引言

提升机器学习模型的训练速度是每位机器学习工程师的共同追求。训练速度的提升意味着实验周期的缩短,进而加速产品的迭代过程。同时,这也表示在进行单一模型训练时,所需的资源将会减少。简而言之,我们追求的是效率。
熟悉 PyTorch profiler
在进行任何优化之前,首先需要了解代码中各个部分的执行时长。Pytorch profiler 是一款功能全面的训练性能分析工具,能够捕捉以下信息:
- CPU 操作的耗时
- CUDA 核心的运行时间
- 内存使用情况的历史记录
这些就是你需要关注的所有内容。而且,使用起来非常简单!记录这些事件的方法是,将训练过程封装在一个 profiler 的上下文环境中,操作方式如下:
import torch.autograd.profiler as profiler
with profiler.profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
on_trace_ready=torch.profiler.tensorboard_trace_handler('./logs'),
) as prof:
train(args)之后,您可以启动张量板并查看分析跟踪。Profiler 提供了众多选项,但最关键的是 "activities" 和 "profile_memory" 这两个功能。尽管你可以探索其他功能,但请记住一个基本原则:启用的选项越少,性能开销也就越低。
例如,如果你的目的是分析 CUDA 内核的执行时间,那么最好的做法是关闭 CPU 分析和其他所有功能。这样,分析结果会更贴近实际的执行情况。
为了让分析结果更易于理解,建议添加一些描述代码关键部分的分析上下文。如果分析功能没有被激活,这些上下文就不会产生任何影响。
with profiler.record_function("forward_pass"):
result = model(**batch)
