目录
[2.1 什么是Altermanager](#2.1 什么是Altermanager)
[2.2 Altermanager使用场景](#2.2 Altermanager使用场景)
[3.1 Altermanager使用步骤](#3.1 Altermanager使用步骤)
[3.2 Altermanager工作机制](#3.2 Altermanager工作机制)
[3.3 Altermanager在Prometheus中的位置](#3.3 Altermanager在Prometheus中的位置)
[4.1 Altermanager部署过程](#4.1 Altermanager部署过程)
[4.1.1 获取安装包](#4.1.1 获取安装包)
[4.1.2 安装包解压](#4.1.2 安装包解压)
[4.1.3 启动alertmanager服务](#4.1.3 启动alertmanager服务)
[4.1.4 访问Altermanager](#4.1.4 访问Altermanager)
[4.1.5 Altermanager核心配置文件介绍](#4.1.5 Altermanager核心配置文件介绍)
[4.2 Altermanager接入Prometheus](#4.2 Altermanager接入Prometheus)
[4.2.1 配置alert target](#4.2.1 配置alert target)
[4.2.2 配置Altermanager监控指标](#4.2.2 配置Altermanager监控指标)
[4.2.3 访问Prometheus](#4.2.3 访问Prometheus)
[4.3 监控node_exporter](#4.3 监控node_exporter)
[4.3.1 创建rule(规则)目录和规则文件](#4.3.1 创建rule(规则)目录和规则文件)
[4.3.2 修改prometheus.yml](#4.3.2 修改prometheus.yml)
[4.3.3 重启Prometheus](#4.3.3 重启Prometheus)
[4.3.4 测试告警规则](#4.3.4 测试告警规则)
[5.1 Alertmanager配置邮箱告警通知](#5.1 Alertmanager配置邮箱告警通知)
[5.1.1 注册QQ邮箱](#5.1.1 注册QQ邮箱)
[5.1.2 开启SMTP服务](#5.1.2 开启SMTP服务)
[5.1.3 配置alertmanager.yml](#5.1.3 配置alertmanager.yml)
[5.1.4 重载配置文件](#5.1.4 重载配置文件)
[5.1.5 效果验证](#5.1.5 效果验证)
[5.2 Alertmanager配置钉钉告警通知](#5.2 Alertmanager配置钉钉告警通知)
[5.2.1 配置钉钉机器人](#5.2.1 配置钉钉机器人)
[5.2.2 获取钉钉webhook插件包](#5.2.2 获取钉钉webhook插件包)
[5.2.3 修改配置文件信息并启动服务](#5.2.3 修改配置文件信息并启动服务)
[5.2.4 使用docker的方式安装](#5.2.4 使用docker的方式安装)
[5.2.5 修改altermanager的配置](#5.2.5 修改altermanager的配置)
[5.2.6 重启altermanager服务](#5.2.6 重启altermanager服务)
[5.2.7 补充说明](#5.2.7 补充说明)
一、前言
在之前的文章中我们介绍了Prometheus的搭建与使用,以及如何配置监控常用的中间件,并基于Grafana对监控的服务指标信息进行可视化展现,接下来问题来了,人们不可能24小时都盯着展示的大屏看数据,是否有某种机制,或者某种方式,比如可以配置某项指标的阈值,一旦当这个指标达到阈值时,能通过一些通知方式将告警信息主动推送给相应的人员呢?这就是本文要分享的关于AlterManager的使用。
二、Altermanager概述
2.1 什么是Altermanager
