使用 Python 示例代码进行介绍(ft. Mistral-7b)
欢迎来到雲闪世界。如何使用 OpenAI 对 LLM 进行微调?然而,这种方法的主要限制在于 OpenAI 的模型隐藏在其 API 后面,这限制了我们可以用它们构建的内容和方式。在这里,我将讨论使用开源模型和 QLoRA 对 LLM 进行微调的另一种方法。

微调 是指我们采用现有模型并针对特定用例进行调整。这是最近人工智能创新爆炸式增长的关键部分,催生了 ChatGPT 等。
尽管微调是一个简单(且功能强大)的想法,但将其应用于 LLM 并不总是那么简单。关键挑战在于LLM 的计算成本(非常)高(即它们不是可以在普通笔记本电脑上训练的东西)。
例如,对 70B 参数模型进行标准微调需要超过 1TB 的内存 1。作为参考,A100 GPU 配备高达 80GB 的内存,因此你(最多)需要十几张这种价值 20,000 美元的显卡!
虽然这可能会打消您构建自定义 AI 的梦想,但请不要放弃。开源社区一直在努力使使用这些模型进行构建变得更容易。从这些努力中萌生的一种流行方法是QLoRA(量化低秩自适应) ,这是一种在不牺牲性能的情况下微调模型的有效方法。
什么是量化?
QLoRA 的一个关键部分是所谓的量化 。虽然这听起来像是一个可怕而复杂的词,但它是一个简单的想法。当你听到"量化 ," 考虑到将一系列数字分成几部分。
例如,0 到 100 之间有无数可能的数字,例如 1、12、27、55.3、83.7823 等等。我们可以量化这个范围,将它们分成基于整数的桶,这样 (1, 12, 27, 55.3, 83.7823) 就变成了 (1, 12, 27, 55, 83),或者我们可以使用十的因子,这样数字就变成了 (0, 0, 20, 50, 80)。此过程的可视化如下所示。
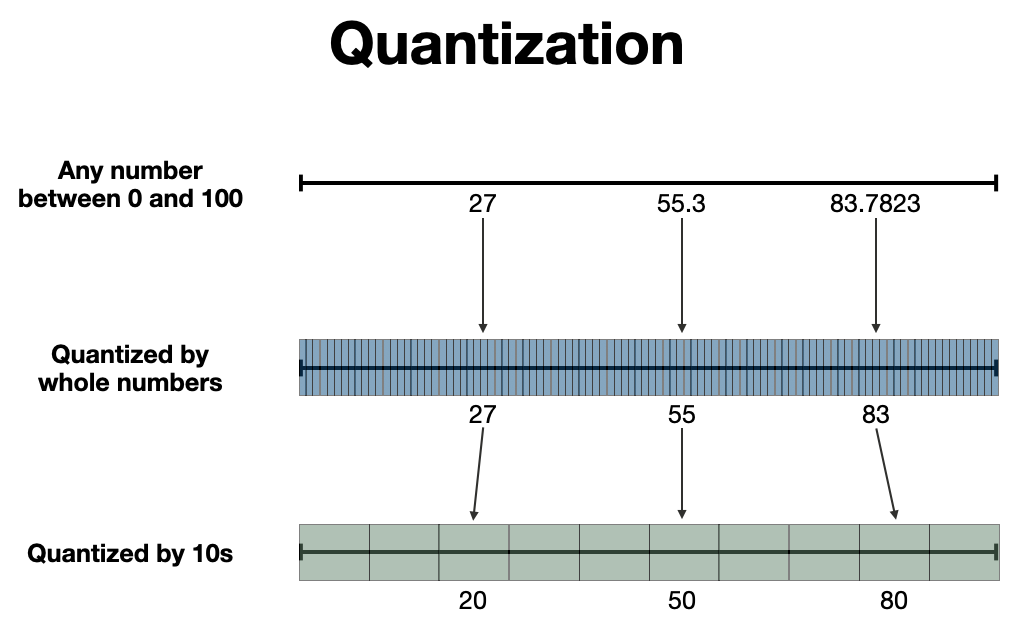 通过整数或 10 来量化数字的可视化
通过整数或 10 来量化数字的可视化
为什么我们需要它
量化使我们能够用较少的信息 来表示给定的一组数字。要了解这为何重要,让我们(简要地)谈谈计算机的工作原理。
计算机使用二进制数字(即位)对信息进行编码。例如,如果我想让计算机记住数字 83.7823,则需要将该数字转换为由 1 和 0 组成的字符串(即位串)。
其中一种方法是通过单精度浮点格式 (即FP32),将数字表示为 32 位序列 2。例如,83.7823 可以表示为 01000010101001111001000010001010 3。
由于 32 位字符串具有 2³²(= 4,294,967,296)个唯一组合,这意味着我们可以用 FP32 表示 4,294,967,296 个唯一值。因此,如果我们有从 0 到 100 的数字,则位数设置表示该范围内数字的精度。
但事情 还有另一面。如果我们用 32 位来表示每个模型参数,每个参数将占用 4 字节内存(1 字节 = 8 位)。因此,一个 10B 参数的模型将消耗 40 GB 内存。如果我们要进行全参数微调,则需要接近 200GB 的内存! 1
这给 LLM 微调带来了一个难题。也就是说,我们希望 模型训练成功,**但又需要尽可能少地使用内存,**以确保内存不会耗尽。平衡这一权衡是 QLoRA 的一项重要贡献。
量子LoRA
