目录
前言
在开始今天的博客内容之前,正在看博客的您先来看看以下这两条sql,如果您刚好还有MySQL的环境。不妨先猜测一下它输出的内容,然后看看是否有什么区别?第一条sql如下:
sql
select length('G30L3B01') as l1;接着再来看另一条sql,sql脚本如下:
sql
select length('G30L3B01') as l2;各位不妨猜测一下,上面两条sql语句的执行结果l1和l2分别是多少?是不是在你的预料之中。 这里不卖关子了,相信执行过sql的朋友一定看到了结果。没有数据库客户端的朋友来看我的执行结果。在给出结果之前,首先把基础环境介绍一下。这里的服务器用的的个人的Windows 7 专业版开发机,数据库服务用的是MySQL5.7,打开的查询服务窗口所在的数据库编码是UTF-8。
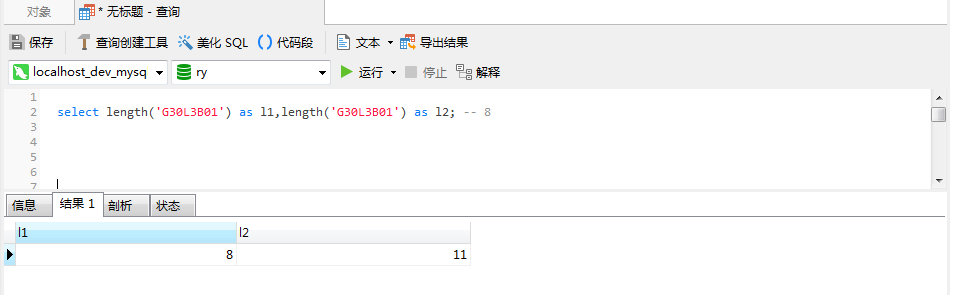
上面这个结果有没有超出你的预想,这两个字符串"看"起来似乎是一模一样的。这里的"看"我打了引号,至于原因,后面会讲到。本文即以上述场景为例,讲解在MySQL中,为什么会有这种"看"起来一致,但实际上不一样的问题,通过现象找本质,通过一步一步的排查,找到问题的根源,最后在寻根溯源后,找解决的办法;从应用代码编程的角度和底层数据库的角度来解决上述问题。如果您现在也遇到了这种"看"起来不正常的值,不妨一起交流一下。
一、问题的由来
首先依然要介绍一下上述问题的出现场景,以便于其它的朋友在此情此景下,有更大的印象。因此本节首先将对问题的场景进行详细的描述。这里打算从两个方面讲述,第一个方面是讲述需求背景,即在什么情况下作这个事。第二个是讲述数据背景,把相关的表设计也说明一下。
1、需求背景
事情发生的背景是这样的,客户要求我们做一个功能,他们会提供一个数据的Excel模板,然后我们需要将这些数据批量导入到数据库中。这个需求咋一看起来,是一个非常简单的需求啊。读取Excel的依赖库,一大把。解析Excel的数据,然后批量插入到数据库中,对于MybatisPlus或者其它的ORM工具都是非常简单的事。当时我们选择的是阿里巴巴开源的读取Excel的组件。感兴趣的朋友可以自己上github搜索一下。然后也基于组件也已经将Excel没个表格都读取到了内存中,然后调用MP的批量插入方法,意外的是在进行批量插入的时候数据库报错了。下面还是将数据库的表先做一个介绍。
2、数据表结构
为了实现将数据导入到数据库中,根据面向对象的原则,我们将Excel表格中的每个单元格都设计成了一个字段,然后对字段的数据类型进行了设计,同时包括数据长度。其中有一个项是输入数据的编码,然后用户是有编码规则的,每一个数据都有一个对应的编码规则。我们简单的看了他们的编码规则,得知其长度大致为8位,因此我们在数据库中设计成了varchar(8);这么设计其实是中规中矩的,非常合理。然而在上面的批量入库过程中就一直报对应的这个字段too long。这个异常看起来很奇怪,因为我们人工去"看"的时候,这个字符串的长度确实是8。于是陷入了沉思。
二、定位问题
既然在开发过程当中出现了问题,那么如何解决问题呢?在解决问题之前,首先要定位问题,只有正确的定位问题,才能对症下药,问题才能迎刃而解。因此本节将重点讲解怎么定位问题。
1、初步的问题
当看到上面问题的时候,第一感觉是懵的,刚开始都有点不敢相信自己的眼睛。因为肉眼根本"看"不出来这个字符串居然不是8位。最开始怀疑的是在字符串的前后可能存在空格,因此导致了其长度超出了8位。为此我们将数据进行去空,使用sql进行去空如下:
sql
SELECT length('G30L3B01') AS VisibleLength,
length(replace('G30L3B01', '', '')) AS CleanLength;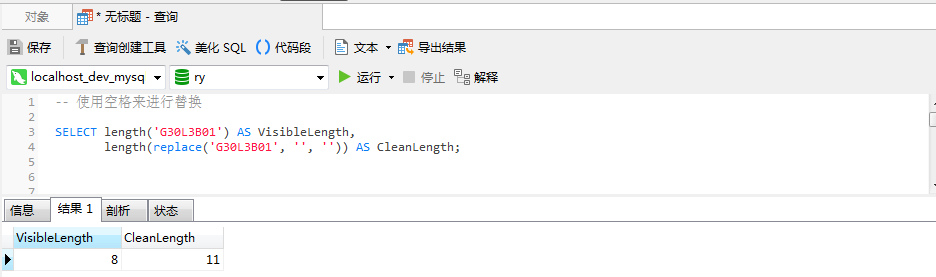
然后发现还是不对,经过替换后其长度还是11,说明还是超长了。
2、编码是否有问题
在进行空字符过滤之后还是没有解决问题。于是换了一个方向,想着有没有可能是字符集的问题。其实大家可以看看UTF-8的字符集规范,字符集虽然会有一定的影响,但是这里存储的都是英文和数字,其长度均是标准的1,因此不存在字符的问题。问题一下子没有了方向,不知道往哪个方面去排查。
