Deploy an AI Coding Assistant with NVIDIA TensorRT-LLM and NVIDIA Triton | NVIDIA Technical Blog
Quick Start Guide --- tensorrt_llm documentation (nvidia.github.io)
使用TensorRT-LLM的源码,来下载docker并在docker里编译TensorRT-LLM;
模型格式先Huggingface转为FasterTransformer;再用TensorRT-LLM将其compile为TensorRT engine;然后可用TensorRT-LLM的C++ runtime来跑推理(或者模型放到Triton Repo上,并指定TensorRT-LLM为backend)
Input的Tokenizing和Output的De-Tokenizing,视作前处理、后处理,创建"Python Model";整个流程用一个"Ensemble Model"来表示,包含以上两个"Model"以及真正的GPT-Model;
LLama:
https://github.com/NVIDIA/TensorRT-LLM/blob/main/examples/llama/README.md
TensorRT-LLM支持很多常用模型;例如:baichuan、internlm、chatglm、qwen、bloom、gpt、gptneox、llama;
convert_checkpoint.py,是每种模型用自己的;run.py,是所有模型共享;
每种模型,支持的技术完善程度不同。
支持LLama的以下功能:
- FP16
- FP8
- INT8 & INT4 Weight-Only
- SmoothQuant
- Groupwise quantization (AWQ/GPTQ)
- FP8 KV CACHE
- INT8 KV CACHE (+ AWQ/per-channel weight-only)
- Tensor Parallel
- STRONGLY TYPED
python convert_checkpoint.py
--tp_size 4 // Tensor-parallel
--pp_size 4 // Pipeline-parallel
Pipeline并行,在某一个GPU忙碌时,其他GPU是否在忙着处理别的batch?
量化相关:
Numerical Precision --- tensorrt_llm documentation (nvidia.github.io)
9种量化,对每种模型只支持一部分:
| Model | FP32 | FP16 | BF16 | FP8 | W8A8 SQ | W8A16 | W4A16 | W4A16 AWQ | W4A16 GPTQ |
|---|---|---|---|---|---|---|---|---|---|
| Baichuan | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| BERT | Y | Y | Y | . | . | . | . | . | . |
| ChatGLM | Y | Y | Y | . | . | . | . | . | . |
| ChatGLM-v2 | Y | Y | Y | . | . | . | . | . | . |