Alertmanager是Prometheus监控系统的一个重要组成部分,主要用于处理由Prometheus服务器生成的警报。虽然Prometheus本身能够检测到指标阈值的违反情况并触发警报,但它并不直接负责警报的后续处理和通知。这就是Alertmanager介入的地方。具体来说,其主要功能特性如下:
-
警报接收与处理:Alertmanager接收来自Prometheus的警报,并对其进行进一步的处理,包括去重、分组、抑制和静默等;
-
去重:同一警报可能会因为网络问题或Prometheus的重试机制而被重复发送,Alertmanager会确保每个警报只被处理一次;
-
分组:Alertmanager可以将类似的警报合并在一起,减少警报的总数量,避免在大量警报出现时造成通知过载;
-
抑制与静默:Alertmanager支持设置抑制规则,在一定时间内不发送重复的警报,以及静默规则,用于在特定时间或条件下暂停警报的发送,例如在预定的维护窗口期间;
-
路由:警报可以按照定义好的路由规则被发送到不同的接收者,这使得可以针对不同的警报类型或严重级别选择合适的响应团队;
-
通知:Alertmanager支持多种通知渠道,包括电子邮件、短信、Slack、Telegram、Webhooks等,以确保警报可以快速准确地送达相关人员;
2.2 Altermanager使用场景
Alertmanager 在多种场景下都能发挥关键作用,特别是在企业级应用和云原生环境中。以下是 Alertmanager 的一些典型使用场景:
-
生产环境监控:
- Alertmanager 可与 Prometheus 或其他监控系统集成,用于实时监控生产环境中的各项指标,如服务器负载、应用程序性能、数据库状态等。当检测到异常或指标超过预设阈值时,Alertmanager 能及时发送预警通知,帮助运维人员迅速定位和解决问题,确保业务连续性和系统稳定性。
-
自动化运维:
- 通过 Alertmanager,运维团队可以建立自动化工作流,比如,在检测到某个服务故障后自动重启服务,或者在资源利用率过高时自动扩展资源。这种自动化响应可以减少人工干预的需求,提升系统自愈能力。
-
事件响应和管理
- 当系统发生故障时,Alertmanager 可以将警报按严重程度和类型分发给相应的团队成员,确保每个人收到与其职责相关的信息。这样可以加快事件响应速度,减少平均修复时间(MTTR),并有助于事件的高效管理。
-
合规性和审计:
- 在金融、医疗等对数据安全有严格要求的行业,Alertmanager 可以用于监控合规性指标,如数据泄露风险、访问控制违规等。一旦发现潜在的合规问题,立即通知合规团队采取行动。
-
用户体验监控:
- 对于面向用户的在线服务,Alertmanager 可以监控用户请求的延迟、错误率等指标,确保良好的用户体验。一旦检测到可能影响用户体验的问题,可以立即通知前端或后端开发团队进行优化。
-
容量规划:
- Alertmanager 可以帮助监控资源使用趋势,预测未来需求。如果发现资源接近耗尽,可以提前发出警告,以便进行容量规划和资源分配调整。
-
节假日和非工作时间的警报管理
- Alertmanager 支持设置警报抑制规则,可以根据时间表自动开启或关闭警报,避免在非工作时间产生不必要的警报,同时确保紧急警报仍然能够得到处理。
-
第三方服务集成
- Alertmanager 可以通过 Webhooks 或其他接口与第三方服务(如 PagerDuty、OpsGenie、钉钉、企业微信等)集成,将警报信息发送到团队常用的消息平台,提高警报的可见性和响应速度。
通过以上场景,可以看到 Alertmanager 是一个非常灵活且强大的工具,它能够适应不同规模和类型的组织的监控需求,有效提升系统的监控效率和运维管理水平。
三、Altermanager架构与原理
3.1 Altermanager使用步骤
Altermanager在生产使用时,主要分为下面几步:
-
部署Alertmanager;
-
配置告警接收人;
-
配置Prometheus与Alertmanager通信;
-
在Prometheus中创建告警规则;
