定时任务能干啥???
它能做的自动化操作实在太多了。先给大家列几个常见的,比如:
-
社交媒体动态监控:定时跟踪特定用户的动态,监控热门话题和趋势
-
数据采集与分析:定时爬取网站的文章、评论信息等
-
自动化营销:定时在社交媒体自动发帖
-
个人自动化:定时提醒和任务管理
过去要实现这些定时的自动化任务,操作起来还是挺麻烦的。通常需要掌握一门编程语言*(如 Python)*、配置服务器或云平台,甚至编写复杂的脚本来处理各种情况。这对于非技术人员或时间有限的开发者来说,往往直接劝退。
但是现在,通过 Apifox 的「定时任务」功能,这些自动化场景基本上都能轻松搞定。
在 Apifox 中,要实现爬虫、监控等自动化定时任务,大致可以分为以下几个步骤:
-
获取 API
-
分析返回数据
-
编排测试场景
-
设置定时任务
我们下面就根据这几个步骤来讲解一下,怎么在 Apifox 中操作。相信不管你的需求是什么,下面的内容都能给你一些灵感~

获取 API
想要监控某些平台的社交媒体动态,或者说要爬取某些平台的数据,首先第一步就是要获取到实现这个操作项的 API,那问题来了,这些 API 从哪儿找呢?
可以到官方的「开放平台」找找有没有相关的开放接口,这是最正规的途径,一般能够在前端展示的页面都会提供。