| ChatGLM-v3 | Y | Y | Y | . | . | . | . | . | . |
| GPT | Y | Y | Y | Y | Y | Y | Y | . | . |
| GPT-NeMo | Y | Y | Y | . | . | . | . | . | . |
| GPT-NeoX | Y | Y | Y | . | . | . | . | . | Y |
| InternLM | Y | Y | Y | . | Y | Y | Y | . | . |
| LLaMA | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| LLaMA-v2 | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| LLaMA-v3 | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| Qwen | Y | Y | Y | . | Y | Y | Y | Y | Y |
W8A16、W4A16:
Activation都是FP16(或BF16); Weight是INT8、INT4,在计算前反量化为FP16(或BF16),FP16*FP16-->FP16;
只是使显卡里塞入了size更大的模型;
并没有加快计算(反而因为dequantize weight从INT到FP16,变慢些)
SmoothQuant: (W8A8)
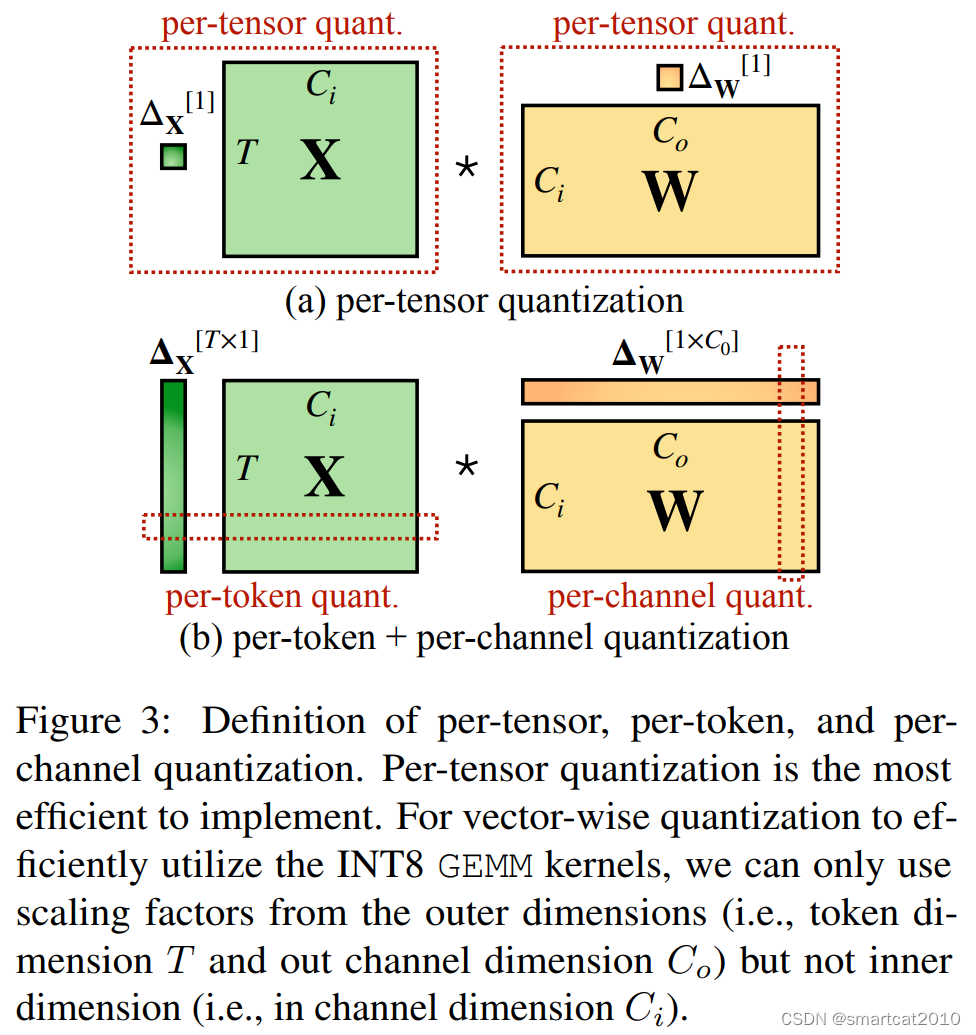
惯例做法,是对Activation的行(Token)和Weight的列(Output channel),进行量化;
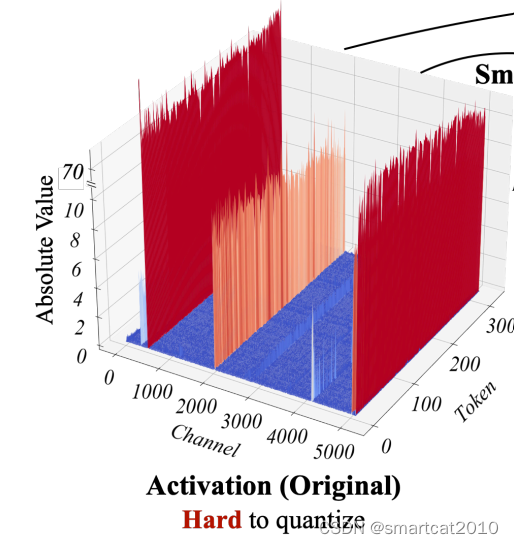
观察到的现象:weights矩阵,没有尖刺;activation矩阵,某几列(channel)是尖刺,而且明显能区分尖刺列和非尖刺列,尖刺列所有行(token)的值都大,非尖刺列所有行的值都小;
如果按照Activation的列进行量化,Gemm矩阵乘法不支持;
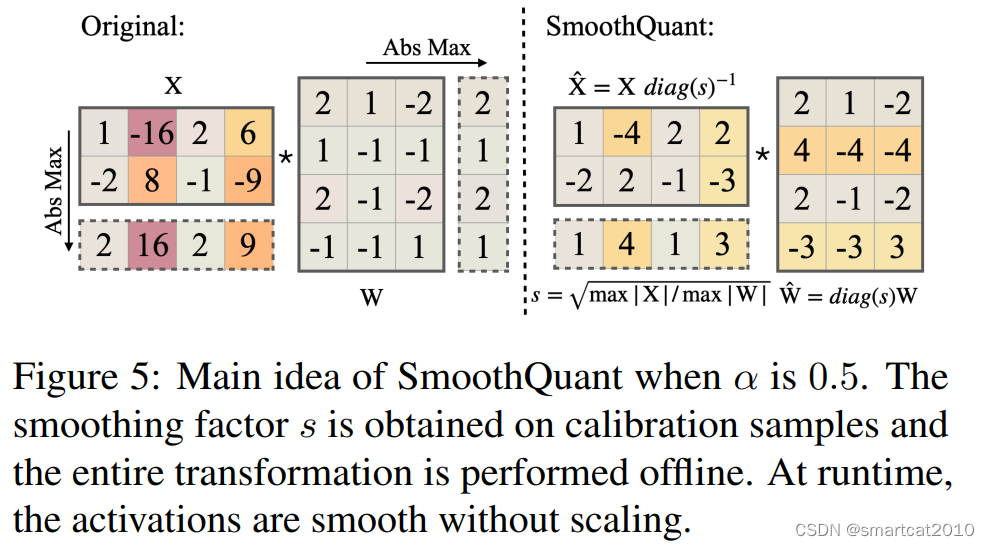
解决方案:对Activation的"尖刺"列,缩小N倍,对Weight的相应行,增大N倍;二者仍分别用老的Per-Token、Per-Channel来量化;
--gemm_plugin int8 : 使用指定的dtype去计算矩阵乘法,用的是加速库;
--gpt_attention_plugin int8 : 优化key-value cache;"use of efficient CUDA kernels for computing attention scores and values, reducing computation and memory overhead compared to the standard implementation." 看不懂:"It allows in-place update of the key-value (KV) cache used for attending to previous tokens, eliminating the need for explicit concatenation operations and further reducing memory consumption"