with profiler.record_function("train_step"):
step(**result)这样,您使用的标签将在迹线中可见。因此,识别代码块会更容易。或者更精细的内部模式的前进:
with profiler.record_function("transformer_layer:self_attention"):
data = self.self_attention(**data)
...
with profiler.record_function("transformer_layer:encoder_attention"):
data = self.encoder_attention(**data, **encoder_data)了解 PyTorch traces
收集traces后,在张量板中打开它们。 CPU + CUDA 配置文件如下所示:
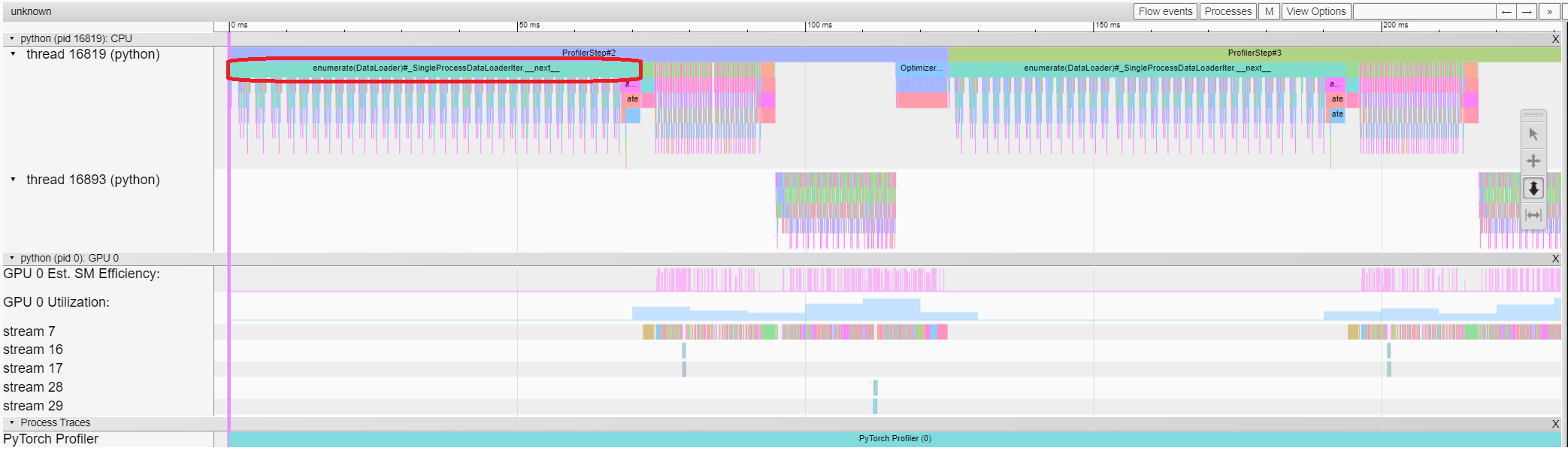
立刻识别出任何训练过程中的关键环节:
- 数据加载
- 前向传播
- 反向传播
PyTorch 会在一个独立线程中处理反向传播(如上图所示的线程 16893),这使得它很容易被识别出来。
数据加载
在数据加载方面,我们追求极致的效率,即几乎不耗费时间。
原因在于,在数据加载的过程中,GPU 闲置不工作,这导致资源没有得到充分利用。但是,由于数据处理和 GPU 计算是两个独立的部分,它们可以同时进行。
你可以通过查看分析器跟踪中的 GPU 估计 SM 效率和 GPU 利用率来轻松识别 GPU 空闲的区域。那些活动量为零的区域就是我们需要注意的问题所在。在这些区域,GPU 并没有参与任何工作。
解决这个问题的一个简单方法是:
- 在后台进程中进行数据处理,这样不会受到全局解释器锁(GIL)的限制。
- 通过并行进程来同时执行数据增强和转换操作。 如果你使用的是 PyTorch 的 DataLoader,通过设置
