
目录:
[一、 Base64概述和应用场景](#一、 Base64概述和应用场景)
[1.1 概述](#1.1 概述)
[1.2 应用场景](#1.2 应用场景)
[2.1 Base16编码](#2.1 Base16编码)
[2.2 Base16编解码](#2.2 Base16编解码)
[四、OpenSSL BIO接☐](#四、OpenSSL BIO接☐)
[4.1 Filter BIOs:](#4.1 Filter BIOs:)
[4.2 Source/Sink BIOs:](#4.2 Source/Sink BIOs:)
[4.3 应用场景:](#4.3 应用场景:)
[4.4 具体使用:](#4.4 具体使用:)
[4.5 进行BIO编码:](#4.5 进行BIO编码:)
[2. Base64解码(Base64Decode`函数)](#2. Base64解码(Base64Decode`函数))
[3. main函数](#3. main函数)
一、 Base64概述和应用场景
1.1 概述
Base64是一种编码方式,用于将二进制数据转换为ASCII字符串,以便在只支持文本的媒体上进行存储和传输。它不是一种加密算法,而是一种数据编码技术。Base64编码是一种简单而有效的数据编码方式,它允许二进制数据在文本环境中安全地传输和存储。尽管它不提供安全性(数据在传输过程中可以被读取),但它确保了数据的完整性和可移植性。
1.2 应用场景
邮件编码(base64)
xml或者json存储二进制内容
网页传递数据URL
数据库中以文本形式存放二进制数据
可打印的比特币钱包地址base58 Check(hash校验)
比特币地址bech32(base32)
二、Base16
2.1 Base16编码
Base16是一种编码方法,它使用16个可打印的ASCII字符来表示二进制数据。这些字符包括数字0到9和字母A到F。每个字符代表4个二进制位,因此Base16有时也称为十六进制编码。

在Base16编码过程中,首先将原始数据(如文本或文件)转换成二进制形式。对于ASCII编码字符,这一步直接涉及将每个字符转换为其对应的8位二进制值。对于UTF-8或其他编码,可能涉及更复杂的转换过程。
接下来,将得到的二进制串按照每4位一组进行切分。由于每组4位可以对应一个0到15之间的十进制数,这个数可以直接映射到上述提到的16个字符之一 。例如,二进制组0101对应十进制数5,按Base16编码转换成字符5;二进制组1001对应十进制数9,转换成字符9;二进制组1010对应十进制数10,转换成字符A,依此类推。

由于Base16使用4位二进制表示一个字符,一个字节(8位)被编码为两个Base16字符。因此,Base16编码后的数据大小是原始数据大小的两倍。
cpp
#include <iostream>
using namespace std;
// 定义一个静态的常量字符数组,用于Base16编码的字符映射表
static const char BASE16_ENC_TAB[] = "123456789ABCDEF";
// 函数:将输入的原始数据按照Base16编码规则编码到输出字符串中
// 参数:in - 指向原始数据的指针;size - 原始数据的字节数;out - 指向输出编码字符串的指针
// 返回值:编码后的字符串长度,即原始数据长度的两倍
int Base16Encode(const unsigned char* in, int size, char* out)
{
// 遍历原始数据的每个字节
for (int i = 0; i < size; i++)
{
// 将当前字节的高四位右移四位,得到高四位的值
char h = in[i] >> 4; // 例如:二进制1000 0001通过移位变为0000 1000
// 将当前字节的低四位与0x0F进行与操作,得到低四位的值
char l = in[i] & 0x0F; // 例如:二进制0000 1111与0x0F与操作后得到0000 0001
// 根据高四位的值,在编码表中查找对应的字符,并存入输出字符串
out[i * 2] = BASE16_ENC_TAB[h]; // 映射高四位到编码表对应的字符
// 根据低四位的值,在编码表中查找对应的字符,并存入输出字符串
out[i * 2 + 1] = BASE16_ENC_TAB[l]; // 映射低四位到编码表对应的字符
}
// 返回编码后的字符串长度,即原始数据长度的两倍
return size * 2;
}
int main(int argc, char* argv[])
{
cout << "测试Base16编码" << endl;
// 定义待编码的原始数据
const unsigned char data[] = "测试base16";
// 获取原始数据的字节长度
int len = sizeof(data) - 1; // 减1是因为sizeof包含了结尾的'\0'字符