QLoRA(量化低秩自适应)结合了 4 种成分,可 在不牺牲模型性能的情况下充分利用机器有限的内存。我将简要总结每种成分的要点。更多详细信息请参阅 QLoRA 论文 4。
要素 1:4 位 NormalFloat
第一个要素将量化的概念推向了实际极限。与用于语言模型参数的典型 16 位数据类型(即半精度浮点)不同,QLoRA 使用一种称为4 位 NormalFloat的特殊数据类型。
顾名思义,此数据类型仅用 4 位对数字进行编码。虽然这意味着我们只有 2⁴(= 16)个存储桶来表示模型参数,但 4 位 NormalFloat 使用一种特殊技巧来充分利用有限的信息容量。
量化一组数字的简单方法就是我们之前看到的,我们将数字分成等间距的 桶 。然而,更有效的方法是使用大小相等的桶。这两种方法的区别如下图所示。
 等间距桶和等大小桶之间的区别
等间距桶和等大小桶之间的区别
更具体地说,4 位 NormalFloat 采用信息理论最优量化策略来处理正态分布数据 4。由于模型参数倾向于聚集在 0 附近,因此这是一种表示 LLM 参数的有效策略。
要素 2:双重量化
尽管名字不太恰当,但双重量化可以通过 量化量化常数来节省内存(明白我的意思了吧)。
为了分解这一点,请考虑以下量化过程。给定一个 FP32 张量,量化它的一个简单方法是使用下面的数学公式 4。

从 FP32 到 Int8 的简单量化公式。示例来自 4。图片由作者提供。
在这里,我们将 FP32 表示转换为 -127, 127 范围内的 Int8(8 位整数)表示。请注意,这归结为重新缩放张量X^(FP32)中的 值 ,然后将其四舍五入为最接近的整数。然后,我们可以通过定义缩放项(或量化常数) c^FP32 = 127/absmax(X^FP32)) 来简化方程。
虽然这种简单的量化方法在实践中并不是这样实现的(记得我们在 4 位 NormalFloat 中看到的技巧),但它确实说明了量化会带来一些计算开销,需要将结果常量存储在内存中。
我们可以通过只执行一次此过程来最大限度地减少此开销。换句话说,为所有模型参数计算一个量化常数。然而,这并不理想,因为它对极值非常敏感。换句话说,由于 c^FP32中的 *absmax()*函数,一个相对较大的参数值会使所有其他参数值产生偏差。
或者,我们可以将模型参数划分为更小的块进行量化。这降低了大值扭曲其他值的可能性,但会占用更大的内存空间。
为了降低内存成本,我们可以(再次)采用量化 ,但现在是针对这种分块方法生成的常量。对于 64 的块大小,FP32 量化常数会增加 0.5 位/参数。通过进一步量化这些常数(例如 8 位),我们可以将此占用空间减少到 0.127 位/参数 4。
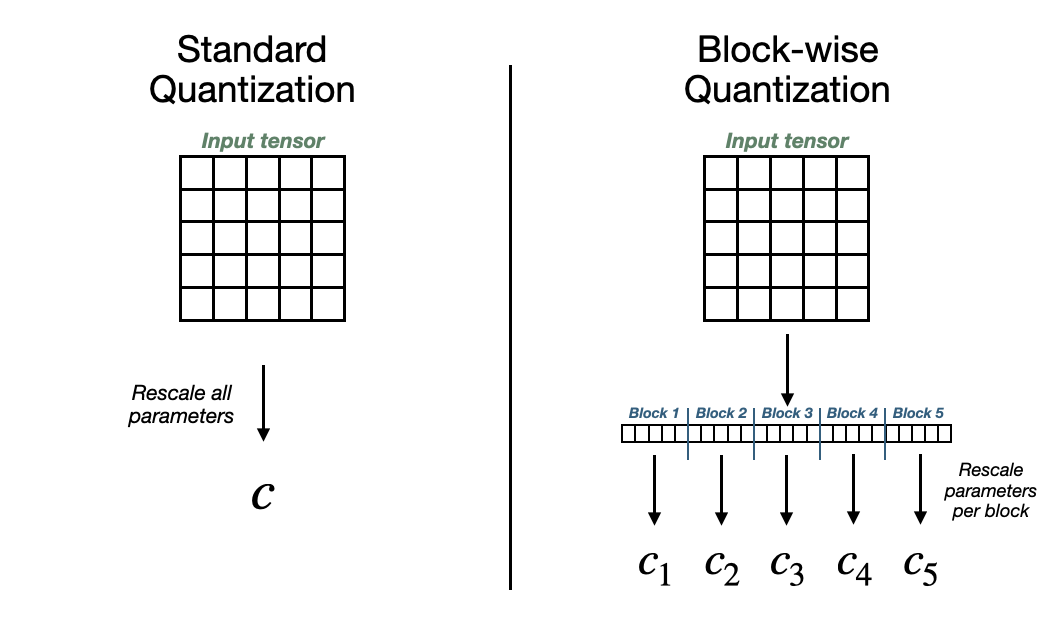 标准量化与块量化的视觉比较
标准量化与块量化的视觉比较
要素 3:分页优化器
该组件使用 Nvidia 的统一内存功能来帮助避免训练期间出现内存不足错误。当 GPU 达到极限时,它会将"页面"内存从 GPU 传输到 CPU。这类似于CPU RAM 和机器存储之间处理内存的方式4。
更具体地说,此内存分页功能会根据需要将优化器状态页面移至 CPU 并移回 GPU。这很重要,因为在训练期间可能会出现间歇性的内存峰值,这可能会导致进程终止。
要素4:LoRA