-
配置生效并触发告警规则;
3.2 Altermanager工作机制
如下是Alertmanager的工作原理图:
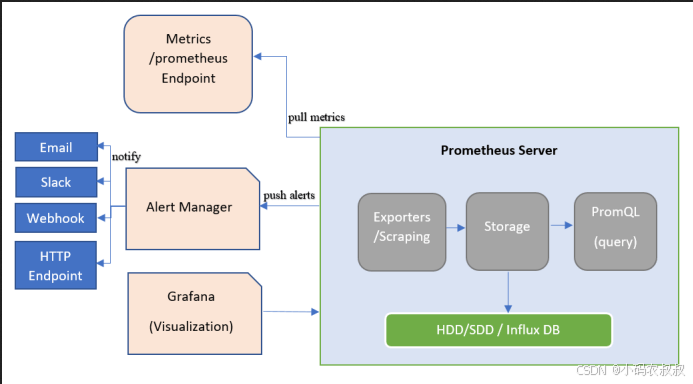
Prometheus发出告警时主要分两步:
-
Prometheus服务器按告警规则(rule_files配置块),将报警信息发送至Alertmanager(即告警规则是在Prometheus上定义的);
-
Alertmanager 接收并管理这些报警,包括去重(Deduplicating)、分组(Grouping)、沉默(silencing),抑制(inhibition),聚合(aggregation),最终通过电子邮件发出通知,对呼叫通知系统,以及即时通讯平台,将告警通知路由(route)给对应联系人。
事实上,在Alertmanager 的内部处理过程中远比这两步要复杂,为了深入了解原理,下面是更详细的处理过程:
-
警报接收
- Alertmanager 从 Prometheus server 接收警报。当 Prometheus 中定义的警报规则被触发时,Prometheus 会生成警报并发送给 Alertmanager。
-
警报去重
- Alertmanager 会对接收到的警报进行去重处理,避免同一警报被多次处理或通知,这是通过检查警报的标签组合来实现的。
-
警报分组
- Alertmanager 能够将具有相似标签的警报进行分组,这样可以减少警报数量,避免重复信息,并且使得警报更加易于管理。
-
警报抑制
- 根据配置,Alertmanager 可以抑制某些警报,防止在特定情况下警报的过度通知。例如,在大规模故障时,可能会抑制较低优先级的警报。
-
警报静默
- 用户可以设置静默规则,用来临时忽略特定警报,通常在计划的维护窗口期间使用。
-
警报状态跟踪:
- Alertmanager 会跟踪警报的状态,包括警报是否已被解决。当 Prometheus 发现警报条件不再满足时,它会发送一个状态为"resolved"的警报给 Alertmanager。
-
警报路由:
- Alertmanager 使用路由规则来决定警报应该发送给哪些接收者。这些规则可以根据警报的标签和状态来确定警报的接收者。
-
警报通知:
- 根据路由规则,Alertmanager 会将警报发送给指定的接收者。接收者可以是电子邮件、短信、Slack、PagerDuty、钉钉、企业微信等。
-
警报恢复确认:
- Alertmanager 在一段时间内未接收到 Prometheus 的警报更新,会自动将警报状态设为"恢复"(resolved),这个时间间隔可以在配置文件中设置。
-
用户交互:
- Alertmanager 提供了一个用户界面和 API,允许管理员查看警报状态、管理静默规则、查询警报历史记录等。
通过上面的步骤不难看出,Alertmanager 整个工作流程的设计目的是为了提高警报的可靠性、减少警报噪声、确保警报的及时通知以及提供有效的警报管理手段。通过上述流程,Alertmanager 成为了 Prometheus 监控体系中不可或缺的一部分,帮助用户更好地理解和应对监控系统的警报。
3.3 Altermanager在Prometheus中的位置
如下是关于Prometheus的整体架构图,Altermanager位于右上侧,简单来说,与Prometheus集成之后,一旦Prometheus收集到来自监控主机的指标信息满足告警规则,就会将其push到Altermanager。
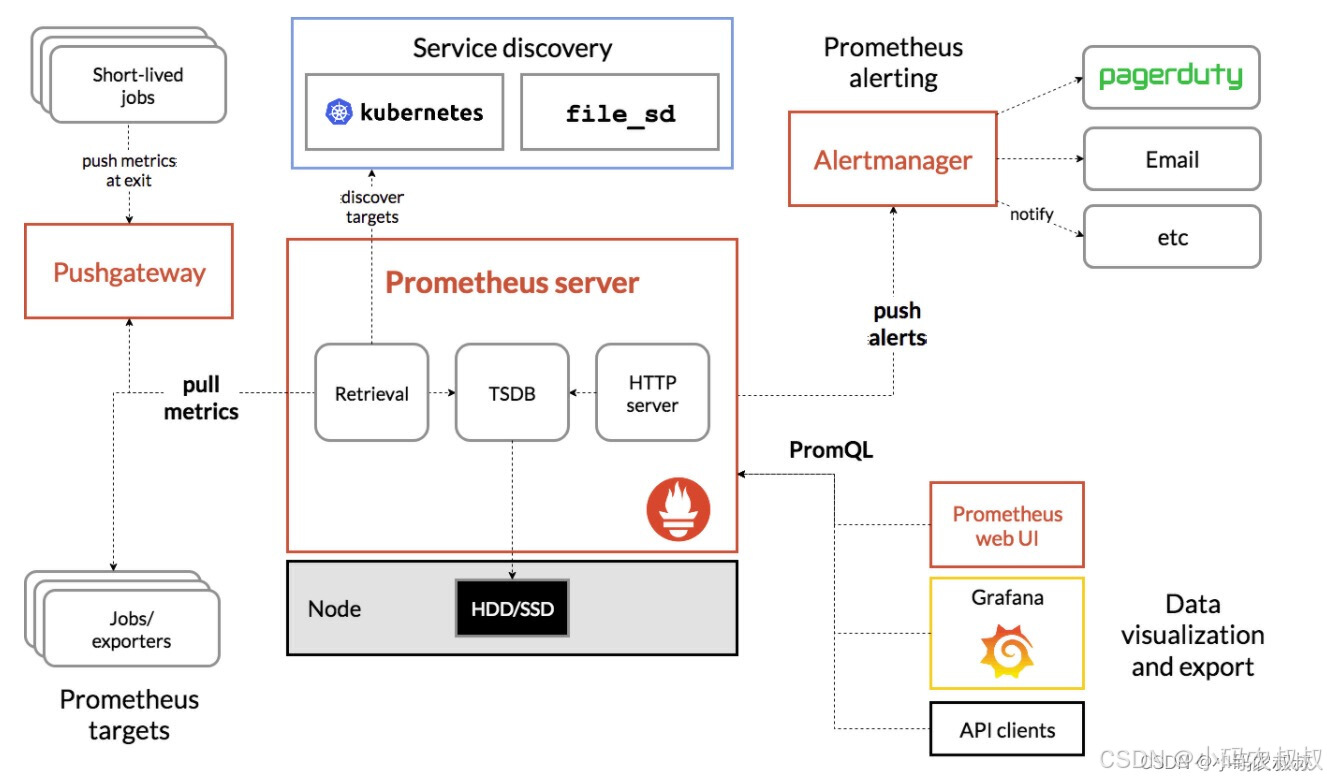
具体来说如下所示:
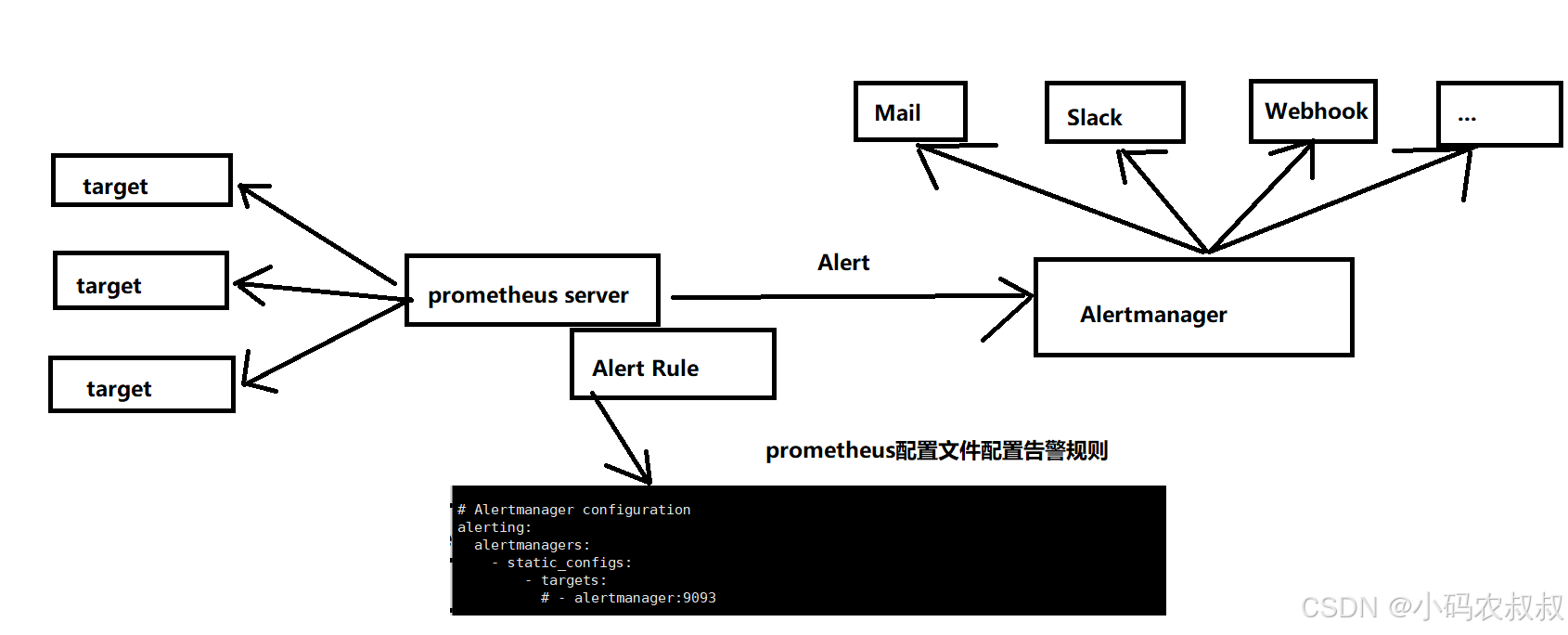
告警能力在Prometheus架构中被划分为两个部分,在上图中有所展示,通过在Prometheus配置文件中定义AlertRule(告警规则),Prometheus会周期性的进行告警规则计算,如果满足告警规则触发条件,就会向Altermanager发送告警信息。
