文章目录
1.EasyCode生成interview_history的crud
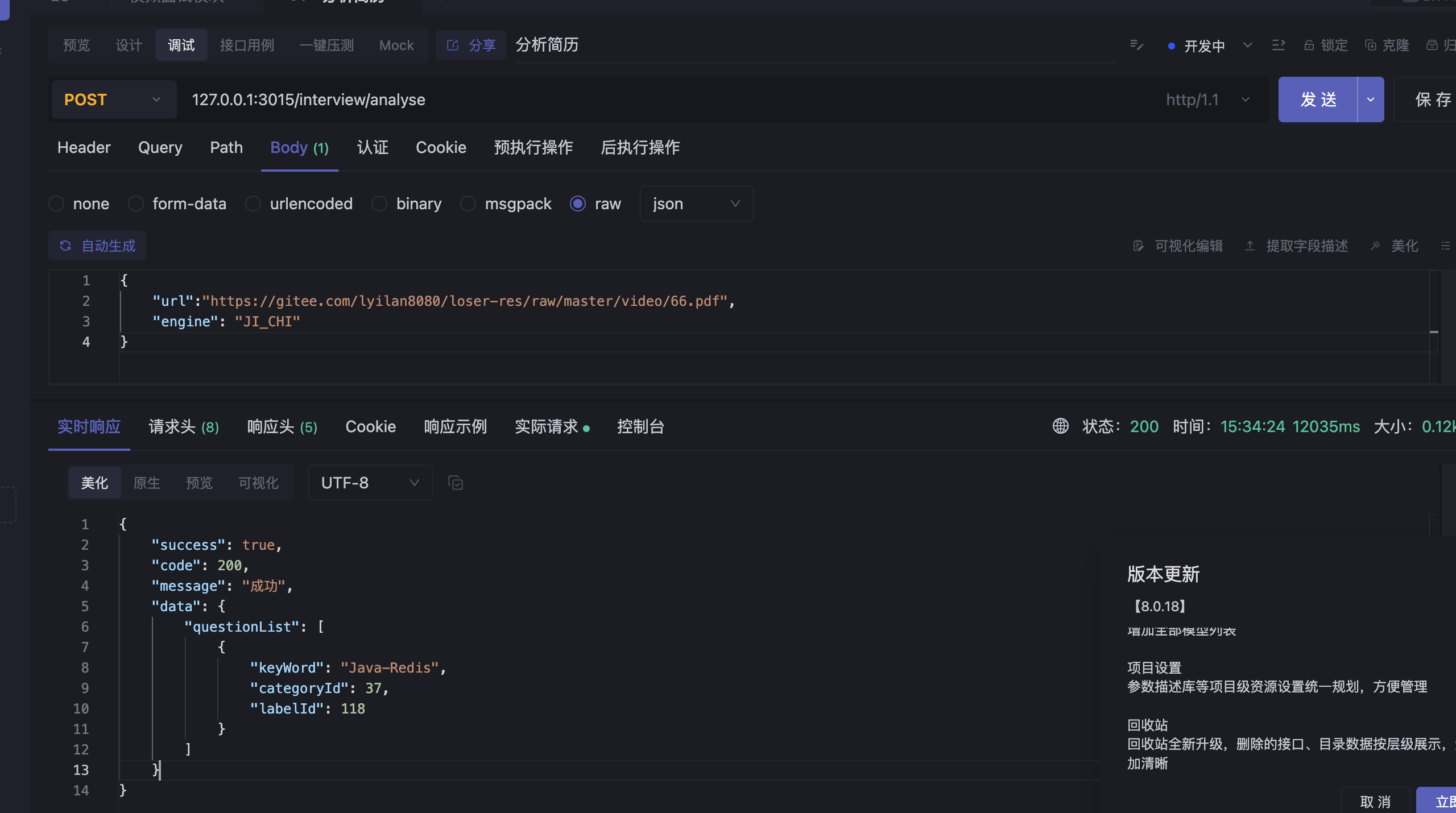
1.在模板设置中手动指定逻辑删除的值
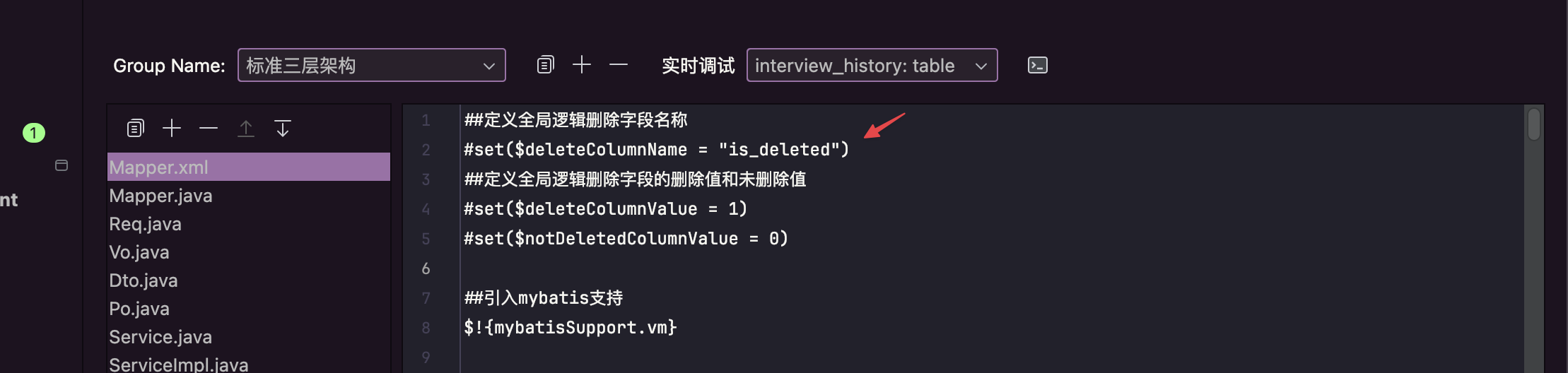
2.生成代码,进行测试
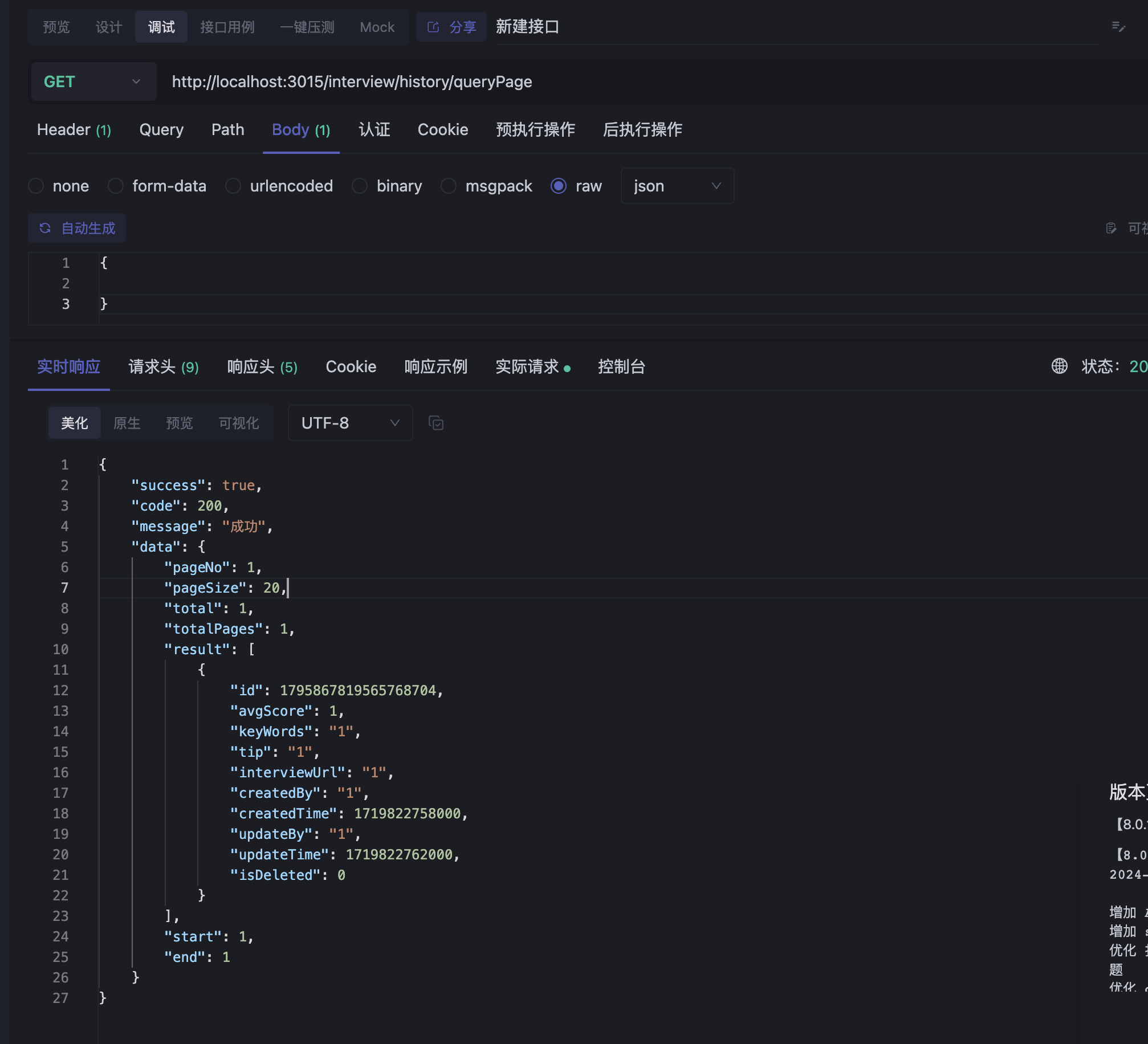
2.PDF识别关键字
1.引入依赖
<!-- pdf解析器 -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.24</version>
</dependency>
2.代码概览
3.PDFUtil.java
package com.sunxiansheng.interview.server.util;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Pattern;
@Slf4j
public class PDFUtil {
private static Pattern pattern = Pattern.compile("\\s*|\t|\r|\n");
/**
* 获取pdf的text
*/
public static String getPdfText(String pdfUrl) {
PDDocument document = null;
String text = "";
try {
URL url = new URL(pdfUrl);
HttpURLConnection htpcon = (HttpURLConnection) url.openConnection();
htpcon.setRequestMethod("GET");
htpcon.setDoOutput(true);
htpcon.setDoInput(true);
htpcon.setUseCaches(false);
htpcon.setConnectTimeout(10000);
htpcon.setReadTimeout(10000);
InputStream in = htpcon.getInputStream();
document = PDDocument.load(in);
PDFTextStripper stripper = new PDFTextStripper();
stripper.setSortByPosition(true);
stripper.setStartPage(0);
stripper.setEndPage(Integer.MAX_VALUE);
text = stripper.getText(document);
text = pattern.matcher(text).replaceAll("");
if (log.isInfoEnabled()) {
log.info("识别到的pdf为{}", text);
}
} catch (Exception e) {
log.error("获取pdf转为文字错误:{}", e.getMessage(), e);
} finally {
if (document != null) {
try {
document.close();
} catch (Exception e) {
log.error("close error", e);
}
}
}
return text;
}
}
4.keyword
1.EndType.java
package com.sunxiansheng.interview.server.util.keyword;
/**
* 结束类型定义
*
* @author minghu.zhang
* @date 11:37 2020/11/11
**/
public enum EndType {
/**
* 有下一个,结束
*/
HAS_NEXT, IS_END
}
2.FlagIndex.java
package com.sunxiansheng.interview.server.util.keyword;
import java.util.List;
/**
* 敏感词标记
*
* @author minghu.zhang
*/
public class FlagIndex {
/**
* 标记结果
*/
private boolean flag;
/**
* 是否黑名单词汇
*/
private boolean isWhiteWord;
/**
* 标记索引
*/
private List<Integer> index;
public boolean isFlag() {
return flag;
}
public void setFlag(boolean flag) {
this.flag = flag;
}
public List<Integer> getIndex() {
return index;
}
public void setIndex(List<Integer> index) {
this.index = index;
}
public boolean isWhiteWord() {
return isWhiteWord;
}
