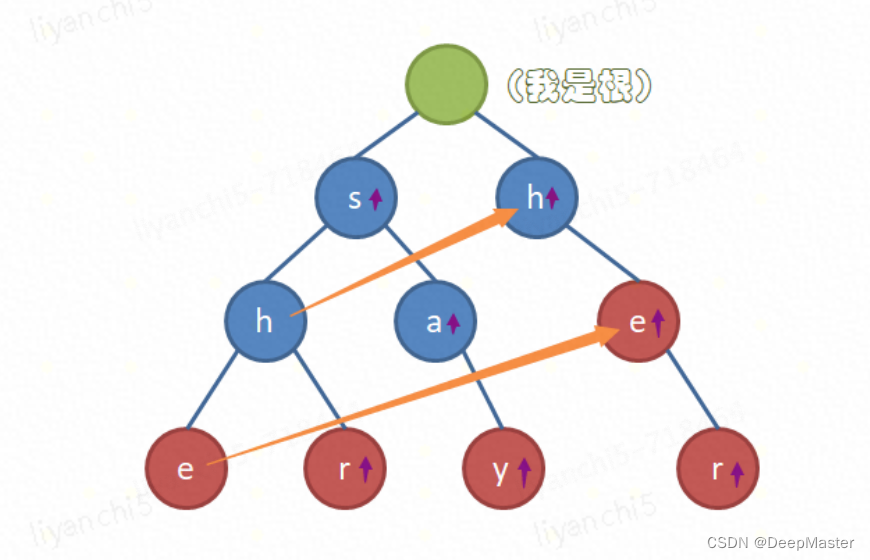
例如"she"最大后缀就是he,刚好树种有对应其他位置的he,就是他们的同值节点,比如当she走完之后发现没法再进行匹配时,就会调到另一个e上继续做匹配
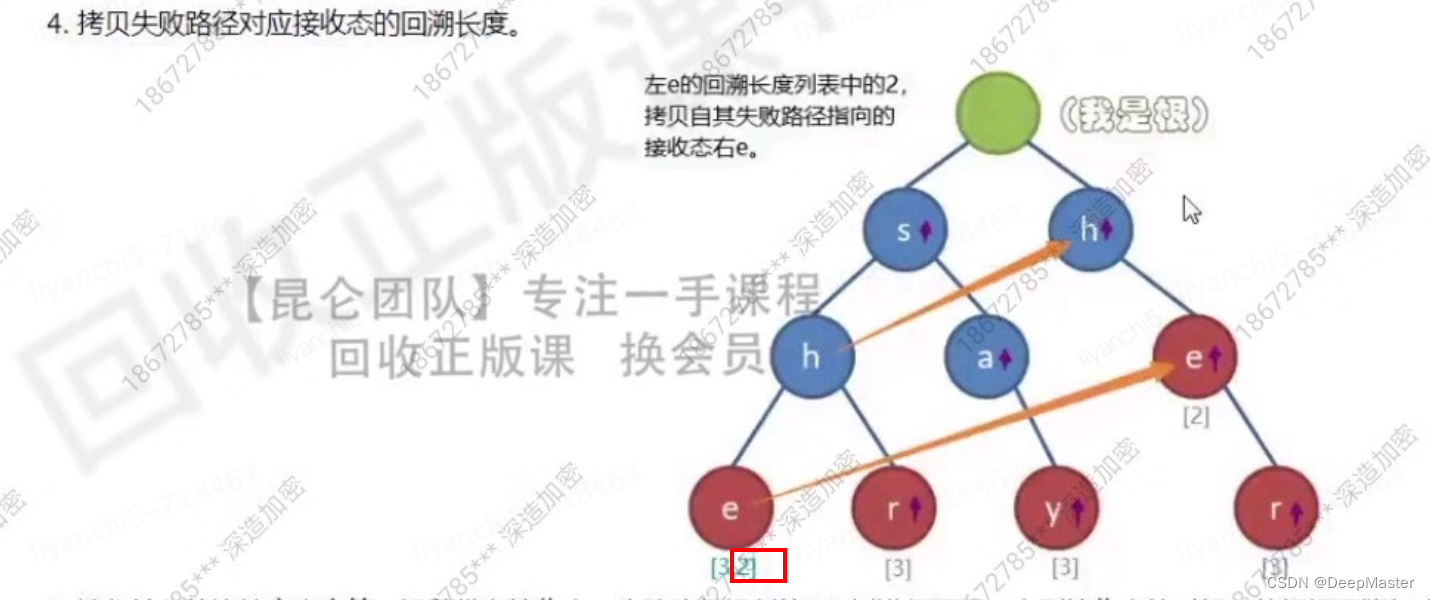
然后还会拷贝失败路径对应接受态,也就是另一个e的回溯长度,2
这样有个好处,会把长路径中蕴含的短路径(模式)也可以记录到
比如在匹配aasherhsy时,前两个a,匹配不到,均是从根节点回到自身,从s开始,一直匹配到she,然后回溯,此时到e时由于存储了两个回溯长度,一个回溯三次,一个回溯两次,所以把she 、he都会算进去,she后匹配不到r,然后就跳转到最大后缀同值节点上,就是另一个e,再往下,刚好可以匹配到r,r是接收态,所以会再次回溯,her也匹配到了,r往后匹配不到了,也没有最大后缀同值节点,于是就跳转回根节点,以此类推。
3. 困惑度过滤低质文本
就是利用一些早期的LM,通过去计算loss,来得到文本的困惑度,困惑度越高就越容易不是一个通顺的句子

