【引子】近来在探索并优化AIPC的软件架构,AI产品经理关于语义搜索的讨论给了自己较多的触动,于是重新梳理嵌入与语义的关系,遂成此文。
文本转换成机器可理解格式的最早版本之一是 ASCII码,这种方法有助于渲染和传输文本,但不能编码单词的意义,其标准的搜索技术是关键字搜索,寻找包含特定单词或 N-gram的所有文档。如今,我们可以计算单词、句子甚至图像的嵌入。嵌入也是数字的向量,但它们可以捕捉意义。因此,可以使用它们进行语义搜索,甚至处理不同语言的文档。
1. 文本嵌入的演变
将文本转换为向量的最基本方法是使用词袋模型(bag of words,BoW)。获得一个单词向量的第一步是将文本分割成单词(标记) ,然后将单词减少到它们的基本形式。例如," running"将转换为" run",这个过程称为词干分析。我们可以使用NLTK 来观察这个过程。
go
from nltk.stem import SnowballStemmer
from nltk.tokenize import word_tokenize
text = ' target text for Bow model'
# tokenization - splitting text into words
words = word_tokenize(text)
print(words)
stemmer = SnowballStemmer(language = "english")
stemmed_words = list(map(lambda x: stemmer.stem(x), words))
print(stemmed_words)现在,有了所有单词的基本形式列表。下一步是计算它们的频率,创建一个向量。
go
import collections
bag_of_words = collections.Counter(stemmed_words)
print(bag_of_words)这种方法非常基本,而且没有考虑到词语的语义,略有改进的版本是 TF-IDF ,这是两个度量的乘法。
TF显示文档中单词的频率。最常见的计算方法是将文档中的词汇的原始计数除以文档中的词汇(单词)总数。然而,还有许多其他方法,如原始计数、布尔"频率"和不同的标准化方法。IDF表示单词提供的信息量。例如,单词" a"或" that"不会提供关于文档主题的任何其他信息。它被计算为文档总数与包含单词的文档总数之比的对数。IDF 越接近于0ーー这个词越常见,它提供的信息就越少。
最后,将得到常见单词的权重较低的向量,而在文档中多次出现的罕见单词的权重较高。这个策略会给出一个更好的结果,但是它仍然不能捕获语义。
这种方法的一个问题是会产生稀疏向量。由于向量的长度等于语料库的大小,将有巨大的向量。但是,句子一般不会有超过50个独特的单词,向量中大量的值将为0,不编码任何信息。
有名的密集向量表示方法之一是 word2vec,由谷歌于2013年在 Mikolov 等人的论文"Efficient Estimation of Word Representations in Vector Space"中提出。文章中提到了两种不同的 word2vec 方法: "CBoW"和"Skip-gram"。
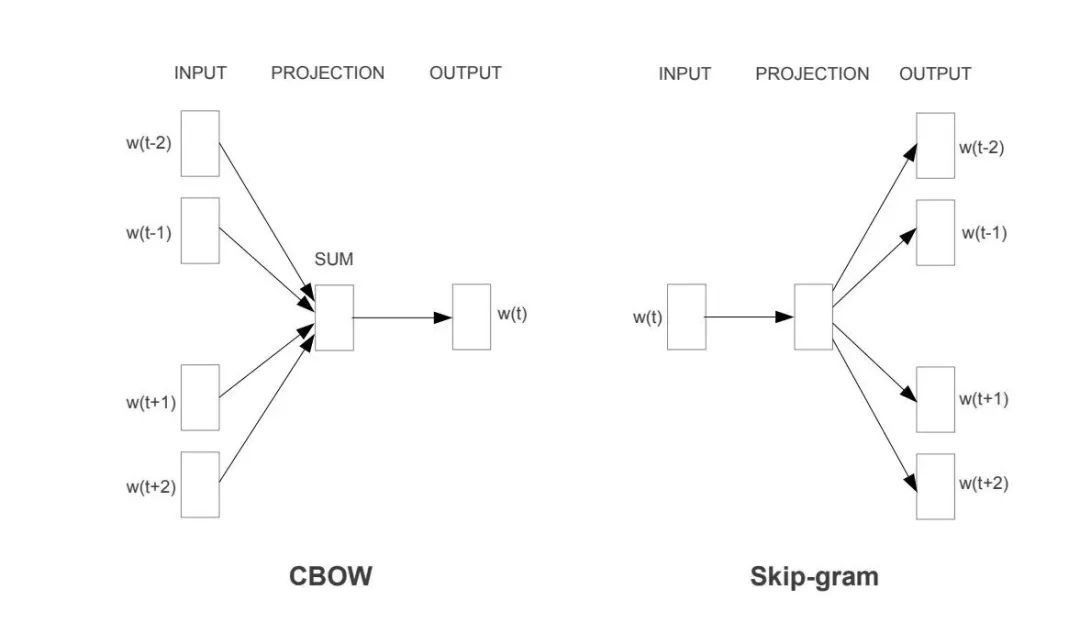
密集向量表示的核心思想是训练两种模型: 编码器和解码器。例如,在Skip-gram情况下,我们可以将"国庆节"传递给编码器。然后,编码器将产生一个向量,我们传递给解码器期望得到单词"快乐""祝""你"。这个模型开始考虑单词的意思,因为它是根据单词的上下文进行训练的。然而,它忽略了词语的表面形式。这个缺点后来在 GloVe 中得到了一定的解决。
word2vec 只能处理单词,但我们希望编码整个句子,于是人们引入了Transformer。在论文" Attention Is All You Need"中,transformer能够产生信息密集的矢量,并成为现代语言模型的主导技术。
Transformers 允许使用相同的基础模型,并针对不同的用例对其进行微调,而无需重新训练基础模型,这导致了预训练模型的兴起。第一个流行的模型之一是 BERT ,是基于transformer的双向编码器表示。BERT 仍然在类似 word2vec 的token级别上运行,获得句子嵌入的简单方法可能是取所有向量的平均值。不幸的是,这种方法并没有显示出良好的性能。在论文"Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks"中,解决了句子嵌入的计算问题。
