map底层结构
Goland的map的底层结构使用hash实现,一个hash表里有多个hash表节点,即bucket,每个bucket保存了map中的一个或者一组键值对。
map结构定义:
runtime/map.go:hmap
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}其中 buckets为 bucket数组指针,数组的大小为2^B
若B=2则,buckets数量是2^2=4
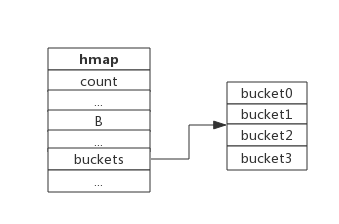 hash结果示意图
hash结果示意图
bucket是桶,通常用来表示一类数据的集合。hash表里的bucket称之为
哈希桶,通常是求余后结果相同的落入一个桶中。
根据key值计算出哈希值,取hash值的低8位与2^hmap.B取模确定存放数据到哪个bucket
bucket结构
bucket结构定义,逻辑上是如下的结果:
go
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
data byte[1] //key value数据:key/key/key/.../value/value/value...
overflow *bmap //溢出bucket的地址
}-
tophash 是长度为8的数组,哈希值高位相同的分到同一个bucket中的键,存入当前bucket时候,会将哈希值的高位存在在该数组中,以方便后续匹配。
-
data这块其实是8个key、8个value,但是我们不能直接看到;为了优化对齐,go采用了key放在一起,value放在一起的存储方式。
-
overflow表示hash冲突发生时,下一个溢出桶的地址
上述中data和overflow并不是在结构体中显示定义的,实际包代码中定义也看不到,但是有这个逻辑存在。
实际源码定义可参考:https://cs.opensource.google/go/go/+/refs/tags/go1.23.0:src/runtime/map.go
这样的定义实现了:若某个哈希对应的bucket空间已满,则需要创建一个新的bmap存储键值对,无数个bmap通过overflow指针进行关联。buckets链条是类似于这样的结构:
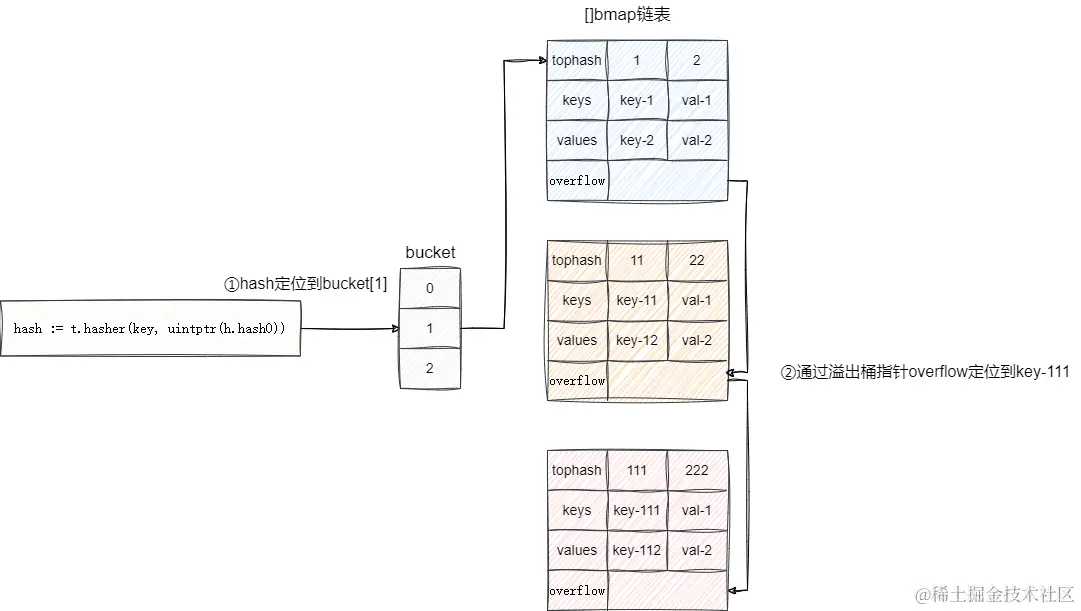
hmap和bmap结构
结合以上hmap和bmap的结构,我们可以总结一个map基本结构:
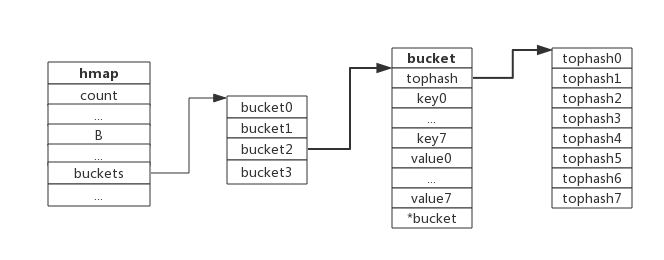
负载因子
负载因子用来衡量一个哈希表冲突情况,公式为:
负载因子=键的数量/bucket数量
对于上图的负载因子:6/3=2
哈希表需要将负载因子控制在合适的大小,超过阈值需要进行rehash,也即键值对重新组织:
- 哈希因子过小,说明空间利用率低
- 哈希因子过大,说明冲突严重,存取效率低
Go语言负载因子达到6.5时就会触发rehash
hash扩容
新元素添加时候,会检查是否需要扩容,扩容条件:
-
负载因子 > 6.5时,也即平均每个bucket存储的键值对达到6.5个。
-
overflow数量 > 2^15时,也即overflow数量超过32768时。
增量式扩容
