目录
前言
在某次摸鱼的过程中,老大突然后面冒出来说要做一个拉取文件到本地的需求(写的时候疯狂回头🤡),当时心想这简单,不就一个HttpClient或者RestTemplate的事情嘛,很快一两天就给整出来心满意足的提交了。
不出意外的话要出意外了,老大看了一眼我的代码就问:"你没有做断点续传吗",我:"啊?"(好吧得加班了)
因为当时我还没有玩过断点续传,老大就和我提了一嘴可以考虑使用Range请求头来实现,在我巴拉巴拉的有一两天后,最终断点续传版本的网络文件下载功能就出来了(工具类加一✔)
省流:本文章除了断点续传的视线,还发散介绍了Range请求头和一些零零散散的其他小东西,不感兴趣的小伙伴可直接跳至"断点续传下载实现"。
1、Range请求头
1.1、概述
顾名思义,HTTP/1.1 Range请求头代表发送范围获取数据的请求,要求服务器仅向客户端回传HTTP消息的一部分,格式以及示例如下:
shell
Range: <数据格式>=<数据开始的索引位置>-<数据结束的索引位置>
# 1. 请求从0至500的byte数据:
Range: bytes=0-500
# 2. 请求第500个byte以后的全部数据:
Range: bytes=501-
# 3. 请求最后500个byte的数据:
Range:bytes=-500
# 4. 请求多个分段时,各分段以,分割:
Range: bytes=0-100,101-2001.2、使用限制
正是得益于Range请求头的这种特性,因此在很多断点续传的场景下都能看到它的身影,但在使用之前需要确定我们的请求中能否使用该请求头。
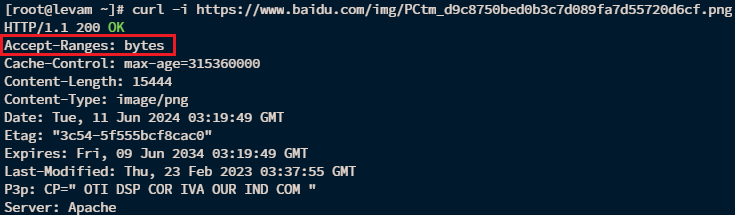
不知道大家伙有没有发现前面提及Range请求头的时候,我添加上了一个前缀"HTTP/1.1",这是因为只在 HTTP/1.1(RFC2616) 之上,才支持范围请求 。所以如果客户端或者服务端两端的某一端低于 HTTP/1.1,我们就不应该使用范围请求的功能。我们可以通过 curl -i命令来测试一下是否支持范围请求:
shell
curl -i https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png如果 HTTP 响应中存在 Accept-Ranges 标头,并且其值不是 none,那么该服务器支持范围请求。
1.3、范围请求
当我们确定可以使用范围请求后,我们便可愉快的开始发起请求啦。这里以获取前1024bytes数据为例:Range 还有几种不同的方式来限定范围,可以根据需要灵活定制:
500-1000:指定开始和结束的范围,一般用于多线程分片下载。500-:指定开始区间,一直传递到结束。这个就比较适用于断点续传、或者在线播放等等。-500:无开始区间,只意思是需要最后 500 bytes 的内容实体。100-300,1000-3000:指定多个范围,这种方式使用的场景很少,了解一下就好了。
shell
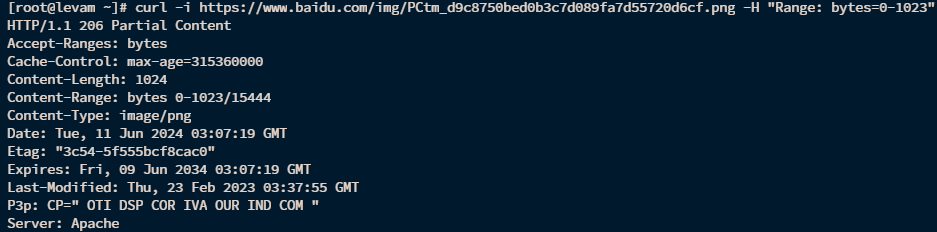
curl -i https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png -H "Range: bytes=0-1023"在响应中我们可以很明确看到206响应码和Content-Range范围响应数据:
- HTTP 206 Partial Content 成功状态响应代码表示请求已成功,进一步了解可查看206 Partial Content - HTTP | MDN
- Content-Range标记当前传递的内容实体范围和总长度,单位是bytes
1.4、预防资源变更
我们在网上偶尔也会发现一个现象:下载大尺寸资源的时候,偶尔中间暂停过再重新下载,资源又重头开始了下载。这看似断点续传功能失效了,但实际上并不一定,可能是在这期间该资源发生了变更。
针对以上情况,可以使用If-Range请求头标记创建具有条件的范围请求,条件没有得到满足,服务器将返回完整的资源以及 200 OK 状态。