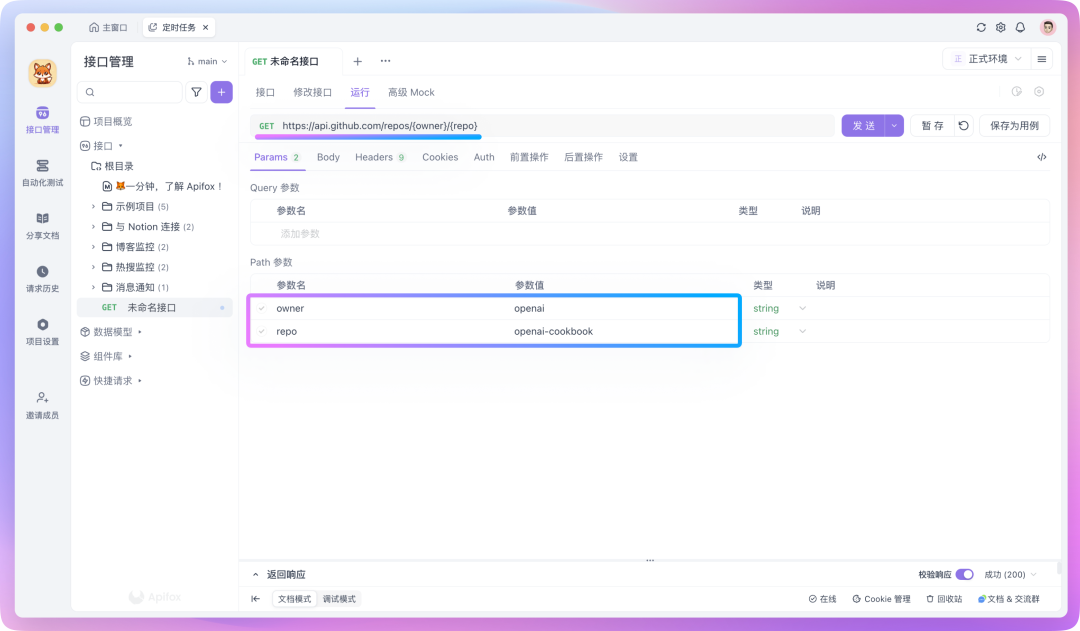
举个例子,假设我们要监控 GitHub 上某个项目的 star 数量变化,我们这时候就可以到 Github 的开放平台看看有没有相关的 API 提供,有的话直接复制下来就行了,如图所示:
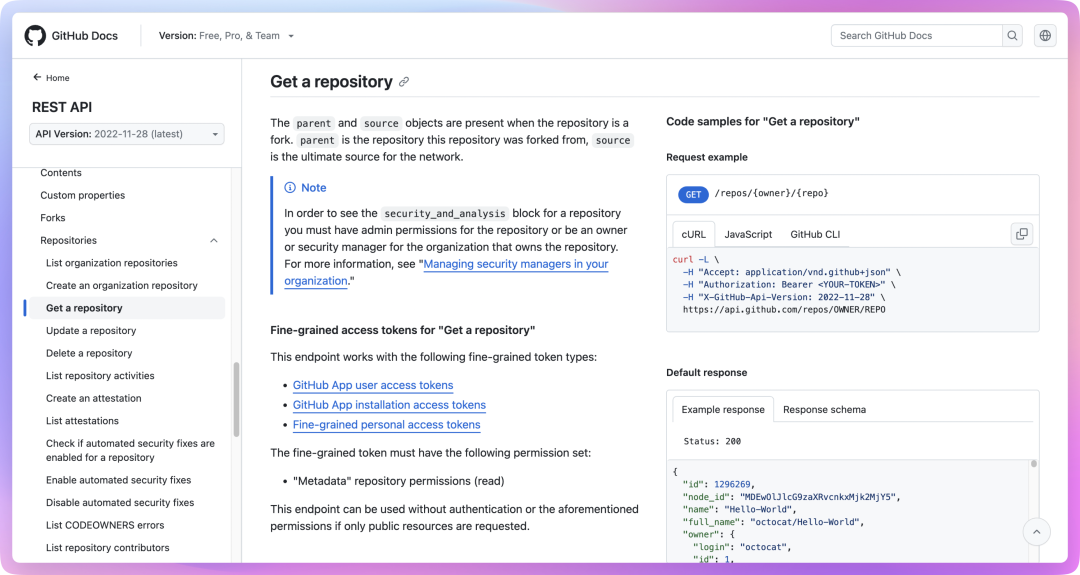
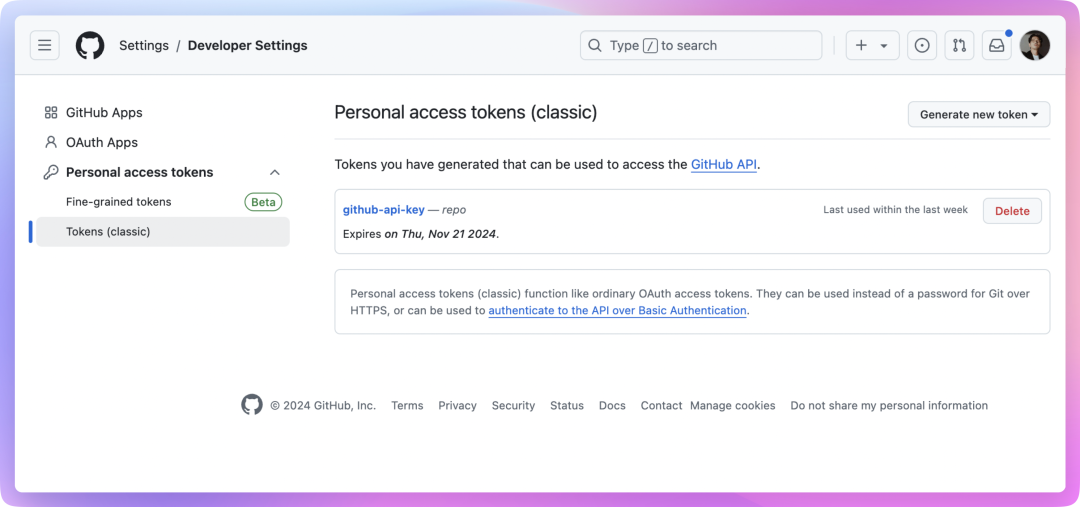
请求开放 API 时会要求携带 Token,一般可以在开发者后台生成。
除了到官方平台去查找 API,还可以选择在浏览器抓包,或者在 Github 上找一些开源项目,具体的操作方法可以到本文结尾的扩展小节查看。
分析返回数据
现在我们知道了怎么获取相关的 API,下一步就是分析返回的数据,看看里面有啥有用的信息。一般来说,这些 API 返回的都是 JSON 格式的数据,我们需要仔细查看每个字段代表什么意思。
比如说,访问下面的这个开放 API 可以获取 Github 上特定开源项目的仓库信息。
curl -L \ -H "Accept: application/vnd.github+json" \ -H "Authorization: Bearer <YOUR-TOKEN>" \ -H "X-GitHub-Api-Version: 2022-11-28" \ https://api.github.com/repos/{owner}/{repo}其中 {owner} 是仓库所有者的用户名或组织名,{repo} 是仓库的名称。要找到这些信息,只需要看一下 GitHub 仓库的网址就可以了:
-
打开你想要查看的 GitHub 项目页面。
-
看一下浏览器地址栏中的 URL,它的格式是这样的:https://github.com/{owner}/{repo}
-
URL 中第一个斜杠后的部分就是 {owner},第二个斜杠后的部分就是 {repo}。
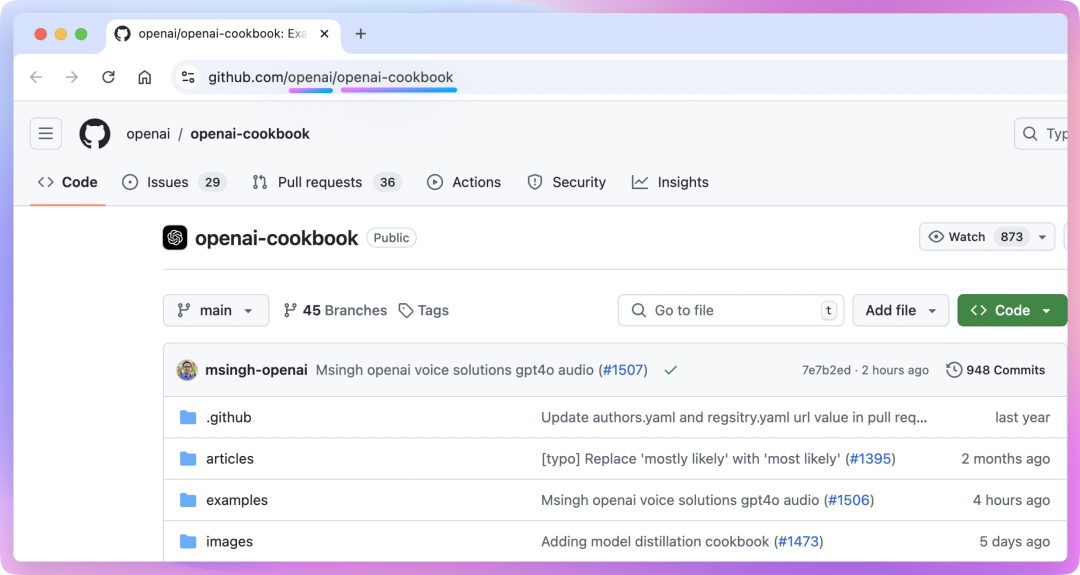
在 Apifox 中,可以直接复制上述的 cURL 命令内容来创建一个新的 API 请求,也可以手动设置请求方法和 URL,同时在请求头中添加 Token。
发送请求后,你会得到类似这样的 JSON 响应:
{ "id": 468576060, "name": "openai-cookbook", "full_name": "openai/openai-cookbook", "stargazers_count": 59366, ...}获取到原始的 JSON 数据后,下一步是进行数据处理。在 Apifox 中,我们可以使用 JSONPath 表达式或者写点简单的脚本来实现这一点。