LoRA(低秩自适应) 是一种参数高效微调 (PEFT) 方法。其关键思想是,LoRA 不会重新训练所有模型参数,而是在保持原始参数不变的情况下添加相对较少数量的可训练参数5
总结
现在我们知道了 QLoRA 的所有要素,让我们看看如何将它们组合在一起。
首先,考虑一个标准的微调过程 ,它包括重新训练每个模型参数。这可能看起来像是使用 FP16 作为模型参数和梯度(总共 4 个字节/参数),使用 FP32 作为优化器状态,例如动量和方差,以及参数(12 个字节/参数)1。因此,一个10B 参数模型需要大约 160GB 的内存来进行微调。
使用 LoRA,我们可以通过减少可训练参数的数量来立即降低计算成本。这通过冻结原始参数并添加一组(小型)适配器来容纳可训练参数 5 来实现。模型参数和梯度的计算成本与以前相同(总共 4 个字节/参数)1。
但是,节省的内存 来自优化器状态 。如果我们的可训练参数减少了 100 倍,并且适配器使用 FP16,那么原始模型中每个参数将多出 0.04 字节(而不是 4 字节/参数)。同样,如果优化器状态使用 FP32,那么每个参数将多出 0.12 字节 4。因此,10B 参数模型需要大约 41.6GB 的内存来微调。节省了大量内存,但对消费级硬件的要求仍然很高。
QLoRA 通过使用成分 1 和 2 量化原始模型参数,从而更进一步。这将成本从 4 字节/参数降低到大约 1 字节/参数。然后,通过以与以前相同的方式使用 LoRA,这将增加另外 0.16 字节/参数。因此,**仅需 11.6GB 内存即可对 10B 模型进行微调!**这可以轻松在消费级硬件上运行,例如 Google Colab 上的免费 T4 GPU。
下面显示了这三种方法的视觉比较4。
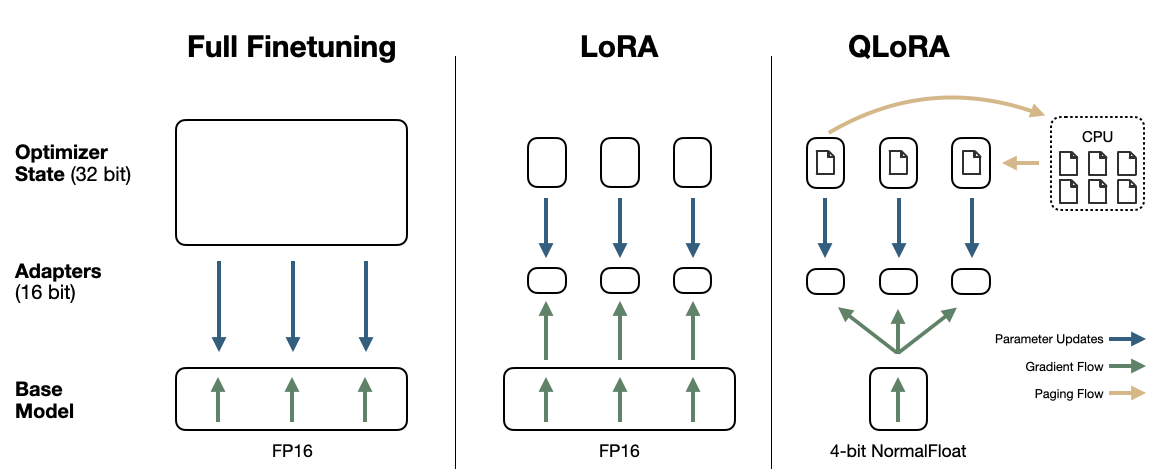
3 种微调技术的视觉比较。基于 4 中的图
示例代码:微调 Mistral-7b-Instruct 以回应 YouTube 评论
现在我们对 QLoRA 的工作原理有了基本的了解,让我们看看它在代码中的使用方式。在这里,我们将使用TheBloke和 Hugging Face 生态系统提供的 Mistral-7B-Instruct 模型的 4 位版本进行微调。
此示例代码可在Google Colab 笔记本中找到,可在 Colab 提供的(免费)GPU 上运行。该数据集也可在 Hugging Face 上找到。
导入
我们从 Hugging Face 的transforms 、peft 和datasets库中导入模块。
ba
从transformers导入AutoModelForCausalLM、AutoTokenizer、pipeline
从peft导入prepare_model_for_kbit_training
从peft导入LoraConfig、get_peft_model
从datasets导入load_dataset
导入transformers此外,我们需要安装以下依赖项才能使一些先前的模块正常工作。
ba
!pip 安装 auto-gptq
!pip 安装 optimal
!pip 安装 bitsandbytes加载基础模型和标记器
