正则表达式
Regular Express
【1】、三剑客与正则表达式
1、注意事项
- 正则符号都是英文符号,避免使用中文符号
- 推荐使用grep/egrep命令,默认设置了别名alias,自动加上颜色
【2】、符号概述
正则:regular expression (RE)
| 正则表达式regular expression | 符号 |
|---|---|
| 基础正则BRE | ^ $ . * .* \[\] \^ |
| 扩展正则ERE | | + () ? {} |
| 其他类型正则(Perl语言类型正则) |
【3】、基础正则
1、^ 以...开头
⚠️英文的符号
sh
[root@Ansible-server /]# grep '^root' /etc/passwd
root:x:0:0:root:/root:/bin/bash2、$ 以...结尾
sh
[root@Ansible-server /]# grep 'nologin$' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin❓为什么我看着文件中有但是却过滤不出来
文件明明是以"o"结尾的,为什么却过滤不出来呢?
sh[root@Ansible-server opt]# cat a.txt 123mnmmlo [root@Ansible-server opt]# grep 'o$' a.txt我们可以使用
cat -A去查看一下文件
sh[root@Ansible-server opt]# cat -A a.txt 123mnmmlo $我们会发现文件的结尾出现了一个"$",并且还有一个空格,这又是什么呢?
这主要是由于
cat -A他显示出了文件中隐藏的符号,这个符号,在Linux中是一行结束的标志,每一行结束都要加一个,只不过在我们日常查看时,他是处于隐藏状态的,我们看不到从这也就可以说明为什么在正则表达式中要用"$"去表示以什么结尾。
从上面的代码中我们可以看到,$和正文之间还有一个空格,也就是说明,正文并不是以o结尾的,而是以空格结尾。至此我们也就知道为什么我们查不到以o结尾的数据了。
我们可以这样做,问题被解决
sh[root@Ansible-server opt]# grep ' $' a.txt 123mnmmlo
3、^$ 匹配空行
sh
[root@Ansible-server opt]# grep -n '^$' a.txt
2:一般来说我们是不想看空行的
因此会把空行过滤出去
grep -v,反向过滤
sh
[root@Ansible-server opt]# grep -n -v '^$' a.txt
1:123mnmmlo
4:afasg 开生产环境中,我们一般会排除空行和#开头的行(注释行),这些会影响我们的观感
sh
[root@Ansible-server opt]# grep -v '^$' /etc/ssh/sshd_config | grep -v '^#'4、. 任意一个字符
初学正则时,很少单独使用
不匹配空行
sh
[root@Ansible-server opt]# grep -n . a.txt
1:123mnmmlo
4:afasg - grep -o:显示正则表达式匹配到了什么内容,以及正则表达式的匹配过程

5、\撬棍
转义字符,去掉特殊符号的含义,让其表示原本的内容
通常和.使用搭配使用
例如:我们相匹配文件中所有以.结尾的行
如果我们直接使用.$,匹配到的是所有行,因此我们就需要将.的特殊含义去除
sh
[root@Ansible-server opt]# grep -n '.$' a.txt
1:123mnmmlo
3:af.
4:23452rtryret.
5:afasg
[root@Ansible-server opt]# grep -n '\.$' a.txt
3:af.
4:23452rtryret.**6、* 前一个字符连续出现0次或0次以上 **
理解什么是连续/重复
111 数字1连续出现了3次
2222 数字2连续出现了4次
weqqrqq 英文字母连续出现了7次
12we 英文字母和数字连续出现了4次
这些都可以算是连续出现,而不是说只有出现相同的内容才算连续出现
❓我们去过滤"2*",我们发现所有的都过滤出来了,这是为什么呢?
* 他可以匹配0次或0次以上的内容,那就可以解释为,不是2 的内容,我们就认为其是 2 出现了0次,因此也就满足要求,可以匹配出来
sh
[root@Ansible-server opt]# grep -n '2*' a.txt
1:123mnmmlo
2:
3:af.
4:23452rtryret.