例如,要使用 JSONPath 提取特定字段,可以在「后置操作」中添加一个「提取变量」的操作,并填写相应的表达式。如果不熟悉如何编写表达式,可以点击 「JSONPath 表达式」输入框内的图标,使用 JSONPath 提取工具作为辅助。
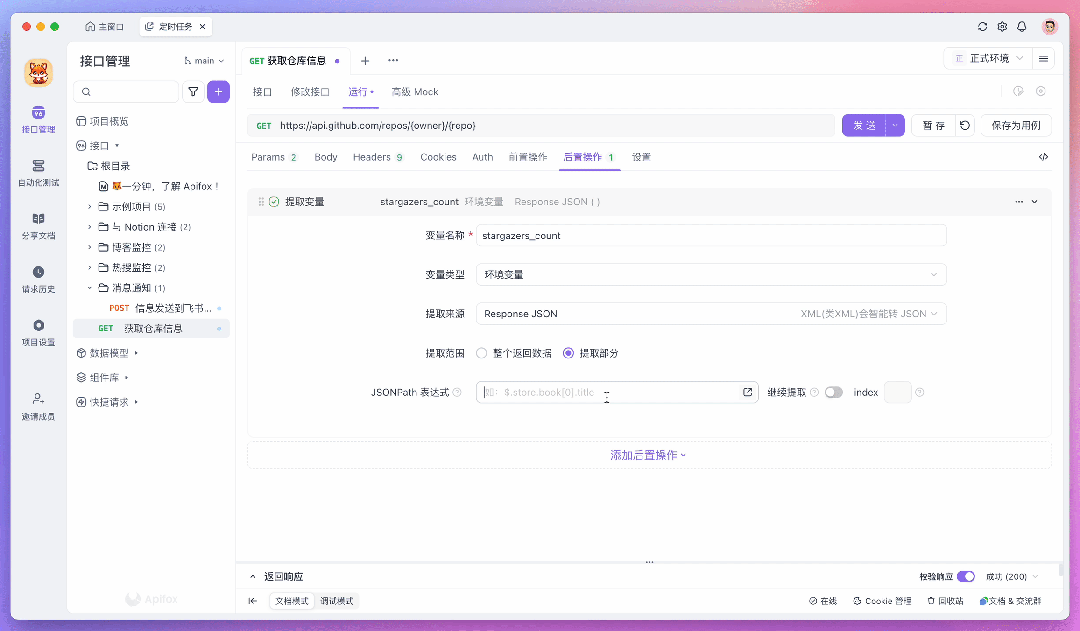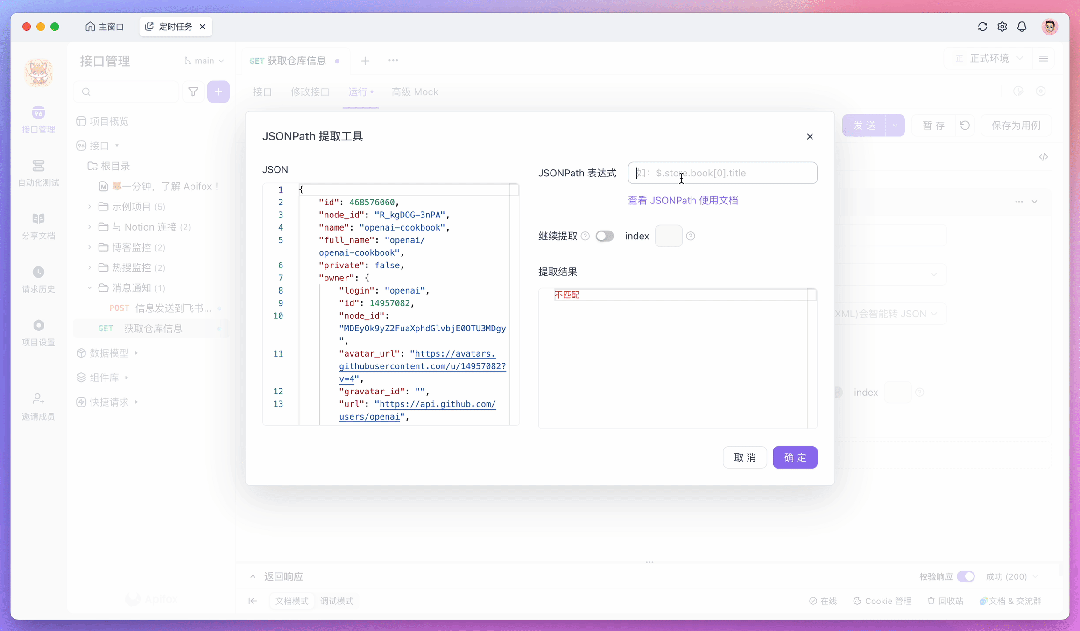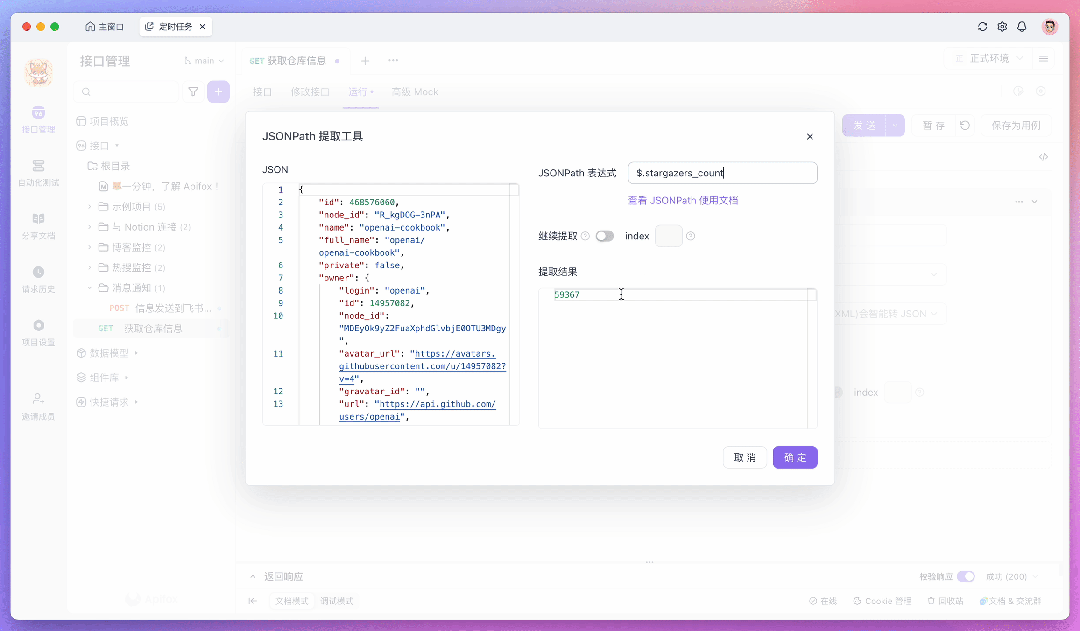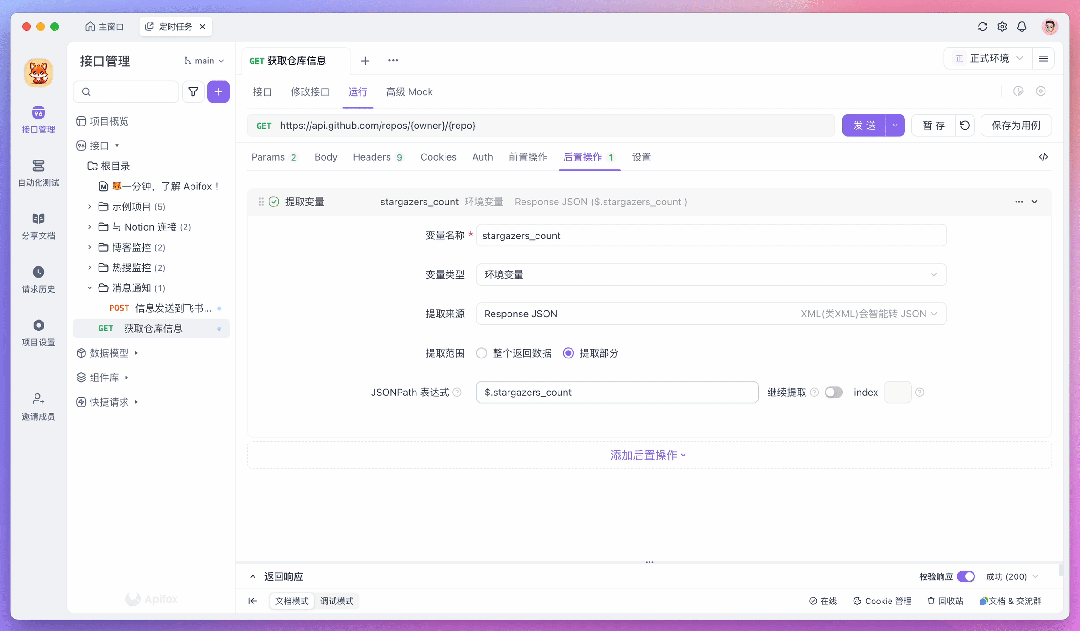
提取出来的数据会暂存在环境变量里,可以在后续步骤中将数据发送到服务器或存储到数据库。
除了常见的 JSON 格式外,还有一种是直接返回整个 HTML 文档,这在服务端渲染的场景中很常见。对此,我们需要使用脚本进行处理。
在 Apifox 中,你可以在「后置操作」中新建一个「自定义脚本」,并使用 fox.liveRequire 方法来引用 htmlparser2 库来处理 HTML 格式的数据。