// 定义足够大的输出数组来存放编码后的字符串
char out1[1024] = { 0 };
// 打印原始数据
cout << "原始数据: " << data << endl;
// 调用Base16编码函数
int re = Base16Encode(data, len, out1);
// 打印编码后的字符串及其长度
cout << "编码后长度: " << re << ", 编码结果: " << out1 << endl;
return 0;
}(1) 定义了一个静态常量字符数组`BASE16_ENC_TAB`,包含了Base16编码所需的字符('0'-'9'和'A'-'F')。
**(2)Base16Encode`函数接收三个参数:**指向原始数据的指针`in`,原始数据的字节数`size`,以及指向输出编码字符串的指针`out`。
**(3) 在`Base16Encode`函数中,使用一个循环遍历输入数据的每个字节。**对于每个字节,进行以下操作:
将字节的高四位右移四位,得到一个0到15之间的值,这个值对应于该字节的高四位。
将字节与0x0F进行位与操作,得到一个0到15之间的值,这个值对应于该字节的低四位。
使用这两个值作为索引,在`BASE16_ENC_TAB`数组中查找对应的字符,并将这些字符分别存储到输出字符串的相应位置。
(4)循环结束后,返回编码后的字符串长度,即原始数据长度的两倍。
**(5)在`main`函数中,定义了一个待编码的字符串`data`,计算其长度(不包括结尾的空字符'\0'),**并声明了一个足够大的字符数组`out1`来存储编码后的字符串。
(6)`main`函数打印出原始数据,调用`Base16Encode`函数进行编码,并打印出编码后的字符串及其长度。

代码定义了一个Base16Encode函数,用于将输入的原始数据按照Base16编码规则编码到输出字符串中 ,并在main函数中进行了测试。sizeof(data)包含了字符串结尾的空字符\0,所以在计算长度时应该减去1,否则会将空字符也进行编码。
2.2 Base16编解码
Base16(或称为十六进制)编码是一种将二进制数据转换为一种使用16个可打印字符(0-9和A-F)表示的方法。Base16编码的解码过程是将编码后的字符串转换回原始的二进制数。
实现了Base16编码和解码的功能。
cpp
#include <iostream>
// 引入iostream库,用于输入输出操作
using namespace std;
// 使用std命名空间,避免在代码中重复写std::前缀
// 定义一个静态的常量字符数组,用于Base16编码的字符映射表
static const char BASE16_ENC_TAB[] = "0123456789ABCDEF"; // 包含16进制编码的字符,从0到F
static const char BASE16_DEC_TAB[128] = {
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, // ASCII码0-15,非16进制字符映射为-1
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, // ASCII码16-31,非16进制字符映射为-1
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, // ASCII码32-47,非16进制字符映射为-1
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, -1, -1, -1, -1, -1, -1, // ASCII码48-57,对应0-9
-1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, // ASCII码65-70,对应A-F
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, // ASCII码71-76,非16进制字符映射为-1
-1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, // ASCII码91-96,对应a-f
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1 // ASCII码97-102,非16进制字符映射为-1
}; // 正确填充解码表,非16进制字符映射为-1
// 函数:将输入的原始数据按照Base16编码规则编码到输出字符串中
int Base16Encode(const unsigned char* in, int size, char* out) {
for (int i = 0; i < size; i++) {
