Jmeter实战
1、需求
查询某个接口在高并发场景下的响应时间(loadtime),需求需要响应在50ms以内,接下来用Jmeter测试一下
Jmeter安装见文章《Jemeter安装教程,Windows下Jemeter详细安装》
2、实现
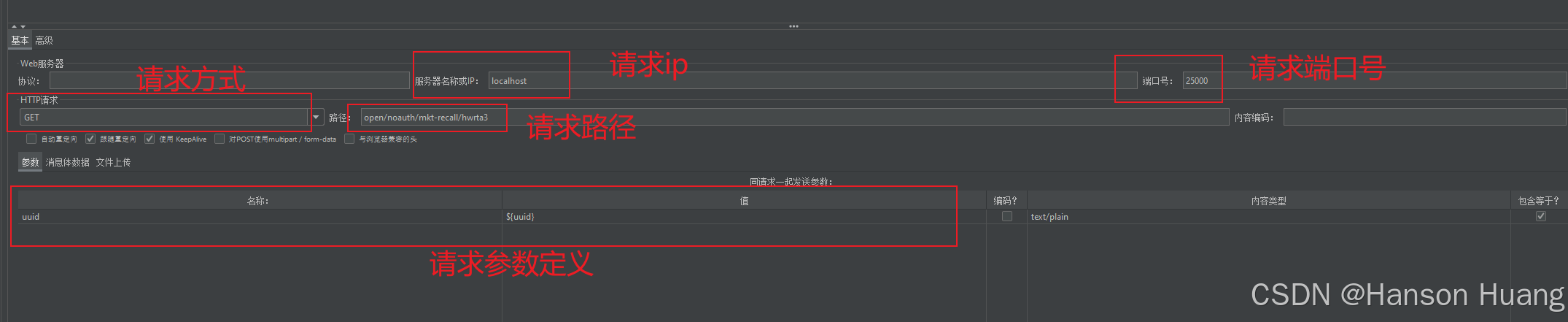
请求接口 :localhost:25000/open/noauth/mkt-recall/hwrta3?uuid=xxxx
底层逻辑:根据uuid缓存,缓存能查到直接返回,缓存不能查到,查数据库,然后更新缓存
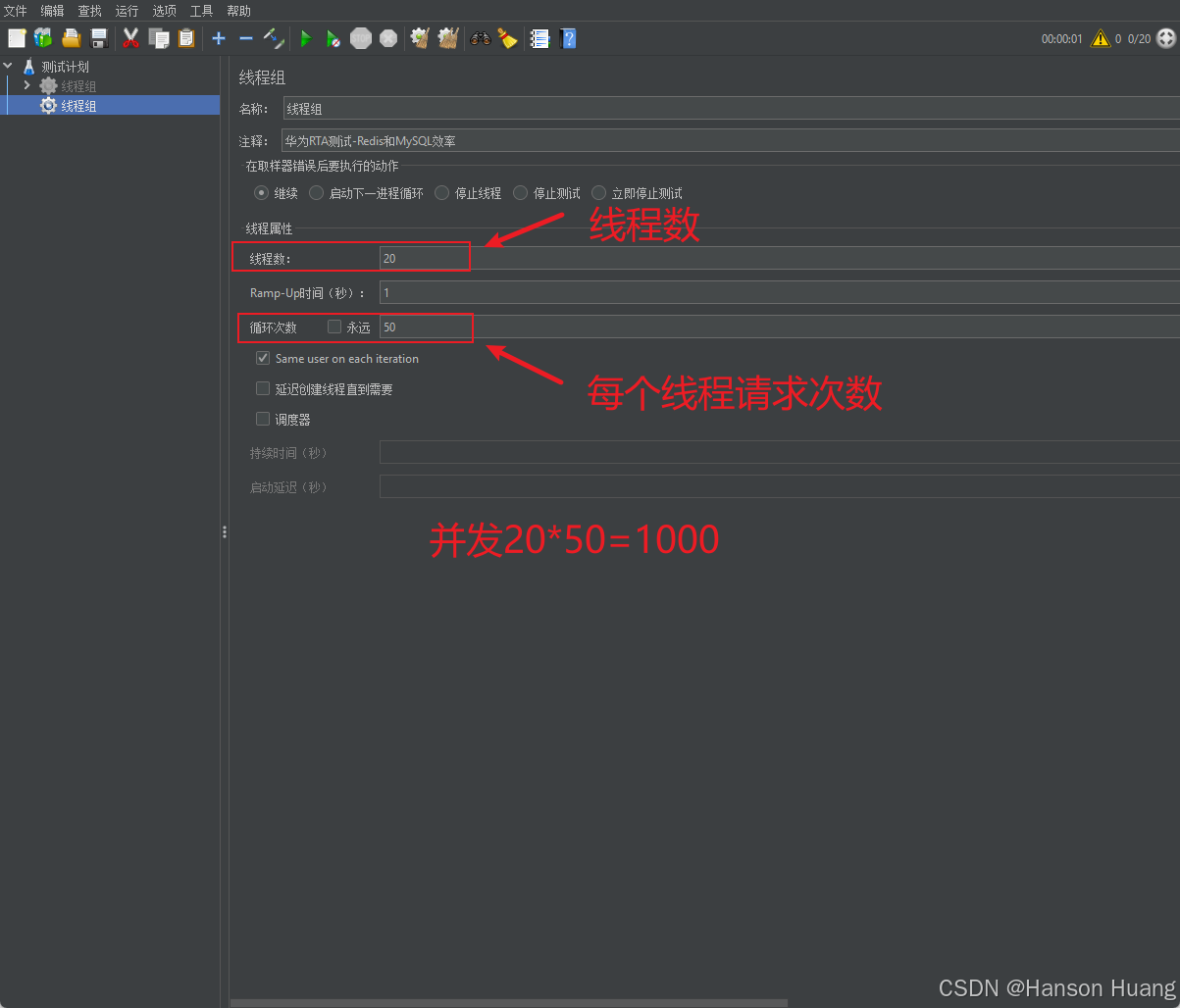
方案:现选取20个uuid,每个uuid请求50次,不污染线上环境,现以开发环境为例子
2.1、新建线程组
添加线程组

添加如下参数
2.2、导入参数
我选择使用csv导入参数
首先去数据库找出20个能用的uuid
sql
select distinct(uuid) FROM t_track_active limit 20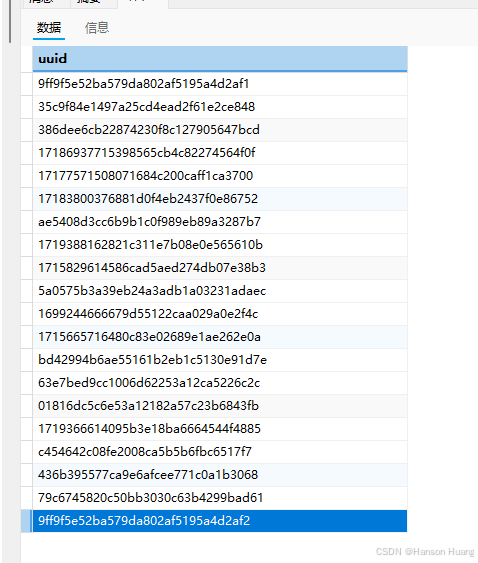
