1.背景介绍
1.1地理空间数据云
由中国科学院计算机网络信息中心科学数据中心成立的地理空间数据云平台是常见的下载空间数据的平台之一。其提供了较为完善的公开数据,如LANDSAT系列数据,MODIS的标准产品及其合成产品,DEM数据(SRTM 90M,ASTER GDEM 30M),EO-1数据,大气污染插值数据,Sentinel数据,高分一号WFV数据产品,NOAA VHRR 数据产品等。地理空间数据云提供高级检索功能,能够根据数据集、空间位置、时间范围、月份、云量、数据有无进行检索,如图1所示。
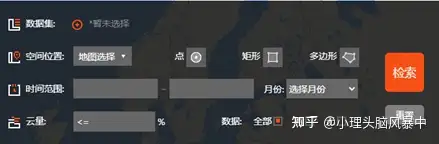
图1 地理空间云高级检索功能
1.2 Selenium+Chromedriver
日常工作中经常需要下载多个区域或者长时间段的遥感影像,然而地理空间数据云的高级检索功能中并未提供没有批量下载的功能,人为手动一景一景下载耗时费力。如若能实现数据的自动化批量下载,将会大幅提高工作效率。利用Selenium+ChromeDriver建立爬虫,即可实现自动化批量下载大量数据。
Selenium是一个Web自动化程序,相当于一个机器人,可以模拟并自动处理人类在浏览器上的一些行为,比如点击、填充数据、删除cookie等等一系列操作。Chromedriver是一个驱动chrome浏览器的驱动程序,使用它才可以驱动浏览器。两者结合就能够实现浏览器操作的自动化,简化人力的重复点击劳动。
2.实验操作
2.1环境配置与工具下载
(1)Python没有自带selenium库,需要自行下载,只需要用简单的命令即可实现:
pip install selenium
(2)下载ChromeDriver之前,需要首先确定浏览器的版本,在浏览器中输入chrome://version/,图2红线所示即为浏览器的版本:

图2 浏览器版本查看
(3)接着去下载对应版本的Chromedriver。通常从以下网址下载:
2.2浏览器对象创建与网页元素获取
(1)首先导入相关模块,然后创建浏览器对象,指定驱动所在路径,接着打开地理空间数据云的首页。代码如下:
from selenium import webdriver
driver_path = r"F:\Pycharm\GeoCloud\chromedriver.exe" # 驱动所在路径
browser = webdriver.Chrome(executable_path=driver_path) # 打开浏览器,指定驱动路径
browser.get('http://www.gscloud.cn/') # 打开地理空间数据云首页运行这些代码会打开一个自动控制的浏览器窗口,并显示"Chrome正受到自动测试软件的控制"。
(2)为了模拟我们的点击活动,需要获取感兴趣的网页元素的地址,selenium提供了例如id,name,classname,xpath,linktext的方法获取元素。本实验采取xpath的方法获取需要点击的元素:首先右键点击需要的元素,然后选择检查,在需要的元素上右键复制Xpath,操作步骤如图3所示。
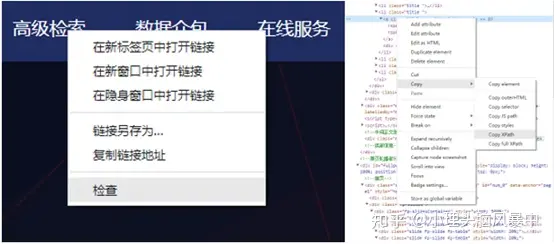
图3 获取元素Xpath
2.3代码实现
配置上述环境之后,下面是具体数据下载的python代码,实现南京地区2000年至今MODIS合成数据集16日的NDVI数据批量下载:
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
import os
driver = webdriver.Chrome(executable_path=r'F:\Pycharm\GeoCloud\chromedriver.exe')
driver.get('http://www.gscloud.cn/accounts/login_user')
email = driver.find_element_by_xpath('//*[@id="email"]')
email.send_keys('***') #账号
password = driver.find_element_by_xpath('//*[@id="password"]')
password.send_keys('***') #密码
captcha = driver.find_element_by_xpath('//*[@id="id_captcha_1"]')
captcha_sj = input('请输入验证码:').strip()
captcha.send_keys(captcha_sj)
# 模拟点击过程
dr_buttoon = driver.find_element_by_xpath('//*[@id="btn-login"]').click() #输入验证码后点击登入按钮
time.sleep(3)
gjjs = driver.find_element_by_xpath('/html/body/div[1]/div[1]/div[2]/ul/li[2]').click() #点击高级检索
time.sleep(3)
