论文揭示了
star operation(元素乘法)在无需加宽网络下,将输入映射到高维非线性特征空间的能力。基于此提出了StarNet,在紧凑的网络结构和较低的能耗下展示了令人印象深刻的性能和低延迟来源:晓飞的算法工程笔记 公众号
论文: Rewrite the Stars

- 论文地址: https://arxiv.org/abs/2403.19967
- 论文代码: https://github.com/ma-xu/Rewrite-the-Stars
- 作者的介绍: 神经网络中,element-wise mutiplication为什么效果好?CVPR'24
Introduction
最近,通过元素乘法融合不同的子空间特征的学习范式越来越受到关注,论文将这种范例称为star operation(由于元素乘法符号类似于星形)。
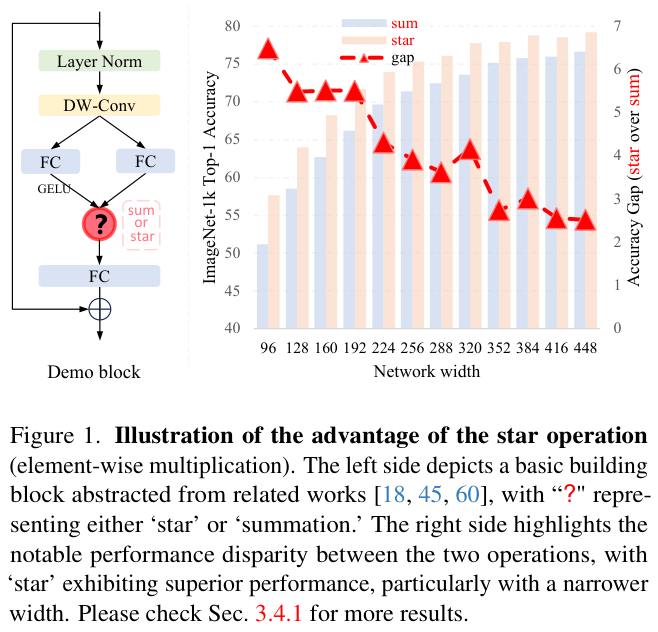
为了便于说明,论文构建了一个用于图像分类的demo block,如图 1 左侧所示。通过在stem层后堆叠多个demo block,论文构建了一个名为DemoNet的简单模型。保持所有其他因素不变,论文观察到逐元素乘法(star operation)在性能上始终优于求和,如图 1 右侧所示。
在这项工作中,论文证明star operation具有将输入映射到极高维的非线性特征空间的能力,从而解释star operation的强表达能力。论文不依赖直观或假设的高级解释,而是深入研究star operation的细节。通过重写和重新表述star operation计算过程,论文发现这个看似简单的运算实际可以生成一个新的特征空间,含大约 \((\frac{d}{\sqrt{2}})^2\) 线性独立维度。
与增加网络宽度(又称通道数)的传统神经网络不同,star operation类似于在不同通道上进行成对特征乘法的核函数,特别是多项式核函数。当应用到神经网络中并通过多层堆叠时,每一层都会带来隐式维度复杂性的指数增长。只需几层,star operation就可以在紧凑的特征空间内实现几乎无限的维度。在紧凑的特征空间内计算,同时受益于隐含的高维度,这就是star operation的独特魅力所在。
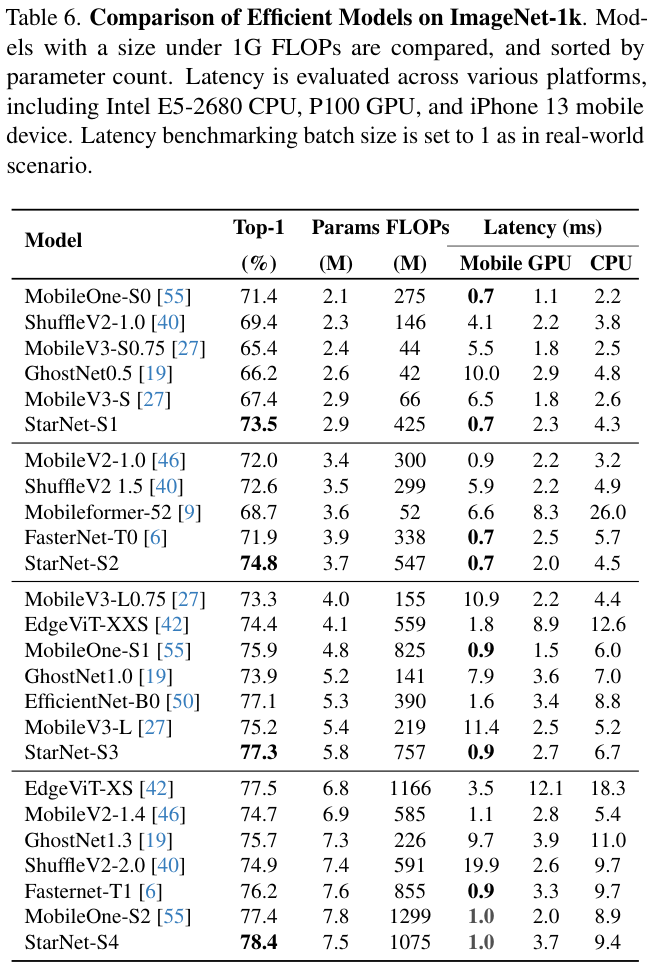
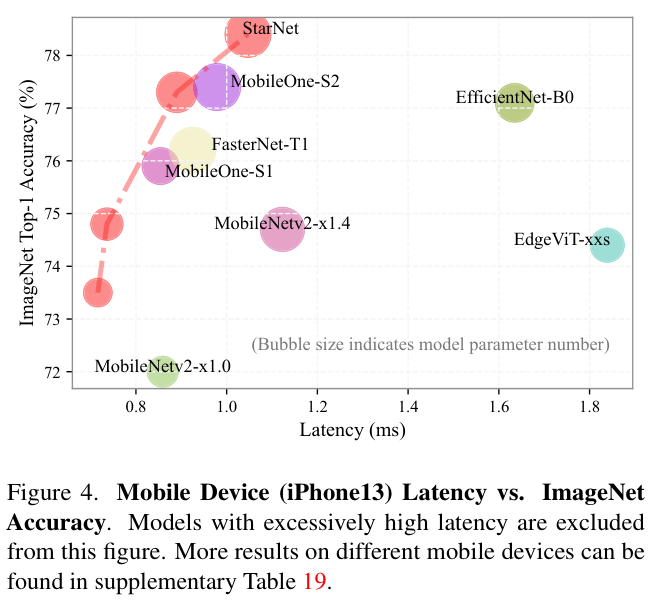
根据上述见解,论文推断star operation本质上更适合高效、紧凑的网络,而不是常规使用的大型模型。为了验证这一点,论文提出了一种概念验证的高效网络StarNet,其特点是简洁和高效。StarNet非常简单,缺乏复杂的设计和微调的超参数。在设计理念上,StarNet与现有网络明显不同,如表 1 所示。利用star operation,StarNet甚至可以超越各种精心设计的高效模型,如MobileNetv3、EdgeViT、FasterNet等。这些结果不仅从经验上验证了论文对恒星运行的见解,而且强调了其在实际应用中的实用价值。
