DataFrame是一个表格型的数据结构,可以看成就是excel中的表格。
官方文档:https://pandas.pydata.org/docs/reference/frame.html
DataFrame的创建
DataFrame构造方法如下:
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
- data:DataFrame的数据部分,可以是字典、二维数组、Series、DataFrame或其他可转换为DataFrame的对象,若不提供此参数,则创建一个空的DataFrame。
- index:DataFrame的行索引,用于标识每行数据,可以是列表、数组、索引对象等,若不提供此参数,则创建一个默认的整数索引。
- columns:DataFrame的列索引,用于标识每列数据。可以是列表、数组、索引对象等,若不提供此参数,则创建默认的整数索引。
- dtype:指定DataFrame的数据类型,可以是NumPy的数据类型,例如np.int64、np.float64等,若不提供此参数,则根据数据自动推断数据类型。
- copy:是否复制数据,默认为False,表示不复制数据,若设置为True,则复制输入的数据。
一维列表创建DataFrame
|-------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|
| import pandas as pd # 例1:单个列表创建 data = ["张三", "李四", "王五", "赵六"] df = pd.DataFrame(data=data) df |  |
|
二维列表创建DataFrame
|----------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------|
| import pandas as pd # 例2:二维列表创建DataFrame,设置列索引 data =[['Alex',10], ['Bob', 12], ['clarke', 13]] df = pd.DataFrame(data=data, columns=['Name', 'Age']) df | 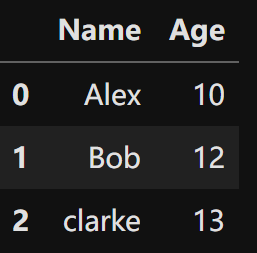 |
|
传递字典创建DataFrame
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------|
| import pandas as pd # 使用默认的行索引,注意:传入字典时字典的KEY成了列索引 data = {'Name': ['Tom', 'Jack', 'steve', 'Ricky'], 'Age': [28, 34, 29, 42]} df = pd.DataFrame(data) print(df) print("*" * 50) # 设置了行索引 data = {'Name': ['Tom', 'Jack', 'steve', 'Ricky'], 'Age': [28, 34, 29, 42]} df = pd.DataFrame(data, index=['rank1', 'rank2', 'rank3', 'rank4']) print(df) | 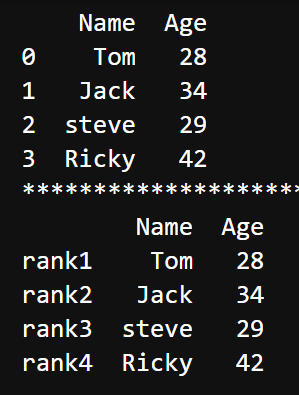 |
|
传递字典列表创建DataFrame
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|
| import pandas as pd data = [{'姓名': '张三', '性别': '男'}, {'姓名': '小红', '性别': '女', '语文': 80}] # 传递字典列表来创建DataFrame df = pd.DataFrame(data) print(df) print('' * 50) # 传递字典列表和行索引来创建DataFrame df = pd.DataFrame(data, index=['first', 'second']) print(df) print('' * 50) # 指定的列索引与字典键相同 df = pd.DataFrame(data, index=['first', 'second'], columns=['姓名', '性别']) print(df) print('*' * 50) # 指定的列索引,其中一个索引具有其他名称 df = pd.DataFrame(data, index=['first', 'second'], columns=['姓名', '班级']) print(df) | 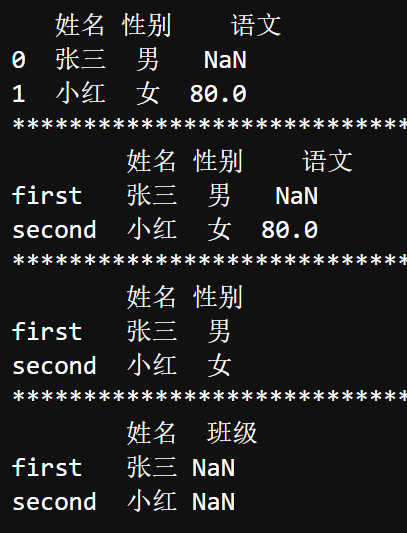 |
|
通过Series对象创建
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|
| import pandas as pd df1 = pd.Series({'california': 423967, 'Texas': 695662, 'New York': 141297, 'Florida': 170312, 'Illinois': 149995}) df2 = pd.Series({'california': 383521, 'Texas': 264193, 'New York': 191127, 'Florida': 195860, 'Illinois': 122135}) # 创建单列的DataFrame df = pd.DataFrame(df1, columns=['area']) print(df) print("*" * 50) # 创建多列的DataFrame对象 df = pd.DataFrame({'area': df1, 'population': df2}) print(df) | 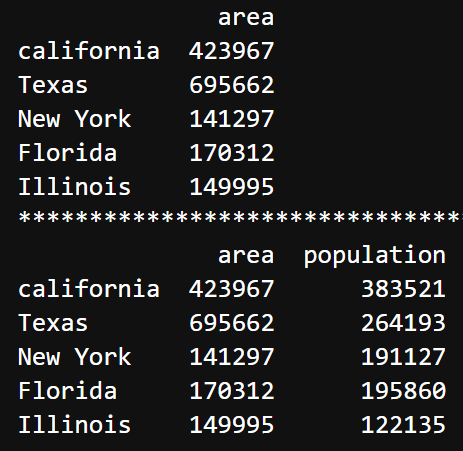 |
|
通过Numpy创建
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|
| import pandas as pd import numpy as np a = np.random.randint(1, 10, (3, 2)) # 基于a数组建立DataFrame df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c']) print(df) | 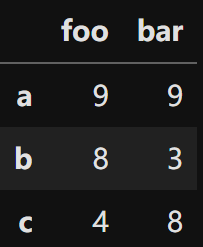 |