进一步了解可查看If-Range - HTTP | MDN
2、断点续传下载实现
2.1、流程设计
基于前面对Range请求头及与其相关内容的分析,假设现在需要下载uTools工具(打钱Please💰),借助Range实现断点续传下载的流程设计如下:
- 获取下载地址链接;
- 获取文件的断点(起始点或续点);
- 设置Range及相关请求头;
- 下载完毕,标记文件完成(以重命名文件作标记)
叠甲:下面的代码实现是为了演示做了修改的代码,大家伙在实现时可根据具体情况具体实现,这里提供几个可更换的点:
- 记录最新修改时间可使用其它方式存储替代Map;
- 文件下载方式视情况而定;
- 文件下载完毕标记等......
2.2、代码实现
java
public class FileUtils {
public static void main(String[] args) {
FileUtils.processNetFile(
"https://open.u-tools.cn/download/uTools-5.0.0.exe",
"uTools-5.0.0.exe",
"F:\\download"
);
}
// 用于存放文件对应的最新修改时间
private static final Map<String, String> fileRangeModifiedMap = new HashMap<>();
/**
* 处理网络文件下载操作
* @author xbaoziplus
* @param downloadUrl 网络文件下载地址
* @param filename 文件名,含后缀
* @param storageDirectory 文件存储目录路径
* @createTime 2024/5/7 15:39
*/
public static void processNetFile(String downloadUrl, String filename, String storageDirectory) {
if (StringUtils.isAnyBlank(downloadUrl, filename)) {
throw new RuntimeException("param is blank");
}
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
HttpGet httpGet = new HttpGet(downloadUrl);
String filePath = storageDirectory + '/' + filename;
String tmpFilePath = storageDirectory + '/' + filename + ".downloading";
// 文件对象及断点位置初始化
File targetFile = new File(tmpFilePath);
long downloadedByte = 0;
if (targetFile.exists()) {
downloadedByte = targetFile.length();
} else {
if (!targetFile.getParentFile().exists()) {
targetFile.getParentFile().mkdirs();
}
targetFile.createNewFile();
}
// 如果文件存在且大小不为0,添加Range请求头
if (downloadedByte > 0) {
httpGet.addHeader("Range", "bytes=" + downloadedByte + "-");
if (fileRangeModifiedMap.get(filename) != null) {
httpGet.addHeader("If-Range", fileRangeModifiedMap.get(filename));
}
}
// 请求下载地址