3、依然回到字符本身
在第一次尝试了空字符替换无果,又排除了字符编码的问题后,再一次将目光投入到字符本身。这一次的想法是,虽然空字符本文替换后,长度还是11,但是这并不说明其内容一定是空格。有没有什么其它的东西在捣乱呢。有时候找问题就是这样,反反复复。
三、深入字符本身
上面从几个方面分析了可能存在的问题,尤其是第三点,我们从最开的字符又回到了起点。那么这次采用什么分析思路呢?本小节深入道来。
1、回归本质
为了来看看这个数据到底是什么?我们将字符串转为十六进制的字符串,通过比较原始字符串来看看区别。在MySQL中可以使用HEX(str)实现转换。相关的转换SQL如下所示:
sql
SELECT HEX('G30L3B01') AS hex_representation,HEX('G30L3B01') as n2;
hex_representation n2
4733304C33423031 4733304C33EFBBBF423031不知道眼尖的你发现了问题没有,上面这条SQL执行完之后发现,其目标字符串似乎不一样啊。后面的字符串,也就是有问题的字符串其长度真的超长了。下面仔细对比这两个字符串。
sql
4733304C33 423031
4733304C33 EFBBBF 423031为了方便展示,我把相同的部分进行对比,我们发现,前面的字符经过十六进制的转换后,一共16个字节,8位。是符合我们的预期的,而下面的十六进制字符则多了6字节,一共22字节,记11位。这也就是为什么这两个字符串不一样的原因。那么这个多出来的EFBBBF又是什么呢?由于这是转成了十六进制的表示,我们需要将其转为十进制。将十六进制转十进制,如果不想计算的朋友可以在网页中直接搜索:
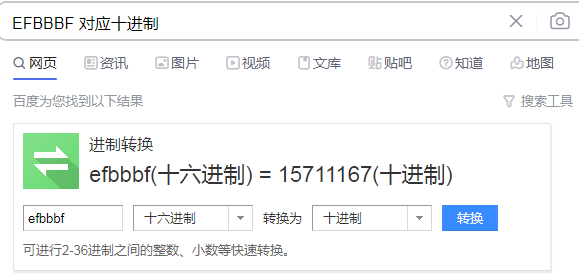
当然你也可以在MySQL中进行进制转换,转换方法如下:
sql
-- CONVERT(CONV('EFBBBF', 16, 10), UNSIGNED) 是在mysql中实现将16进制转10进制数据
select length(char(15711167)),hex(char(15711167)),CONVERT(CONV('EFBBBF', 16, 10), UNSIGNED);执行之后,可以看到:
java
length(char(15711167)) hex(char(15711167)) CONVERT(CONV('EFBBBF', 16, 10), UNSIGNED)
3 EFBBBF 15711167到这里,为什么两个"看"起来一模一样的字符串,实际上不一样呢?根源就在这里,在字符串的中间位置插入了不可见字符。就是这不可见字符EFBBBF导致我们做数据插入时报too long。
2、数据库解决之道
在明确了以上的问题所在之后,我们就可以根据实际情况来进行调整。只要将这种不可见字符替换掉即可。实现的方式也很简单,sql如下:
sql
select length(REPLACE('G30L3B01', CHAR(15711167),'')) t;
t
8通过replace函数就实现了不可见字符EFBBBF的去除,这样再调用Insert语句,就不会报too long的问题。
3、代码层解决
除了在数据库层来解决问题,还可以在什么地方解决呢?在编码层解决是否可行。答案是肯定的。下面我们来详细介绍一下代码层的处理办法,以java语言为例。其实原理是一样的,都是要将不可见字符进行替换掉。
java
/*
* 字节数组转16进制字符串
*/
public static String bytesToHexString(byte[] bArr) {
if (bArr == null) {
return null;
}
StringBuffer sb = new StringBuffer(bArr.length);
String sTmp;
for (int i = 0; i < bArr.length; i++) {
sTmp = Integer.toHexString(0xFF & bArr[i]);
if (sTmp.length() < 2)
sb.append(0);
sb.append(sTmp);
}
return sb.toString();