例如,倘若想要将一个 HTML 里的 <article> 标签及其内部所有内容都提取出来,并转换为文本格式,可以这样编写脚本:
fox.liveRequire("htmlparser2", (htmlparser2) => { console.log(htmlparser2)
// HTML 字符串(一般从接口的返回数据中读取) const htmlString = ` <html> <body> <article> <h1>Title</h1> <p>This is a paragraph.</p> <p>Another piece of text.</p> </article> <footer>Footer content</footer> </body> </html> `;
// 解析文档 const document = htmlparser2.parseDocument(htmlString);
// 使用 DomUtils 查找 <article> 标签 const article = htmlparser2.DomUtils.findOne(elem => elem.name === "article", document.children);
// 将 <article> 中的内容转换为完整的 HTML 片段 if (article) { const articleHTML = htmlparser2.DomUtils.getOuterHTML(article); console.log(articleHTML); } else { console.log("No <article> tag found."); }})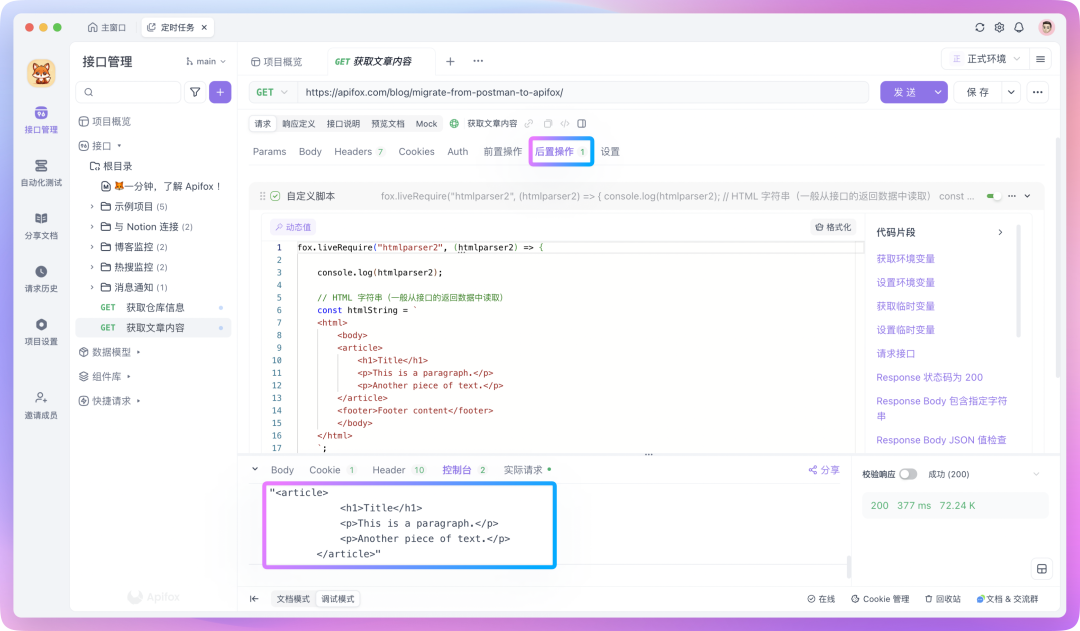
通过脚本来处理 HTML 格式的内容就不过多探讨了,你可以简单的理解为这是一个「DOM 操作」,具体的可以问一下 AI。
编排测试场景
有了 API,分析好了数据,接下来就是在自动化测试中编排测试场景了。
在 Apifox 里,你可以在自动化测试中创建一个测试场景,并将准备好的 API 请求导入其中。
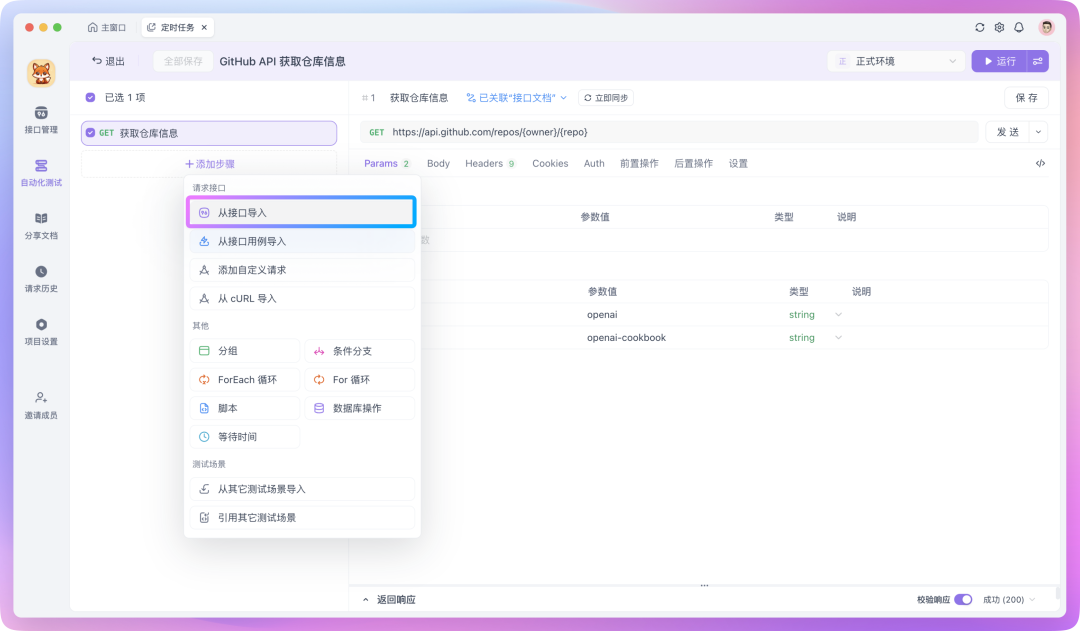
如果你需要将处理好的数据插入到数据库,可以在「后置操作」中新建一个「数据库操作」,将处理好的数据通过 SQL 命令插入到数据库中,SQL 命令里支持读取环境变量中的值,例如:
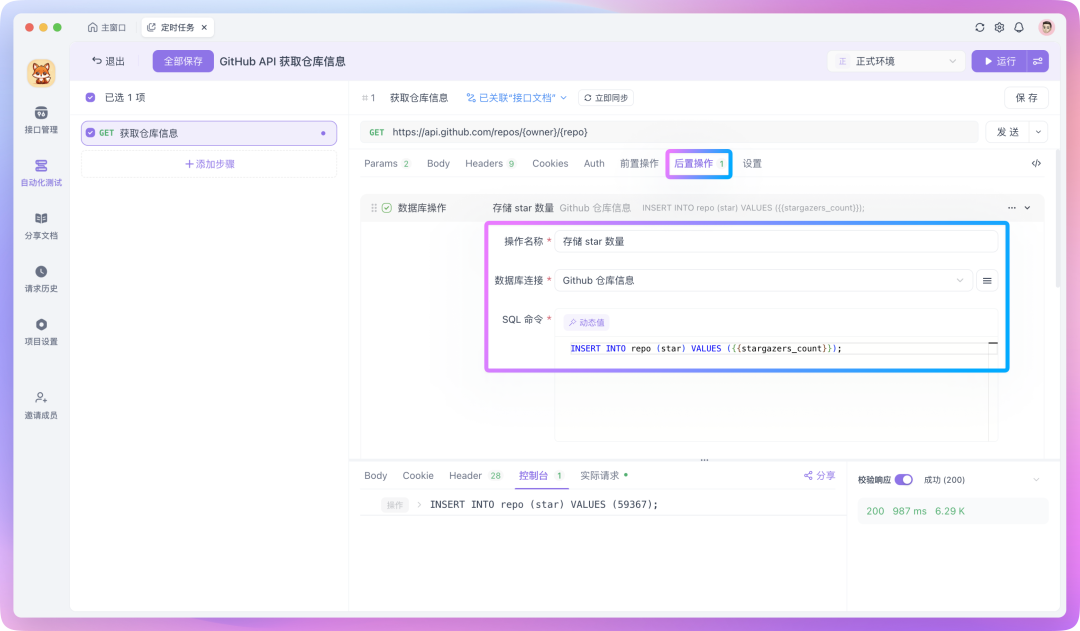
