目录
[Seata 介绍](#Seata 介绍)
[Seata 术语](#Seata 术语)
[Seata AT 模式](#Seata AT 模式)
[部署 Seata](#部署 Seata)
[实现 RM](#实现 RM)
[实现 TM](#实现 TM)
[1. Seata 部署成功,服务启动成功,全局事务不生效](#1. Seata 部署成功,服务启动成功,全局事务不生效)
[2. 服务启动报错 can not get cluster name in registry config 'service.vgroupMapping.xx', please make sure registry](#2. 服务启动报错 can not get cluster name in registry config ‘service.vgroupMapping.xx‘, please make sure registry)
[debug 调试](#debug 调试)
[RM & TM 如何与 TC 建立连接](#RM & TM 如何与 TC 建立连接)
[AT 模式如何避免脏写和脏读](#AT 模式如何避免脏写和脏读)
项目地址:GitHub - chenyukang1/mall
本文实战基于如下版本:
JDK 8
Spring Boot 2.6.11
Spring Cloud 2021.0.4
Spring Cloud Alibaba 2021.0.4.0
Seata 1.5.2
Seata 介绍
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案
-
对业务无侵入:即减少技术架构上的微服务化所带来的分布式事务问题对业务的侵入
-
高性能:减少分布式事务解决方案所带来的性能消耗
源码:https://github.com/seata/seata(opens new window)
文档:Apache Seata
Seata 术语
TC (Transaction Coordinator) 事务协调者 :维护全局和分支事务的状态,驱动全局事务提交或回滚
TM (Transaction Manager) 事务管理器:开始全局事务、提交或回滚全局事务
RM (Resource Manager) 资源管理器:管理分支事务处理的资源,与 TC 交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚

Seata AT 模式
介绍
AT 模式是 Seata 创新的一种非侵入式的分布式事务解决方案,Seata 在内部做了对数据库操作的代理层,我们使用 Seata AT 模式时,实际上用的是 Seata 自带的数据源代理 DataSourceProxy,Seata 在这层代理中加入了很多逻辑,比如插入回滚 undo_log 日志,检查全局锁等
在 AT 模式下,用户只需关注自己的业务SQL,用户的业务SQL 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作
实战(nacos注册中心,db存储)
部署 Seata
完成 db 建表,nacos 发布 seataServer.properties 配置,最后启动 seata,参考:Docker compose部署 | Apache Seata
实现 RM
-
创建订单和库存服务的 DB 和表
-- 库存服务DB执行
CREATE TABLEtab_storage(
idbigint(11) NOT NULL AUTO_INCREMENT,
product_idbigint(11) DEFAULT NULL COMMENT '产品id',
totalint(11) DEFAULT NULL COMMENT '总库存',
usedint(11) DEFAULT NULL COMMENT '已用库存',
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTOtab_storage(product_id,total,used)VALUES ('1', '96', '4');
INSERT INTOtab_storage(product_id,total,used)VALUES ('2', '100','0');-- 订单服务DB执行
CREATE TABLEtab_order(
idbigint(11) NOT NULL AUTO_INCREMENT,
user_idbigint(11) DEFAULT NULL COMMENT '用户id',
product_idbigint(11) DEFAULT NULL COMMENT '产品id',
countint(11) DEFAULT NULL COMMENT '数量',
moneydecimal(11,0) DEFAULT NULL COMMENT '金额',
statusint(1) DEFAULT NULL COMMENT '订单状态:0:创建中;1:已完成',
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; -
各数据库加入
undo_log表CREATE TABLE
undo_log(
idbigint(20) NOT NULL AUTO_INCREMENT,
branch_idbigint(20) NOT NULL,
xidvarchar(100) NOT NULL,
contextvarchar(128) NOT NULL,
rollback_infolongblob NOT NULL,
log_statusint(11) NOT NULL,
log_createddatetime NOT NULL,
log_modifieddatetime NOT NULL,
extvarchar(100) DEFAULT NULL,
PRIMARY KEY (id),