LM的loss就是,分解到每一步,每一步都是以前面生成token为依据,生成当前token的概率然后取log。 每一步求和,取负数,求平均。
困惑度的计算方式是

就是每一步的生成概率累乘起来然后开T次方(文本长度)
有:ppl = exp(loss)
关于loss的计算方式,label就是原始文本错一位即可,比如"我爱上学",label就是"爱上学",就是每个token的next token,就是label
计算结果示例:

可以看到语句不通顺的句子,困惑度非常高
困惑度这个指标其实不好设定相关的阈值,一般来说是,取一批样本,计算完困惑度之后按困惑度进行倒排,然后通过人为判定,取一个分位点,按照分位点对应的值再做筛选
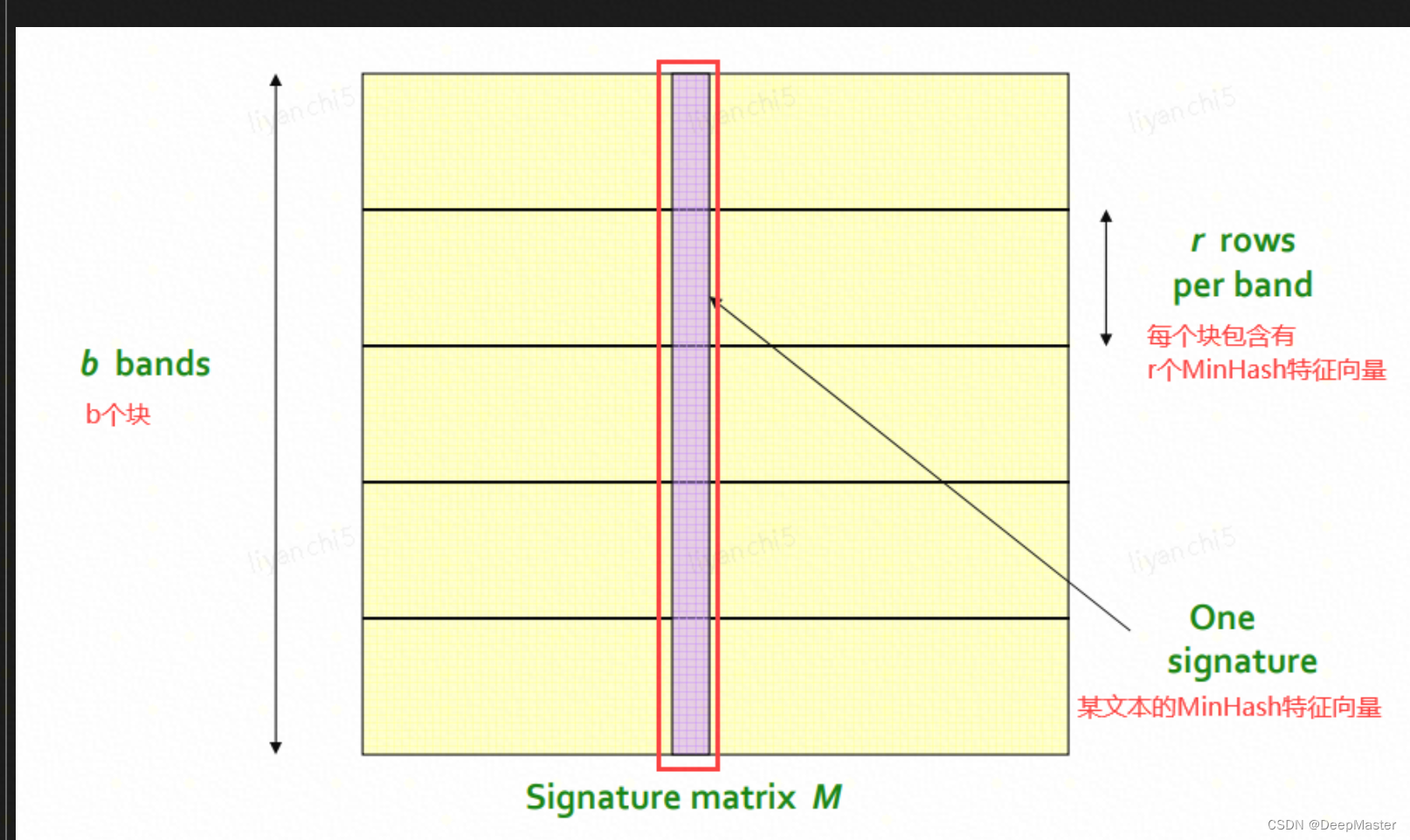
4. 最小哈希算法实现文本去重
文本去重一般使用Jaccard相似度