Altermanager作为一个独立组件,负责接收处理来自Prometheus Server(也可以是其他客户端程序)的告警信息。接收到之后,Altermanager可以对这些告警信息进一步的处理,比如收到大量的重复告警信息时能够消除重复告警,同时对告警信息进行分组并且路由到正确的通知方。
同时,Prometheus内置了对邮件,Slack等多种通知方式的支持,还支持与Webhook的集成,从而支持更多的定制化场景,比如目前还支持钉钉,这样用户就可以通过Webhook与钉钉机器人进行集成,从而通过钉钉接收告警通知信息,同时,Altermanager还提供了静默告警和告警抑制功能对钉钉的告警行为进行优化。
四、Altermanager部署与接入Prometheus
通过上面的介绍初步了解了Altermanager的基本理论,接下来通过实际操作演示如何部署Altermanager服务,以及如何接入Prometheus进行使用。
4.1 Altermanager部署过程
参考下面的操作步骤
4.1.1 获取安装包
安装包下载地址:https://prometheus.io/download/
可以直接在服务器上,使用下面的命令下载:
bash
wget https://github.com/prometheus/alertmanager/releases/download/v0.27.0/alertmanager-0.27.0.linux-amd64.tar.gz4.1.2 安装包解压
使用下面的命令解压安装包
bash
tar -zxvf alertmanager-0.27.0.linux-amd64.tar.gz
4.1.3 启动alertmanager服务
进入安装包目录,使用下面的命令后台启动
bash
cd cd alertmanager-0.27.0.linux-amd64/
# 前台启动
./alertmanager --config.file=alertmanager.yml
# 后台启动alertmanager,并且重定向输入日志到当前目录的alertmanager.out
nohup ./alertmanager --config.file=alertmanager.yml >> nohup.out 2>&1 &4.1.4 访问Altermanager
访问:http://IP:9093/,默认端口为 9093,效果如下

同时,也提供了metrics的指标监控端点,如果访问 IP:9093/metrics,可以看到下面的指标信息,通过这个指标监控的端点,可以在后续接入Prometheus进行指标监控时使用
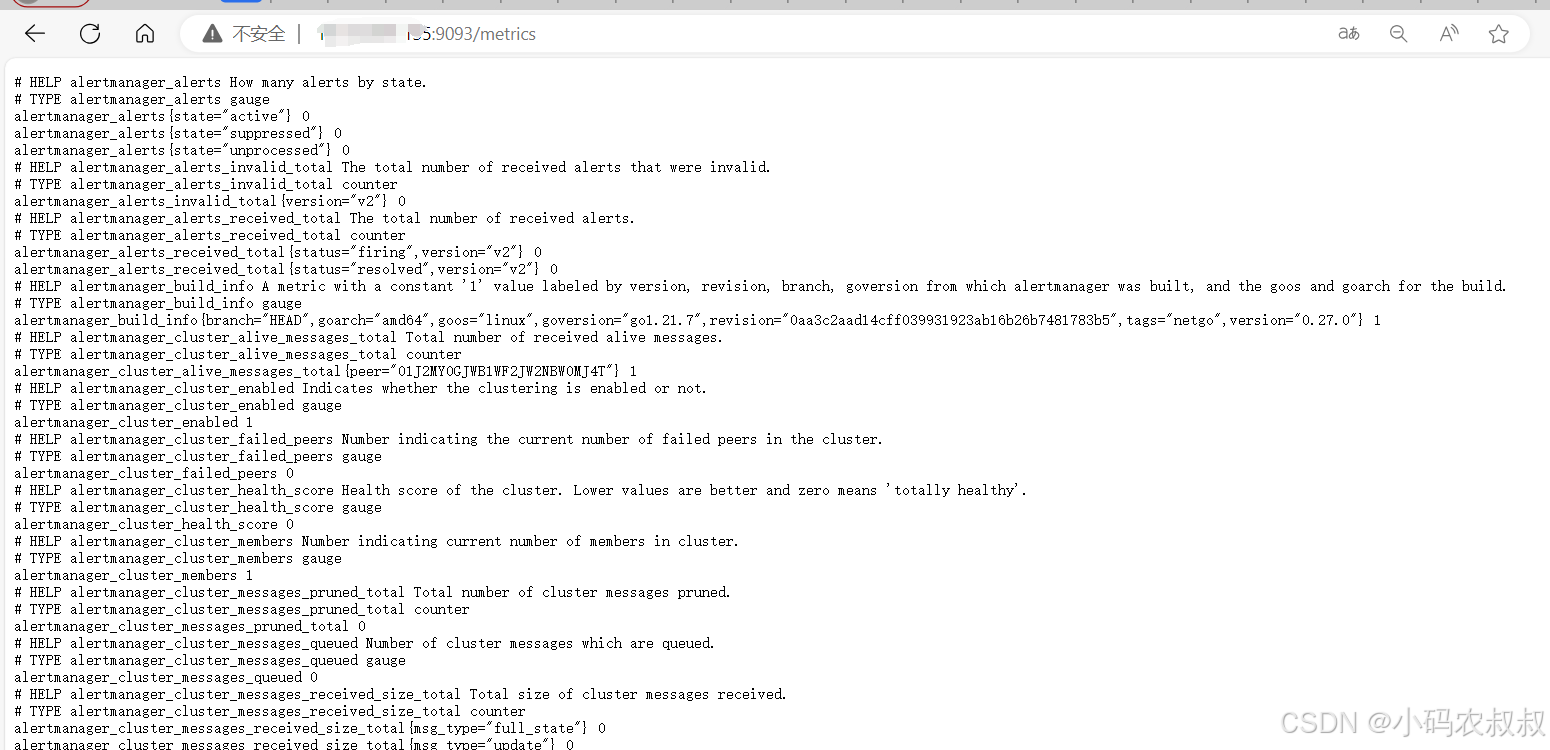
4.1.5 Altermanager核心配置文件介绍
Altermanager主要负责对Prometheus产生的告警进行统一处理,因此在Altermanager的配置中一般包含下面几个主要部分:
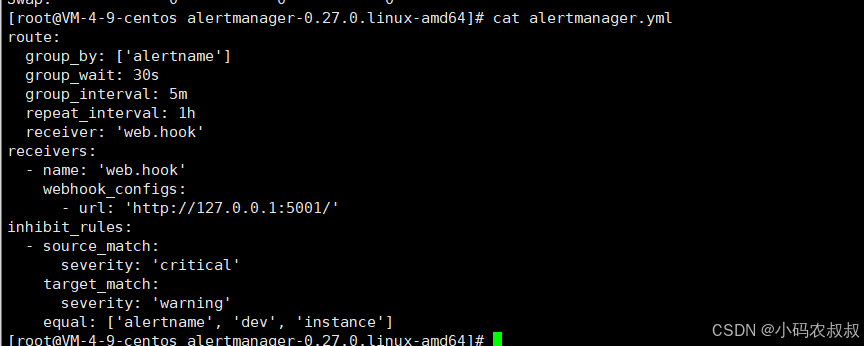
核心参数说明:
-
全局配置(global):
- 用于定义一些全局的公共参数,例如全局SMTP配置,Slack配置等内容;
-
模板(templates):
- 用于定义通知告警时的模板,例如HTML模板,邮件模板等;
-
告警路由(route):
- 根据标签匹配,确定当前告警应该如何处理;
-
接收人(receivers):
- 接收人是一个抽象概念,它可以是一个邮箱,也可以是微信、Slack或Webhook等,接收人一般配合告警路由使用;
-
抑制规则(inhibit_rules):
- 合理设置抑制规则,可以减少垃圾告警的产生;
4.2 Altermanager接入Prometheus
4.2.1 配置alert target
Altermanager与Prometheus集成也很简单,只需要在Prometheus的配置文件中稍改一下配置即可,找到Prometheus的yml文件,如下,只需要放开注释即可,默认是本机的Altermanager,如果是远程部署的Altermanager,更改为相应的IP即可,这一步是为了后续通过Prometheus将告警规则push到Altermanager;

