使用Pytorch手把手搭建一个Transformer网络结构并完成一个小型翻译任务。
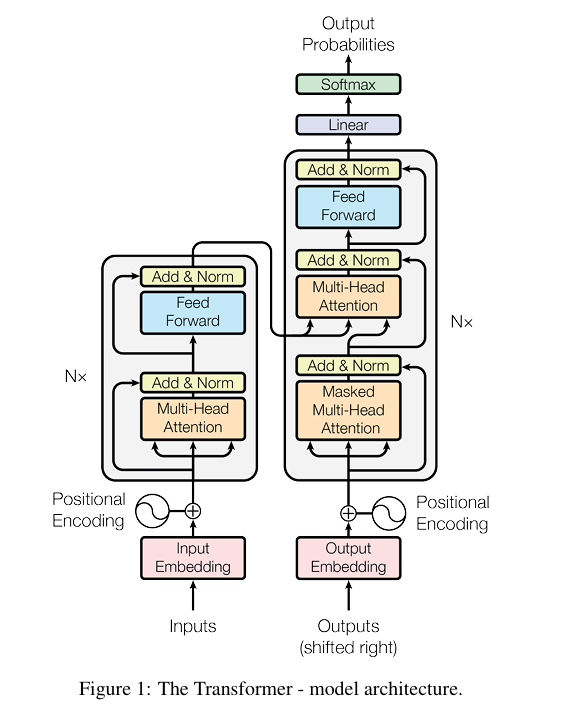
首先,对Transformer结构进行拆解,Transformer由编码器和解码器(Encoder-Decoder)组成,编码器由Multi-Head Attention + Feed-Forward Network组成的结构堆叠而成,解码器由Multi-Head Attention + Multi-Head Attention + Feed-Forward Network组成的结构堆叠而成。
python
class Encoder(nn.Module):
def __init__(self, corpus) -> None:
super().__init__()
self.src_emb = nn.Embedding(len(corpus.src_vocab), d_embedding) # word embedding
self.pos_emb = nn.Embedding.from_pretrained(get_sin_enc_table(corpus.src_len + 1, d_embedding), freeze=True) # position embedding
self.layers = nn.ModuleList([EncoderLayer() for _ in range(encoder_n_layers)])
def forward(self, enc_inputs):
pos_indices = torch.arange(1, enc_inputs.size(1)+1).unsqueeze(0).to(enc_inputs)
enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(pos_indices)
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
enc_self_attn_weights = []
for layer in self.layers:
enc_outputs, enc_self_attn_weight = layer(enc_outputs, enc_self_attn_mask)
enc_self_attn_weights.append(enc_self_attn_weight)
return enc_outputs, enc_self_attn_weights
class Decoder(nn.Module):
def __init__(self, corpus) -> None:
super().__init__()
self.tgt_emb = nn.Embedding(len(corpus.tgt_vocab), d_embedding) # word embedding
self.pos_emb = nn.Embedding.from_pretrained(get_sin_enc_table(corpus.tgt_len + 1, d_embedding), freeze=True) # position embedding
self.layers = nn.ModuleList([DecoderLayer() for _ in range(decoder_n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs):
pos_indices = torch.arange(1, dec_inputs.size(1)+1).unsqueeze(0).to(dec_inputs)
dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(pos_indices)
# 生成填充掩码
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)
# 生成后续掩码
dec_self_attn_subsequent_mask= get_attn_subsequent_mask(dec_inputs)