当负载因子过大,新建bucket,新的bucket长度是原2倍,旧bucket数据搬迁至新的bucket。搬迁过程采样逐步搬迁策略,即每次访问map都会触发一次搬迁,每次搬迁2个键值对。
渐进式扩容中,oldbuckets指向原来的桶。而buckets指向了新申请的bucket。新的键值对被插入新的bucket中。后续对map的访问操作会触发迁移,将oldbuckets中的键值对逐步的搬迁过来。当oldbuckets中的键值对全部搬迁完毕后,删除oldbuckets。
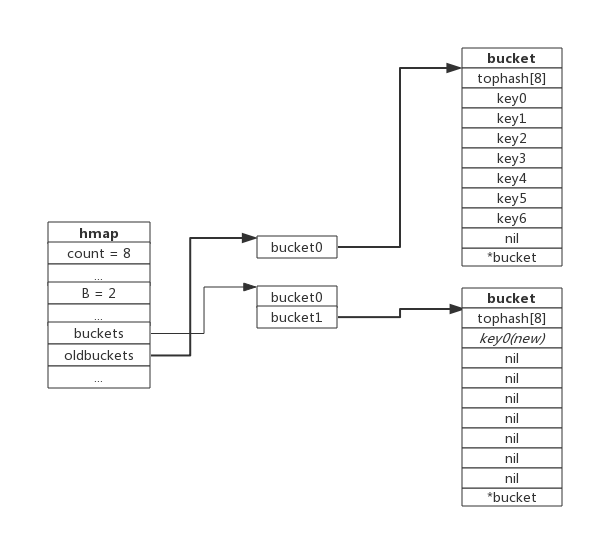
如上,bucket0已经有7个值,此时负载因子是7,超过6.5,当再存入一个key时,就会触发扩容。新建了bucket1,但是新建的bucket是buckets指向的,且在新的空间给bucket0留出位置,待一点点的将oldbuckets指向的空间数据迁移至新的bucket0空间,然后删除就得oldbuckets指向的空间。搬迁完成的空间示意图:
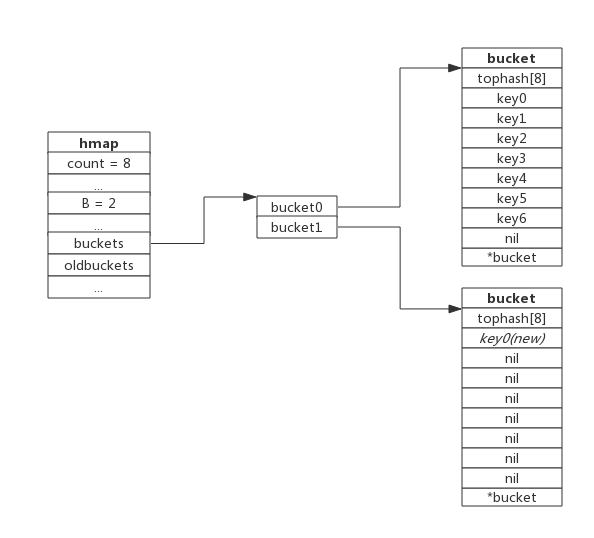
等量式扩容
所谓等量扩容,实际上并不是扩大容量。buckets数量不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取
map查找数据
-
首先根据key值计算出哈希值
-
取哈希值的低八位与2^hmap.B取模确定bucket位置
-
取高八位在桶数组中进行查找
-
如果tophashi中存储值也哈希值相等,则去找到该bucket中的key值进行比较
-
当前bucket没有找到,则继续从下个overflow的bucket中查找。
-
如果当前处于扩容搬迁过程,则优先从oldbuckets查找
map插入过程
- 根据key值算出哈希值
- 取哈希值低位与hmap.B取模确定bucket位置
- 查找该key是否已经存在,如果存在则直接更新值
- 如果没找到将key,将key插入
map操作
操作包括初始化、键的判断、遍历、作为函数参数使用
map声明与初始化
map是一种引用类型,有几种声明方法:
-
声明空的map
var myMap map[string]int
这样声明的map是nil值,对它操作之前,必须使用make来初始化。
注意,struct结构中成员是map变量的话,在实际使用中必须再make初始化空间。
-
使用make直接声明+初始化
stringMap := make(map[string]string, n)
n表示长度,但是使用中是可以扩容的,相当于建议的长度。
-
使用字面量初始化
myMap := map[string]int{ "one": 1, "two": 2, "three": 3, }
:= 是一个特殊的赋值操作符,被称为"短变量声明"或"短变量赋值"。它主要用于在函数内部声明并初始化新的局部变量。使用 := 可以同时完成变量的声明和初始化,使得代码更加简洁。在全局作用域(即函数外部)不能使用 := 来声明变量,因为 := 会隐式地声明变量,而全局变量需要显式声明。
4,使用var关键字结合字面量来初始化
var myMap = map[string]int{
"one": 1,
"two": 2,
"three": 3,
}5,显示声明类型+初始化
var myMap map[string]int = map[string]int{ "one": 1, "two": 2, "three": 3, }对于全局变量或需要在多个地方引用的变量,显式声明类型可能更加合适。
