Zookeeper部署
注意:该文章为简单部署操作,没有复杂的配置内容,用的是3.7.2版本。
下载安装包
进入zookeeper官网:
html
https://zookeeper.apache.org/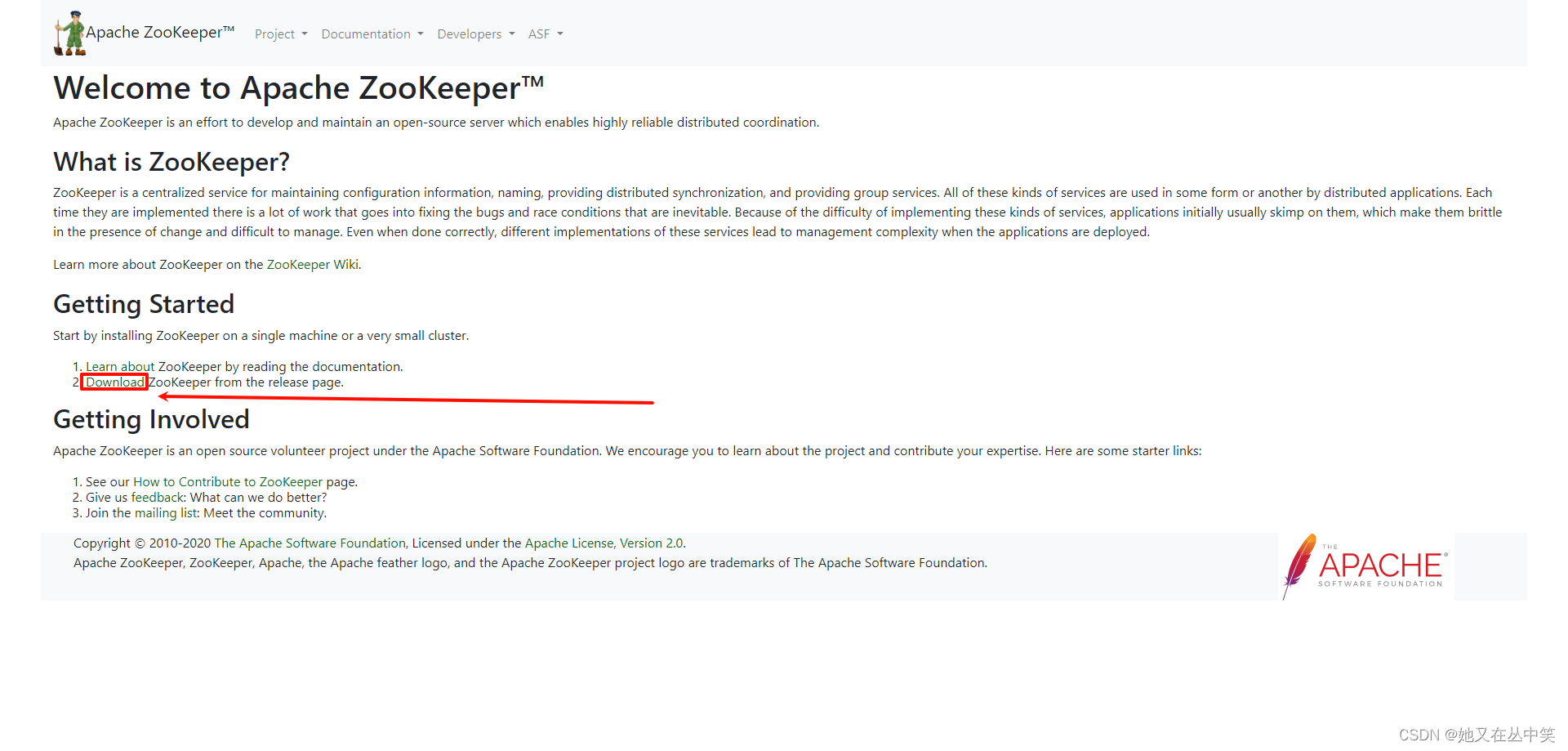
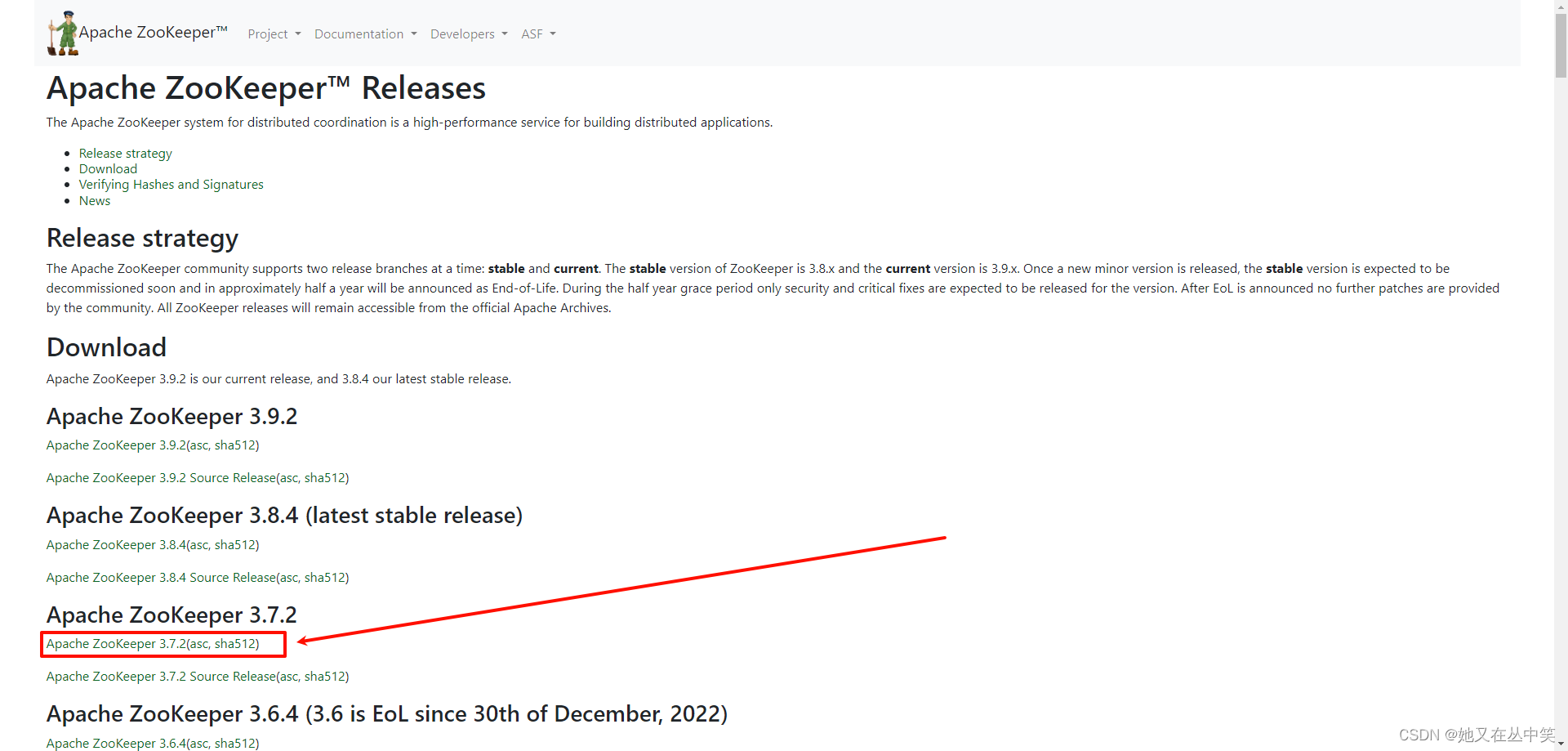