HttpResponse response = httpClient.execute(httpGet);
// 获取并保存last-modified头值
String lastModified = response.getFirstHeader("Last-Modified").getValue();
fileRangeModifiedMap.put(filename, lastModified);
long contentLength = Long.parseLong(response.getFirstHeader("Content-Length").getValue()) + downloadedByte;
System.out.println("总大小:" + contentLength + " bytes");
try (InputStream is = response.getEntity().getContent();
RandomAccessFile raf = new RandomAccessFile(targetFile, "rwd")) {
// 将写文件指针移到文件尾。
raf.seek(downloadedByte);
// 设置每次磁盘写入最大1M
byte[] buffer = new byte[1024*1024];
int len;
while ((len = is.read(buffer)) != -1) {
raf.write(buffer, 0, len);
System.out.println("下载进度:" + raf.length() * 100 / contentLength + "%, " + raf.length() + '/' + contentLength + " bytes");
}
}
// 下载完成,重命名临时文件成正式文件
targetFile.renameTo(new File(filePath));
System.out.println("下载完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}2.3、运行结果
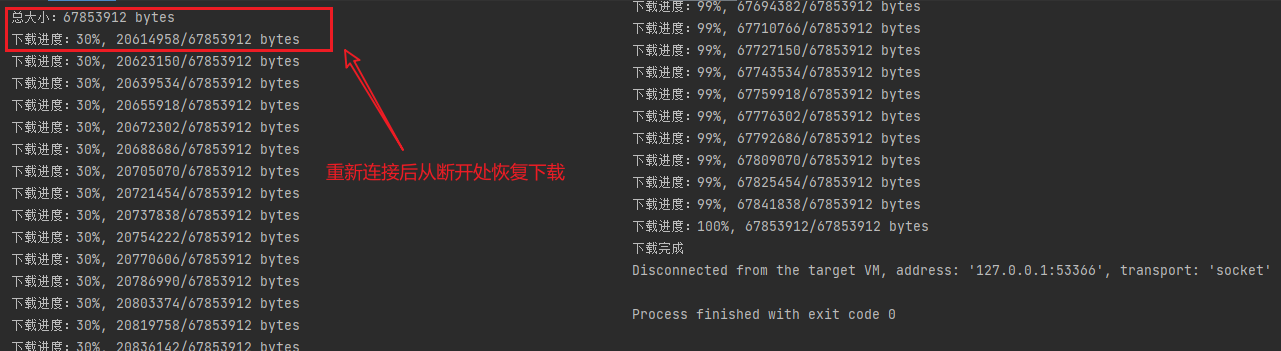
本地运行之后可自行打断重试,从而测试断点续传是否生效,以下是我这边断点续传的结果
图片做了裁剪拼接,左边是断点续传的起始截图,右边是程序结束截图,左右拼接得到的以下图片
3、RandomAccessFile
RandomAccessFile是Java I/O库 中的一个特殊类,不属于InputStream或OutputStream的子类,它支持对文件的随机访问读写,也就是说,可以访问文件的任意位置 。正因为这一特性,在代码中采用该类进行实现文件写入,通过seek()方法移动文件指针,而后将续传的内容拼接写入文件中。
该类的构造函数中可传入不同的运行模式:
r代表以只读方式打开指定文件 。rw以读写方式打开指定文件 。rws读写方式打开,并对内容或元数据都同步写入底层存储设备 。rwd读写方式打开,对文件内容的更新同步更新至底层存储设备 。
4、思维拓展
通过前面我们知道Range请求头可用于断点续传实现,这得益于Range请求头支持指定请求范围的特性,那么这个特性我们还能不能用于其它业务场景的视线呢?答案肯定是可以的。
比如现在有100w个静态资源文件链接需要检测该文件是否可用,即需要确定这些文件链接的可访问性,比较清晰明了的方法就是都请求一遍,若正常请求通了,那便是可访问的。
但这有一个问题,这些都是静态资源文件的链接,即他们的下载地址,那么当我们全部请求一遍之后,那就代表着我们对这100w个文件都进行了下载,这无疑是对服务器的带宽、内存和CPU等资源是一个巨大的开销。
这种情况下我们就可以使用Range请求头进行实现这种检测的需求,每次请求之前携带上Range请求头,内容为Range: bytes=0-1,这代表每一个链接我都只尝试获取1字节的内容,从而大大减少了网络流量的流通和性能的提高。