dataset = driver.find_element_by_xpath('//*[@id="dataset-btn"]').click() #选择数据集
time.sleep(0.5)
plus = driver.find_element_by_xpath('//*[@id="all-datasets-dlg"]/div/div[2]/div/div[2]/ul/li[2]/span[1]').click() #点击加号
time.sleep(0.5)
select = driver.find_element_by_xpath('//*[@id="all-datasets-dlg"]/div/div[2]/div/div[2]/ul/li[2]/ul/li[16]/div/label').click() #点击数据集
time.sleep(0.5)
queding = driver.find_element_by_xpath('//*[@id="all-datasets-dlg"]/div/div[3]/button[2]').click() #确定
time.sleep(0.5)
dituxuanze = driver.find_element_by_xpath('//*[@id="condition-panel"]/div[2]/div[2]/div').click() #地图选择
time.sleep(0.5)
xingzhengqu = driver.find_element_by_xpath('//*[@id="condition-panel"]/div[2]/div[2]/div/label[1]').click() #行政区
time.sleep(0.5)
sheng = driver.find_element_by_xpath('//*[@id="provinces-list"]').click() #省
time.sleep(0.5)
sheng_s = driver.find_element_by_xpath('//*[@id="reg32"]').click() #省
time.sleep(0.5)
shi = driver.find_element_by_xpath('//*[@id="city-list"]').click() #市
time.sleep(0.5)
shi_c = driver.find_element_by_xpath('//*[@id="city-list"]/option[9]').click() #市
time.sleep(0.5)
Time1 = driver.find_element_by_xpath('//*[@id="sdate-input"]') #Time1
Time1.send_keys('2000-01-01')
time.sleep(0.5)
Time2 = driver.find_element_by_xpath('//*[@id="edate-input"]') #Time2
Time2.send_keys('2022-12-31')
time.sleep(0.5)
jiansuo = driver.find_element_by_xpath('//*[@id="search-btn"]').click() #检索
# 开始下载
# #一共是7页
page_num = 49
page = 1
while page <= page_num:
print('当前下载第{}页'.format(page))
for tr_num in range(1,11): # 每页10个
d_everypage = '//*[@id="result-listview"]/div/table/tr['+str(tr_num)+']/td[2]/div/div/a[2]/span'
WebDriverWait(driver, 20).until(expected_conditions.visibility_of_element_located((By.XPATH, d_everypage))) # 翻页后重新定位,否则报错ElementClickInterceptedException:
element = driver.find_element_by_xpath(d_everypage)
webdriver.ActionChains(driver).move_to_element(element).click(element).perform()
time.sleep(600) #下载间隔
page += 1
next = driver.find_element_by_xpath('//*[@id="pager"]/div/table/tr/td[10]/a/span/span/span').click() # 下一页
time.sleep(3)3.实验结果
图4展示了下载的影像中的其中一幅。经过高级检索我们可以发现,符合要求的影像共有487条,人为手动下载必然是很大的工作量,但是使用爬虫可以大大缩减工作量。
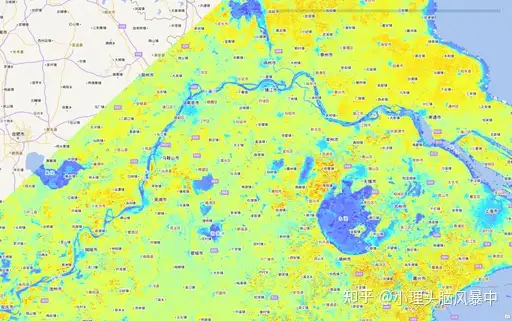
图4 实验下载影像
文案 | 陆鼎阳
编辑&校对 | 曹浩宇&杨陵
指导 | 熊礼阳 副教授
侵删