char h = in[i] >> 4; // 获取字节的高4位
char l = in[i] & 0x0F; // 获取字节的低4位
out[i * 2] = BASE16_ENC_TAB[h]; // 将高4位转换为对应的16进制字符
out[i * 2 + 1] = BASE16_ENC_TAB[l]; // 将低4位转换为对应的16进制字符
}
return size * 2; // 返回编码后的长度,是输入长度的两倍
}
// 函数:将Base16编码的字符串解码回原始数据
int Base16Decode(const string& in, char* out) {
for (int i = 0; i < in.size(); i += 2) { // 以2个字符为一组进行解码
unsigned char h = BASE16_DEC_TAB[static_cast<unsigned char>(in[i])]; // 获取高4位
unsigned char l = BASE16_DEC_TAB[static_cast<unsigned char>(in[i + 1])]; // 获取低4位
out[i / 2] = (h << 4) | l; // 将高4位和低4位合并成原始字节
}
return in.size() / 2; // 返回解码后的长度,与输入长度相同
}
int main(int argc, char* argv[]) {
cout << "测试Base16编码" << endl;
const unsigned char data[] = "测试base16编码";
int len = sizeof(data) - 1;
char out1[1024] = { 0 };
unsigned char out2[1024] = { 0 };
cout << "原始数据: " << data << endl;
int encodedLength = Base16Encode(data, len, out1);
cout << "编码后长度: " << encodedLength << ", 编码结果: " << out1 << endl;
int decodedLength = Base16Decode(out1, reinterpret_cast<char*>(out2));
cout << "解码后长度: " << decodedLength << ", 解码结果: " << out2 << endl;
return 0;
}1. 字符映射表:
BASE16_ENC_TAB 是一个包含16进制编码字符的静态常量字符数组,从'0'到'F'
BASE16_DEC_TAB 是一个静态常量字符数组,用于将ASCII码转换为对应的16进制数值。数组中索引0-15对应ASCII码0-9和A-F,其他索引为-1,表示不是16进制字符。
2. Base16Encode函数:
接受三个参数:输入数据的指针in,输入数据的大小size,输出字符串的指针out。
循环遍历输入数据的每个字节,提取高4位和低4位。
使用高4位和低4位索引`BASE16_ENC_TAB`数组,获取对应的16进制字符。
将两个字符依次写入输出字符串的相应位置。
函数返回编码后的长度,即输入长度的两倍。
3. Base16Decode函数:
接受两个参数:Base16编码的字符串`in`和输出数据的指针out。
以两个字符为一组进行解码,因为Base16编码是将每个字节转换为两个字符。
使用输入字符串的每个字符索引BASE16_DEC_TAB数组,获取对应的16进制数值。
将高4位和低4位合并成一个字节,写入输出数据。
函数返回解码后的长度,即输入长度的一半。
4. main函数:
定义测试数据data,它是要编码和解码的字符串。
定义输出缓冲区out1用于存储编码后的字符串,以及`out2`用于存储解码后的数据。
打印原始数据。
调用Base16Encode函数编码数据,并打印编码后的长度和结果。
调用Base16Decode函数解码数据,并打印解码后的长度和结果。

通过定义字符映射表和实现编码和解码函数,实现了对字符串进行Base16编码和解码的功能。在`main`函数中,通过示例数据展示了如何使用这些函数。
三、Base64

**1. 分组处理:**Base64编码将每3个字节的二进制数据(24位)作为一组进行处理。

**2. 转换:**将这3个字节的24位分成4组,每组6位。每组的6位二进制数转换成对应的4位Base64字符。

**3. 补齐:**如果原始数据不是3的倍数,那么在最后可能会剩下1个或2个字节。为了将这些数据也能编码,Base64会在编码后的字符串末尾添加'='字符。如果剩余1个字节,就会添加一个'=';如果剩余2个字节,就会添加两个'='。
四、OpenSSL BIO接☐
penSSL BIO(Basic I/O)是OpenSSL库中用于抽象I/O操作的一个组件。BIO提供了多种接口来控制不同类型的I/O操作