然而, 句子的嵌入 或者说句子的语义表达是个大课题, 还需要进一步深入研究。
2.文本嵌入的计算
如今,已经有很多的嵌入模型可以供我们参考和使用,例如 OpenAI 的text-embedding-ada-002和text-embedding-3-large,当然,我们也可以通过Huggingface的嵌入模型排行榜进行选择并探索。
go
from openai import OpenAI
client = OpenAI()
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model)\
.data[0].embedding
get_embedding("Here is TEXT what we want ..... ")结果,我们得到了一个1536维的浮点数向量, 然后,我们可以为所有的数据计算向量,并展开分析,一个主要的目标是了解句子之间的意义有多接近。我们可以计算向量之间的距离,较小的距离相当于较近的意义。
假设有两个文本的嵌入是vector1 和vector2, 可以使用不同的度量标准来衡量两个向量之间的距离:
-
欧式距离
-
曼哈顿距离
-
向量点积
-
余弦距离
2.1 欧式距离
定义两点(或向量)之间距离的直观方法是欧式距离,或者叫 L2范数。我们可以直接使用python或者利用 numpy 函数来计算这个度量。
go
import numpy as np
L2_py = sum(list(map(lambda x, y: (x - y) ** 2, vector1, vector2))) ** 0.5
L2_np = np.linalg.norm((np.array(vector1) - np.array(vector2)), ord = 2)2.2 曼哈顿距离
另一个常用的距离是 L1标准距离或曼哈顿距离,是以纽约曼哈顿岛来命名的。这个岛上的街道有网格布局,曼哈顿两点之间的最短路线是跟着网格走的 L1距离。我们同样可以使用python或者利用 numpy 函数来计算这个度量。
go
L1_py = sum(list(map(lambda x, y: abs(x - y), vector1, vector2)))
L1_np = np.linalg.norm((np.array(vector1) - np.array(vector2)), ord = 1)2.3 向量点积
观察向量间距离的另一种方法是计算点积。
go
sum(list(map(lambda x, y: x*y, vector1, vector2)))
np.dot(vector1, vector2)点积需要从几何上进行理解。一方面,它显示向量是否指向一个方向。另一方面,结果高度依赖于矢量的大小。例如,计算两对(1,1)向量之间的点积为2, 计算两对(10,10)向量之间的点积为20,在这两种情况下,向量是共线的,但是点积在第二种情况下要大十倍。
2.4 余弦距离
余弦距离是由向量的大小(或范数)归一化的点积。我们可以用前面的方法计算余弦距离,还可以利用Sklearn。
go
dot_product = sum(list(map(lambda x, y: x*y, vector1, vector2)))
norm_vector1 = sum(list(map(lambda x: x ** 2, vector1))) ** 0.5
norm_vector2 = sum(list(map(lambda x: x ** 2, vector2))) ** 0.5
cs_py=dot_product/norm_vector1/norm_vector2
print(cs_py)
from sklearn.metrics.pairwise import cosine_similarity
cs_sk = cosine_similarity(
np.array(vector1).reshape(1, -1),
np.array(vector2).reshape(1, -1))[0][0]
print(cs_sk)cosine_similarity 函数需要2D 数组,所以需要将向量转化为数组的形式。余弦距离等于两个向量之间的余弦。向量越接近,度量值就越高。
我们可以使用任何距离来比较所有的文本嵌入。然而,对于自然语言处理的任务,一般的做法通常是使用余弦距离,因为:
-