public void setWhiteWord(boolean whiteWord) {
isWhiteWord = whiteWord;
}
}
3.WordType.java
package com.sunxiansheng.interview.server.util.keyword;
/**
* 词汇类型
*
* @author minghu.zhang
* @date 11:37 2020/11/11
**/
public enum WordType {
/**
* 黑名单/白名单
*/
BLACK, WHITE
}
4.KeyWordUtil.java
package com.sunxiansheng.interview.server.util.keyword;
import com.baomidou.mybatisplus.core.toolkit.CollectionUtils;
import java.util.*;
public class KeyWordUtil {
/**
* 敏感词字典
*/
private final static Map wordMap = new HashMap(1024);
private static boolean init = false;
public static boolean isInit() {
return init;
}
/**
* 获取敏感词列表
*
* @param text 输入文本
*/
public static List<String> buildKeyWordsLists(final String text) {
List<String> wordList = new ArrayList<>();
char[] charset = text.toCharArray();
for (int i = 0; i < charset.length; i++) {
FlagIndex fi = getFlagIndex(charset, i, 0);
if (fi.isFlag()) {
if (fi.isWhiteWord()) {
i += fi.getIndex().size() - 1;
} else {
StringBuilder builder = new StringBuilder();
for (int j : fi.getIndex()) {
char word = text.charAt(j);
builder.append(word);
}
wordList.add(builder.toString());
}
}
}
return wordList;
}
/**
* 获取标记索引
*
* @param charset 输入文本
* @param begin 检测起始
* @param skip 文本距离
*/
private static FlagIndex getFlagIndex(final char[] charset, final int begin, final int skip) {
FlagIndex fi = new FlagIndex();
Map current = wordMap;
boolean flag = false;
int count = 0;
List<Integer> index = new ArrayList<>();
for (int i = begin; i < charset.length; i++) {
char word = charset[i];
Map mapTree = (Map) current.get(word);
if (count > skip || (i == begin && Objects.isNull(mapTree))) {
break;
}
if (Objects.nonNull(mapTree)) {
current = mapTree;
count = 0;
index.add(i);
} else {
count++;
if (flag && count > skip) {
break;
}
}
if ("1".equals(current.get("isEnd"))) {
flag = true;
}
if ("1".equals(current.get("isWhiteWord"))) {
fi.setWhiteWord(true);
break;
}
}
fi.setFlag(flag);
fi.setIndex(index);
return fi;
}
public static void addWord(Collection<String> wordList) {
init = true;
if (CollectionUtils.isEmpty(wordList)) {
return;
}
WordType wordType = WordType.BLACK;
Map nowMap;
Map<String, String> newWorMap;
// 迭代keyWordSet
for (String key : wordList) {
nowMap = wordMap;
for (int i = 0; i < key.length(); i++) {
// 转换成char型