num_workers参数就可以轻松实现这一点。如果你使用的是 IterableDataset,情况会稍微复杂一些,因为数据可能会被重复处理。不过,通过使用get_worker_info()方法,你仍然可以解决这个问题------你需要调整迭代方式,确保每个工作进程处理的是互不重叠的不同数据行。
如果你需要更灵活的数据处理方式,你可以考虑使用 multiprocessing 模块来自己实现多进程转换功能。
内存分配器
使用 PyTorch 在 CUDA 设备上分配张量时,PyTorch 会利用缓存分配器来避免执行成本较高的 cudaMalloc 和 cudaFree 操作。PyTorch 的分配器会尝试复用之前通过 cudaMalloc 分配的内存块。如果分配器手头有合适的内存块,它将直接提供这块内存,而无需再次调用 cudaMalloc,这样 cudaMalloc 只在程序启动时调用一次。
但是,如果你处理的是长度不一的数据,不同前向传播过程可能需要不同大小的中间张量。这时,PyTorch 的分配器可能没有合适的内存块可用。在这种情况下,分配器会尝试通过调用 cudaFree 释放之前分配的内存块,以便为新的内存分配腾出空间。
释放内存后,分配器会重新开始构建其缓存,这将涉及到大量的 cudaMalloc 调用,这是一个资源消耗较大的操作。你可以通过观察 tensorboard profiler viewer 的内存分析部分来识别这个问题。
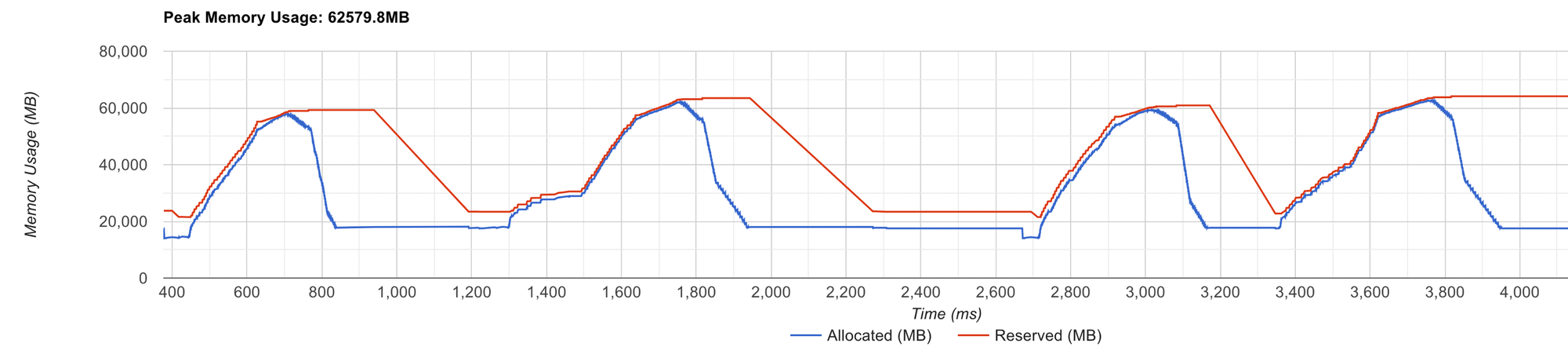
请注意,代表分配器预留内存的红线持续波动。这表明 PyTorch 的内存分配器在处理内存请求时遇到了效率问题。
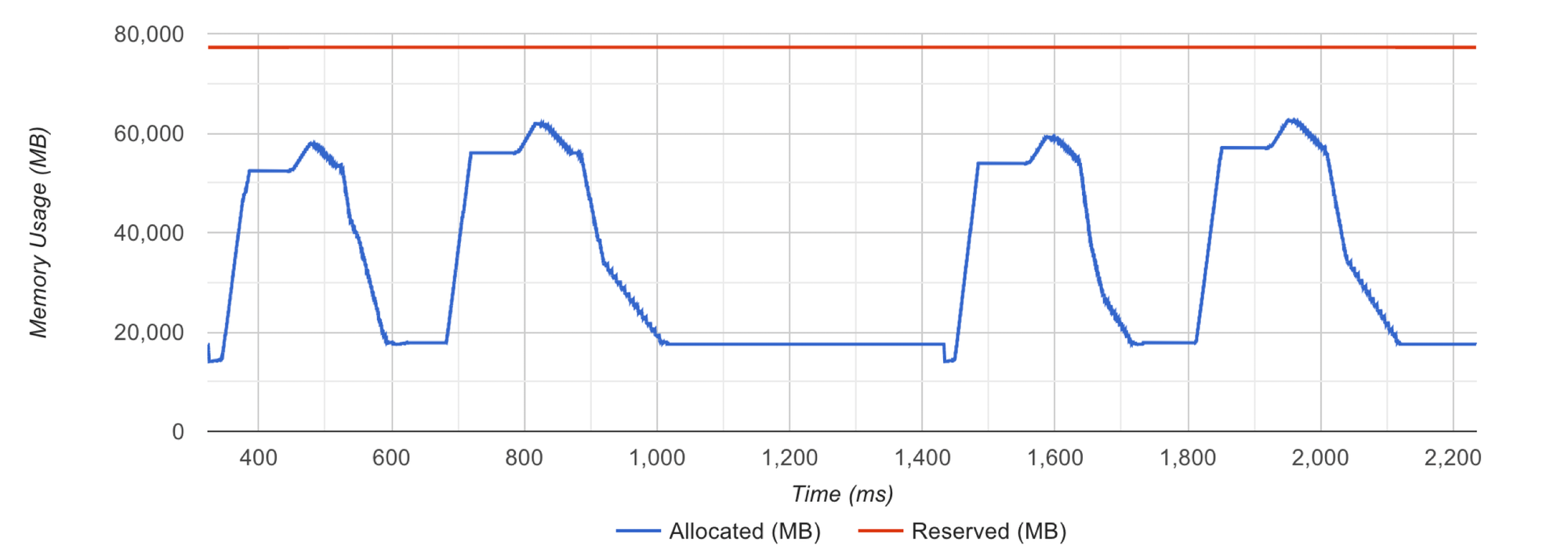
当内存分配在没有触发分配器紧急情况下顺利进行时,你会看到红线保持平稳。
本文由mdnice多平台发布