4.2.2 配置Altermanager监控指标
像之前配置node_exporter那样,再在Prometheus的yml中添加一个Altermanager的job的配置,如下:
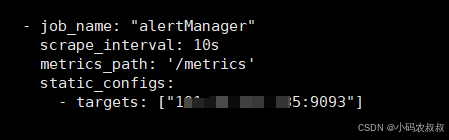
注意:以上配置完成后需要重启Prometheus
4.2.3 访问Prometheus
访问Prometheus控制台,可以看到Altermanager就纳入Prometheus进行指标监控了
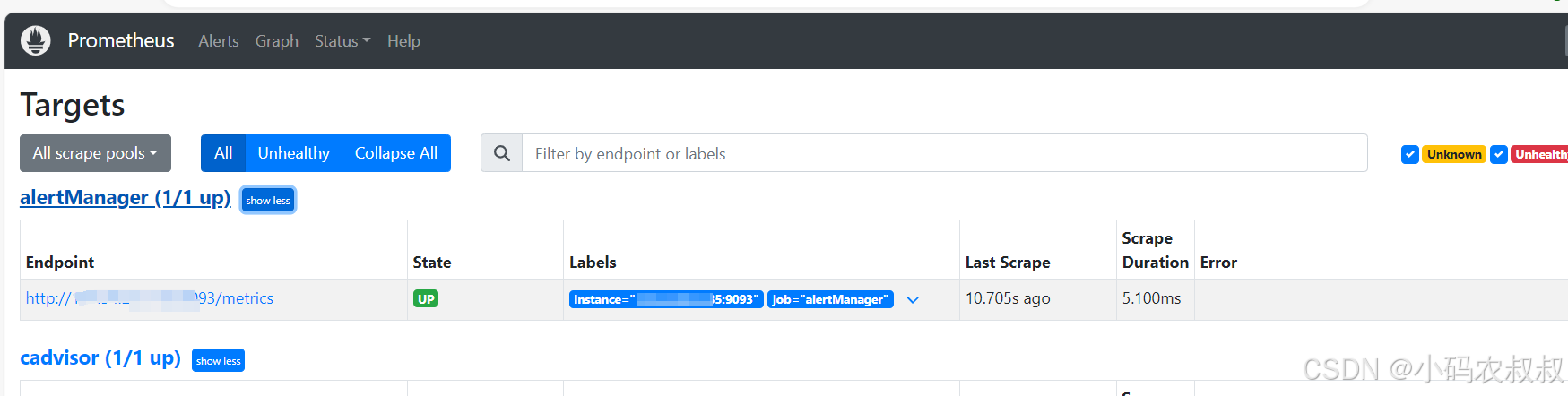
4.3 监控node_exporter
在之前的文章中我们介绍了node_exporter以及集成到Prometheus监控本机内存等指标信息,现在假如说使用node_exporter检测到机器的某些指标达到了阈值,需要进行告警,在这种情况下就可以利用Altermanager的告警功能进行集成和配置,参考下面的步骤进行操作;
4.3.1 创建rule(规则)目录和规则文件
prometheus.yml同目录下新建node.yml(文件名称和可以自行修改)
node.yml配置文内容参考如下:
bash
groups:
- name: node_exporter_alert_rule
rules:
- alert: PrometheusTargetMissing
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: 服务器宕机 (instance {{ $labels.instance }})
description: "服务器宕机,或者node exporter未启动\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostOutOfDiskSpace
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 5 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 10s
labels:
severity: warning
annotations:
summary: 主机磁盘空间不足 (instance {{ $labels.instance }})
description: "主机磁盘空间不足 (剩余 < 10% )\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostHighCpuLoad
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80
for: 0m
labels:
severity: warning
annotations:
summary: CPU使用率过高! (instance {{ $labels.instance }})
description: "CPU使用率超过 > 80%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostOutOfMemory
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
for: 2m
labels:
severity: warning
annotations:
summary: 内存使用率过高 (instance {{ $labels.instance }})
description: "内存使用率过高 (剩余< 10% )\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"以上是列举了常用的几个关于主机相关的监控规则,比如内存使用率过高,主机磁盘空间等,更多的规则可以参阅相关的资料在这里进行配置即可;