5:112222fgh
6:2225564vvv
7:afasg
8:2227、.* 所有
使用频率特别高,表示所有,任何东西
- .表示任意字符
- *表示0次或0次以上匹配
- .*表示匹配所有
sh
[root@Ansible-server opt]# grep -n '^.*linux' a.txt
5:I learn linux
6:I do not learn linux贪婪匹配
正则表达式表示连续出现 或者表示所有的时候正则表达式会体现出贪婪性,尽可能多的去匹配
他会一直去匹配a,直到最后一个

8、\[\]匹配任意一个字符
abc:表示匹配a或者b或者c
匹配中括号中的任意一个字符

⚠️**\[\]会自动去掉特殊符号的特殊含义**
9、\^表示过滤除了中括号中的内容
\^abc:表示过滤文件中除了abc之外的内容
sh
[root@Ansible-server opt]# grep -n '[^a-z]' a.txt
1:123mnmmlo
7:iaflknklanaaanubkbajo9878970akbjkhakj6797
8:222【4】、扩展正则
- grep不支持扩展正则的使用
- egrep 支持扩展正则
- sed 使用sed -r支持扩展正则
- awk 默认支持扩展正则
1、+ 前一个字符连续出现1次或1次以上
-
一般搭配着【】一起使用
-
去除连续出现的2
sh[root@Ansible-server opt]# grep '2+' a.txt [root@Ansible-server opt]# egrep '2+' a.txt 123mnmmlo 222 -
连续出现的数字
sh[root@Ansible-server opt]# egrep '[0-9]+' a.txt 123mnmmlo iaflknklanaaanubkbajo9878970akbjkhakj6797 222 -
连续出现的单词
sh[root@Ansible-server opt]# egrep '[a-Z]+' a.txt 123mnmmlo iaflknklanaaanubkbajo9878970akbjkhakj6797 [root@Ansible-server opt]# egrep -o '[a-Z]+' a.txt mnmmlo iaflknklanaaanubkbajo akbjkhakj -
统计单词出现的次数
sh[root@Ansible-server opt]# egrep -o '[a-Z]+' a.txt | sort | uniq -c 1 akbjkhakj 1 iaflknklanaaanubkbajo 1 mnmmlo
2、| 或者
一般是过滤出含有单词1或者含有单词2的行
sh
[root@Ansible-server opt]# egrep -n 'linux|apple' a.txt
3:apple agsag vv
4:linux wrathh apple在/etc/services中过滤出:ssh或http或smtp
sh
[root@Ansible-server opt]# egrep 'ssh|http|stmp' /etc/services排除/etc/ssh/sshf_conf中的空行和注释行
sh
[root@Ansible-server opt]# egrep -v -n '^$|^#' /etc/ssh/sshd_config3、()表示一个整体,或者后向引用
()表示一个整体或者在sed中表示后向引用
sh
[root@Ansible-server ~]# rpm -qa | egrep '^tree|^vim|^sl'
vim-enhanced-8.0.1763-19.el8_6.4.x86_64
vim-filesystem-8.0.1763-19.el8_6.4.noarch
vim-common-8.0.1763-19.el8_6.4.x86_64
tree-1.7.0-15.el8.x86_64
vim-minimal-8.0.1763-19.el8_6.4.x86_64
slang-2.3.2-3.el8.x86_64
slirp4netns-1.2.1-1.module+el8.9.0+19731+94cfa27e.x86_64
sl-5.02-1.el8.x86_64
# 表示一个整体
[root@Ansible-server ~]# rpm -qa | egrep '^(tree|vim|sl)'
vim-enhanced-8.0.1763-19.el8_6.4.x86_64
vim-filesystem-8.0.1763-19.el8_6.4.noarch
vim-common-8.0.1763-19.el8_6.4.x86_64
tree-1.7.0-15.el8.x86_64
vim-minimal-8.0.1763-19.el8_6.4.x86_64
slang-2.3.2-3.el8.x86_64
slirp4netns-1.2.1-1.module+el8.9.0+19731+94cfa27e.x86_64
sl-5.02-1.el8.x86_644、{}
| 格式 | |
|---|---|
| a | 表示连续出现的范围 |
| a{n} | 匹配固定的次数 |
| a | 前一个字符至少出现n次 |
| a | 前一个字符连续出现,最多m次 |

 ``
``
sh
## 匹配身份证
[root@Ansible-server opt]# egrep '[0-9]{17}[0-9X]$' a.txt5、?