char keyChar = key.charAt(i);
// 获取
Object wordMap = nowMap.get(keyChar);
// 如果存在该key,直接赋值
if (wordMap != null) {
nowMap = (Map) wordMap;
} else {
// 不存在则构建一个map,同时将isEnd设置为0,因为他不是最后一个
newWorMap = new HashMap<>(4);
// 不是最后一个
newWorMap.put("isEnd", String.valueOf(EndType.HAS_NEXT.ordinal()));
nowMap.put(keyChar, newWorMap);
nowMap = newWorMap;
}
if (i == key.length() - 1) {
// 最后一个
nowMap.put("isEnd", String.valueOf(EndType.IS_END.ordinal()));
nowMap.put("isWhiteWord", String.valueOf(wordType.ordinal()));
}
}
}
}
}
3.策略模式实现引擎切换&简历分析
1.req和vo
1.InterviewReq.java
package com.sunxiansheng.interview.api.req;
import com.sunxiansheng.interview.api.enums.EngineEnum;
import lombok.Getter;
import lombok.Setter;
import java.io.Serializable;
@Getter
@Setter
public class InterviewReq implements Serializable {
/**
* pdf的url
*/
private String url;
/**
* 分析引擎的名字(AI或者本地)
*/
private String engine = EngineEnum.JI_CHI.name();
}
2.InterviewVO.java
package com.sunxiansheng.interview.api.vo;
import lombok.Data;
import lombok.Getter;
import lombok.Setter;
import java.io.Serializable;
import java.util.List;
@Getter
@Setter
public class InterviewVO implements Serializable {
/**
* 问题列表
*/
private List<Interview> questionList;
/**
* 内部类(具体的问题信息)
*/
@Data
public static class Interview {
/**
* pdf识别出来的关键词(分类名-标签名)
*/
private String keyWord;
/**
* 标签的分类id
*/
private Long categoryId;
/**
* 标签id
*/
private Long labelId;
}
}
2.策略模式准备
1.引擎策略枚举 EngineEnum.java
package com.sunxiansheng.interview.api.enums;
import lombok.Getter;
/**
* 引擎
*/
@Getter
public enum EngineEnum {
JI_CHI,
ALI_BL,
}
2.引擎策略能力接口 InterviewEngine.java
package com.sunxiansheng.interview.server.service;
import com.sunxiansheng.interview.api.enums.EngineEnum;
import com.sunxiansheng.interview.api.vo.InterviewVO;
import java.util.List;
/**
* 引擎能力接口
*/
public interface InterviewEngine {
/**
* 标识引擎类型的能力
*/
EngineEnum engineType();
/**
* 通过简历关键字获取面试关键字
*/
InterviewVO analyse(List<String> KeyWords);
}
3.本地引擎具体策略 JiChiInterviewEngine.java
package com.sunxiansheng.interview.server.service.impl;
import com.sunxiansheng.interview.api.enums.EngineEnum;
import com.sunxiansheng.interview.api.vo.InterviewVO;
import com.sunxiansheng.interview.server.entity.po.SubjectCategory;
import com.sunxiansheng.interview.server.entity.po.SubjectLabel;