在告警规则文件中,我们可以将一组相关的规则配置定义在一个group下,在每一个group中可以定义多个告警规则,对于一条具体的告警规则来说,主要由下面几部分组成:
-
alert:指定告警规则名称;
-
expr:基于PromQL表达式的告警触发条件,用于计算是否时间序列满足该条件;
-
for:评估等待时间,可选参数,用于表示只有当触发条件持续一段时间后才发告警。而在等待期间,新产生告警的状态为pending;
-
labels:自定义标签,允许用户指定要附加到告警上的一组附加标签;
-
annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字,annotations的内容在告警产生时会一同作为参数发送到Altermanager;
4.3.2 修改prometheus.yml
在Prometheus配置文件中添加下面信息,将上述的规则文件进行加载(当然,也可以通过通配符的方式进行配置):
bash
rule_files:
- "node.yml"
#- "second_rules.yml"为了能让Prometheus启用自定义的告警规则,需要在Prometheus的全局配置文件中通过rule_files指定一组告警规则文件的访问路径,Prometheus启动的时候就会自动扫描这些规则路径下规则文件中定义的内容,并且根据这些规则计算是否向外发送通知;
4.3.3 重启Prometheus
重启Prometheus服务,然后再次进入到Prometheus的控制台,在Alert菜单下,就能看到上面的配置那几个规则信息了
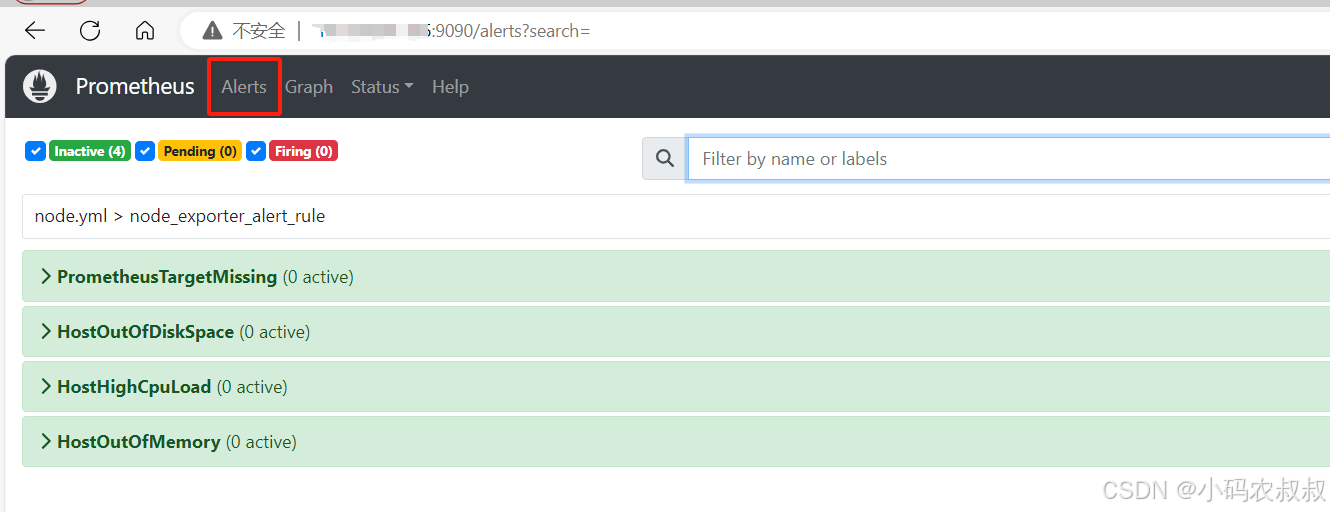
展开其中的某一项,可以看到规则的详细信息,和配置文件中的是一致的

补充说明:
在上述的界面展示中,出现了3个状态,INACTIVE,Pending,Firing ,这三个状态在下面的实际操作中会得到体现,表示被监控的服务指标满足了告警规则时的不同状态的切换。
4.3.4 测试告警规则
如何验证上述配置的告警规则是否生效呢?做第一个实验,手动关闭node_exporter服务:
bash
ps -ef|grep node_exporter
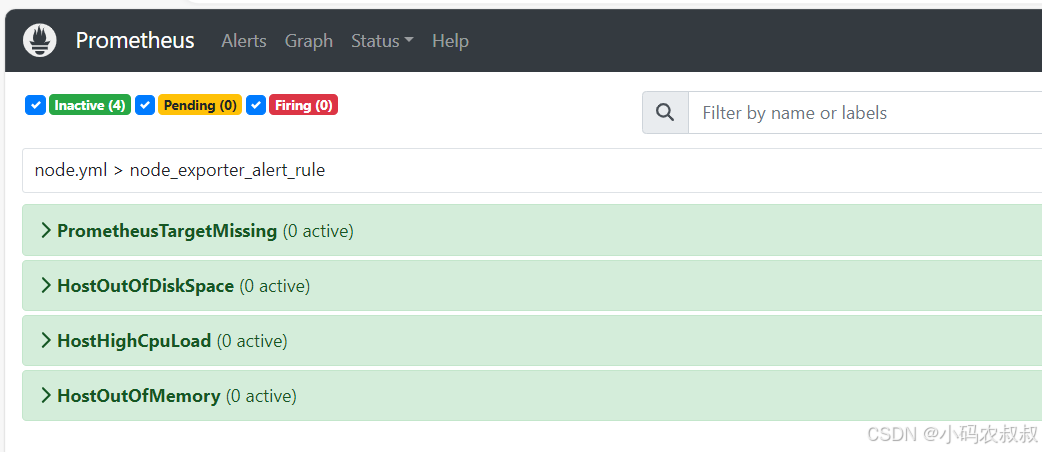
kill -9 28634Prometheus首次检测到满足触发的条件后,由于告警规则中设置了1分钟(for:1m)的等待时间,告警状态从INACTIVE,变为Pending,如下图所示:
kill之前
一分钟之后,如果告警条件持续满足,告警状态将从Pending变为Firing,并且会将告警信息推送给Alertmanager,如下图所示:
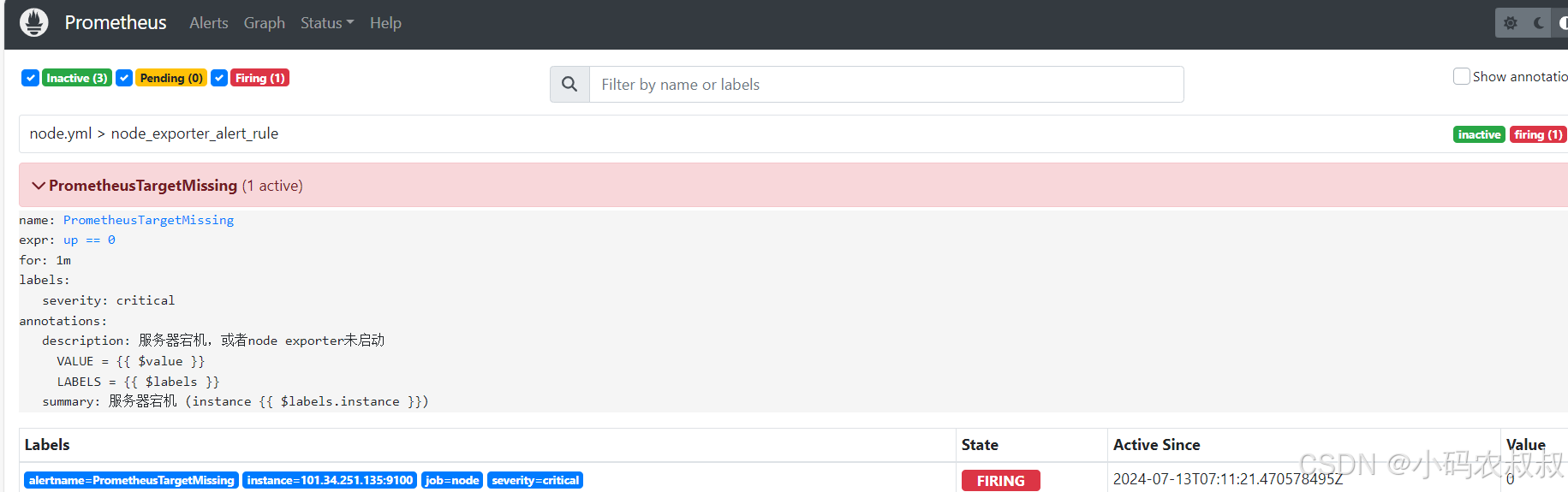
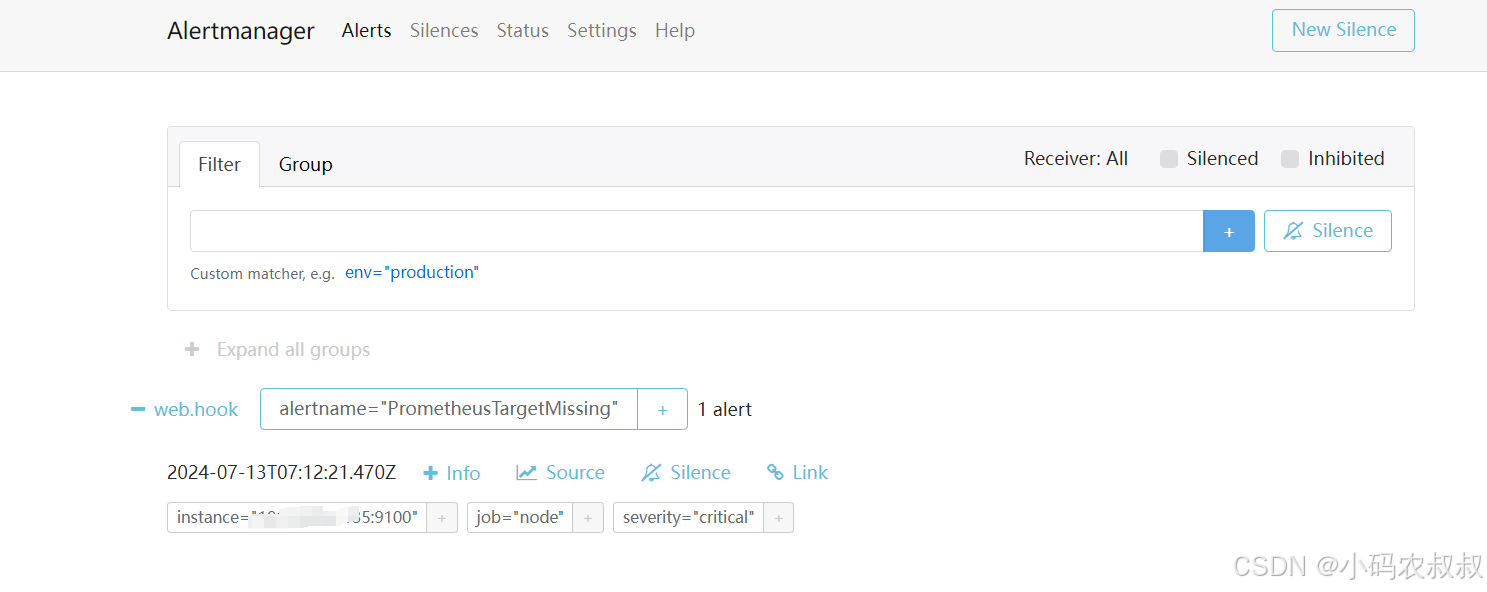
此时再次进入到Alertmanager的控制台界面上,可以看到界面上展示出了正在告警的信息
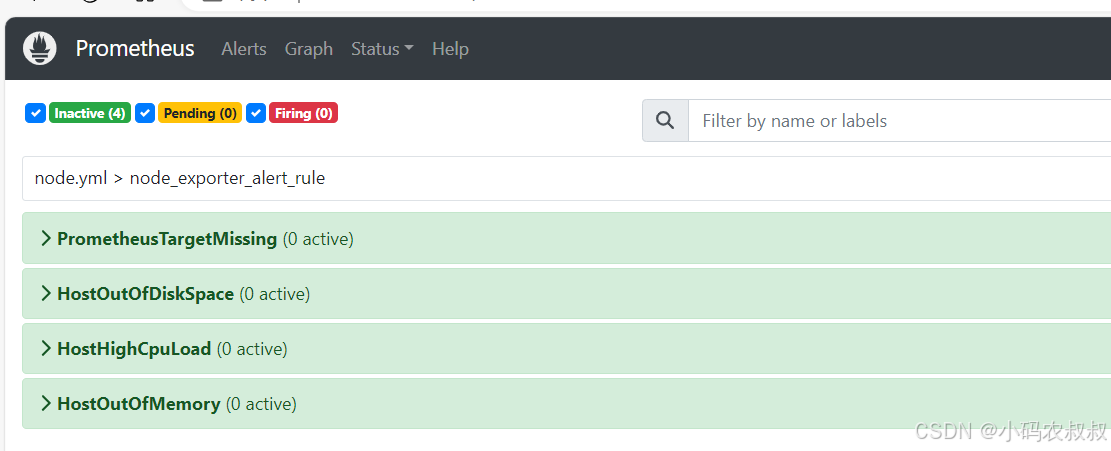
再次启动node-exporter服务,状态过一会儿就又切换回去了
五、Alertmanager配置告警推送
通过上面的操作,可以通过Alertmanager结合Prometheus对监控的指标信息进行规则的预警,事实上,在实际应用中,运维人员希望达到的目的是,当告警规则被触发的时候,能够及时以某种方式通知到相应的人员,才能第一时间对事件现场进行响应和处理,接下来演示下如何配置告警的消息推送。
5.1 Alertmanager配置邮箱告警通知
以QQ邮箱为例进行说明
5.1.1 注册QQ邮箱
如果没有的话可以提前注册一个,略
5.1.2 开启SMTP服务
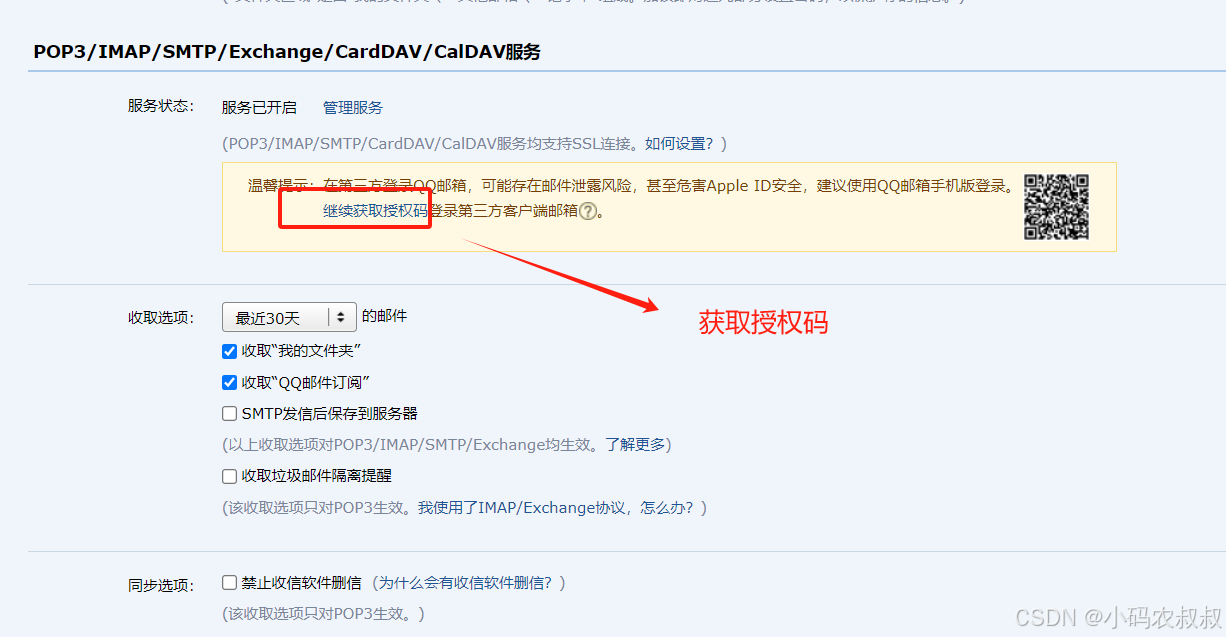
通过qq邮箱的设置,开启SMTP服务,并获取下图中的授权码,下文配置中会用到
5.1.3 配置alertmanager.yml
在该配置文件中配置如下信息
bash
global:
# 在3分钟内未收到新的相同告警,则认为告警已解决
resolve_timeout: 3m