余弦距离在 -1和1之间,而 L1和 L2是无界的,所以更容易解释。
-
从实际角度来看,计算欧几里得度量点积比计算平方根更有效。
-
余弦距离受维数灾难的影响较小。
其中,"维数灾难"是指维度越高,矢量之间的距离分布越窄。
3. 文本嵌入的可视化
理解数据的最好方法就是将它们可视化。不幸的是,如果文本嵌入有1536个维度,理解数据会非常困难。然而,我们可以使用降维技术在二维空间中做向量投影。
最基本的降维技术是 PCA (主成分分析) ,我们将嵌入转换成一个2D numpy 数组,然后将其传递给 sklearn。
go
import numpy as np
from sklearn.decomposition import PCA
embeddings_array = np.array(df.embedding.values.tolist())
print(embeddings_array.shape)
pca_model = PCA(n_components = 2)
pca_model.fit(embeddings_array)
pca_embeddings_values = pca_model.transform(embeddings_array)
print(pca_embeddings_values.shape)因此得到了一个矩阵,可以很容易地把它做成在一个散点图。
go
fig = px.scatter(
x = pca_embeddings_values[:,0],
y = pca_embeddings_values[:,1],
color = df.topic.values,
hover_name = df.full_text.values,
title = 'PCA embeddings', width = 800, height = 600,
color_discrete_sequence = plotly.colors.qualitative.Alphabet_r
)
fig.update_layout(
xaxis_title = 'first component',
yaxis_title = 'second component')
fig.show()PCA是一种线性算法,而现实生活中大多数关系是非线性的。因此,由于非线性的原因,可以尝试使用一个非线性算法 t-SNE。
go
from sklearn.manifold import TSNE
tsne_model = TSNE(n_components=2, random_state=42)
tsne_embeddings_values = tsne_model.fit_transform(embeddings_array)
fig = px.scatter(
x = tsne_embeddings_values[:,0],
y = tsne_embeddings_values[:,1],
color = df.topic.values,
hover_name = df.full_text.values,
title = 't-SNE embeddings', width = 800, height = 600,
color_discrete_sequence = plotly.colors.qualitative.Alphabet_r
)
fig.update_layout(
xaxis_title = 'first component',
yaxis_title = 'second component')
fig.show()此外,还可以制作三维空间的投影,并将其可视化。
4. 文本嵌入的应用示例
文本嵌入的主要目的不是将文本编码为数字向量,或者仅仅为了将其可视化。我们可以从捕捉文本含义的能力中受益匪浅。
4.1 聚类
聚类是一种非监督式学习的技术,它允许将数据分成不带任何初始标签的组,可以帮助理解数据中的内部结构模式。最基本的聚类算法是K-Means,应用时需要指定聚类的数目,可以使用轮廓得分来定义最佳的聚类。例如,尝试 聚类数量k 介于2和50之间,对于每个 k,训练一个模型并计算轮廓分数。轮廓得分越高,聚类效果越好。
go
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import tqdm
silhouette_scores = []
for k in tqdm.tqdm(range(2, 51)):