注意:要用这种不带source的bin安装包,这种是直接打包好的,但是source包是源码包,如果你有修改代码的需要那就下载这个。
Linux解压安装包
使用指令
shell
tar -zxvf apache-zookeeper-3.7.2-bin.tar.gz安装包解压后目录:
修改配置文件
进入目录下的conf目录,执行以下命令拷贝zoo_sample.cfg文件并重命名为zoo.cfg:
shell
cp zoo_sample.cfg zoo.cfg编辑zoo.cf配置
注意:以下为主要配置,其他配置按需添加。
txt
# zookeeper客户端连接的端口,默认为2181
clientPort=2189
# zookeeper默认管理端口,默认为8080
admin.serverPort=8083对于【admin.serverPort】配置,文件默认是没有的,如果出现下面的错误,那就得需要修改管理端口了。
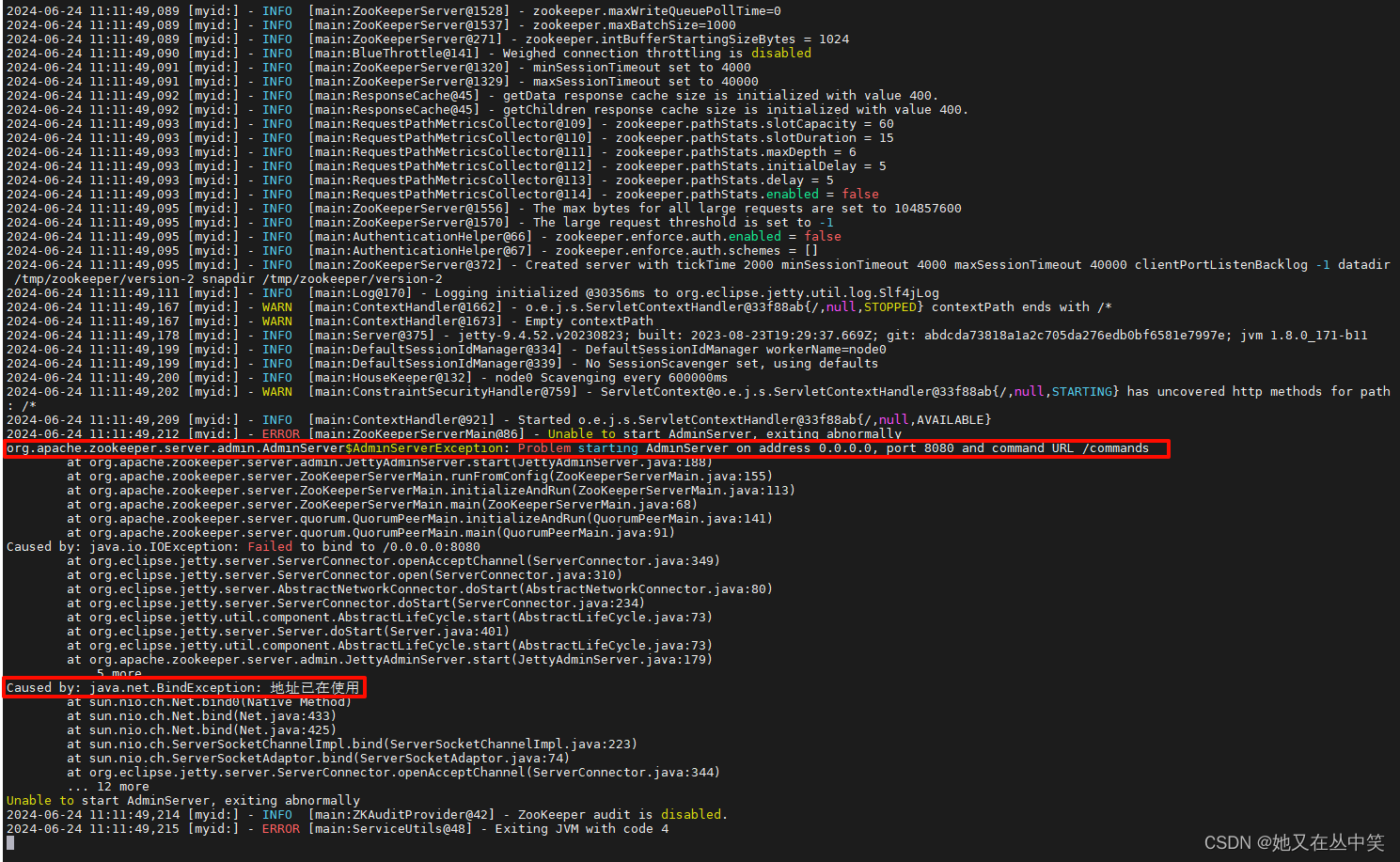