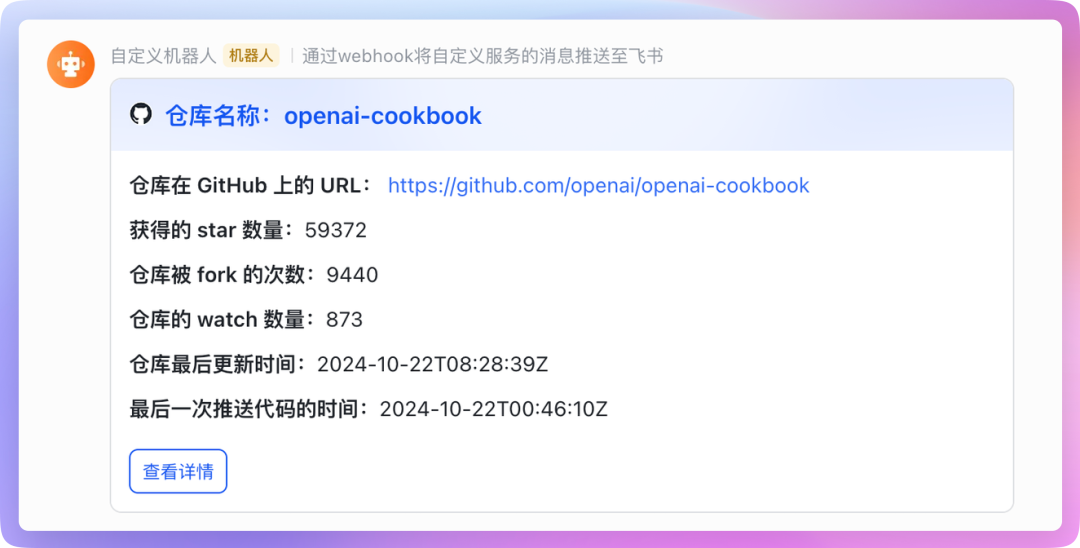
此外,你还可以将处理好的数据通过 API 存储起来,也就是自己编写一个 API 将数据保存至服务器,或者通过 Webhook 将数据发送到一些第三方平台。
比如这里我要将处理好的数据发送到飞书,这时就可以在测试场景中新添加一个测试步骤,并使用飞书提供的 Webhook API 来发送消息。在此过程中,你可以通过「动态值」来读取前置步骤的运行结果,这样处理数据会更加的方便。
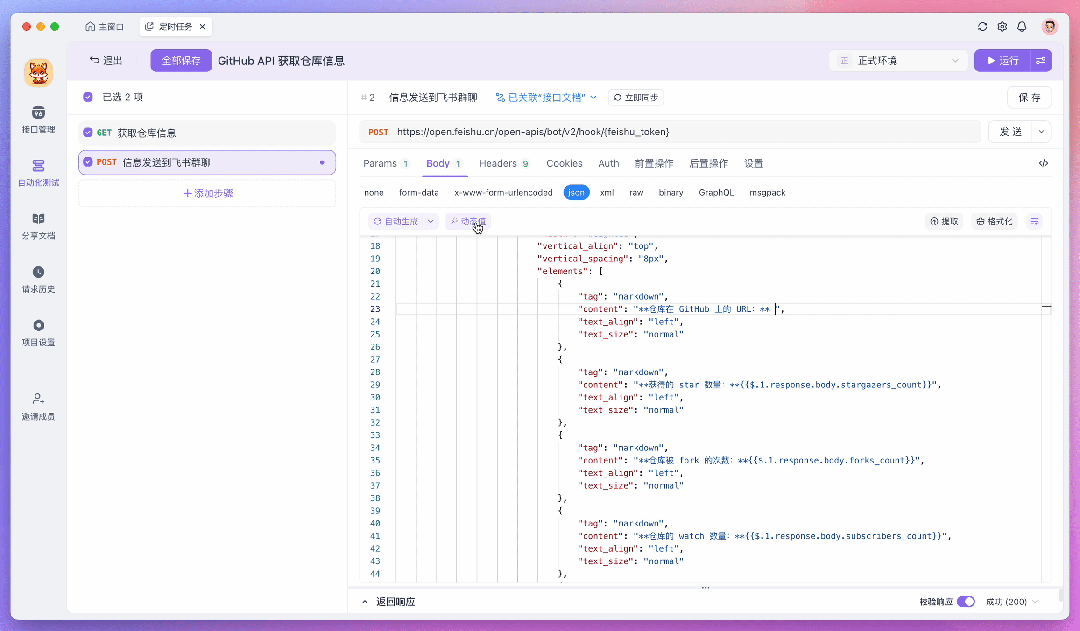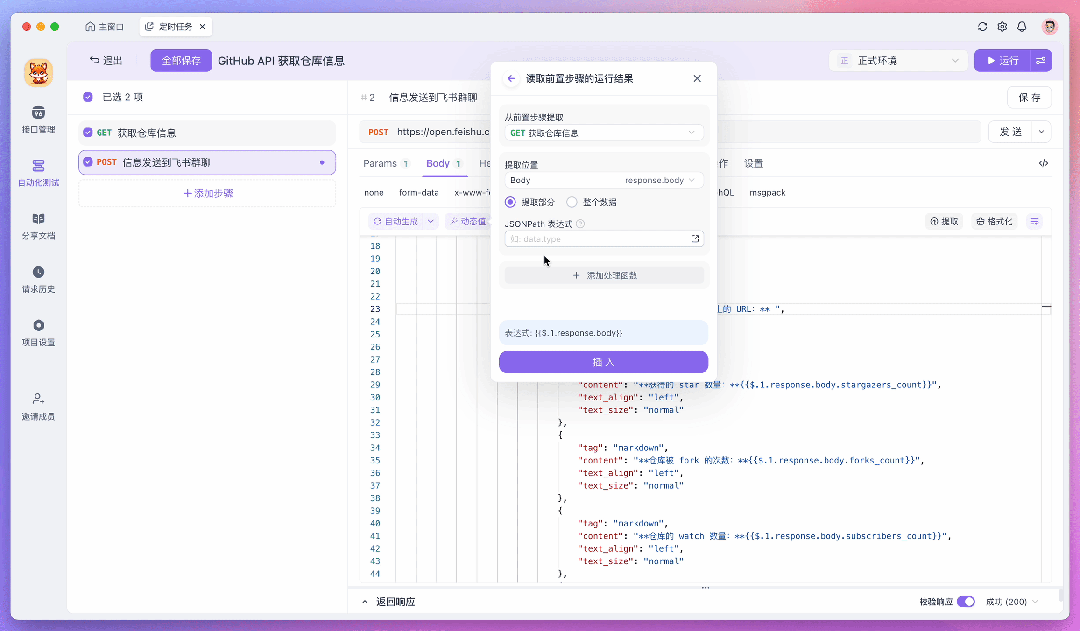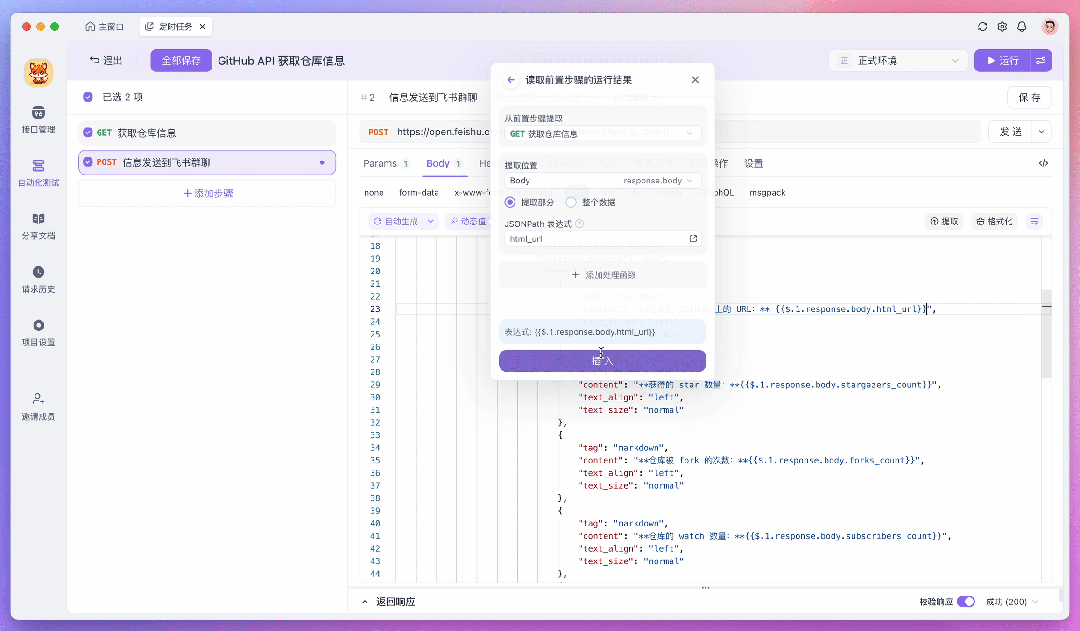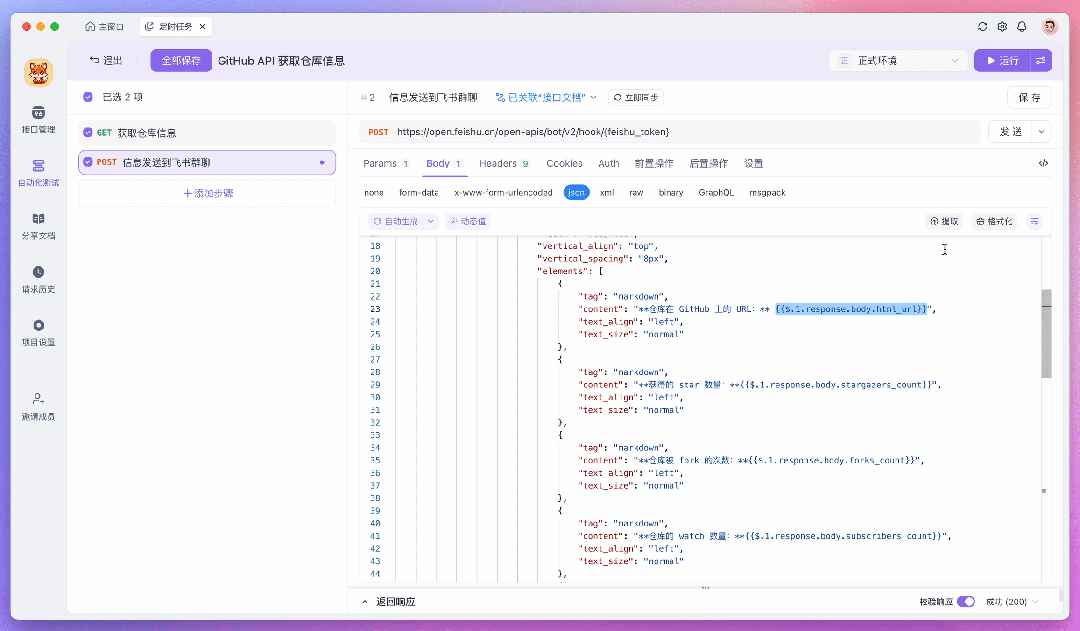
如果你需要对一组数据进行遍历,或者让返回的字段满足某些特定条件才继续往下执行,你也可以给测试步骤添加「流程控制条件」。
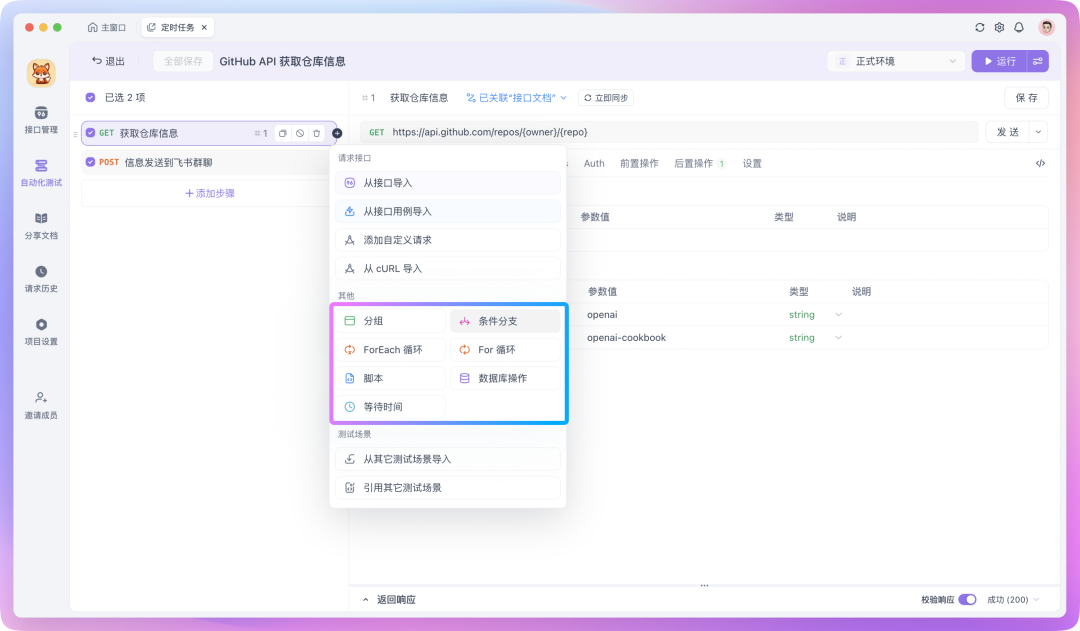
测试场景编排完成后,可运行测试以查看效果。检查整个测试场景是否存在错误,并确认数据是否成功回传。如果编排的测试场景没问题的话,就可以进入下一步------设置定时任务!