import com.sunxiansheng.interview.server.mapper.SubjectMapper;
import com.sunxiansheng.interview.server.service.InterviewEngine;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.function.Function;
import java.util.stream.Collectors;
/**
* Description: 本地的引擎
* @Author sun
* @Create 2024/7/22 14:23
* @Version 1.0
*/
@Component
public class JiChiInterviewEngine implements InterviewEngine {
@Resource
private SubjectMapper subjectMapper;
/**
* 所有的标签和
*/
private List<SubjectLabel> labels;
private Map<Long, SubjectCategory> categoryMap;
// bean装载后初始化
@PostConstruct
public void init() {
labels = subjectMapper.listAllLabel();
// 收集成map,key为分类id,value为分类对象
categoryMap = subjectMapper.listAllCategory().stream().collect(Collectors.toMap(
SubjectCategory::getId, Function.identity()
));
}
/**
* 枚举标识自己是本地引擎
* @return
*/
@Override
public EngineEnum engineType() {
return EngineEnum.JI_CHI;
}
/**
* 根据关键词分析简历
* @param KeyWords
* @return
*/
@Override
public InterviewVO analyse(List<String> KeyWords) {
// 判空
if (CollectionUtils.isEmpty(KeyWords)) {
return new InterviewVO();
}
// 首先过滤出所有是关键词的标签
List<SubjectLabel> includedLabels = labels.stream().filter(item -> {
return KeyWords.contains(item.getLabelName());
}).collect(Collectors.toList());
// map成InterviewVO.Interview
List<InterviewVO.Interview> collect = includedLabels.stream().map(
// label为是关键词的标签
label -> {
InterviewVO.Interview interview = new InterviewVO.Interview();
// 根据标签来获取这个标签所在的分类
SubjectCategory subjectCategory = categoryMap.get(label.getCategoryId());
// 如果分类不为空,则将分类名和标签名format成 "分类名-标签名" 的格式作为KeyWord
if (Objects.nonNull(subjectCategory)) {
interview.setKeyWord(String.format("%s-%s", subjectCategory.getCategoryName(), label.getLabelName()));
} else {
interview.setKeyWord(label.getLabelName());
}
interview.setCategoryId(label.getCategoryId());
interview.setLabelId(label.getId());
return interview;
}
).collect(Collectors.toList());
InterviewVO interviewVO = new InterviewVO();
interviewVO.setQuestionList(collect);
return interviewVO;
}
}
3.业务
1.InterviewController.java
package com.sunxiansheng.interview.server.controller;
import com.alibaba.fastjson.JSON;
import com.google.common.base.Preconditions;
import com.sunxiansheng.interview.api.common.Result;