接下来,我们从 Hugging Face 加载量化模型。这里我们使用TheBloke 准备的 Mistral-7B-Instruct-v0.2版本,他已经免费量化并分享了数千个LLM。
请注意,我们使用的是 Mistral-7b 的"Instruct"版本。这表明该模型已经过指令调整 ,这是一个微调过程 ,旨在 提高模型在回答问题和响应用户提示方面的性能。
除了指定我们要下载的模型 存储库之外,我们还设置了以下参数:device_map 、trust_remote_code 和revision。device_map 让该方法自动找出如何最好地分配计算资源以在机器上加载模型。接下来,trust_remote_code=False 可防止自定义模型文件在您的机器上运行。最后,revision指定我们要从存储库中使用哪个版本的模型。
ba
model_name = "TheBloke/Mistral-7B-Instruct-v0.2-GPTQ"
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
trust_remote_code=False,
revision="main") 加载后,我们看到 7B 参数模型仅占用4.16GB 内存,这可以轻松容纳 Colab 上免费提供的 CPU 或 GPU 内存。
接下来,我们为模型加载标记器。这是必要的,因为模型需要以特定方式对文本进行编码。
ba
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)使用基础模型
接下来,我们可以使用该模型进行文本生成。首先,让我们尝试向模型输入测试评论。我们可以分 3 步完成此操作。
首先 ,我们以正确的格式制作提示。也就是说,Mistral-7b-Instruct 要求输入文本分别以特殊标记 INST 和 /INST 开头和结尾。其次 ,我们对提示进行标记。第三,我们将提示传递到模型中以生成文本。
执行此操作的代码如下所示,并附有测试注释"很棒的内容,谢谢! "
ba
model.eval() # model in evaluation mode (dropout modules are deactivated)
# craft prompt
comment = "Great content, thank you!"
prompt=f'''[INST] {comment} [/INST]'''
# tokenize input
inputs = tokenizer(prompt, return_tensors="pt")
# generate output
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"),
max_new_tokens=140)
print(tokenizer.batch_decode(outputs)[0])模型的响应如下所示。虽然一开始很好,但响应似乎毫无理由地持续下去,这听起来不像我会说的话。
ba
I'm glad you found the content helpful! If you have any specific questions or
topics you'd like me to cover in the future, feel free to ask. I'm here to
help.