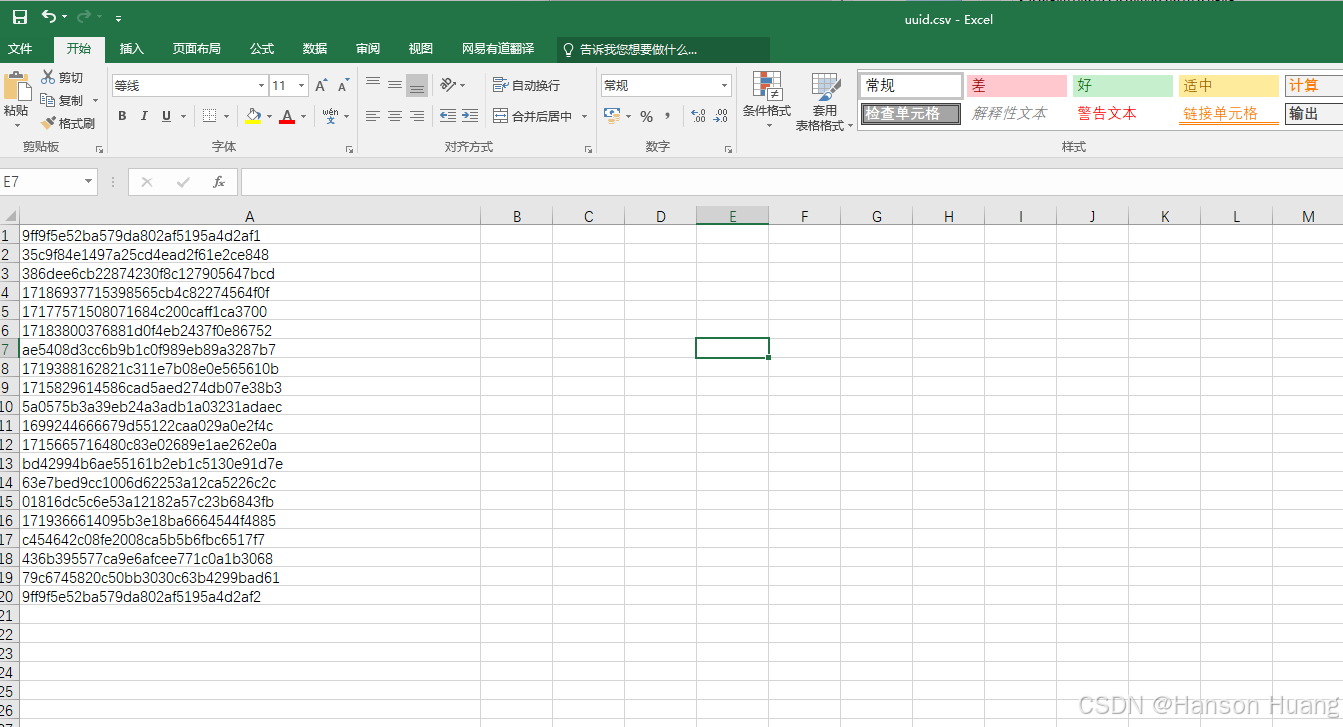
然后将数据导入csv中(建议先用xlsx写,然后另存为.csv格式,防止乱码)
然后右击线程组,添加配置元件中的CSV Data Set Config
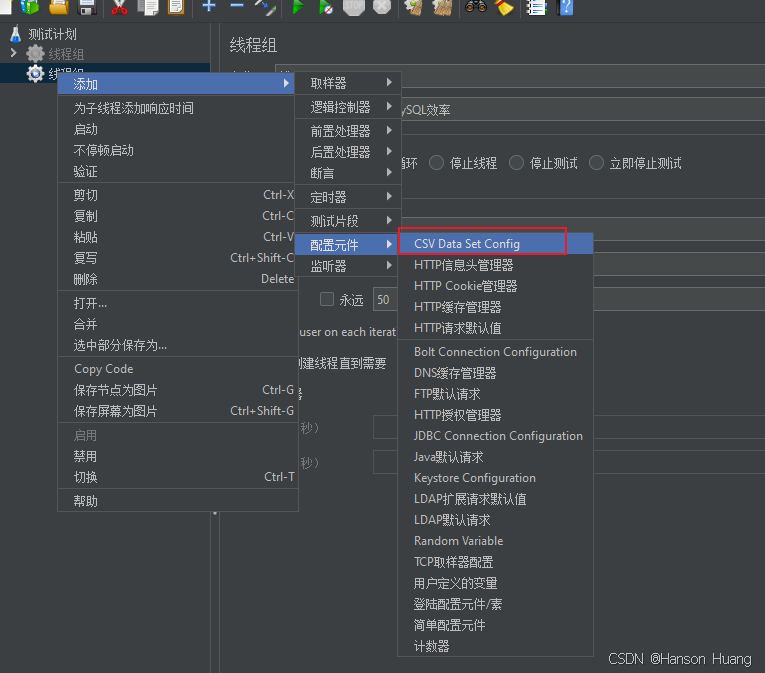
输入文件名和变量名称

2.3、新建HTTP请求
如下
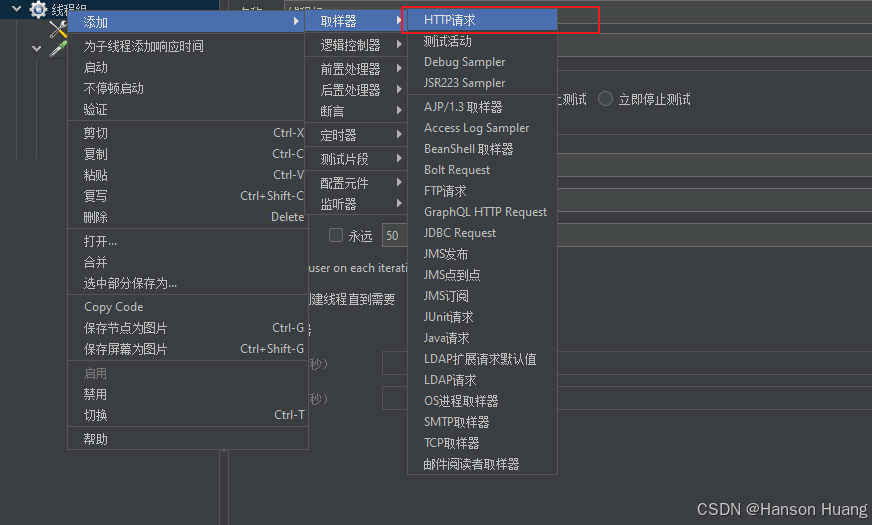
- 配置 HTTP 请求的参数:
- Server Name or IP: 输入目标服务器的域名或 IP 地址。
- Path: 输入请求路径。
- Method: 选择请求方法(例如 GET 或 POST)。
- 在请求参数中,使用 ${uuid} 引用 CSV 文件中的 UUID 值。
2.4、添加监听器
添加查看结果树和汇总报告两个监听器
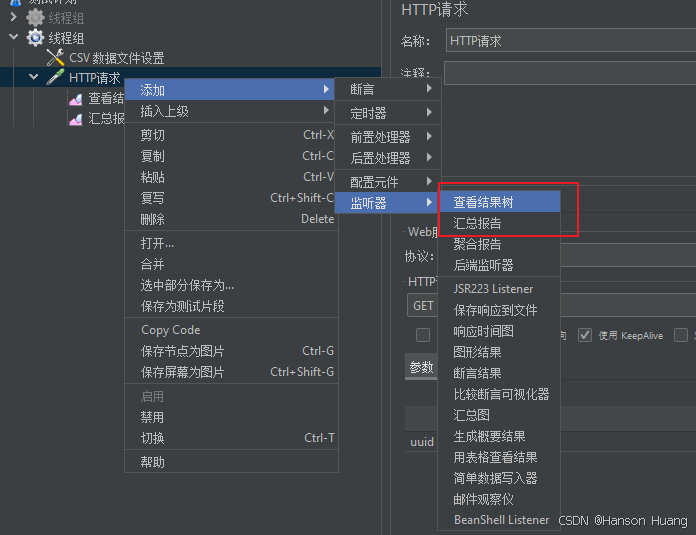
