我正在接受挑战,在只有 8GB VRAM 的 GPU 上运行 Llama 3.1 405B 模型。
Llama 405B 模型有 820GB!这是 8GB VRAM 容量的 103 倍!
显然,8GB VRAM 无法容纳它。那么我们如何让它工作呢?

NSDT工具推荐 : Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、4 位量化
首先,我们使用 4 位量化技术将 16 位浮点数转换为 4 位,从而节省四倍的内存。
量化后,所有浮点数将分配到 4 位的 16 个存储桶中的一个。深度神经网络中浮点数的范围从 -3.40282347E+38 到 3.40282347E+38。仅使用 16 个存储桶可以表示如此广泛的浮点数范围吗?
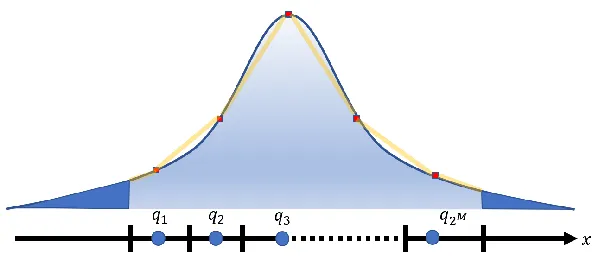
是的,可以。
最重要的是要确保这些参数均匀分布在 16 个 bucket 中。
通常,这几乎是不可能实现的。分布不均匀会导致严重的精度损失。
幸运的是,深度神经网络的参数一般都服从正态分布。因此,简单的变换就可以确保理论上的均匀分布。
当然,服从统计分布并不意味着没有异常值。
我们只需要使用一些专用的存储空间来专门记录这些异常值。这被称为异常值相关量化。
大量实验表明,4 位量化几乎不会影响大型语言模型的准确性。(在某些情况下,准确率甚至更高!)
经过一轮广泛的 4 位量化后,Llama 405B 模型的大小已减小到 230GB,让我们"更接近"将其加载到我的 8GB GPU 上。
2、逐层推理
实现这一挑战的第二个秘诀是逐层推理。
实际上,Transformer 的推理过程只需要逐层加载模型。无需一次性将整个模型加载到内存中。

Llama 405B型号共有126层,层数增加了50%。

但是向量维度增加了一倍,多头注意力头的数量也增加了一倍,所以每层的参数数量大概是原来的四倍。
通过逐层加载和推断,最大 VRAM 使用量约为 5GB。
挑战完成!
现在我可以在我的 8GB GPU 上成功运行 Llama 405B 了!
3、开源项目 AirLLM
AI 行业中各种大型模型之间的差距正在迅速缩小。模型之间的差异越来越不明显。
越来越多的公司愿意采用开源模型并自行部署大型模型,确保他们可以根据业务需求灵活地控制和调整他们的模型。
我也是开源的坚定信徒,相信 AI 的未来属于开源。
本文介绍的方法已在我的开源项目AirLLM中分享:
pip install airllm你只需要几行代码:
from airllm import AutoModel
model = AutoModel.from_pretrained(
"unsloth/Meta-Llama-3.1-405B-Instruct-bnb-4bit")
input_text = ['What is the capital of United States?',]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=128,
padding=False)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=10,
return_dict_in_generate=True)
output = model.tokenizer.decode(generation_output.sequences[0])
print(output)