UNIQUE KEYux_undo_log(xid,branch_id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; -
编写业务代码
实现创建订单 & 锁库存逻辑
public boolean save(long userId, long productId) {
OrderEntity orderEntity = new OrderEntity();
orderEntity.setUserId(userId);
orderEntity.setProductId(productId);
orderEntity.setCount(1);
orderEntity.setMoney(BigDecimal.valueOf(80));
orderEntity.setStatus(0);
return save(orderEntity);
}
public boolean lockStock(long productId, long used) {
return storageDao.lockStock(productId, used) > 0;
}
<update id="lockStock">
UPDATE tab_storage
SET used = used + #{num}
WHERE
product_id = #{productId}
AND total - used >= #{num}
</update>实现 TM
TM 作为事务全局管理者,也是全局事务的发起者,通过远程调用订单和库存服务,开启全局事务
-
编写 Feign 远程调用
-
开启全局事务
@GlobalTransactional(timeoutMills = 300000) @GetMapping("/submitOrder") public R submitOrder(long userId, long productId, long used) { businessService.submitOrder(userId, productId, used); return R.ok().put("res", "success"); } @Override public void submitOrder(long userId, long productId, long used) { log.info("submitOrder begin ... xid: {}", RootContext.getXID()); R lockStock = storageFeignService.lockStock(productId, used); boolean lockRes = (boolean) lockStock.get("res"); if (!lockRes) { throw new RuntimeException("lock stock fail"); } R save = orderFeignService.save(userId, productId); boolean saveRes = (boolean) save.get("res"); if (!saveRes) { throw new RuntimeException("save order fail"); } }
可能遇到的问题
1. Seata 部署成功,服务启动成功,全局事务不生效
首先检查是否有全局事务 ID xid,请求的时候会通过请求头传递到下游服务,没有这个一切白搭。可以直接在全局事务的入口打印出来看看,代码示例:
log.info("submitOrder begin ... xid: {}", RootContext.getXID()); 如果全局事务 ID 为 null,可能的原因有:
- 版本问题:如果选用较低版本的 Seata(比如v1.5.2),适当降低 Spring Boot、Spring Cloud、Spring Cloud Alibaba 的配套版本,实在不确定可以参考文章开头我的版本配置
2. 服务启动报错 can not get cluster name in registry config 'service.vgroupMapping.xx', please make sure registry
这个报错是因为 TM/RM 的 service.vgroupMapping.xx 配置与 Seata Server 的不一致,可以按如下方式排查:
- TM/RM 配置指定了事务群组

- 服务端有对应的配置(以 nacos 为例)

-
TM/RM 的 nacos 注册中心必须和 Seata 在同一 namespace、同一 group(默认是 SEATA_GROUP) 下
-
Seata 使用 nacos 部署,它读的配置默认是 seataServer.properties,而 TM/RM 的配置要通过官方提供的脚本发布到 nacos 与 Seata 同一命名空间下 ,推荐阅读:Nacos 配置中心 | Apache Seata
debug 调试
我们在全局事务开启后,结束前打断点,看看数据库发生了什么
undo_log
发现 RM 的 undo_log 表中都生成了一条记录,以库存表为例,字段的数据如下
