这里写自定义目录标题
逆向技巧
断点
-
普通断点
-
条件断点
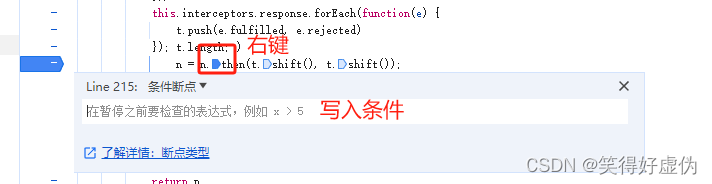
-
日志断点
-
XHR断点
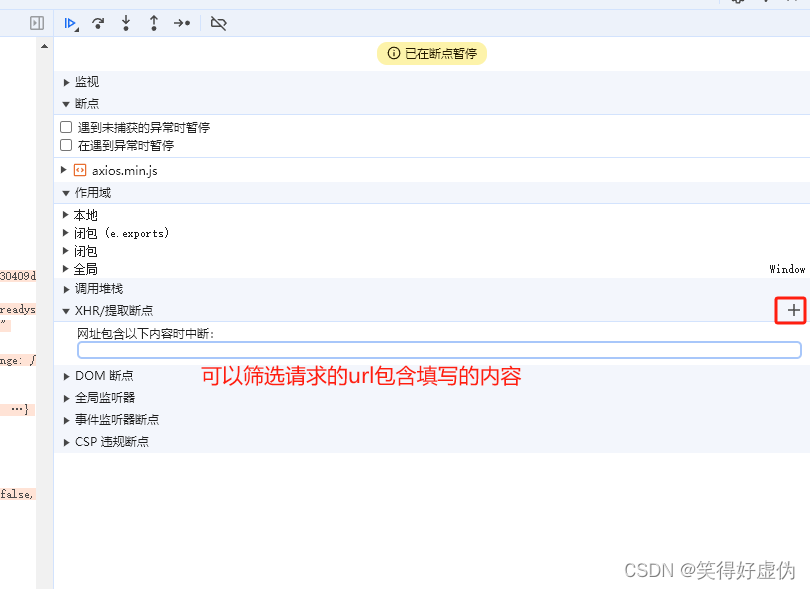
一 、请求入口定位
1. 关键字搜索
key关键字
方法关键字: encrypt decrypt
. headers关键字
路径关键字
interceptors:
interceptors.request.use(fn1)
interceptors.request.use(fn2)
interceptors.response.use(fn3)
interceptors.response.use(fn3)
n = n.then(t.shift(), t.shift());