论文简要总结并强调这项工作的主要贡献如下:
- 证明了
star operation的有效性,如图 1 所示,揭示了star operation具有将特征投影到极高维隐式特征空间的能力,类似于多项式核函数。 - 从分析中汲取灵感,确定了
star operation在高效网络领域的实用性,并提出了概念验证模型StarNet。无需复杂的设计或精心选择的超参数即可实现高性能,超越了许多高效的设计。 - 基于
star operation存在大量未探索的可能性,论文的分析可以作为指导框架,引导研究人员远离随意的网络设计尝试。
Rewrite the Stars
Star Operation in One layer
在单层神经网络中,star operation通常写为 \((\mathrm{W}{1}^{\mathrm{T}}\mathrm{X}+\mathrm{B}{1})\ast(\mathrm{W}{2}^{\mathrm{T}}\mathrm{X}+\mathrm{B}{2})\),通过逐元素乘法融合两个线性变换的特征。为了方便起见,将权重矩阵和偏置合并为一个实体 \(\mathrm{W} = \Bigg\begin{array}{c}{\mathrm{W}}\{\mathrm{B}}\end{array}\Bigg\),同样地,通过 \(\mathrm{X} = \Bigg\begin{array}{c}{\mathrm{X}}\{\mathrm{1}}\end{array}\Bigg\),得到star operation \((\mathrm{W}{1}^{\mathrm{T}}\mathrm{X})\ast(\mathrm{W}{2}^{\mathrm{T}}\mathrm{X})\)。
为了简化分析,论文重点关注涉及单输出通道转换和单元素输入的场景。具体来说,定义 \(w\_1, w\_2, x \in \mathbb{R}^{(d+1)\times 1}\),其中 \(d\) 为输入通道数。这可以随时进行 \(\mathrm{W}\_1, \mathrm{W}\_2 \in \mathbb{R}^{(d+1)\times(d^{\prime}+1)}\) 扩展以适应多个输出通道,以及处理多元素输入 \(\mathrm{X} \in \mathbb{R}^{(d+1)\times n}\)。
一般来说,可以通过以下方式重写star operation:
\ \\begin{array}{l} {{w_{1}\^{\\mathrm{T}}x\\ast w_{2}\^{\\mathrm{T}}x}} \& (1) \\ {{=\\left(\\sum_{i=1}\^{d+1}w_{1}\^{i}x\^{i}\\right)\\\*\\left(\\sum_{j=1}\^{d+1}w_{1}\^{i}w\\_{2}\^{j}x\^{j}\\right)}} \& (2) \\ {{=\\sum_{i=1}\^{d+1}\\sum_{j=1}\^{d+1}w_{1}\^{i}w_{2}\^{j}x\^{i}x\^{j}}} \& (3) \\ =\\underbrace{{\\alpha_{(1,1)}x\^{1}x\^{1}+\\cdots+\\alpha_{(4,5)}x\^{4}x\^{5}+\\cdots+\\alpha_{(d+1,d+1)}x\^{d+1}x\^{d+1}}}_{(d+2)(d+1)/2\\ \\mathrm{items}} \& (4) \\end{array} \\
其中 \(i,j\) 作为通道下标,\(\alpha\) 为个子项的系数:
\ {\\alpha}_{(i,j)}=\\left{\\begin{array}{c c}{{{w}_{1}\^{i}{w}_{2}\^{j}}}\&{{\\mathrm{if}\\;i==j,}}\\ {{{w}_{1}\^{i}{w}_{2}\^{j}+{w}_{1}\^{j}{w}\\_{2}\^{i}}}\&{{\\mathrm{if}\\;i!=j.}}\\end{array}\\right. \\quad\\quad(5) \\
重写star operation后,可以将其展开为 \(\frac{(d+2)(d+1)}{2}\) 个不同子项的组合,如等式 4 所示。值得注意的是,除了 \(\alpha\_{(d+1,:)}x^{d+1}x\) 的每个子项(这里是 \(x^{d+1}\) 偏置项)都与 \(x\) 呈非线性关联,表明它们是单独的隐式维度。
因此,在 \(d\) 维度空间中使用计算效率高的star operation,可以得到\({\frac{(d+2)(d+1)}{2}}\approx(\frac{d}{\sqrt{2}})^2\)(\(d\gg 2\))的隐式维度特征空间。从而在显著放大特征维度的同时,不会在单层内产生任何额外的计算开销,这个突出的属性与内核函数有着相似的理念。
Generalized to multiple layers
通过堆叠多个层,可以递归地将隐式维度以指数方式增加到几乎无限。
对于宽度为 \(d\) 的初始网络层,应用一次star operation(\(\sum_{i=1}^{d+1}\sum_{j=1}^{d+1}w_{1}^{i}w_{2}^{j}x^{i}x^{j}\)),可得到 \(\mathbb{R}^{(\frac{d}{\sqrt{2}})^{2^{1}}}\) 的隐式特征空间内。
让 \({O}\_{l}\) 表示第 \(l\) 个star operation的输出,可得:
\ \\begin{array}{l l} {{O_{1}=\\sum_{i=1}\^{d+1}\\sum_{j=1}\^{d+1}w_{(1,1)}\^{i}w\\_{(1,2)}\^{j}x\^{i}x\^{j}\\qquad\\in\\mathbb{R}\^{({\\frac{d}{\\sqrt{2}}})\^{2\^{1}}}}} \&(6) \\ {{O_{2}=\\mathrm{W}_{2,1}\^{\\mathrm{T}}\\mathrm{O}_{1}\\ast\\mathrm{W}_{2,2}\^{\\mathrm{T}}O\\_{1}}}\\qquad\\qquad\\qquad\\,\\,{{\\in\\,\\mathbb{R}\^{({\\frac{d}{\\sqrt{2}}})\^{2\^{2}}}}} \&(7) \\ {{O_{2}=\\mathrm{W}_{3,1}\^{\\mathrm{T}}\\mathrm{O}_{2}\\ast\\mathrm{W}_{3,2}\^{\\mathrm{T}}O\\_{2}}}\\qquad\\qquad\\qquad\\,\\,{{\\in\\,\\mathbb{R}\^{({\\frac{d}{\\sqrt{2}}})\^{2\^{3}}}}} \&(8) \\ \\cdots \&(9) \\ {{O_{2}=\\mathrm{W}_{l,1}\^{\\mathrm{T}}\\mathrm{O}_{l-1}\\ast\\mathrm{W}_{l,2}\^{\\mathrm{T}}O\\_{l-1}}}\\qquad\\qquad\\quad\\,\\,{{\\in\\,\\mathbb{R}\^{({\\frac{d}{\\sqrt{2}}})\^{2\^{l}}}}} \&(10) \\end{array} \\
也就是说,通过堆叠 \(l\) 层可以隐式获得 \(\mathbb{R}^{({\frac{d}{\sqrt{2}}})^{2^{l}}}\) 维特征空间。例如,给定一个宽度为 128 的 10 层网络,通过star operation获得的隐式特征维数近似为 \(90^{1024}\) ,相当于无限维度。因此,通过堆叠多个层,即使只有几个层,star operation也可以以指数方式大幅放大隐式维度。
Special Cases
实际上,并非所有star operation都遵循公式 1 那样,两个分支都进行变换。例如,VAN和SENet包含一个identity分支,而GENet-\(\theta^{-}\)无需任何需学习的变换(池化、最近邻插值后乘回原特征)即可运行。
- Case I: Non-Linear Nature of \(\mathrm{W}{1}\) and/or \(\mathrm{W}{2}\)
在实际场景中,大量研究(例如Conv2Former、FocalNet等)通过合并激活函数将变换函数 \({\mathrm{W}}{1}\) 和/或 \({\mathrm{W}}{2}\) 变为非线性。尽管如此,最重要的其实是看通道间的处理是否像公式 2 那样实现,是则其隐式维度仍然保持不变(大约为 \(\frac{d}{\sqrt{2}})^2\) )。
- Case II: \(\mathrm{W}\_{1}^{\mathrm{T}}\mathrm{X}\ast \mathrm{X}\)