{"@class":"io.seata.rm.datasource.undo.BranchUndoLog","xid":"116.198.200.0:8091:45570721124696075","branchId":45570721124696077,"sqlUndoLogs":["java.util.ArrayList",[{"@class":"io.seata.rm.datasource.undo.SQLUndoLog","sqlType":"UPDATE","tableName":"tab_storage","beforeImage":{"@class":"io.seata.rm.datasource.sql.struct.TableRecords","tableName":"tab_storage","rows":["java.util.ArrayList",[{"@class":"io.seata.rm.datasource.sql.struct.Row","fields":["java.util.ArrayList",[{"@class":"io.seata.rm.datasource.sql.struct.Field","name":"id","keyType":"PRIMARY_KEY","type":-5,"value":["java.lang.Long",2]},{"@class":"io.seata.rm.datasource.sql.struct.Field","name":"used","keyType":"NULL","type":4,"value":44}]]}]]},"afterImage":{"@class":"io.seata.rm.datasource.sql.struct.TableRecords","tableName":"tab_storage","rows":["java.util.ArrayList",[{"@class":"io.seata.rm.datasource.sql.struct.Row","fields":["java.util.ArrayList",[{"@class":"io.seata.rm.datasource.sql.struct.Field","name":"id","keyType":"PRIMARY_KEY","type":-5,"value":["java.lang.Long",2]},{"@class":"io.seata.rm.datasource.sql.struct.Field","name":"used","keyType":"NULL","type":4,"value":46}]]}]]}}]]}- xid:全局事务 id
- branchId:分支事务 id
- beforeImage:事务前快照
- afterImage:事务后快照
branch_table
TC 的 branch_table 新增两条记录,表示开启两个分支事务
global_table
global_table 新增一条记录,表示开启一个全局事务
lock_table
lock_table 新增两条记录,表示两个 RM 一阶段开启了事务,但事务未提交,都持有行锁
原理
RM & TM 如何与 TC 建立连接
在启动阶段,RM/TM 会在控制台打出注册信息,即与 TC 建立了连接
NettyPool create channel to transactionRole:TMROLE,address:116.198.200.0:8091,msg:< RegisterTMRequest{applicationId='seata-server', transactionServiceGroup='business-tx-service-group'} >不难看出,它们之间的通信基于 Netty,Netty 作为一款高性能的 RPC 通信框架,保证了 TC 与 RM 之间的高效通信
但它又是怎么区分 RM 还是 TM 的?毕竟配置文件都一样。答案是 @GlobalTransactional 注解,这个注解表示开启全局事务,Seata 认为标注这个注解的客户端就是 TM,这类注解都是基于 Spring AOP 机制,对使用了注解的 Bean 方法分配对应的拦截器进行增强,来完成对应的处理逻辑。而 GlobalTransactionScanner 这个 Spring Bean,就承载着为各个注解分配对应的拦截器的职责
推荐阅读:Seata应用侧启动过程剖析------RM & TM如何与TC建立连接 | Apache Seata
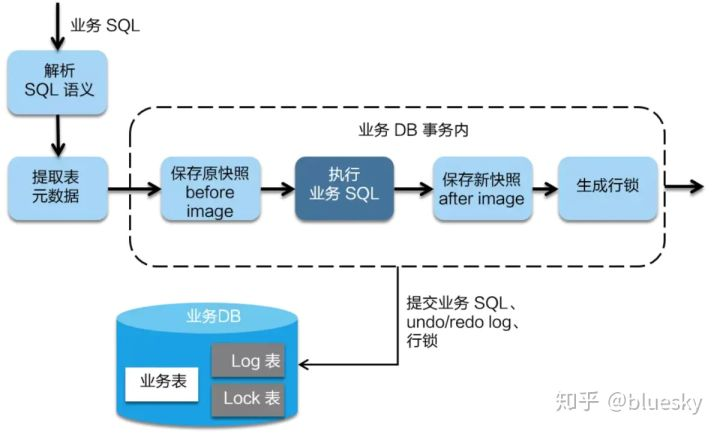
一阶段步骤
- RM 写表的过程,Seata 会拦截业务 SQL,首先解析 SQL 语义
- 在业务数据被更新前,做一次快照,生成 beforeImage
- 执行业务 SQL
- 在业务数据更新之后,做一次快照,生成 afterImage,最后生成行锁
以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性
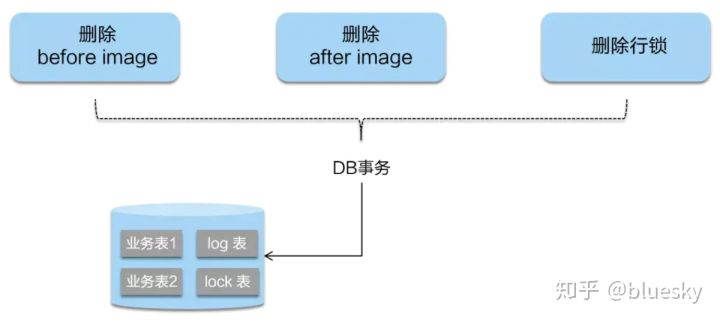
二阶段步骤
因为业务 SQL 在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可
- 正常:TM 执行成功,通知 TC 全局提交,TC 此时通知所有的 RM 提交成功,删除 undo_log 回滚日志
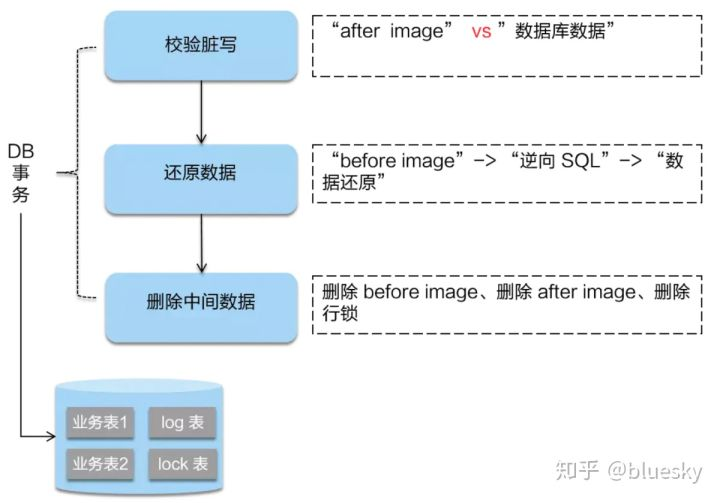
- 异常:TM 执行失败,通知 TC 全局回滚,TC 此时通知所有的 RM 进行回滚,根据 undo_log 反向操作,使用 beforeImage 还原业务数据,删除 undo_log。但在还原前要首先要校验脏写,对比 "数据库当前业务数据" 和 "afterImage",如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写会按配置的策略处理
AT 模式如何避免脏写和脏读
推荐阅读:Seata AT 模式 | Apache Seata
总结
优点:
- 无侵入性:本质上是通过代理数据源实现 2PC 模式,对业务无侵入性,开发成本低
缺点:
- 不适合高并发场景:AT 模式的实现依赖数据库锁机制,本地事务依赖行锁来实现读写隔离,以电商中常见的提交订单业务为例,提交订单的业务流程涉及到创建订单,锁库存等等,订单是用户维度的数据,并发度不高;但库存记录是 sku 级别的,加行锁很容易让后续的读写请求都阻塞