启动服务
进入bin目录,执行指令:
shell
./zkServer.sh start停止服务
进入bin目录,执行指令:
shell
./zkServer.sh stop常用zookeeper指令
执行以下指令,进入zookeeper客户端
shell
./zkCli.sh -server zookeeper服务ip:zoo.cfg客户端监听端口
例:./zkCli.sh -server localhost:2181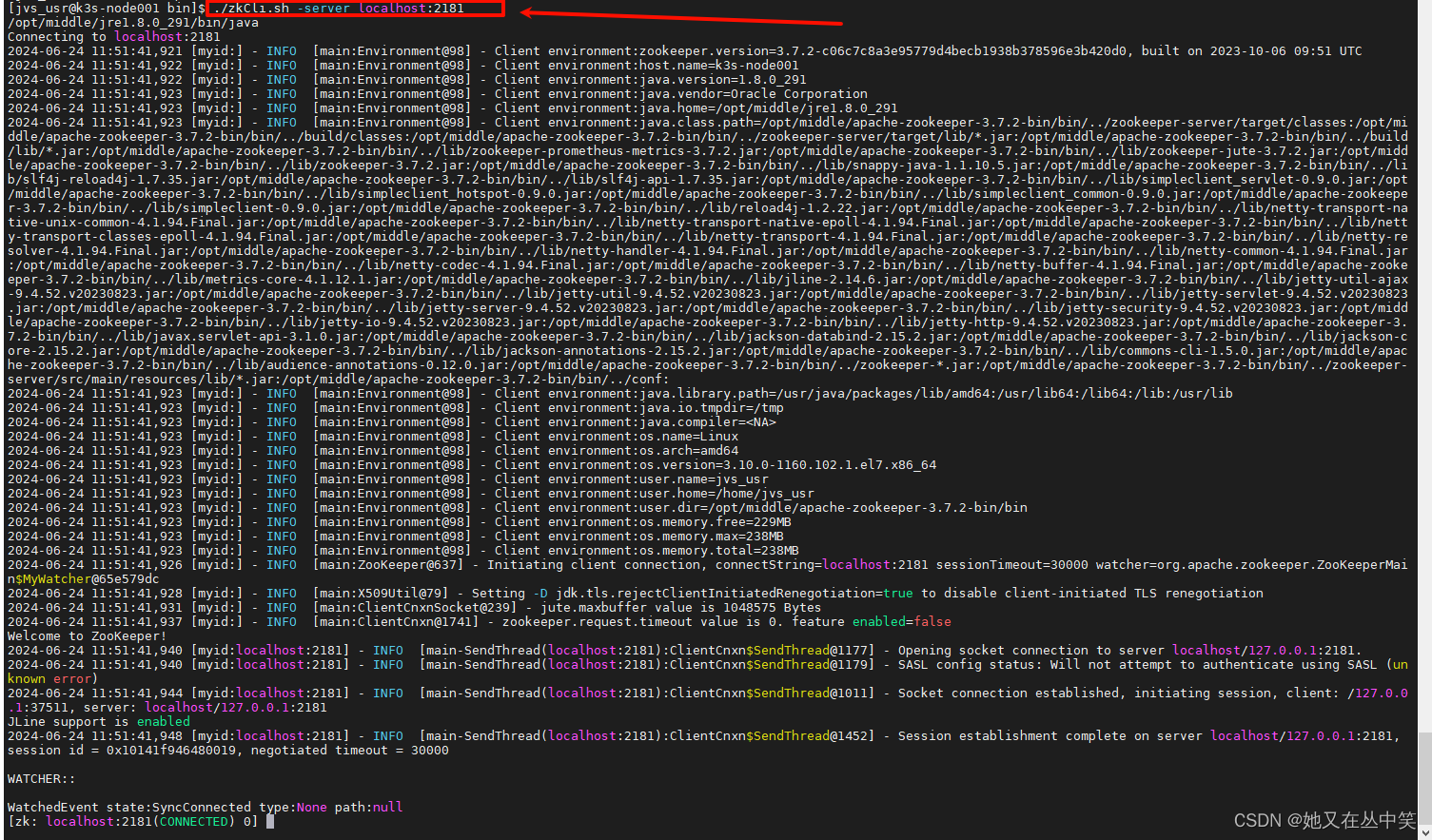
查看namespace列表
shell
ls /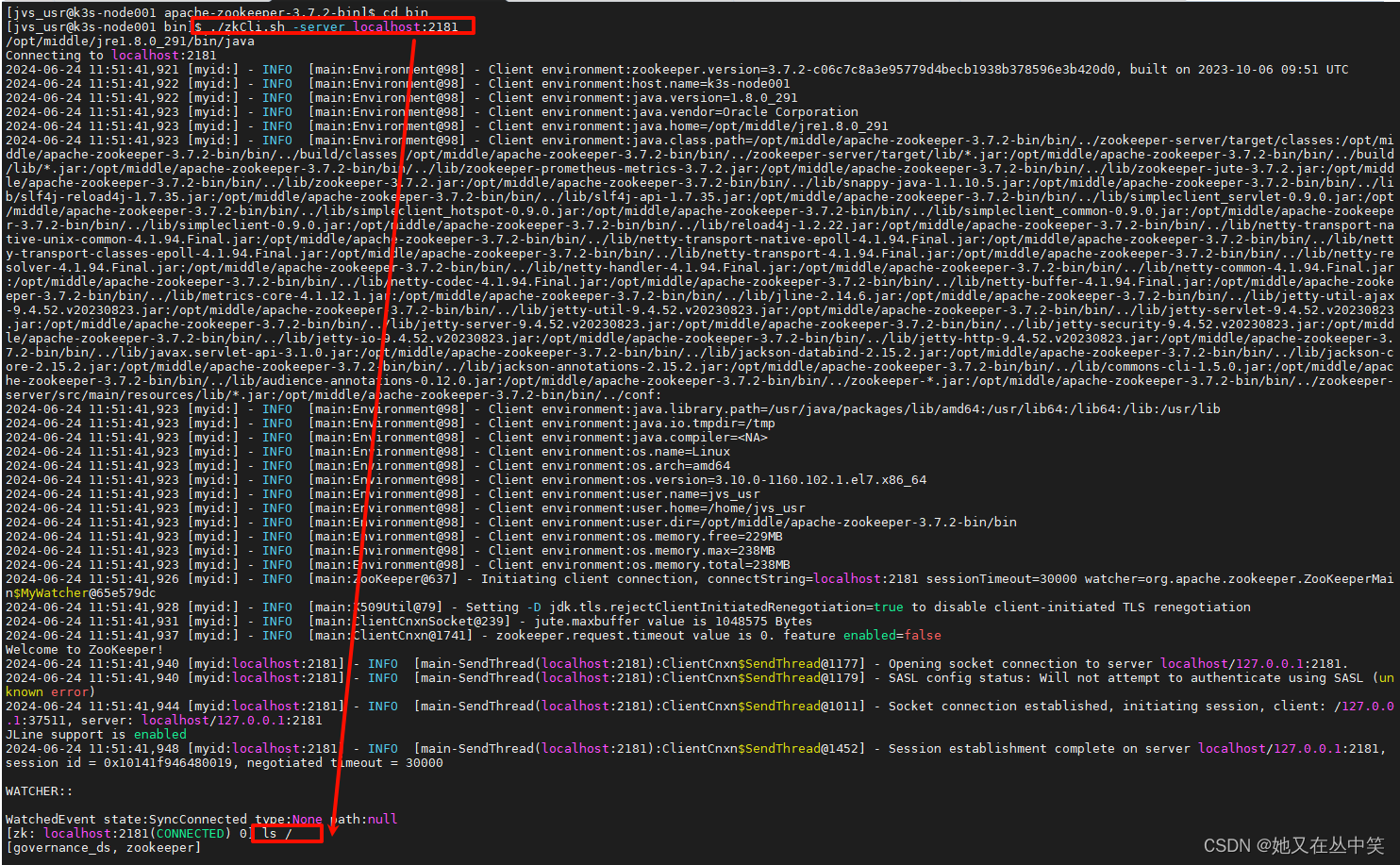
创建namespace
shell
create /test注意:上面指令的斜杠是必须的,不要省略。
删除namespace
shell
delete /test注意:上面指令的斜杠是必须的,不要省略。