import com.sunxiansheng.interview.api.req.InterviewReq;
import com.sunxiansheng.interview.api.vo.InterviewVO;
import com.sunxiansheng.interview.server.convert.InterviewHistoryConvert;
import com.sunxiansheng.interview.server.entity.dto.InterviewHistoryDto;
import com.sunxiansheng.interview.server.entity.page.PageResult;
import com.sunxiansheng.interview.server.entity.req.InterviewHistoryReq;
import com.sunxiansheng.interview.server.entity.vo.InterviewHistoryVo;
import com.sunxiansheng.interview.server.service.InterviewHistoryService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
import java.util.Objects;
/**
* 模拟面试信息 前端控制器
*
* @author sun
* @since 2024-07-21 16:03:42
*/
@Slf4j
@RestController
@RequestMapping("/interview")
public class InterviewController {
/**
* 服务对象
*/
@Resource
private InterviewHistoryService interviewHistoryService;
/**
* 分页查询数据
*
* @param req 筛选条件
* @return 查询结果
*/
@GetMapping("/queryPage")
public Result<PageResult<InterviewHistoryVo>> queryByPage(@RequestBody InterviewHistoryReq req) {
try {
// 打印日志
if (log.isInfoEnabled()) {
log.info("分页查询数据入参{}", JSON.toJSONString(req));
}
// ============================== Preconditions 参数校验 ==============================
// ============================== Preconditions 参数校验 ==============================
// 将req转换为dto(如果req的字段符合service层的规范,不转也可以)
InterviewHistoryDto interviewHistoryDto = InterviewHistoryConvert.INSTANCE.convertReqToDto(req);
// 调用service层
PageResult<InterviewHistoryVo> interviewHistoryVoPageResult = this.interviewHistoryService.queryByPage(interviewHistoryDto);
return Result.ok(interviewHistoryVoPageResult);
} catch (Exception e) {
// 打印error日志
log.error("分页查询数据!错误原因{}", e.getMessage(), e);
return Result.fail(e.getMessage());
}
}
/**
* 分析简历
*/
@PostMapping(value = "/analyse")
public Result<InterviewVO> analyse(@RequestBody InterviewReq req) {
try {
if (log.isInfoEnabled()) {
log.info("分析简历入参{}", JSON.toJSON(req));
}
Preconditions.checkArgument(!Objects.isNull(req), "参数不能为空!");
Preconditions.checkArgument(!Objects.isNull(req.getEngine()), "引擎不能为空!");
Preconditions.checkArgument(!Objects.isNull(req.getUrl()), "简历不能为空!");
return Result.ok(interviewHistoryService.analyse(req));
} catch (IllegalArgumentException e) {
log.error("参数异常!错误原因{}", e.getMessage(), e);