就是交集的token数除以并集的token数。
但是这种方法在计算多文本以及长文本的时候计算量太大,速度慢
于是有一种近似的方法,就是minhash
步骤:

- 首先构造一个矩阵

类似于一个词袋模型
(这里看来,每个文本对应的向量就是1,1,1,1, 0,1,1,1, 1,0,0,1)
- 行打乱

每个文本记录第一个1出现的位置对应的行号,S1S2S3分别是0,0,2,此时S1向量就是1
第二次打乱

S1S2S3分别是0,1,0,此时S1的向量就是0,0
循环进行
假设打乱了三次,S1,S2,S3分别得到一个三维向量
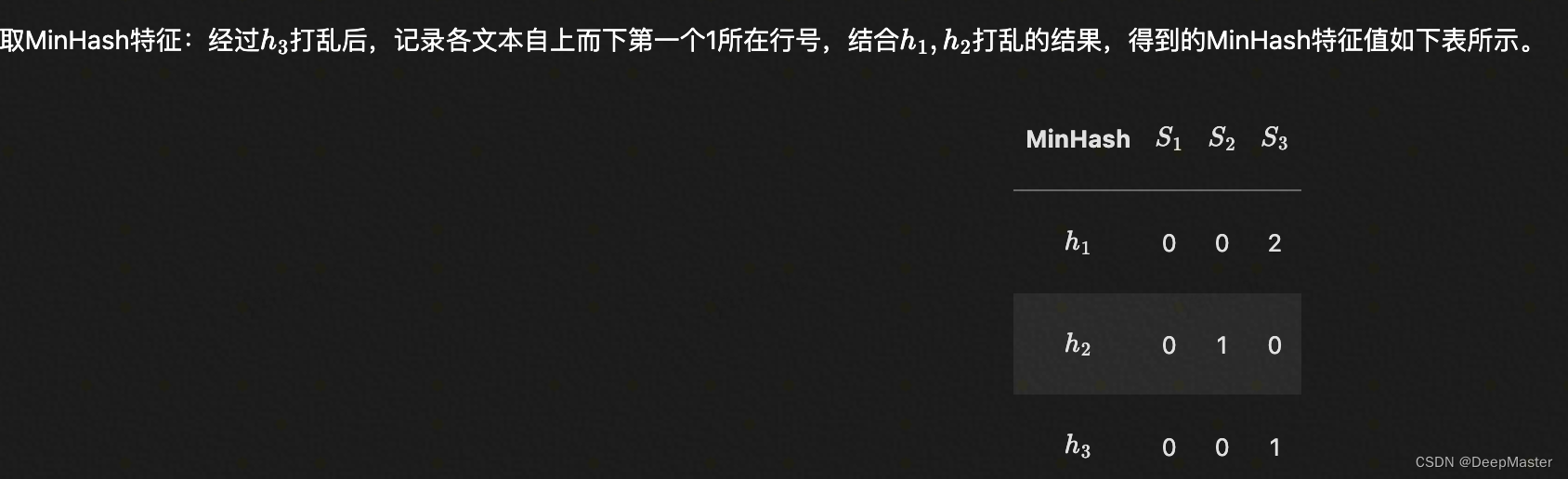
计算相似度