配置完目录如下:

点击绿色箭头运行
2.5、结果
查看结果树中就有响应数据


-
Thread Name: 线程组 1-11,表示这是"线程组 1"中的第 11 个线程执行的请求。
-
Sample Start: 2024-07-19 18:36:51 CST,表示请求开始的时间,是在 2024 年 7 月 19 日 18:36:51(CST 时间)。
-
Load time: 13,表示请求从开始到完成的总时间(毫秒)。在这个例子中是 13 毫秒。
-
Connect Time: 0,表示建立连接所花费的时间(毫秒)。在这个例子中是 0 毫秒,意味着连接已经是复用的(例如,HTTP Keep-Alive)。
-
Latency: 13,表示请求从开始到接收到第一个字节的时间(毫秒)。在这个例子中也是 13 毫秒,表明整个请求响应时间和接收到第一个字节的时间相同。
-
Size in bytes: 762,表示整个响应的大小(字节),包括 headers 和 body。在这个例子中是 762 字节。
-
Sent bytes: 187,表示发送的请求大小(字节)。在这个例子中是 187 字节。
-
Headers size in bytes: 162,表示响应 headers 的大小(字节)。在这个例子中是 162 字节。
-
Body size in bytes: 600,表示响应 body 的大小(字节)。在这个例子中是 600 字节。
-
Sample Count: 1,表示这个请求样本的数量。在这个例子中是 1。
-
Error Count: 0,表示请求错误的数量。在这个例子中是 0,意味着没有错误。
-
Data type ("text"|"bin"|""): text,表示响应的数据类型。在这个例子中是文本(text)。
-
Response code: 200,表示 HTTP 响应码。在这个例子中是 200,意味着请求成功。
-
Response message: OK,表示 HTTP 响应消息。在这个例子中是 OK,通常与响应码 200 一起出现,表示请求成功。
-