return Result.fail(e.getMessage());
} catch (Exception e) {
log.error("分析简历异常!错误原因{}", e.getMessage(), e);
return Result.fail("分析简历异常!");
}
}
}
2.InterviewHistoryService.java
package com.sunxiansheng.interview.server.service;
import com.sunxiansheng.interview.api.req.InterviewReq;
import com.sunxiansheng.interview.api.vo.InterviewVO;
import com.sunxiansheng.interview.server.entity.dto.InterviewHistoryDto;
import com.sunxiansheng.interview.server.entity.page.PageResult;
import com.sunxiansheng.interview.server.entity.vo.InterviewHistoryVo;
/**
* 面试汇总记录表(InterviewHistory)service接口
*
* @author sun
* @since 2024-07-21 16:03:42
*/
public interface InterviewHistoryService {
/**
* 分页查询
*
* @param Dto 筛选条件
* @return 查询结果
*/
PageResult<InterviewHistoryVo> queryByPage(InterviewHistoryDto Dto);
/**
* 使用引擎分析简历
*
* @param req
* @return
*/
InterviewVO analyse(InterviewReq req);
}
3.InterviewHistoryServiceImpl.java
package com.sunxiansheng.interview.server.service.impl;
import com.google.common.base.Preconditions;
import com.sunxiansheng.interview.api.req.InterviewReq;
import com.sunxiansheng.interview.api.vo.InterviewVO;
import com.sunxiansheng.interview.server.convert.InterviewHistoryConvert;
import com.sunxiansheng.interview.server.entity.dto.InterviewHistoryDto;
import com.sunxiansheng.interview.server.entity.page.PageResult;
import com.sunxiansheng.interview.server.entity.page.SunPageHelper;
import com.sunxiansheng.interview.server.entity.po.InterviewHistoryPo;
import com.sunxiansheng.interview.server.entity.po.SubjectLabel;
import com.sunxiansheng.interview.server.entity.vo.InterviewHistoryVo;
import com.sunxiansheng.interview.server.mapper.InterviewHistoryMapper;
import com.sunxiansheng.interview.server.mapper.SubjectMapper;
import com.sunxiansheng.interview.server.service.InterviewEngine;
import com.sunxiansheng.interview.server.service.InterviewHistoryService;
import com.sunxiansheng.interview.server.util.PDFUtil;
import com.sunxiansheng.interview.server.util.keyword.KeyWordUtil;
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.*;
import java.util.stream.Collectors;
/**
* 面试汇总记录表(InterviewHistory)service实现类
*
* @author sun
* @since 2024-07-21 16:27:12
*/
@Service("interviewHistoryService")