}
// 转化十六进制编码为字符串
public static String toStringHex(String s) {
byte[] baKeyword = new byte[s.length() / 2];
try {
for (int i = 0; i < baKeyword.length; i++) {
baKeyword[i] = (byte) (0xff & Integer.parseInt(s.substring(i * 2, i * 2 + 2), 16));
}
s = new String(baKeyword, "utf-8");// UTF-16le:Not
} catch (Exception e1) {
e1.printStackTrace();
}
return s;
}下面给出测试代码,您可以实际测试以下结果,看是否与我的预期一样:
java
public static void main(String[] args) {
System.out.println("G8014Z03".substring(0, 2));
System.out.println(bytesToHexString("G30L3B01".getBytes()).toUpperCase()); // 长
System.out.println(bytesToHexString("G30L3B01".getBytes()).toUpperCase()); // 短
System.out.println("G30L3B01".length()); // 长
System.out.println("G30L3B01".length()); // 短
System.out.println("进制转换======================================================");
System.out.println(toStringHex("4733304C33423031"));
System.out.println(toStringHex("4733304C33423031").length());
System.out.println(toStringHex("4733304C33EFBBBF423031"));
System.out.println(toStringHex("4733304C33EFBBBF423031").length());
System.out.println("================================================");
System.out.println(toStringHex("4733304C33EFBBBF423031".replaceAll("EFBBBF", "")));
System.out.println(toStringHex("4733304C33EFBBBF423031".replaceAll("EFBBBF", "")).length());
System.out.println("G30L3B01".equals("G30L3B01"));
System.out.println(toStringHex("4733304C33EFBBBF423031".replaceAll("EFBBBF", "")).equals("G30L3B01"));
}在代码中使用上述代码也可以实现目标字符的替换,将不可见字符进行替换掉。欢迎在实践中进行测试使用。
四、总结
以上就是本文的主要内容,本文以数据库中不可见字符处理为例,讲解在MySQL中,为什么会有这种"看"起来一致,但实际上不一样的问题,通过现象找本质,通过一步一步的排查,找到问题的根源,最后在寻根溯源后,找到解决的办法;从应用代码编程的角度和底层数据库的角度来解决上述问题。
使用建议,如果您也有这方面的问题,尤其是从Excel或者其它的模板中导入数据的,很有可能会遇到这个问题。如果碰到看起来一致,但实际内容不一样的情况,可以试试看是不是碰到了不可见字符,本文即分享了一种在MySQL中的不可见字符的解决方案,同时分享了使用JAVA语言进行上述问题的解决。本文行文仓促,难免有不足之处,欢迎各位专家朋友在评论区批评指正,不慎感激。