两两相似度就是,看对应位置是否相等,相等就是1否则为0,然后除以向量长度
假设原始向量长度是2000,那么我们可以通过这种方式降维到256,512等,通过这种minhash的方式来近似jaccard的结果
但是这种方式在计算的文档数过多时,还是不够快
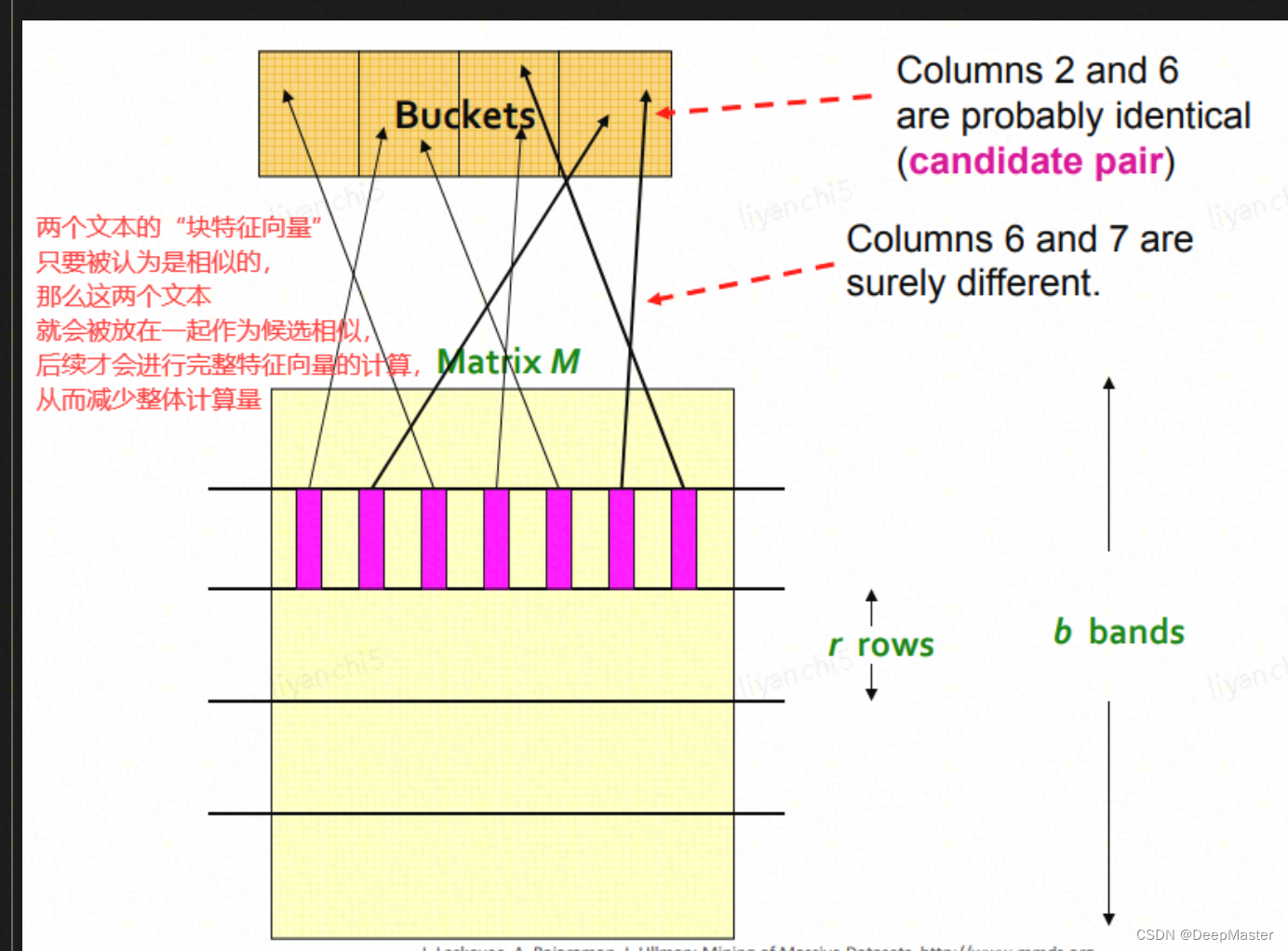
于是在minhash基础上再引入LSH,LSH指Locality Sensitive Hashing(局部敏感哈希)
通过给minhash产生的向量进行分块,先从第一个块开始计算,若两个向量第一个块开始相似度就不够高,那么就不用再计算下去了,相当于做了一个快速的初筛