# 整合掩码
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # 自注意力机制只有填充掩码,且是根据encoder和decoder的输入生成的
dec_self_attn_weights = []
dec_enc_attn_weights = []
for layer in self.layers:
dec_outputs, dec_self_attn_weight, dec_enc_attn_weight = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attn_weights.append(dec_self_attn_weight)
dec_enc_attn_weights.append(dec_enc_attn_weight)
return dec_outputs, dec_self_attn_weights, dec_enc_attn_weights
class Transformer(nn.Module):
def __init__(self, corpus) -> None:
super().__init__()
self.encoder = Encoder(corpus)
self.decoder = Decoder(corpus)
self.projection = nn.Linear(d_embedding, len(corpus.tgt_vocab), bias=False)
def forward(self, enc_inputs, dec_inputs):
enc_outputs, enc_self_attn_weights = self.encoder(enc_inputs)
dec_outputs, dec_self_attn_weights, dec_enc_attn_weights = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs)
return dec_logits, enc_self_attn_weights, dec_self_attn_weights, dec_enc_attn_weights很直接的,我们可以看到,要实现Transformer需要实现两个基本结构:Multi-Head Attention + Feed-Forward Network。
Multi-Head Attention
要实现多头注意力机制,首先要实现注意力机制。
Attention的计算:
- 对输入进行线性变换,得到QKV矩阵
- QK点积、缩放、softmax
- 再对V进行加权求和
Multi-Head Attention就是包含多个Attention头:
- 多个头进行concat
- 连接全连接层,使得Multi-Head Attention得到的输出与输入相同
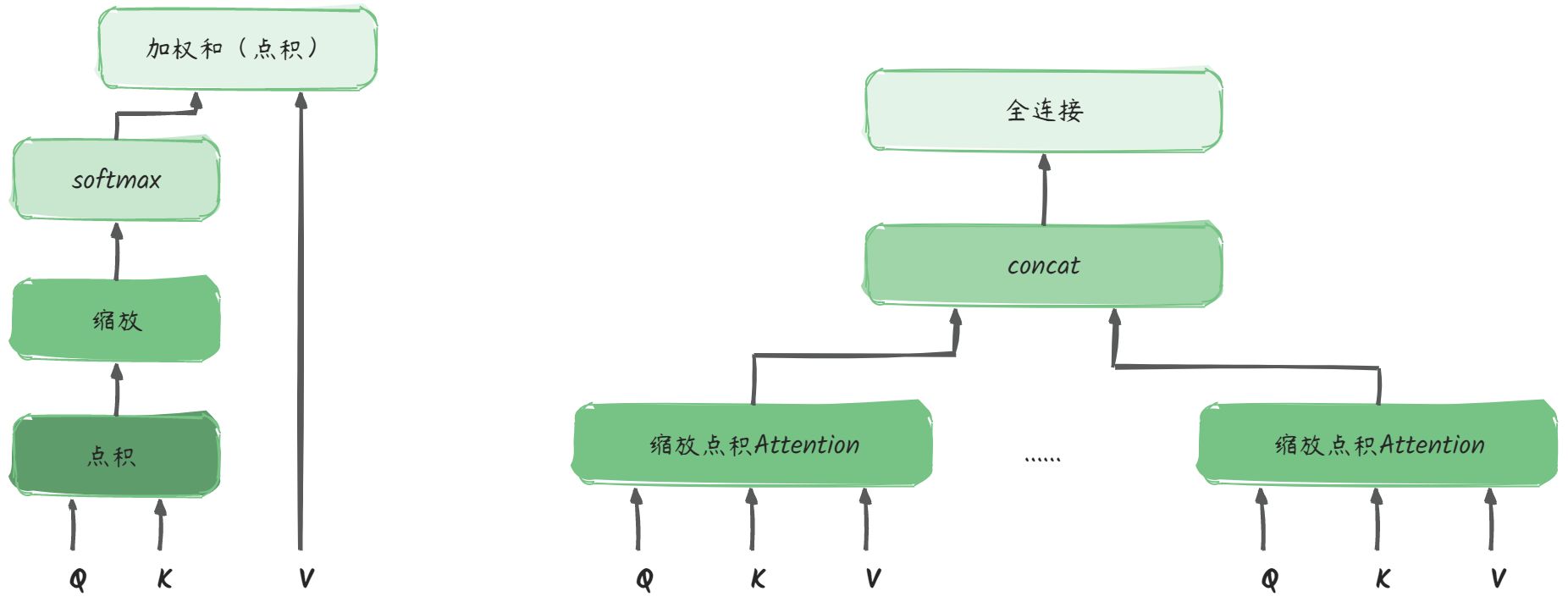
我们来手把手走一下Multi-Head Attention的计算:
假设输入序列的长度为n,针对每个token的编码长度为d,则输入为(n, d)
权重矩阵:$ W_Q: (d, d_q), W_K: (d, d_q), W_V:(d, d_v)
$
- 得到的QKV分别为: Q: (n, d_q), K: (n, d_q), V:(n, d_v)
- Q与K的转置相乘: Q \\cdot K\^T : (n, d_q) \\cdot (d_q, n) = (n, n) ,每一个点的值代表第i个token和第j个token的相似度
- 缩放:不改变矩阵的尺寸,只改变矩阵中的值
- softmax:对矩阵中的值进行归一化
- 对V做加权求和: softmax(\\frac {Q \\cdot K\^T} {\\sqrt{d_k}})\\cdot V = (n, n)\\cdot(n, d_v) = (n, d_v)
- 针对一个 (n, d) \\(的输入,单头得到的输出为\\) (n, d_v) \\(, 多头concat得到的输出就是\\) (n_{heads}, n, d_v)
- transpose并进行fully-connection运算: (n_{heads}, n, d) -\> (n, n_{heads}\*d_v) -\> (n, d)