public class InterviewHistoryServiceImpl implements InterviewHistoryService, ApplicationContextAware {
@Resource
private InterviewHistoryMapper interviewHistoryMapper;
@Resource
private SubjectMapper subjectMapper;
/**
* 存放所有的引擎策略的map
*/
private static final Map<String, InterviewEngine> engineMap = new HashMap<>();
/**
* 在bean初始化之后立即被调用,这里用来得到所有的引擎对象并封装到map中,方便获取
*
* @param applicationContext
* @throws BeansException
*/
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
// 从上下文中获取所有具体的引擎
Collection<InterviewEngine> engines = applicationContext.getBeansOfType(InterviewEngine.class).values();
// 将这些引擎放到map中
for (InterviewEngine engine : engines) {
engineMap.put(engine.engineType().name(), engine);
}
}
/**
* 分页查询
*
* @param interviewHistoryDto 筛选条件,需要携带pageNo和pageSize以及查询条件
* @return 分页结果
*/
@Override
public PageResult<InterviewHistoryVo> queryByPage(InterviewHistoryDto interviewHistoryDto) {
// 将dto转换为po
InterviewHistoryPo interviewHistoryPo = InterviewHistoryConvert.INSTANCE.convertDtoToPo(interviewHistoryDto);
// 使用 SunPageHelper 执行分页操作
PageResult<InterviewHistoryPo> paginate = SunPageHelper.paginate(interviewHistoryDto.getPageNo(), interviewHistoryDto.getPageSize(),
() -> interviewHistoryMapper.count(interviewHistoryPo),
(offset, size) -> interviewHistoryMapper.queryPage(interviewHistoryPo, offset, size)
);
// 将po转换为vo
PageResult<InterviewHistoryVo> interviewHistoryVoPageResult = InterviewHistoryConvert.INSTANCE.convertPageResult(paginate);
return interviewHistoryVoPageResult;
}
/**
* 分析简历
*
* @param req
* @return
*/
@Override
public InterviewVO analyse(InterviewReq req) {
// 从pdf中获取关键词
List<String> keyWords = buildKeyWords(req.getUrl());
// 从map中获取处理的引擎
InterviewEngine engine = engineMap.get(req.getEngine());
Preconditions.checkArgument(!Objects.isNull(engine), "引擎不能为空!");
// 使用获取到的引擎来分析简历
return engine.analyse(keyWords);
}
/**
* 分析pdf来获取关键词
*
* @param url
* @return
*/
private List<String> buildKeyWords(String url) {
String pdfText = PDFUtil.getPdfText(url);
if (!KeyWordUtil.isInit()) {
// 数据库中查询所有标签,作为敏感词放到KeyWordUtil
List<String> list = subjectMapper.listAllLabel().stream().map(SubjectLabel::getLabelName).collect(Collectors.toList());
KeyWordUtil.addWord(list);
}
// 与数据库中查询出来的敏感词来进行比对,得到关键字列表
return KeyWordUtil.buildKeyWordsLists(pdfText);
}
}
4.测试