4.1 Filter BIOs:
这些BIOs用于在数据从一个BIO流向另一个BIO的过程中进行转换或过滤。
BIO_f_base64():用于Base64编码和解码。BIO_f_cipher():用于加密和解密。BIO_f_md5():用于MD5散列。BIO_f_md4():用于MD4散列。BIO_f_sha1():用于SHA-1散列。BIO_f_sm3():用于SM3散列。BIO_f_sign():用于签名。BIO_f_verify():用于验证签名。BIO_f_negotiate():用于TLS/SSL协商。BIO_f_buffer():用于缓冲。
4.2 Source/Sink BIOs:
这些BIOs是数据源或接收器
BIO_new(BIO_s_mem()):创建一个内存BIO,用于存储数据。BIO_new(BIO_s_file()):创建一个文件BIO,用于文件读写。BIO_new(BIO_s_socket()):创建一个套接字BIO,用于网络通信。BIO_new(BIO_s_fd()):创建一个文件描述符BIO。BIO_new(BIO_s_open()):创建一个用于打开文件的BIO。BIO_new(BIO_s_mem()):创建一个内存BIO。BIO_new(BIO_s_connect()):创建一个用于连接的BIO。BIO_new(BIO_s_accept()):创建一个用于接受连接的BIO。
4.3 应用场景:
- BIOs常用于构建复杂的I/O操作,如加密通信、数据转换等。
- 在TLS/SSL通信中,BIOs用于封装底层的I/O操作,如读写数据。
4.4 具体使用:
BIO_new():用于创建一个新的BIO对象。- 数据源BIO,例如
BIO_new(BIO_s_mem()),创建一个内存BIO。- 过滤BIO,例如
BIO_new(BIO_f_base64()),创建一个Base64编码和解码的过滤BIO。- 创建BIO链,例如
BIO_push(b64_bio, mem_bio),将Base64过滤BIO和内存BIO连接起来。BIO_write():用于向BIO写入数据。当使用Base64过滤BIO时,数据会被编码。BIO_read_ex():用于**从BIO读取数据。**当使用Base64过滤BIO时,数据会被解码。
4.5 进行BIO编码:
通过**使用OpenSSL的BIO链表和Base64编码过滤器,将输入数据编码为Base64格式,并将结果输出到控制台。**主要思路是利用OpenSSL库提供的功能,通过BIO链表处理编码过程,最后将编码后的数据存储并输出。
cpp
#include <iostream>
#include <openssl/rand.h>
#include <openssl/evp.h>
#include <openssl/buffer.h>
#include <cstring>
using namespace std;
int Base64Encode(const unsigned char* in, int len, char* out_base64)
{
if (!in || len <= 0 || !out_base64)
return 0;
// 内存源
auto mem_bio = BIO_new(BIO_s_mem());
if (!mem_bio) return 0;
// base64 filter
auto b64_bio = BIO_new(BIO_f_base64());
if (!b64_bio)
{
BIO_free(mem_bio);
return 0;
}
// 形成BIO链表
// b64-mem
BIO_push(b64_bio, mem_bio);
// 写入到base64 filter 进行编码,结果会传递到链表的下一个节点
// 到mem中读取结果(从链表头部,代表了整个链表)
int re = BIO_write(b64_bio, in, len);
if (re < 0)
{
// 清空整个链表节点
BIO_free_all(b64_bio);
return 0;
}
// 刷新缓存,写入链表的mem
BIO_flush(b64_bio);
int outsize = 0;
// 从链表源内存读取
BUF_MEM* p_data = NULL;
BIO_get_mem_ptr(b64_bio, &p_data);
if (p_data)
{
// 确保输出数组足够大
if (p_data->length < len * 4 / 3 + 1)
{
BIO_free_all(b64_bio);
return 0;
}
memcpy(out_base64, p_data->data, p_data->length);
outsize = p_data->length;
}
BIO_free_all(b64_bio);