kmeans = KMeans(n_clusters=k,
random_state=42,
n_init = 'auto').fit(embeddings_array)
kmeans_labels = kmeans.labels_
silhouette_scores.append(
{
'k': k,
'silhouette_score': silhouette_score(embeddings_array,
kmeans_labels, metric = 'cosine')
}
)
fig = px.line(pd.DataFrame(silhouette_scores).set_index('k'),
title = '<b>Silhouette scores </b>',
labels = {'value': 'silhoutte score'},
color_discrete_sequence = plotly.colors.qualitative.Alphabet)
fig.update_layout(showlegend = False)如果有实际文本的主题标签,我们可以用它来评估聚类结果的好坏。
4.2 分类
同样,文本嵌入可以用于分类或回归任务。例如,预测客户评论的情绪(分类)或 NPS 评分(回归)。分类和回归是监督式学习,所以需要有数据标签。为了正确评估分类模型的性能,我们将数据集划分为训练集和测试集(80% 比20%)。然后,在一个训练集上训练模型,并在一个测试集上测量质量。
以随机森林分类器为例:
go
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
class_model = RandomForestClassifier(max_depth = 5)
# defining features and target
X = embeddings_array
y = df.topic
# splitting data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state = 49, test_size=0.2, stratify=y)
# fit & predict
class_model.fit(X_train, y_train)
y_pred = class_model.predict(X_test)然后,我们计算一个混淆矩阵,理想的情况下所有非对角线的元素应该是0。
go
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
fig = px.imshow(
cm, x = class_model.classes_,
y = class_model.classes_, text_auto='d',
aspect="auto",
labels=dict(
x="predicted label", y="true label",
color="cases"),
color_continuous_scale='pubugn',
title = '<b>Confusion matrix</b>', height = 550)
fig.show()我们还可以使用嵌入来发现数据中的异常。例如,在可视化的图像上,看到一些问题与它们的聚类相去甚远,那些就可能是异常的数据。
4.3 RAG
随着 LLM 最近越来越流行,文本嵌入在 RAG 用例中得到了广泛的应用。当有很多文档需要检索增强生成时,而我们却不能将它们全部传递给 LLM,因为:
-
LLM 对上下文大小有限制(例如,GPT-4 Turbo 的上下文大小是128K)。
-
由于需要为token付费,所以传递所有信息的成本更高。
-
在更大的上下文中,LLM 显示出的性能较差。
为了能够使用广泛的知识库,我们可以利用 RAG 方法:
-
计算所有文档的嵌入,并将它们存储在向量存储器中。
-
当得到一个用户请求时,可以计算它的嵌入并从存储中检索该请求的相关文档。
-
只将相关文档传递给 LLM 以获得最终答案。
5. 一句话小结
文本处理方法的演变导致了文本嵌入的出现,从词汇的语义表达到句子嵌入,多种距离度量方法可以帮助理解文本是否具有相似的意义,文本嵌入的可视化可以帮助我们了解数据的内在模式,常见的应用示例包括聚类、分类以及基于大模型的RAG等。
ps. 对文本嵌入感兴趣的朋友可以参考老码农的一本译作《基于混合方法的自然语言处理》。

【关联阅读】
-
<>解读向量数据库