|
DataFrame的属性
dataframe.T
df.T属性主要用来转置行和列,和 df.transpose() 实现的效果一样。
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|
| import pandas as pd import numpy as np a = np.random.randint(1, 10, (3, 2)) # 基于a数组建立DataFrame df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c']) print(df) print("*" * 50) print(df.T) | 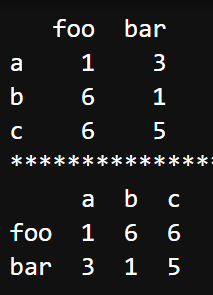 |
|
dataframe.axes
返回包含行索引和列索引的列表,可以通过 df.axes[0].tolist() 或 list(df.axes[0]) 转成行索引列表,列索引列表同理。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
# 基于a数组建立DataFrame
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.axes) # [Index(['a', 'b', 'c'], dtype='object'), Index(['foo', 'bar'], dtype='object')]
print(df.axes[0].tolist()) # ['a', 'b', 'c']
print(list(df.axes[0])) # ['a', 'b', 'c']dataframe.dtypes
查看每列的数据类型。
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|
| import pandas as pd import numpy as np a = np.random.randint(1, 10, (3, 2)) # 基于a数组建立DataFrame df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c']) print(df) print("*" * 50) print(df.dtypes) | 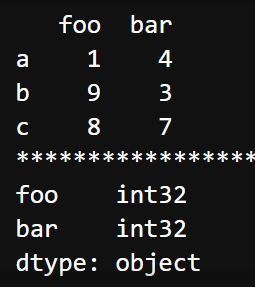 |
|
dataframe.ndim
获取DataFrame的维数。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
# 基于a数组建立DataFrame
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.ndim) # 2dataframe.shape
获取DataFrame的行数和列数,是一个元组。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
# 基于a数组建立DataFrame
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.shape) # (3, 2)dataframe.size
返回DataFrame中的元素个数。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
# 基于a数组建立DataFrame
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.size) # 6dataframe.values
返回一个所有行数据组成的二维的数组,每个元素是一个一维数组(也就是一行数据),可以通过 list(df.values) 或 df.values.tolist() 转成python的列表类型。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
# 基于a数组建立DataFrame
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.values) # [[8 6] [3 3] [8 7]]
print(list(df.values)) # [array([8, 6], dtype=int32), array([3, 3], dtype=int32), array([8, 7], dtype=int32)]
print(df.values.tolist()) # [[8, 6], [3, 3], [8, 7]]dataframe.index
获取行索引,返回的是Index类型,可以通过list(df.index)或 df.index.tolist() 转换成列表。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.index) # Index(['a', 'b', 'c'], dtype='object')
print(df.index.values) # ['a' 'b' 'c']
print(list(df.index)) # ['a', 'b', 'c']
print(df.index.tolist()) # ['a', 'b', 'c']dataframe.columns
获取列索引,返回的是Index类型,可以通过 list(df.columns) 或 df.columns.tolist() 转换成列表。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.columns) # Index(['foo', 'bar'], dtype='object')
print(df.columns.values) # ['foo' 'bar'],可用 df.columns.values.tolist() 转换成列表
print(list(df.columns)) # ['foo', 'bar']
print(df.columns.tolist()) # ['foo', 'bar']