# QQ邮箱SMTP服务器地址和端口,通常使用465端口,SMTPS
smtp_smarthost: 'smtp.qq.com:465'
# 从这个邮箱发送告警
smtp_from: '你的QQ@qq.com'
# 发送告警的邮箱账号
smtp_auth_username: '你的QQ@qq.com'
# 邮箱的第三方授权码,而不是普通密码
smtp_auth_password: 'vuqmvptmxowwzdbbec'
#根据你的SMTP服务器设置决定是否需要TLS加密
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
#receiver: 'web.hook'
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '你的QQ@qq.com'
send_resolved: true
#抑制规则
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']5.1.4 重载配置文件
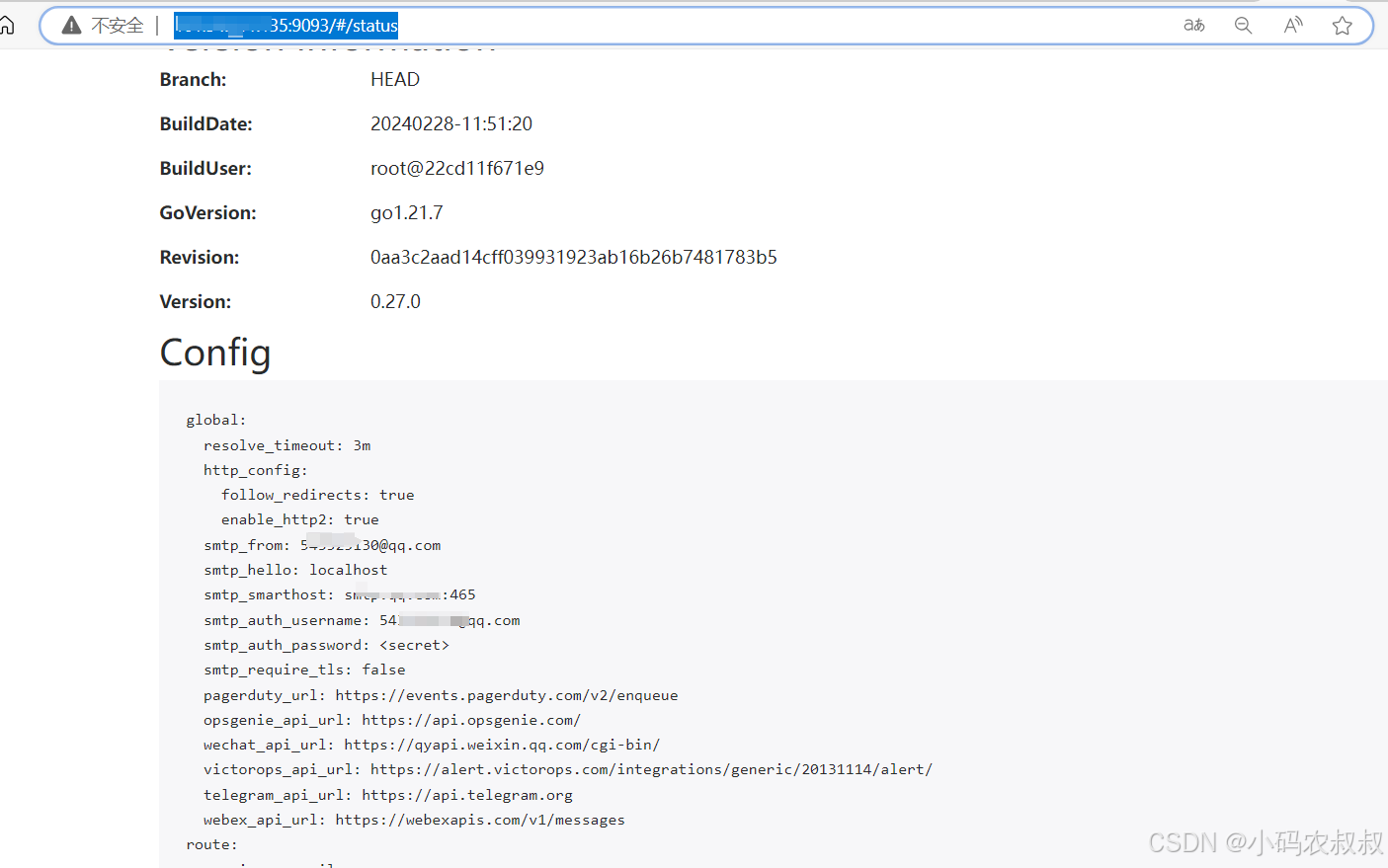
重启Alertmanager服务,重启完成后,再次进入Alertmanager页面,通过status菜单可以看到,上述配置得邮箱信息就展示出来了
5.1.5 效果验证
仍然以上面配置的node-exporter为例,我们关闭该服务,理论上在1分钟之后Prometheus会检测到服务的宕机信息从而满足触发告警规则条件,从而向Alertmanager推送告警信息,上面配置了邮箱之后,Alertmanager就能将信息发送至接收的邮箱中;
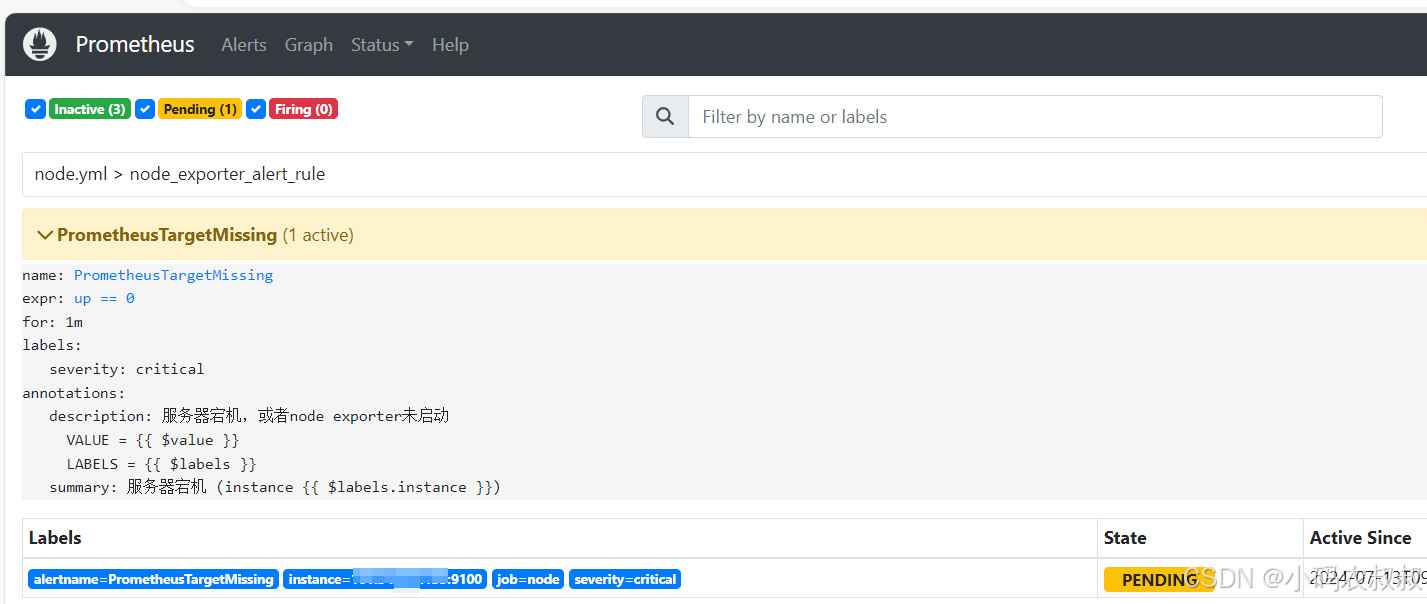
将node-exporter服务kill掉之后,等待1分钟,可以看到node_exporter配置的告警规则被触发,状态也变成了Pending;
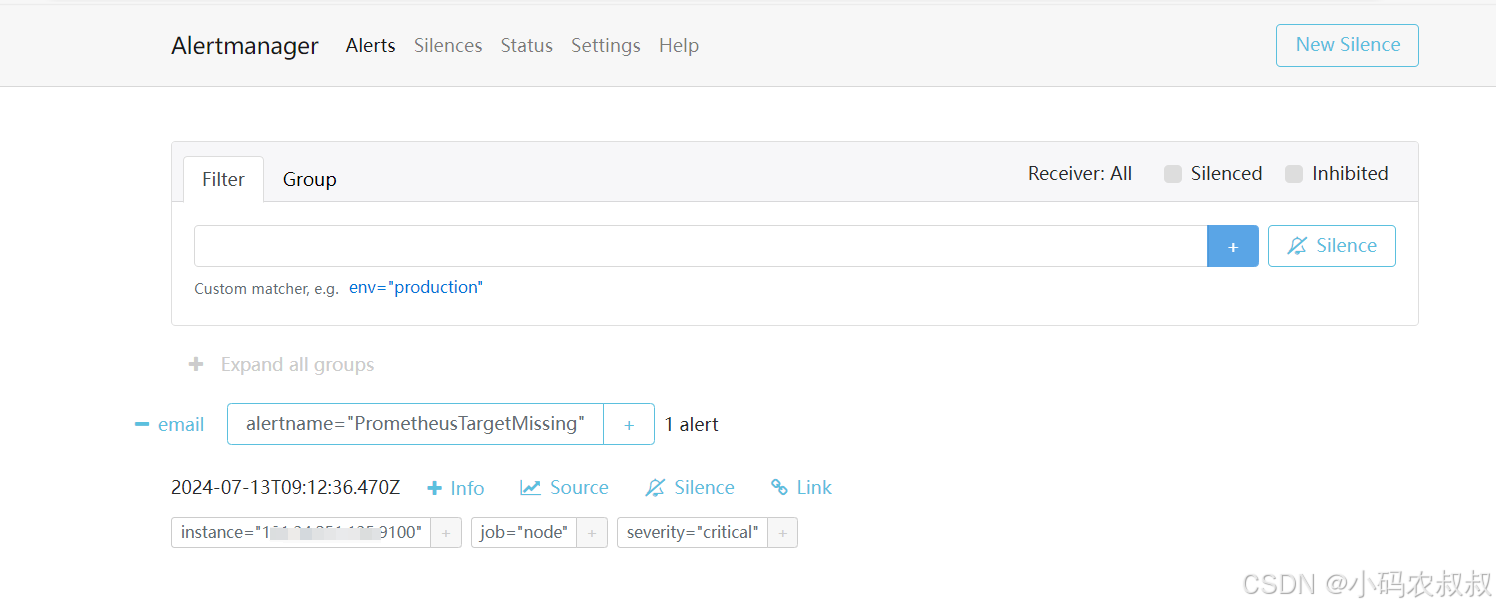
同时alertmanager控制台也输出了相应的信息
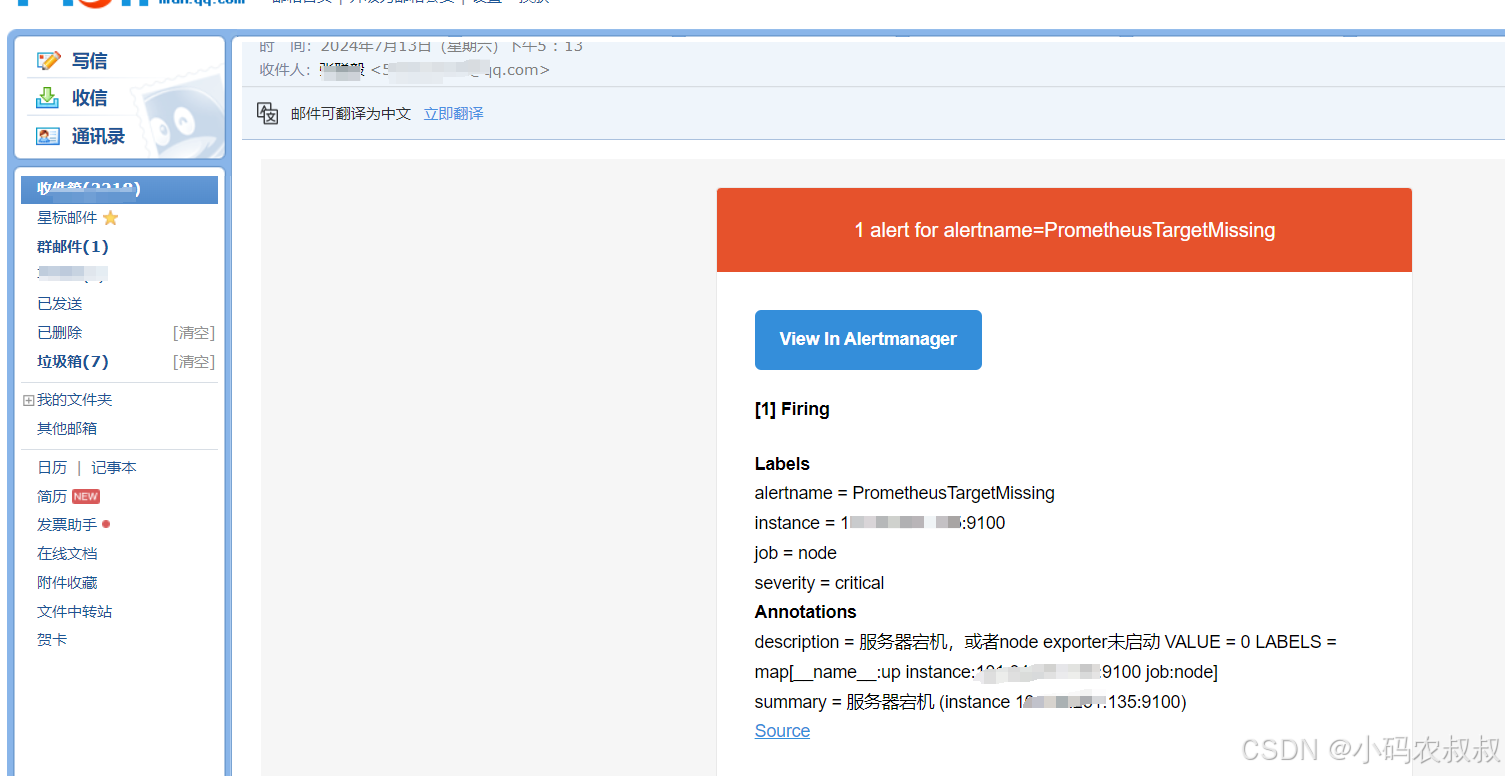
此时进入个人的QQ邮箱,可以看到一封告警通知邮件
关于邮件的告警推送,也可以采用自定义邮件模板进行配置,网上关于这块的资料也比较多,基于上面的配置简单做下调增即可
5.2 Alertmanager配置钉钉告警通知
接下来演示如何将告警通知通过钉钉进行消息推送
5.2.1 配置钉钉机器人
创建钉钉群,找到群设置中的机器人
点击添加机器人
选择自定义webhook
配置如下信息
- 注意拷贝上面的Webhook地址和下面的加签信息,后面配置中会用到;
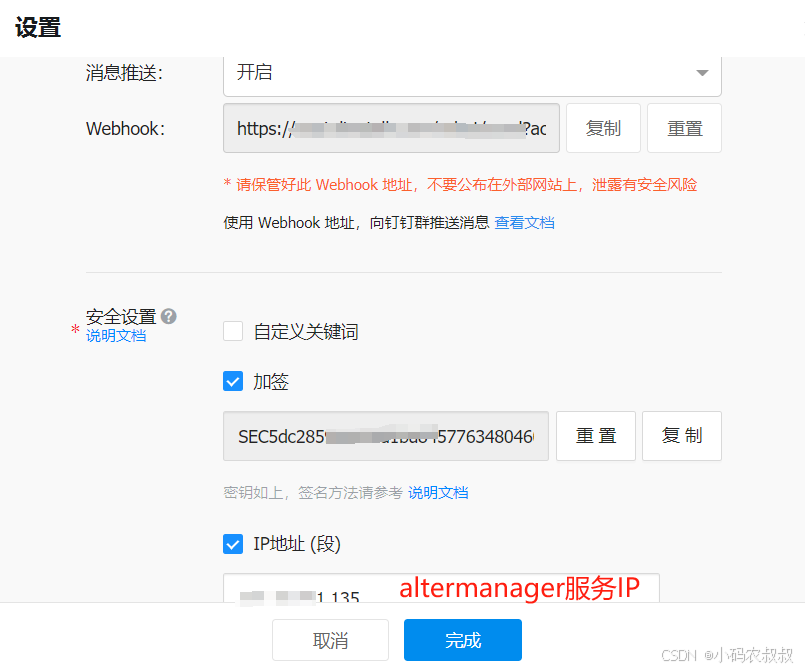
点击完成然后就可以看到,机器人已经创建完成
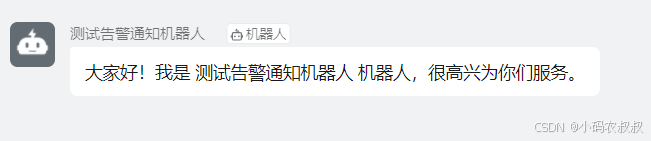
5.2.2 获取钉钉webhook插件包
alertmanger必须通过webhoo插件才能将告警发送到钉钉/微信/飞书,因此,需要先安装webhook插件,安装方式有二进制、docker和源码,这里直接运行二进制文件
webhook插件官方地址:GitHub - timonwong/prometheus-webhook-dingtalk: DingTalk integration for Prometheus Alertmanager
下载插件
bash
wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v2.1.0/prometheus-webhook-dingtalk-2.1.0.linux-arm64.tar.gz解压插件安装包
bash
tar xf prometheus-webhook-dingtalk-2.1.0.linux-arm64.tar.gz 修改目录名称
bash