代码实现如下:
python
class MultiHeadAttention(nn.Module):
def __init__(self) -> None:
super().__init__()
self.W_Q = nn.Linear(d_embedding, d_k * n_heads)
self.W_K = nn.Linear(d_embedding, d_k * n_heads)
self.W_V = nn.Linear(d_embedding, d_v * n_heads)
self.linear = nn.Linear(n_heads * d_v, d_embedding)
self.layer_norm = nn.LayerNorm(d_embedding)
def forward(self, Q, K, V, attn_mask):
'''
Q: [batch, len_q, d_embedding]
K: [batch, len_k, d_embedding]
V: [batch, len_v, d_embedding]
attn_mask: [batch, len_q, len_k]
'''
residual, batch_size = Q, Q.size(0)
# step1: 对输入进行线性变换 + 重塑
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # [batch, n_heads, len_q, d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # [batch, n_heads, len_k, d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1, 2) # [batch, n_heads, len_v, d_v]
# step2: 计算注意力分数, 点积 + 缩放
scores = torch.matmul(q_s, k_s.transpose(-1, -2)) / np.sqrt(d_k) # [batch_size, n_heads, len_q, len_k]
# step3: 使用注意力掩码, 将mask值为1处的权重替换为极小值
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9)
# step4: 对注意力分数进行归一化
weights = nn.Softmax(dim=-1)(scores)
# step5: 计算上下文向量,对V进行加权求和
context = torch.matmul(weights, v_s) # [batch_size, n_heads, len_q, dim_v]
# step6: fc
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # [batch_size, len_q, n_heads * dim_v]
output = self.linear(context) # [batch_size, len_q, d_embedding]
# step7: layernorm
output = self.layer_norm(output + residual)
return output, weightsFeed-Forward Network
在Encoder和Decoder的每个注意力层后面都会接一个Position-Wise Feed-Forward Network,起到进一步提取特征的作用。这个过程在输入序列上的每个位置都是独立完成的,不打乱,不整合,不循环,因此称为Position-Wise Feed-Forward。
计算公式为:
F(x) = max(0, W_1x+b_1)\*W_2+b_2
计算过程如图所示,使用conv1/fc先将输入序列映射到更高维度(d_ff是一个可调节的超参数,一般是4倍的d),然后再将映射后的序列降维到原始维度。
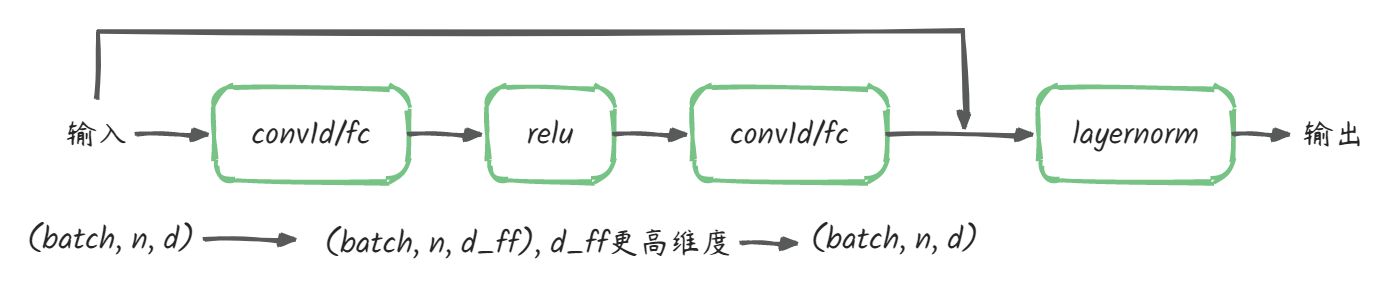
使用conv1d的实现如下