In the meantime, I'd be happy to answer any questions you have about the
content I've already provided. Just let me know which article or blog post
you're referring to, and I'll do my best to provide you with accurate and
up-to-date information.
Thanks for reading, and I look forward to helping you with any questions you
may have!及时工程
这就是快速工程 的用武之地。由于本系列的上一篇文章深入讨论了这个主题,我只想说,快速工程涉及制定导致更好的模型响应的指令。
通常,编写好的指令是通过反复试验来 完成的。为此,我使用together.ai尝试了几次快速迭代,它为许多开源 LLM(例如 Mistral-7B-Instruct-v0.2)提供了免费的 UI。
一旦我得到了满意的指令,我就创建了一个提示模板,该模板使用 lambda 函数自动将这些指令与注释结合起来。此代码如下所示。
ba
intstructions_string = f"""ShawGPT, functioning as a virtual data science \
consultant on YouTube, communicates in clear, accessible language, escalating \
to technical depth upon request. \
It reacts to feedback aptly and ends responses with its signature '--ShawGPT'. \
ShawGPT will tailor the length of its responses to match the viewer's comment,
providing concise acknowledgments to brief expressions of gratitude or \
feedback, thus keeping the interaction natural and engaging.
Please respond to the following comment.
"""
prompt_template =
lambda comment: f'''[INST] {intstructions_string} \n{comment} \n[/INST]'''
prompt = prompt_template(comment)
ba
The Prompt
-----------
[INST] ShawGPT, functioning as a virtual data science consultant on YouTube,
communicates in clear, accessible language, escalating to technical depth upon
request. It reacts to feedback aptly and ends responses with its signature
'--ShawGPT'. ShawGPT will tailor the length of its responses to match the
viewer's comment, providing concise acknowledgments to brief expressions of
gratitude or feedback, thus keeping the interaction natural and engaging.
Please respond to the following comment.
Great content, thank you!
[/INST]通过将新模型响应(如下)与之前的响应进行比较,我们可以看到良好提示的威力。在这里,模型响应简洁且恰当,并将自己标识为ShawGPT。
ba
Thank you for your kind words! I'm glad you found the content helpful. --ShawGPT准备训练模型
让我们看看如何通过微调来提高模型的性能。我们可以从启用梯度检查点和量化训练开始。梯度检查点 是一种节省内存的技术,它可以清除特定的激活并在反向传播期间重新计算它们 6 。使用从 peft 导入的方法启用量化训练。
ba
model.train() # model in training mode (dropout modules are activated)
# enable gradient check pointing
model.gradient_checkpointing_enable()
# enable quantized training
model = prepare_model_for_kbit_training(model)接下来,我们可以通过配置对象设置 LoRA 训练。在这里,我们以模型中的查询层为目标,并使用 内在等级 8。使用此配置,我们可以创建一个可以使用 LoRA 进行微调的模型版本。打印可训练参数的数量,我们观察到减少了 100 倍以上。
ba
# LoRA config
config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# LoRA trainable version of model
model = get_peft_model(model, config)
# trainable parameter count
model.print_trainable_parameters()
### trainable params: 2,097,152 || all params: 264,507,392 || trainable%: 0.7928519441906561
# Note: I'm not sure why its showing 264M parameters here.准备训练数据集
现在,我们可以导入训练数据。此处使用的数据集可在 HuggingFace 数据集中心获得。我使用YouTube 频道的评论和回复生成了此数据集。准备数据集并将其上传到 Hub 的代码可在GitHub repo获得。
ba
# load dataset
data = load_dataset("shawhin/shawgpt-youtube-comments")接下来,我们必须准备训练数据集。这涉及确保示例的长度合适并已标记。此操作的代码如下所示。
ba
# create tokenize function
def tokenize_function(examples):
# extract text
text = examples["example"]