mv prometheus-webhook-dingtalk-2.1.0.linux-arm64 prometheus-webhook-dingtalk 5.2.3 修改配置文件信息并启动服务
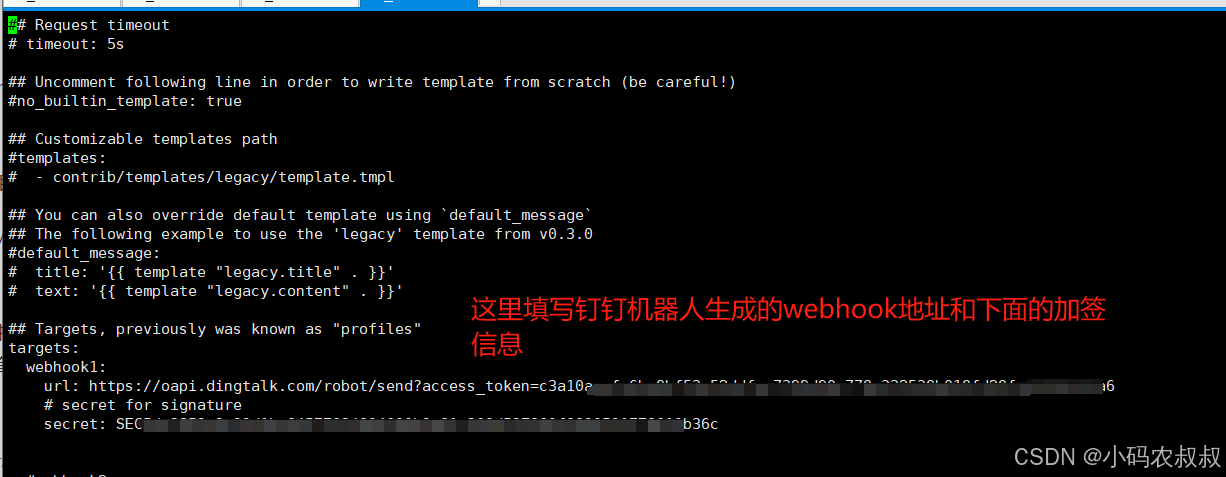
进入上述webhook的目录,修改yml配置文件,配置信息如下,这里可以暂时先配置一个webhoo即可,其他的可以暂时注释掉
最后使用下面的命令进行启动
bash
./prometheus-webhook-dingtalk --config.file=./config.yml --web.enable-ui &5.2.4 使用docker的方式安装
如果仍然觉得使用上面插件包的方式弄起来麻烦,可以使用下面的docker-compose的方式做;
创建一个config.yml配置文件
配置如下内容,webhook的信息改为你自己的即可
bash
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=aa06a9c58dfa03080c46cd243f3e81560e43d66da434d0a84ecbe2954bc58c
secret: SEC85684de209427ba29a4d20541e86b62520068ffb3fef2dfca91af2485627c3创建docker-compose.yml文件
配置如下内容
bash
version: '3.3'
services:
webhook:
image: timonwong/prometheus-webhook-dingtalk:v2.1.0
container_name: prometheus-webhook-dingtalk
ports:
- 8060:8060
command:
- '--config.file=/etc/prometheus-webhook-dingtalk/config.yml'
volumes:
- /usr/local/soft/pro/prometheus-webhook-dingtalk/config.yml:/etc/prometheus-webhook-dingtalk/config.yml
- /etc/localtime:/etc/localtime:ro启动docker服务
使用docker-compose命令启动
bash
docker-compose up -d
使用docker命令检查下容器是否启动

访问8060端点,访问地址:IP:8060,浏览器看到下面的效果说明钉钉的webhook插件服务已经可以使用
5.2.5 修改altermanager的配置
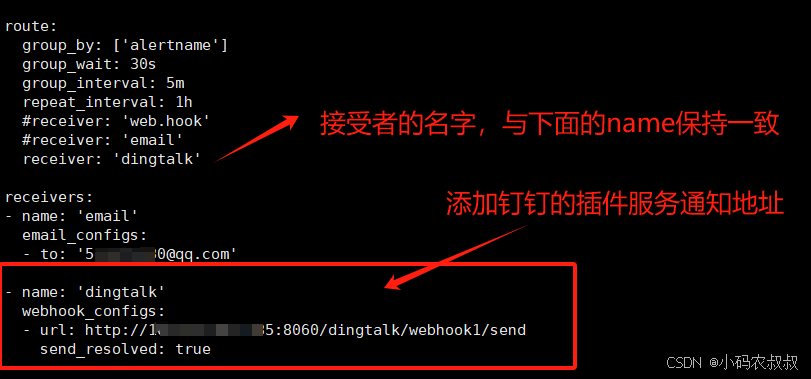
进入altermanager安装目录,找到alertmanager.yml,配置钉钉的webhook信息,如下:
5.2.6 重启altermanager服务
重启之后,模拟5.1中的操作,我们将node_exporter服务进行手动kill,在Prometheus上面可以看到如下信息
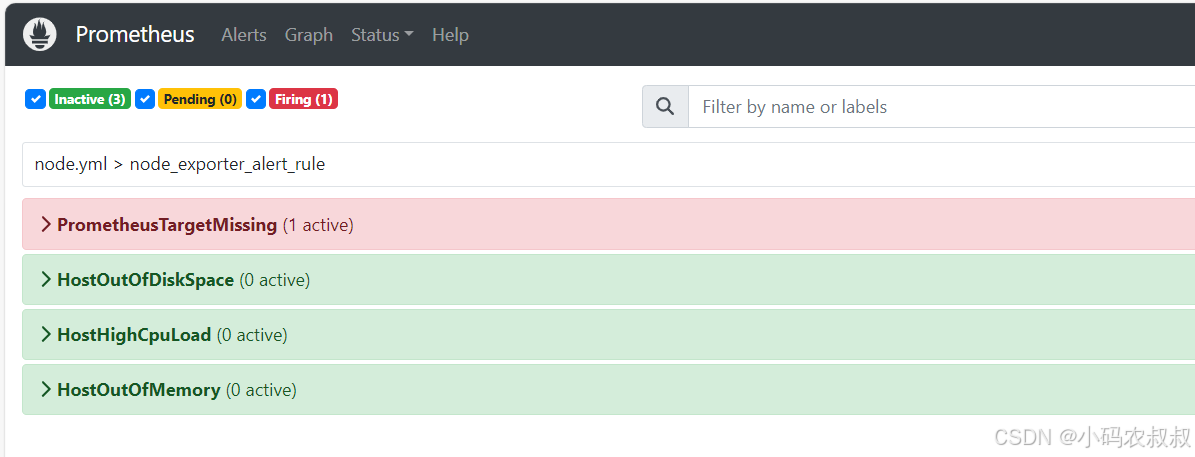
等待一分钟之后,由于满足了告警规则的触发条件,此时将告警信息推送到了钉钉的webhook地址,然后再在钉钉群中就能收到通知信息了,如下:
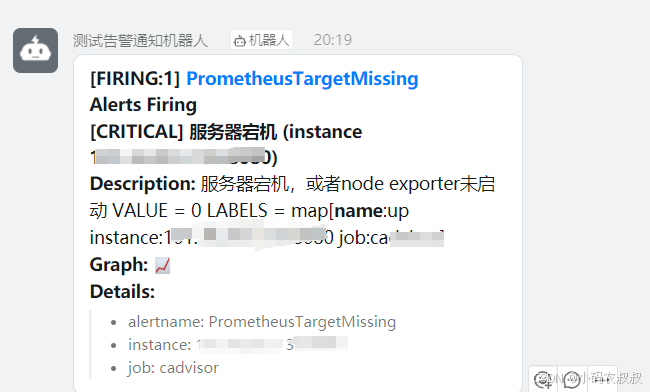
5.2.7 补充说明
上面总结来说做了两个示例演示,一个是通过node_exporter的服务启动和宕机模拟,验证是否能够正常触发告警规则,然后,再通过将告警规则中配置的信息,以邮件或钉消息的方式进行推送,基于此,如果在实际项目中进行应用,只需要参照类似的模式,先定义待监控的指标告警规则,然后配置告警规则被触发之后推送到指定的通知服务,或者webhook地址即可。
六、写在文末
本文通过实际案例详细介绍了Alertnamager的使用,并结合Prometheus配置告警触发规则,将告警信息推送到特定的通知服务,在实际项目中具有一定的实用和参考价值,希望对看到的同学有用,本篇到此结束,感谢观看。