return outsize;
}
int main(int argc, char *argv[])
{
cout << "The openssl BIO base64!" << endl;
unsigned char data[] = "测试Base64数据";
int len = sizeof(data);
char out[len * 4 / 3 + 1]; // 基于最大编码长度分配内存
int encoded_len = Base64Encode(data, len, out);
if (encoded_len > 0)
{
out[encoded_len] = '\0'; // 确保字符串以null终止
cout << out << endl;
}
getchar();
return 0;
}1. 包含必要的头文件:
<iostream>:用于输入输出流。
<openssl/evp.h>:用于加密和编码操作。
<openssl/buffer.h>:用于缓冲区操作。
<cstring>:用于字符串操作。
2. 命名空间声明:
使用`using namespace std;`使得`std`命名空间下的元素可以直接使用,无需前缀。
3. 定义Base64编码函数`Base64Encode:
函数接收三个参数:输入数据指针`in`,输入数据长度`len`,输出Base64编码数据指针out_base64。
进行参数有效性检查,如果输入无效,则返回0。
创建一个`BIO`(BASIC I/O)对象`mem_bio`,用于内存操作。
创建一个`BIO`对象`b64_bio`,用于Base64编码。
将`b64_bio`连接到`mem_bio`后面,形成BIO链表,以便将编码后的数据写入内存。
使用`BIO_write`将输入数据写入到`b64_bio`。
使用`BIO_flush`将缓存中的数据写入到内存中。
获取编码后的数据长度,并确保输出数组足够大。
将编码后的数据复制到输出数组中。
释放BIO资源,并返回编码后的数据长度。
4. 主函数main:
打印一个信息字符串。
定义一个要编码的字符数组`data`。
调用`Base64Encode`函数进行编码。
如果编码成功,将编码后的数据输出到控制台。
等待用户按键,然后退出程序。

4.6进行BIO解密:
使用了OpenSSL库中的BIO(块I/O)抽象,它提供了一种灵活的方式来处理不同类型的I/O操作,包括加密和编码操作 。通过将Base64编码和解码功能封装在BIO链表中。
cpp
#include <iostream>
#include <openssl/rand.h>
#include <openssl/evp.h>
#include <openssl/buffer.h>
#include <cstring>
using namespace std;
int Base64Encode(const unsigned char* in, int len, char* out_base64)
{
if (!in || len <= 0 || !out_base64)
return 0;
// 内存源
auto mem_bio = BIO_new(BIO_s_mem());
if (!mem_bio)
return 0;
// base64 filter
auto b64_bio = BIO_new(BIO_f_base64());
if (!b64_bio)
{
BIO_free(mem_bio);
return 0;
}
// 形成BIO链表
// b64-mem
BIO_push(b64_bio, mem_bio);
// 写入到base64 filter 进行编码,结果会传递到链表的下一个节点
// 到mem中读取结果(从链表头部,代表了整个链表)
//write为编码 3字节-》4字节,不足3字节补充0和=
int re = BIO_write(b64_bio, in, len);
if (re < 0)
{
// 清空整个链表节点
BIO_free_all(b64_bio);
return 0;
}
// 刷新缓存,写入链表的mem
BIO_flush(b64_bio);
int outsize = 0;
// 从链表源内存读取
BUF_MEM* p_data = NULL;
BIO_get_mem_ptr(b64_bio, &p_data);
if (p_data)
{
// 确保输出数组足够大
if (p_data->length < len * 4 / 3 + 1)
{
BIO_free_all(b64_bio);
return 0;
}
memcpy(out_base64, p_data->data, p_data->length);
outsize = p_data->length;
}
BIO_free_all(b64_bio);
return outsize;
}