表示前一个字符出现0或1次
一般用于匹配的内容可能有(出现1次)或者没有出现(出现0次)
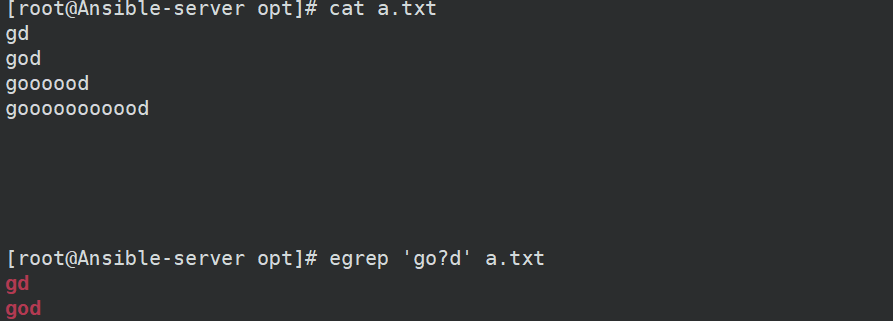
6、\b
单词边界
sh
[root@moudle01 19:27:51 ~]# grep "the" abc
the apple
I like the apple
these apple
hello tomthe
[root@moudle01 19:27:56 ~]# egrep "\bthe\b" abc
the apple
I like the apple7、扩展正则小结
| 扩展正则 | 含义 |
|---|---|
| +⭐⭐⭐⭐⭐ | 前一个字符连续出现一次或者多次 |
| |⭐⭐⭐⭐⭐ | 或者 |
| ()⭐⭐ | 🅰️表示整体 🅱️表示后向引用(sed中) |
| {} | 表示前一个字符出现的次数范围 |
| ? | 前一个字符出现0或者1次 |
| \b | 单词边界\b单词\b,确定一个单词 |
| 基础正则 | 含义 |
|---|---|
| ^⭐⭐⭐⭐⭐ | 以...开头 |
| $⭐⭐⭐⭐⭐ | 以...结尾 |
| ^$⭐⭐⭐⭐⭐ | 过滤空行 |
| . | 任意字符 |
| \ | 转义字符、撬棍 |
| * | 前一个字符出现0次或0次以上 |
| .*⭐⭐⭐⭐⭐ | 匹配所有字符 |
| \[\]⭐⭐⭐⭐⭐ | abc,匹配a或b或c |
| \^ | 取反 |
【5】、perl语言正则表达式
- perl正则
支持perl正则的命令
grep -P
| 符号 | 含义 |
|---|---|
| /d | 0-9 |
| /w | 0-9a-zA-Z |
| /s | 匹配空字符 空格 tab 等等\\ \\t\\r\\n\\f |
| /D | \^0-9 |
| /S | 匹配空格、tab键 |
| /W | 排除数字,大小写字母和_ |
1、匹配IP
sh
[root@moudle01 09:04:45 /script]# grep -E "([0-9]{1,3}\.){3}[0-9]{1,3}" ip.txt
123.33.22.11
123.4.123.11
192.45.3.21
[root@moudle01 09:04:52 /script]# grep -P "(\d{1,3}\.){3}\d{1,3}" ip.txt
123.33.22.11
123.4.123.11
192.45.3.21
[root@moudle01 09:11:43 /script]# grep -P "(25[0-5]\.|2[0-4]\d\.|1?\d?\d\.){3}(25[0-5]\.|2[0-4]\d\.|1?\d?\d)" ip.txt
123.33.22.11
123.4.123.11
192.45.3.2