llama.cpp server在 2025年12月11日发布的版本中正式引入了 router mode(路由模式),如果你习惯了 Ollama 那种处理多模型的方式,那这次 llama.cpp 的更新基本就是对标这个功能去的,而且它在架构上更进了一步。
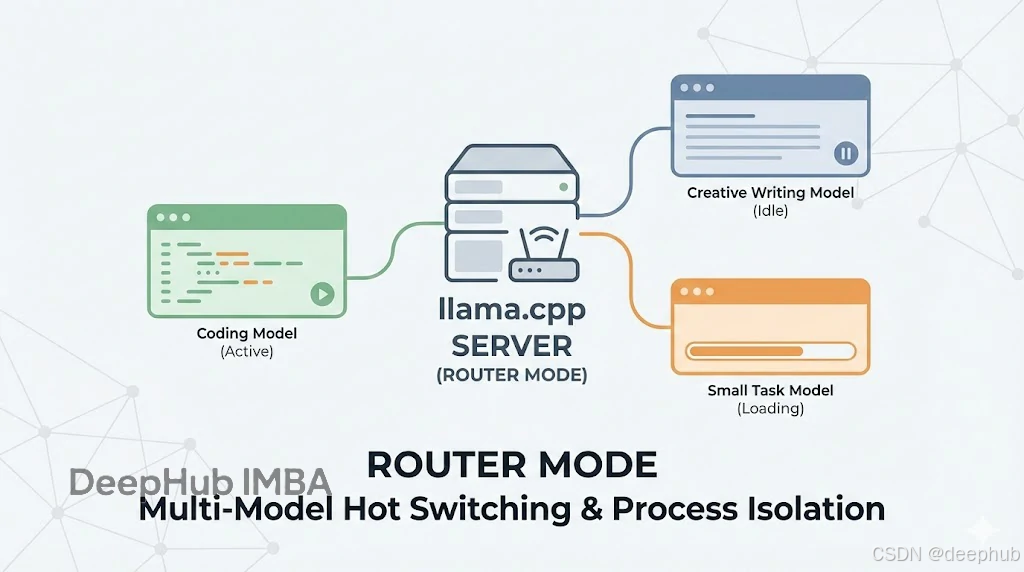
路由模式的核心机制
简单来说,router mode 就是一个内嵌在 llama.cpp 里的模型管理器。
以前跑 server,启动时需要指定一个模型,服务就跟这个模型绑定了。要想换模型?要么停服务、改参数、重启,要么直接启动多个服务,而现在的路由模式可以动态加载多个模型、模型用完后还可以即时卸载,并且在不同模型间毫秒级切换,最主要的是全过程无需重启服务,这样我们选择一个端口就可以了。
这里有个技术细节要注意:它的实现是多进程的(Each model runs in its own process)。也就是说模型之间实现了进程级隔离,某个模型如果跑崩了,不会把整个服务带崩,其他模型还能正常响应。这种架构设计对稳定性的考虑还是相当周到的。
启动配置与自动发现
启用方式很简单,启动 server 时不要指定具体模型即可:
bash
llama-server服务启动后会自动扫描默认缓存路径(LLAMA_CACHE 或 ~/.cache/llama.cpp)。如果你之前用 llama-server -hf user/model 这种方式拉取过模型,它们会被自动识别并列入可用清单。
但是我们一般会把模型存放在特定目录,指定一下就行:
bash
llama-server --models-dir /llm/gguf这个模式不仅是"能加载"那么简单,它包含了一套完整的资源管理逻辑:
- Auto-discovery(自动发现):启动即扫描指定目录或缓存,所有合规的 GGUF 文件都会被注册。
- On-demand loading(按需加载):服务启动时不占满显存,只有当 API 请求真正过来时,才加载对应模型。
- LRU eviction(LRU 淘汰):可以设置最大驻留模型数(默认是 4)。当加载新模型导致超出限制时,系统会自动释放那个最近最少使用的模型以腾出 VRAM。
- Request routing(请求路由) :完全兼容 OpenAI API 格式,根据请求体中的
model字段自动分发流量。
调用实测
通过 API 调用特定模型,如果该模型未加载,首个请求会触发加载过程(会有冷启动延迟),后续请求则是热调用。
bash
curl http://395-1.local:8072/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss-120b-GGUF/gpt-oss-120b-mxfp4-00001-of-00003.gguf",
"messages": [{"role": "user", "content": "打印你的模型信息"}]
}'查看模型状态
这对于监控服务状态很有用,能看到哪些模型是 loading,哪些是 idle。
bash
curl http://395-1.local:8072/models手动资源管理
除了自动托管,也开放了手动控制接口:
加载模型:
bash
curl -X POST http://395-1.local:8072/models/load \
-H "Content-Type: application/json" \
-d '{"model": "Qwen3-Next-80B-A3B-Instruct-1M-MXFP4_MOE-GGUF/Qwen3-Next-80B-A3B-Instruct-1M-MXFP4_MOE-00001-of-00003.gguf"}'卸载模型:
bash
curl -X POST http://395-1.local:8072/models/unload \
-H "Content-Type: application/json" \
-d '{"model": "Qwen3-Next-80B-A3B-Instruct-1M-MXFP4_MOE-GGUF/Qwen3-Next-80B-A3B-Instruct-1M-MXFP4_MOE-00001-of-00003.gguf"}'常用参数与全局配置
这几个参数在路由模式下使用频率很高:
--models-dir PATH: 指定你的 GGUF 模型仓库路径。--models-max N: 限制同时驻留显存的模型数量。--no-models-autoload: 如果不想让它自动扫描目录,可以用这个关掉。
比如下面这个启动命令,设定了全局的上下文大小,所有加载的模型都会继承这个配置:
bash
llama-server --models-dir ./models -c 8192进阶:基于预设的配置
全局配置虽然方便,但是不同的模型有不同的配置方案,比如你想让 Coding 模型用长上下文,而让写作模型一部分加载到cpu中。
这时候可以用 config.ini 预设文件:
bash
llama-server --models-preset config.ini配置文件示例:
ini
[oss120]
model = gpt-oss-120b-GGUF/gpt-oss-120b-mxfp4-00001-of-00003.gguf
ctx-size = 65536
temp = 0.7这样就能实现针对特定模型的精细化调优
同时官方自带的 Web 界面也同步跟进了。在下拉菜单里直接选模型,后端会自动处理加载逻辑,对于不想写代码测试模型的人来说也很直观。
总结
Router mode 看似只是加了个多模型支持,实则是把 llama.cpp 从一个单纯的"推理工具"升级成了一个更成熟的"推理服务框架"。
不仅是不用重启那么简单,进程隔离和 LRU 机制让它在本地开发环境下的可用性大幅提升。对于那些要在本地通过 API 编排多个模型协作的应用(Agent)开发来说,这基本是目前最轻量高效的方案之一。
https://avoid.overfit.cn/post/f604f19386df4d9ebb37aae55f899ec5