判断键是否存在
value, ok := sliceMapkey
判断ok来判断值是否存在
key := "小明"
value, ok := deleMap[key]
if ok {
fmt.Println("key:", key, "value:", value)
} else {
fmt.Println("key:", key, "不存在")
}删除键值对
delete(mapName,key)
删除mapName map中的key值键值对
deleMap := make(map[string]int)
deleMap["张三"] = 90
deleMap["小明"] = 100
deleMap["王五"] = 60
fmt.Println("map:", deleMap)
delete(deleMap, "小明")
fmt.Println("map after delete:", deleMap)delete是安全的操作,即使删除不存在的key也不报错。delete中如果查找删除失败将返回value类型对应的零值
m1 := map[int]string{1: "sss", 2: "fff", 3: "zzz"}
delete(m1, 5)
for k, v := range m1 {
fmt.Printf("%d ----> %s\n", k, v)
}
//1 ----> sss
//2 ----> fff
//3 ----> zzz遍历map
使用for range遍历map,第一个参数是key,第二是value
for key, value := range scoreMap {
fmt.Println(key, value)
}第二种遍历方法,只返回key,省略value
for k := range scoreMap {
fmt.Printf("%s----> %v\n", k, scoreMap[k])
}map长度
可以使用len函数获取map中键值对的个数:
fmt.Println("len is:", len(stringMap))map作为函数参数与返回值
map作为函数参数是引用传递
map作为函数返回值也是引用传递
m1 := map[int]string{1: "sss", 2: "fff", 3: "zzz"}
m2 := getAndChangeMap(m1)
fmt.Println("map m2:", m2)
fmt.Println("map m1:", m1)
m2[4] = "yiyi"
fmt.Println("change m2")
fmt.Println("map m2:", m2)
fmt.Println("map m1:", m1)
func getAndChangeMap(m map[int]string) map[int]string {
m[23] = "lili"
return m
}打印内容
map m2: map1:sss 2:fff 3:zzz 23:lili
map m1: map1:sss 2:fff 3:zzz 23:lili
change m2
map m2: map1:sss 2:fff 3:zzz 4:yiyi 23:lili
map m1: map1:sss 2:fff 3:zzz 4:yiyi 23:lili