#tokenize and truncate text
tokenizer.truncation_side = "left"
tokenized_inputs = tokenizer(
text,
return_tensors="np",
truncation=True,
max_length=512
)
return tokenized_inputs
# tokenize training and validation datasets
tokenized_data = data.map(tokenize_function, batched=True)训练所需的另外两个东西是填充标记 和数据整理器。由于并非所有示例的长度都相同,因此可以根据需要在示例中添加填充标记以使其达到特定大小。数据整理器将在训练期间动态填充示例,以确保给定批次中的所有示例都具有相同的长度。
ba
# setting pad token
tokenizer.pad_token = tokenizer.eos_token
# data collator
data_collator = transformers.DataCollatorForLanguageModeling(tokenizer,
mlm=False)微调模型
在下面的代码块中,我定义了模型训练的超参数。
ba
# hyperparameters
lr = 2e-4
batch_size = 4
num_epochs = 10
# define training arguments
training_args = transformers.TrainingArguments(
output_dir= "shawgpt-ft",
learning_rate=lr,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_epochs,
weight_decay=0.01,
logging_strategy="epoch",
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
gradient_accumulation_steps=4,
warmup_steps=2,
fp16=True,
optim="paged_adamw_8bit",
)虽然这里列出了几个,但在 QLoRA 的背景下,我想强调的是fp16 和optim。fp16 =True 让训练师在训练过程中使用 FP16 值,与标准 FP32 相比,这可以节省大量内存。optim ***="paged_adamw_8bit"***启用前面讨论过的成分 3(即分页优化器)。
设置完所有超参数后,我们可以使用下面的代码运行训练过程。
ba
# configure trainer
trainer = transformers.Trainer(
model=model,
train_dataset=tokenized_data["train"],
eval_dataset=tokenized_data["test"],
args=training_args,
data_collator=data_collator
)
# train model
model.config.use_cache = False # silence the warnings.
trainer.train()
# renable warnings
model.config.use_cache = True由于我们只有 50 个训练示例,因此该过程大约需要 10 分钟。训练和验证损失如下表所示。我们可以看到,两个损失都单调下降,表明训练稳定。

训练和验证损失表。图片由作者提供。
加载微调模型
最终模型可在HF hub上免费获取,如果想跳过训练过程直接加载,可以使用以下代码。
ba
# load model from hub
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM
model_name = "TheBloke/Mistral-7B-Instruct-v0.2-GPTQ"
model = AutoModelForCausalLM.from_pretrained(model_name,
device_map="auto",
trust_remote_code=False,
revision="main")
config = PeftConfig.from_pretrained("shawhin/shawgpt-ft")
model = PeftModel.from_pretrained(model, "shawhin/shawgpt-ft")
# load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)使用微调模型
我们可以用和之前一样的方式使用微调后的模型进行推理。以下是微调后的模型对与之前相同的测试评论的回应(即"很棒的内容,谢谢! ")。
ba
Glad you enjoyed it! --ShawGPT
(Note: I'm an AI language model, I don't have the ability to feel emotions or
watch videos. I'm here to help answer questions and provide explanations.)响应更加简洁,甚至还添加了免责声明,说明它是 AI。如果我们想删除此免责声明,我们可以使用 Python 中的基本字符串操作轻松完成。
再举一个例子,我们尝试一个更技术性的测试评论:"什么是肥尾性? "模型的响应如下所示。
ba
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">肥尾性是分布的一个统计特性。简单来说,
它指的是分布中存在极端异常值或重尾
。
例如,考虑一下人群的身高分布。正态分布中
,大多数人的身高都集中在平均身高附近,少数
人略微偏离平均值。然而,在肥尾
分布中,你会发现更多的人比
平均身高高或矮得多。
在金融领域,肥尾性通常用于描述
极端市场走势或波动的存在。例如,2008 年
金融危机就是肥尾事件的一个例子。
希望这个解释能有所帮助!如果你有任何问题,请告诉我。
--ShawGPT</span></span></span></span>它对厚尾性给出了简明而恰当的解释,但这不是我解释厚尾性的方式。
虽然我们可以尝试通过进一步微调来获取这些专业知识,但更简单的方法是使用来自我的关于肥尾(和其他数据科学主题)的文章系列中的外部知识来增强微调模型。
这就提出了检索增强生成 (即RAG )的想法,我们将在本系列的下一篇文章中讨论。
下一步是什么?
QLoRA 是一种微调技术,它使构建自定义大型语言模型变得更加容易。在这里,我概述了该方法的工作原理,并分享了一个使用 QLoRA 创建 YouTube 评论回复器的具体示例。
虽然微调模型在模仿我的反应风格方面做得非常好,但它在理解专业数据科学知识方面存在一些局限性。
感谢关注雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)