初赛A:烟草营销案例数据分析
AB题综合难度不大,难度可以视作0.4个国赛,题量可以看作0.35个国赛题量。适合于国赛前队伍练手,队伍内磨合。竞赛获奖率50%,八月底出成绩,参赛人数3000队左右。本文将为大家进行A题的超详细解题思路+部分代码分享
钉钉杯赛中分享资料(问题一代码+论文+思路)链接(18点更新)
链接:https://pan.baidu.com/s/16o5y5Gxu2NDa9mGxshbnvw
提取码:sxjm
对于数据类型的题目,首先就是应该进行数据预处理,这里由于每一问题都涉及不同的数据集,因此对于该问题的数据预处理。我们应该分问进行,下面主要对问题一涉及的数据进行详细的说明,后面仅作展示处理。
-
数据预处理数据清洗-缺失值异常值处理
-
对于题目中,存在明显的极大值以及极小值。例如2013 12这个数据当月销量只有0.4箱子该数据与其他正常数据差异过大,应进行必要的数据处理。例如,应该将该异常值使用箱型图等方面进行判定,对于判定结果进行剔除处理。对于剔除后产生的空缺值使用插值的方法进行填充。

例如,我们以A1 A2为例,首先将进行正态分布的判定,对于正态分布的数据使用3西格玛原则判定异常值,对于非正态分布的数据使用箱型图判定异常值。将判定结果替换为缺失值,进行插值填充。

进行判定,得出A1的数据均不服从正态分布,A2的数据服从正太分布。因此,需要对不同的数据进行不同的处理。
数据可视
绘制时间序列图,观察数据趋势、周期性和季节性。

数据显示,销售金额在2013年和2014年出现了明显的高峰。之后的几年中,销售金额总体呈现下降趋势,直到2018年后趋于平稳。从2011年到2017年,销售金额的长期趋势呈下降态势。2017年以后,趋势有所回升,并逐渐趋于平稳。数据显示,每年某些月份的销售金额显著增加,表现出较强的季节性波动。这个季节性模式在各年间基本保持一致。残差部分显示出较大的波动性,但没有明显的系统性趋势。这些波动反映了数据中随机和不可预测的部分。【论文内容:图形文字描述】
问题一二都涉及到了选择两种不同的数学预测模型,这里我们将常见的预测模型放于文章最后,供大家参考使用。理论上所有的模型都是正确的、都是可以使用的。在数学建模是没有答案的,因此也没有对错,仅仅只有使用的适配度和精度问题。所以文末的各种模型都是可以使用的
1. 预测A1、A2品牌的销量
对未来销量进行预测:使用历史销售数据构建2个不同类型的时间序列预测模型,分别对 A1、A2香烟品牌的未来销量进行数据预测,目标为表中最后空白项。自行选择和设计模型类型 、参数、结构。
对于问题一预测模型的选择多种多样只要符合预测条件即可,这里给出其中两种的步骤
模型选择:
- ARIMA(AutoRegressive Integrated Moving Average)模型:
-
参数选择:使用AIC/BIC准则选择最优的p, d, q参数。
-
模型训练:拟合ARIMA模型,并进行预测。
-
结果评价:使用RMSE、MAE等评价指标衡量模型性能。
- Prophet模型:
-
数据处理: 转换数据格式以适应Prophet模型。
-
模型训练: 拟合Prophet模型,并进行预测。
-
结果评价: 使用RMSE、MAE等评价指标衡量模型性能。

|-----------------------|--------------------------------------|-----------------------|----------------------|
| 模型名称 | 描述 | 优点 | 缺点 |
| ARIMA | 结合自回归和移动平均,适用于非平稳时间序列数据 | 适用于平稳和非平稳数据;参数选择较灵活 | 需要手动选择参数;对数据要求较高 |
| SARIMA | 在ARIMA基础上增加季节性部分,适用于季节性时间序列数据 | 能够捕捉季节性变化;适用于周期性波动的数据 | 参数较多,选择复杂;计算复杂度高 |
| Prophet | 由Facebook开发,适用于具有多种季节性和假期效应的时间序列数据 | 易于使用;对异常值和缺失值鲁棒 | 适用于较长时间序列数据;短期预测效果较差 |
| LSTM | 基于神经网络,能够捕捉长时间序列依赖关系,适用于复杂的非线性数据 | 能够捕捉长期依赖关系;适用于复杂非线性数据 | 需要大量数据训练;训练时间长,计算资源高 |
| Exponential Smoothing | 通过对历史数据加权平均来预测未来值,包括单、双和霍尔特-温特斯季节性模型 | 简单易用;计算速度快 | 对复杂数据预测效果较差;不能捕捉长 |
2. 预测A3、A4品牌的销售金额
对销售金额进行预测:使用历史销售数据构建2个不同类型的时间序列预测模型,分别对 A3、A4香烟品牌的销售金额进行数据预测,目标为表中最后空白项。自行选择和设计模型类型 、参数、结构。
模型选择:
- SARIMA(Seasonal ARIMA)模型:
-
参数选择: 使用AIC/BIC准则选择最优的p, d, q, P, D, Q, m参数。
-
模型训练: 拟合SARIMA模型,并进行预测。
-
结果评价: 使用RMSE、MAE等评价指标衡量模型性能。
- LSTM(Long Short-Term Memory)模型:
-
数据处理: 标准化数据,创建适合LSTM模型的输入格式。
-
模型构建: 构建并训练LSTM神经网络模型。
-
结果评价: 使用RMSE、MAE等评价指标衡量模型性能。

3. 集成学习模型构建
集成学习:在上述分别对销量及销售金额预测模型的基础上,构建集成学习模型,实现 对A5香烟品牌的销量和销售金额的联合预测。集成学习模型不局限于上述问题中建立的模型, 可新增,以最终性能为评判标准。
目标: 对A5品牌的销量和销售金额进行联合预测。
步骤:
1、 ARIMA模型选择和训练:
遍历 p、d 和 q 参数的所有可能组合(从0到2),选择AIC值最小的参数组合。
使用最佳参数组合训练ARIMA模型,并进行10步预测。
2、 Prophet模型训练和预测:
将数据转换为Prophet模型所需的格式(列名分别为 ds 和 y)。使用Prophet模型进行10步预测。
3、 构建集成学习模型(Stacking):
将ARIMA和Prophet模型的预测结果作为特征,实际值作为目标变量,使用线性回归模型作为元学习器进行训练。使用训练好的线性回归模型生成最终的集成学习预测结果。
4、 评价模型:
计算集成学习模型的均方误差(MSE)和平均绝对误差(MAE)。
对比ARIMA模型和Prophet模型的MSE和MAE,评估各模型的性能。
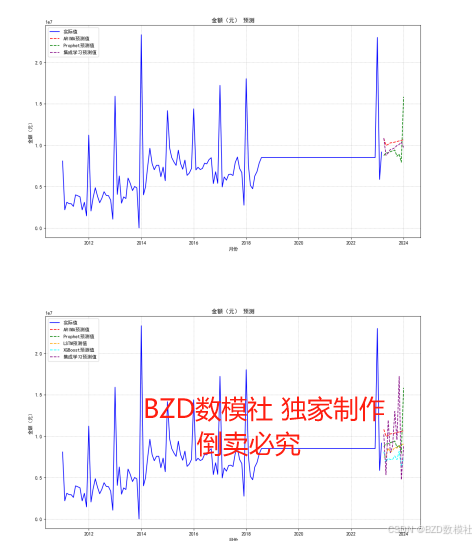
绘制实际值、ARIMA预测值、Prophet预测值和集成学习预测值的时间序列图。
BZD数模社 独家制作