前言
自己个人兴趣爱好,线上有一个阿里云服务器,处理数据用的,会频繁IO和分析数据。隔一段时间就会卡死(大概2个月),重启就OK。本来没当一回事,直到后来影响到赚取money了才引起重视。服务的启动脚本如下:
nohup java -Xms512m -Xmx1024m -jar xxx.jar &当然这个脚本是有很多问题的,毕竟自己的服务器,追求的就是一个简单粗暴,怎么简单怎么来,没有那么多顾虑。但是自己埋的坑、迟早有一天哭着也要填完!
现象
突然有一天,登录服务器发现登录不上去,xshell 类似下面的提示。看起来是连接上了,但是进不去,这种情况一般要么是网卡、要么是服务器卡,我这显然是后者。通过阿里云控制台都进不去,一般这种情况等一段时间,消耗内存的应用会被杀掉,然后就能进去了。当然我这种急性子自然是选择去阿里云后台直接强制重启服务器。

服务器是能进去了,但是没有任何日志可供查询,没有堆栈信息,查看日志并没有发现oom错误(这里只能一句卧槽了)。于是修改启动脚本如下,以便下一次有类似情况可以有痕迹可寻:
nohup java -Xms512m -Xmx1024m -Xlog:gc*:file=gc.log:time,uptime,level,tags -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/dumps -jar xx.jar &内存的原因,自然是要关注内存。一般我们需要关注一下垃圾回收器的行为以及堆内存使用情况。-XX:+HeapDumpOnOutOfMemoryError 以及-XX:HeapDumpPath 就是指定了当发生堆内存溢出的时候,转储当时的内存文件供我们后续分析(其实观察到内存开销持续上涨,回收效果不明显,就可以用这个命令导来导出堆内存文件分析:jamp -dump:live,format=b,file=xxx.hprof)。终于是在某一天(2个月后),发现了OOM错误,如下所示。
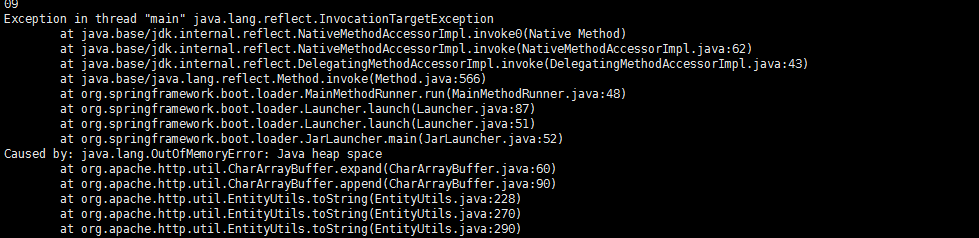
这就很离谱了,上次我卡死直接强制重启了,nohup.out文件并没有看到OOM错误的日志,但是这次为啥出现OOM错误日志了。这个问题现在我都没搞清楚为什么,服务器是2G内存,启动脚本堆最大1G内存,完全够用哇,讲道理不可能消耗完服务器内存。难道代码还有IO等内存泄漏? 先不管了,先解决眼前的问题。既然是OOM错误,自然是要看是哪个实例占用了内存,使用MAT分析一下。(PS: JHAT 无异于大海捞针,因为类太多,他又不能把较大内存的排序,然后OQL又不能支持通配符,就无解,还是MAT香)。MAT分析报告如下:
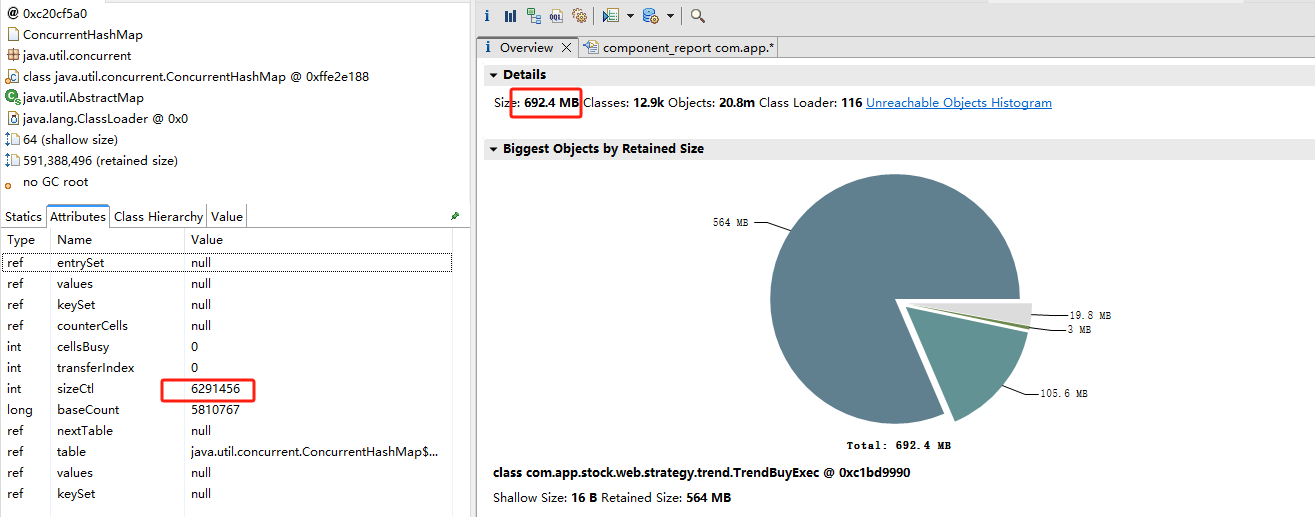
可以看到有一个大对象占用内存692.4M , 这基本可以锁定这个问题就出现在这个对象上了。 然后再查其中有一个属性,是一个静态成员变量map,如图所示有6291456个key。 结合代码看该变量会被业务数据依据具体情况,填充进数据,但是并没有释放的地方,so 这就是问题所在了。
解决
我这里就是简单粗暴的定时清理一下内存,如下所示。

因为要很久才出现OOM, 所以这个代码能用,但却是不优雅的。奈何自己的项目随便弄的,写成了屎山代码,不太好改,毕竟有一句话说的好: If your code runs in some inexplicable way, don't touch it anymore。否则将会是面对如下所示的残酷:
后话
文中有提到设置了-Xmx1024m 但是实际导致服务器2G内存卡死,可能存在的内存泄漏问题,先在启动脚本加上参数-XX:MaxDirectMemorySize=256M,控制一下本地内存,后续如果再次出现OOM 了,在继续-。
nohup java -Xms512m -Xmx1024m -Xlog:gc*:file=gc.log:time,uptime,level,tags -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/dumps -XX:MaxDirectMemorySize=256M -jar xx.jar &大家不偷懒的话,gc日志参数,堆内存导出,这些最好都设置好!