当移除 \(\mathrm{W}\_{2}\) 变换时,隐式维度从大约 \(\frac{d^{2}}{2}\) 减少到 \(2d\)。
- Case III: \(\mathrm{X}\ast \mathrm{X}\)
在这种情况下,star operation将特征从特征空间 \({{x}^{1},{x}^{2},\cdots,\;{x}^{d}} \in\mathbb{R}^{d}\) 转换为 \({{x}^{1}{x}^{1},{x}^{2}{x}^{2},\cdots,\;{x}^{d}{x}^{d}} \in\mathbb{R}^{d}\) 的新特征空间。
有几个值得注意的方面需要考虑:
star operation及其特殊情况通常会(尽管不一定)与空间交互集成,比如通过池化或卷积实现线性变换。但许多这些方法只强调扩大感受野带来的好处,往往忽视隐式高维空间赋予的优势。- 组合这些特殊情况是可行的,如
Conv2Former合并了Case I和Case II,以及GENet-\(\theta^{-}\)混合了Case I和Case III。 - 虽然
Case II和Case III可能不会显著增加单层的隐式维度,但使用线性层(主要用于通道通信)和skip连接依然可以通过堆叠多个层来实现高隐式维度。
Proof-of-Concept: StarNet
鉴于star operation的独特优势---在低维空间中计算的同时产生高维特征,论文确定了其在高效网络架构领域的实用性。因此,论文提出StarNet作为概念验证模型,特点是极其简约的设计和显著减少的人为干预。尽管StarNet很简单,但它展示了卓越的性能,强调了star operation的功效。
StarNet Architecture
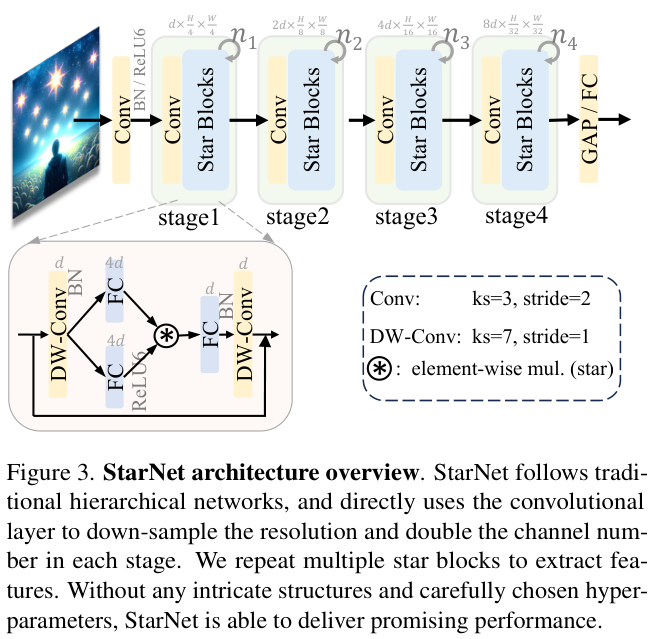
StarNet采用 4 级分层架构,利用卷积层进行下采样,并使用修改后的demo block进行特征提取。为了满足效率的要求,将Layer Normalization替换为Batch Normalization,并将其放置在深度卷积之后(可以在推理时融合)。受到MobileNeXt的启发,论文在每个块的末尾加入了一个深度卷积。通道扩展因子始终设置为 4,网络宽度在每个阶段加倍。遵循MobileNetv2设计,demo block中的GELU激活被替换为ReLU6。
Experimental
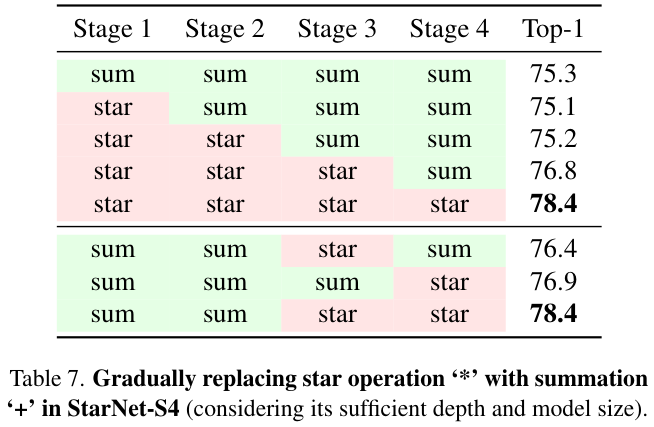
Star Operation
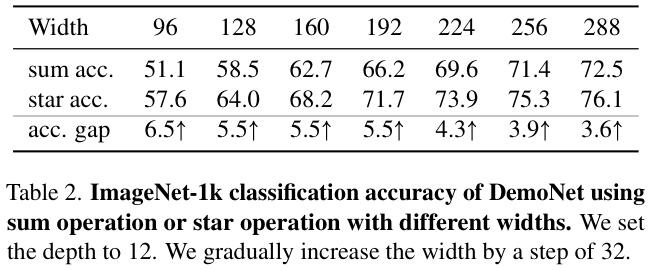

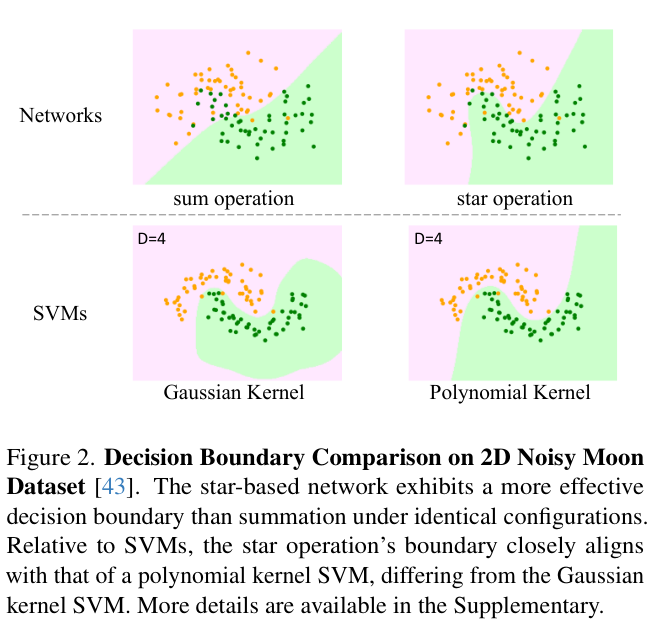
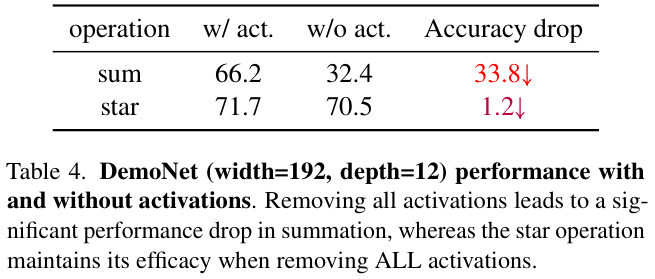
StarNet


如果本文对你有帮助,麻烦点个赞或在看呗~undefined更多内容请关注 微信公众号【晓飞的算法工程笔记】