HTTPSampleResult fields:,包含一些附加信息。
-
ContentType: application/json,表示响应的 Content-Type。在这个例子中是 application/json,意味着响应是 JSON 格式。
-
DataEncoding: null,表示响应的字符编码。在这个例子中是 null,意味着没有特定的字符编码信息。

运行测试后,点击汇总报告监听器,你会看到以下列:
- Label: 请求名称
- Samples: 样本数
- Average: 平均负载时间(Load time)
- Min: 最小负载时间
- Max: 最大负载时间
- Std. Dev.: 标准差
在 Average 列中,你可以看到平均负载时间为17ms。
现在我们清除一下树,在运行一次
查看汇总报告
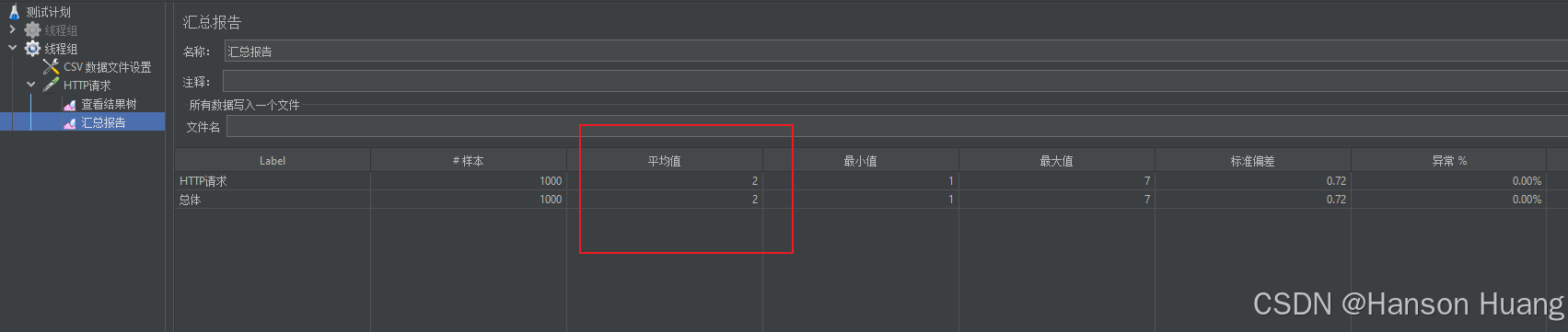
平均loadtime来到了2ms,第一遍走数据库平均是17ms,第二遍查的缓存,平均是2ms,所以缓存速度还是比数据库快很多