int Base64Decode(const char* in, int len, unsigned char* out_data)
{
if (!in || len <= 0 || !out_data)
return 0;
// 内存源:密文
BIO* mem_bio = BIO_new_mem_buf(in, len);
if (!mem_bio)
return 0;
// base64过滤器
BIO* b64_bio = BIO_new(BIO_f_base64());
if (!b64_bio)
{
BIO_free(mem_bio);
return 0;
}
// 形成BIO链
BIO_push(b64_bio, mem_bio);
// 读取 解码
// read为解码 4字节 -> 3字节
size_t size = 0;
BIO_read_ex(b64_bio, out_data, len, &size);
BIO_free_all(b64_bio);
// 将解码后的字节转换为字符串
string decoded_string((char*)out_data, size);
// 打印解码后的字符串,以便于检查
cout << "Decoded data: " << decoded_string << endl;
return size;
}
int main(int argc, char* argv[]) {
cout << "The openssl BIO base64!" << endl;
unsigned char data[] = "测试Base数据的结果";
int len = sizeof(data);
char out[len * 4 / 3 + 1]; // 基于最大编码长度分配内存
unsigned char out2[len * 4 / 3 + 1]; // 声明变量out2
int encoded_len;
cout << "source: " << data << endl << endl;
encoded_len = Base64Encode(data, len, out);
cout << "encode: ";
if (encoded_len > 0) {
out[encoded_len] = '\0'; // 确保字符串以null终止
cout << out << endl;
}
encoded_len = Base64Decode(out, encoded_len, out2); // 使用编码后的长度
cout << endl << "Decoded data: ";
cout << (const char*)out2 << endl;
getchar();
return 0;
}实现了两个主要功能:Base64编码和Base64解码。
1.Base64编码(Base64Encode函数)
**(1). 输入验证:**首先检查输入参数是否有效,包括输入数据指针、长度和输出缓冲区指针。
(2). BIO链表初始化:
创建一个内存BIO(`BIO_s_mem`),用于临时存储编码数据。
创建一个Base64过滤器BIO(`BIO_f_base64`),用于执行Base64编码。
**(3). 形成BIO链表:**将Base64过滤器BIO插入到内存BIO的前面,形成链表。
**(4). 写入数据:**使用`BIO_write`函数将输入数据写入Base64过滤器BIO。
**(5). 刷新缓存:**使用`BIO_flush`函数刷新缓存,确保所有数据都被编码。
(6). 读取编码数据:
使用`BIO_get_mem_ptr`函数获取内存BIO中的数据。
检查输出缓冲区是否足够大以存储编码数据。
使用`memcpy`将编码数据复制到输出缓冲区。
**(7). 清理:**释放所有BIO资源。
2. Base64解码(Base64Decode`函数)
**(1). 输入验证:**同样检查输入参数是否有效。
(2). BIO链表初始化:
创建一个内存BIO,用于存储输入的Base64编码数据。
创建一个Base64过滤器BIO,用于执行Base64解码。
**(3). 形成BIO链表:**将Base64过滤器BIO插入到内存BIO的前面。
(4). 读取和解码数据:
使用`BIO_read_ex`函数从Base64过滤器BIO中读取和解码数据。
输出解码后的数据到用户提供的缓冲区。
**(5). 清理:**释放所有BIO资源。
3. main函数
(1). 打印欢迎信息。
(2). 编码数据:
调用`Base64Encode`函数进行编码。
输出编码后的Base64字符串。
(3). 解码数据:
调用`Base64Decode`函数进行解码。
输出解码后的原始数据。
(4). 等待用户输入,以便用户可以看到输出并手动关闭程序。
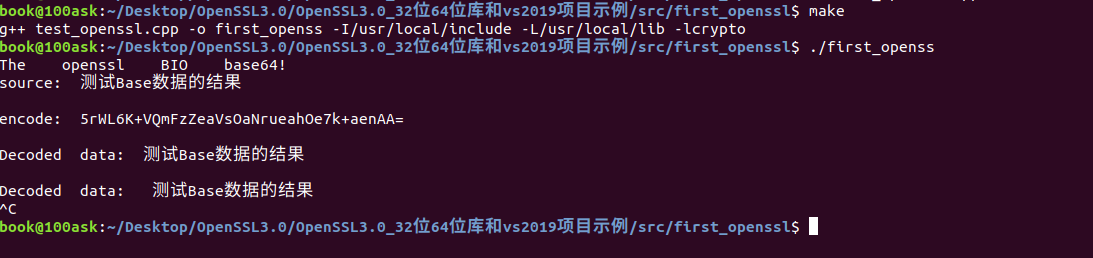
到此我们就算对Base64的编解码都实现其功能