nn.Conv1d(in_channels, out_channels, kernel_size, ...)
(batch, n, d)-\> (batch, d, n) -\> (batch, d_ff, n) -\> (batch, d, n) -\> (batch, n, d)
第一个conv1d的参数为:
nn.Conv1d(d, d_ff, 1, ...)
第二个conv1d的参数为:
nn.Conv1d(d_ff, d, 1, ...)
python
class PoswiseFeedForwardNet(nn.Module):
def __init__(self, d_ff=2048) -> None:
super().__init__()
# 定义一个一维卷积层,将输入映射到更高维度
self.conv1 = nn.Conv1d(in_channels=d_embedding, out_channels=d_ff, kernel_size=1)
# 定义一个一维卷积层,将输入映射回原始维度
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_embedding, kernel_size=1)
self.layer_norm = nn.LayerNorm(d_embedding)
def forward(self, inputs):
'''
inputs: [batch_size, len_q, embedding_dim]
output: [batch_size, len_q, embedding_dim]
'''
residual = inputs
output = self.conv1(inputs.transpose(1, 2))
output = nn.ReLU()(output)
output = self.conv2(output)
output = self.layer_norm(output.transpose(1, 2) + residual)
return output使用fc的实现如下
nn.Linear(in_features, out_features, bias=True)
(batch, n, d)-\> (batch, n, d_ff) -\> (batch, n, d)
第一个fc的参数为:
nn.Linear(d, d_ff, bias=True)
第一个fc的参数为:
nn.Linear(d_ff, d, bias=True)
python
class PoswiseFeedForwardNet_fc(nn.Module):
def __init__(self, d_ff=2048) -> None:
super().__init__()
# 定义一个一维卷积层,将输入映射到更高维度
self.fc1 = nn.Linear(d_embedding, d_ff, bias=True)
self.fc2 = nn.Linear(d_ff, d_embedding, bias=True)
# self.conv1 = nn.Conv1d(in_channels=d_embedding, out_channels=d_ff, kernel_size=1)
# 定义一个一维卷积层,将输入映射回原始维度
# self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_embedding, kernel_size=1)
self.layer_norm = nn.LayerNorm(d_embedding)
def forward(self, inputs):
'''
inputs: [batch_size, len_q, embedding_dim]
output: [batch_size, len_q, embedding_dim]
'''
residual = inputs
output = self.fc1(inputs)
output = nn.ReLU()(output)
output = self.fc2(output)
output = self.layer_norm(output + residual)
return output参考链接: