KMP算法
主要用来进行字符串匹配
KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
所以如何记录已经匹配的文本内容,是KMP的重点,也是next数组肩负的重任。
next数组就是一个前缀表(prefix table)。
前缀表有什么作用呢?
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
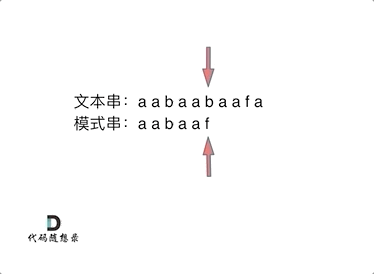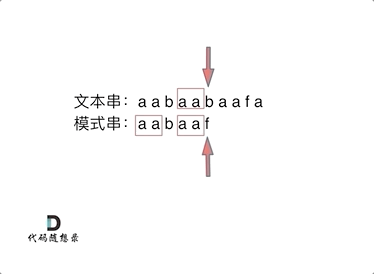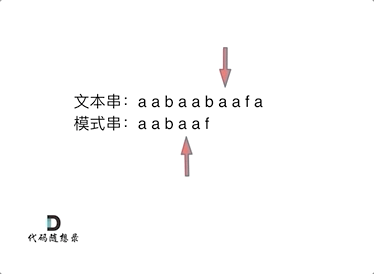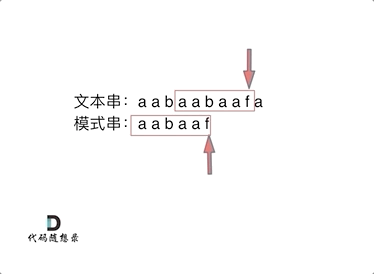
此时就要问了前缀表是如何记录的呢?
首先要知道前缀表的任务是当前位置匹配失败,找到之前已经匹配上的位置,再重新匹配,此也意味着在某个字符失配时,前缀表会告诉你下一步匹配中,模式串应该跳到哪个位置。
那么什么是前缀表:记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面重新匹配就可以了。
所以前缀表具有告诉我们当前位置匹配失败,跳到之前已经匹配过的地方的能力。
很多KMP算法的实现都是使用next数组来做回退操作,那么next数组与前缀表有什么关系呢?
next数组就可以是前缀表,但是很多实现都是把前缀表统一减一(右移一位,初始位置为-1)之后作为next数组。
其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
暴力的解法显而易见是O(n × m),所以KMP在字符串匹配中极大地提高了搜索的效率。
28.实现strStr()
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例 1:
输入:haystack = "sadbutsad", needle = "sad"
输出:0
解释:"sad" 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。示例 2:
输入:haystack = "leetcode", needle = "leeto"
输出:-1
解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。提示:
1 <= haystack.length, needle.length <= 104
haystack 和 needle 仅由小写英文字符组成
正解(KMP)
显然,是一道KMP模板题
上代码(●'◡'●)
cpp
class Solution {
public:
void getNext(int* next, const string& s) {
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}
int strStr(string haystack, string needle) {
if (needle.size() == 0) {
return 0;
}
vector<int> next(needle.size());
getNext(&next[0], needle);
int j = -1; // // 因为next数组里记录的起始位置为-1
for (int i = 0; i < haystack.size(); i++) { // 注意i就从0开始
while(j >= 0 && haystack[i] != needle[j + 1]) { // 不匹配
j = next[j]; // j 寻找之前匹配的位置
}
if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动
j++; // i的增加在for循环里
}
if (j == (needle.size() - 1) ) { // 文本串s里出现了模式串t
return (i - needle.size() + 1);
}
}
return -1;
}
};459.重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
示例 1:
输入: s = "abab"
输出: true
解释: 可由子串 "ab" 重复两次构成。示例 2:
输入: s = "aba"
输出: false示例 3:
输入: s = "abcabcabcabc"
输出: true
解释: 可由子串 "abc" 重复四次构成。 (或子串 "abcabc" 重复两次构成。)提示:
1 <= s.length <= 104
s 由小写英文字母组成
正解(依旧是KMP)
当一个字符串s:abcabc,内部由重复的子串组成
也就是由前后相同的子串组成。
那么既然前面有相同的子串,后面有相同的子串,用 s + s,这样组成的字符串中,后面的子串做前串,前面的子串做后串,就一定还能组成一个s;
所以判断字符串s是否由重复子串组成,只要两个s拼接在一起,里面还出现一个s的话,就说明是由重复子串组成。
当然,我们在判断 s + s 拼接的字符串里是否出现一个s的的时候,要刨除 s + s 的首字符和尾字符;
这样避免在s+s中搜索出原来的s,我们要搜索的是中间拼接出来的s。
上代码(●'◡'●)
cpp
class Solution {
public:
void getNext (int* next, const string& s){
next[0] = -1;
int j = -1;
for(int i = 1;i < s.size(); i++){
while(j >= 0 && s[i] != s[j + 1]) {
j = next[j];
}
if(s[i] == s[j + 1]) {
j++;
}
next[i] = j;
}
}
bool repeatedSubstringPattern (string s) {
if (s.size() == 0) {
return false;
}
int next[s.size()];
getNext(next, s);
int len = s.size();
if (next[len - 1] != -1 && len % (len - (next[len - 1] + 1)) == 0) {
return true;
}
return false;
}
};写博不易,请大佬点赞支持一下8~