设置定时任务
在 Apifox 里,设置定时任务超级简单。但是,使用定时任务的前提是你已在服务器中部署了 Runner,具体可以参考这篇文章《Apifox 「定时任务」操作指南,解锁自动化测试的新利器》,该指南详细介绍了 Runner 的安装和配置过程。
假设你已经把 Runner 给部署好了,接下来就可以为之前编排的测试场景添加定时任务,使其定时执行,以实现自动化监控。
在 Apifox 的自动化测试中,找到「定时任务」模块,然后新建一个定时任务。在配置界面,你将看到以下选项:
-
任务名称:为任务起一个描述性的名字,例如"每日 GitHub Star 数监控";
-
测试场景:选择需定期运行的测试场景,如定时监控或爬虫测试场景;
-
设置运行周期:例如,每天下午 6:00 运行一次;
-
执行环境:选择已部署的 Runner 服务;
-
通知设置:指定任务完成后的通知方式,可以是邮件、钉钉等。
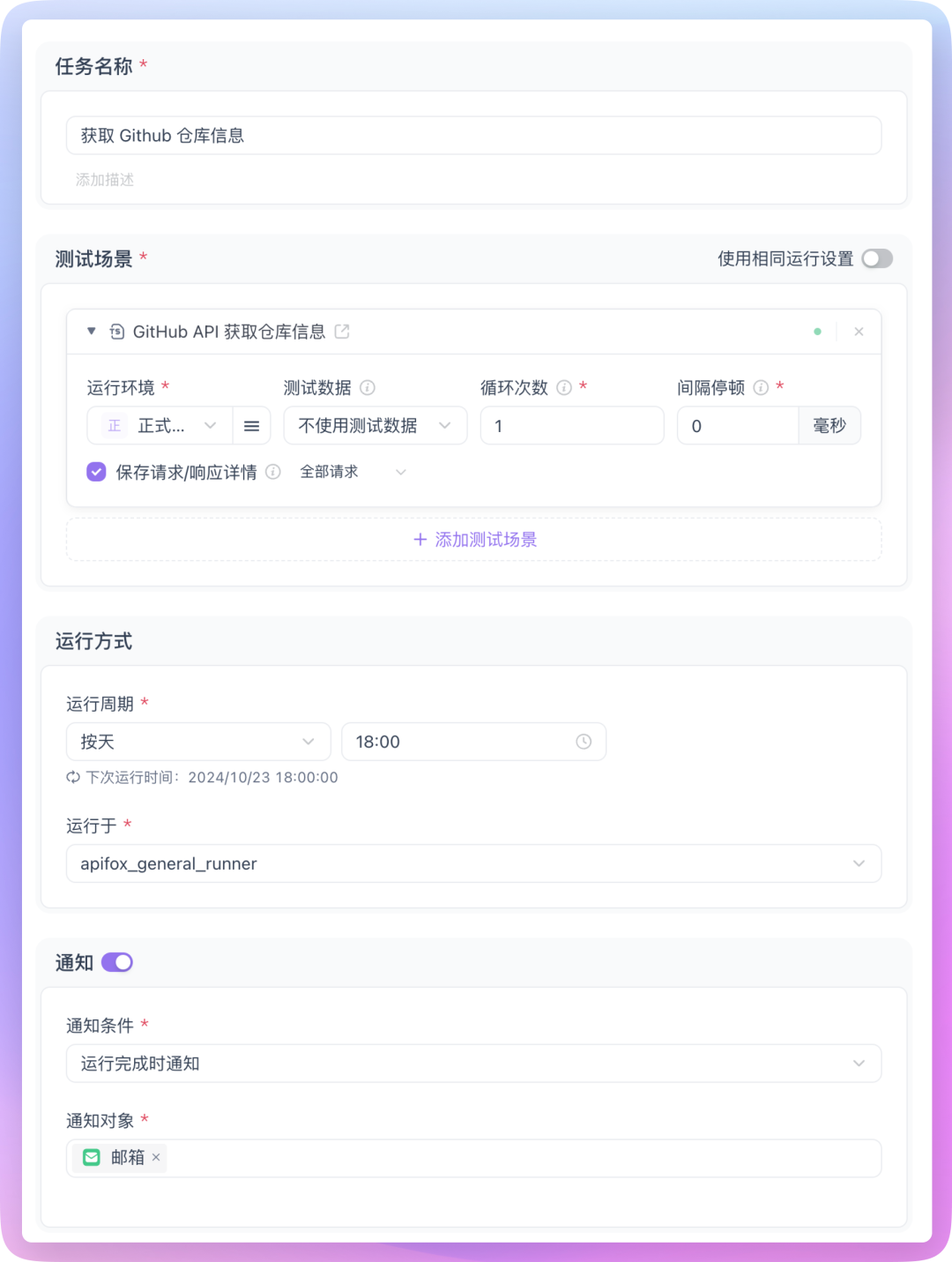
设置并保存后,这个定时任务下的测试场景就会按照设置的运行周期定时运行了,我们实现自动化定时监控的目的也已经达到。
其他扩展
在上文「获取 API」这一小节,除了可以到官方开放平台查找 API,还可以直接在浏览器抓包。
举个例子。
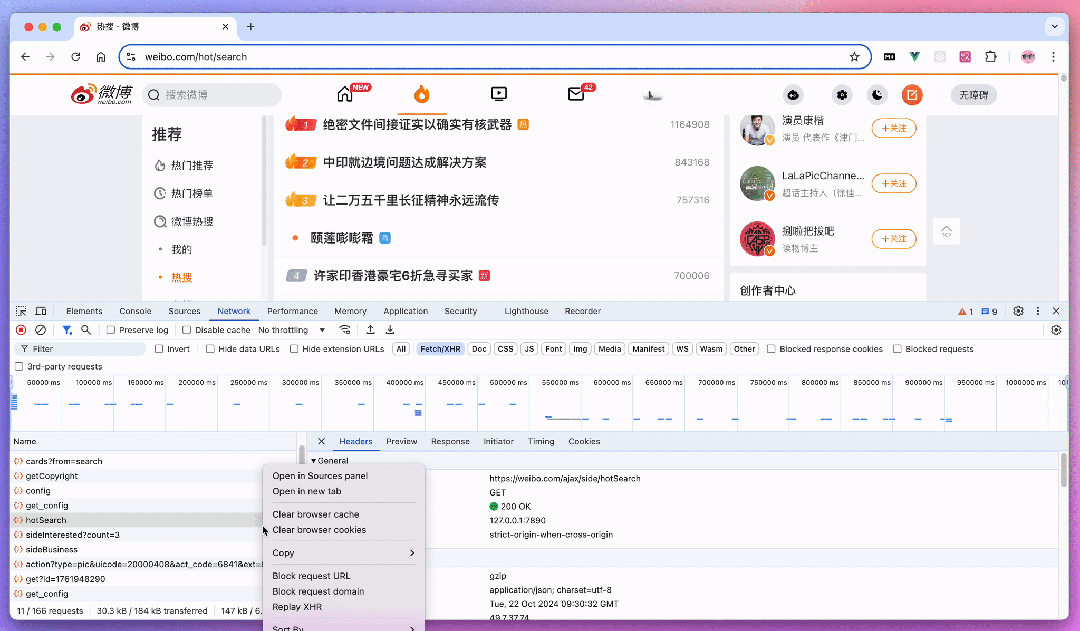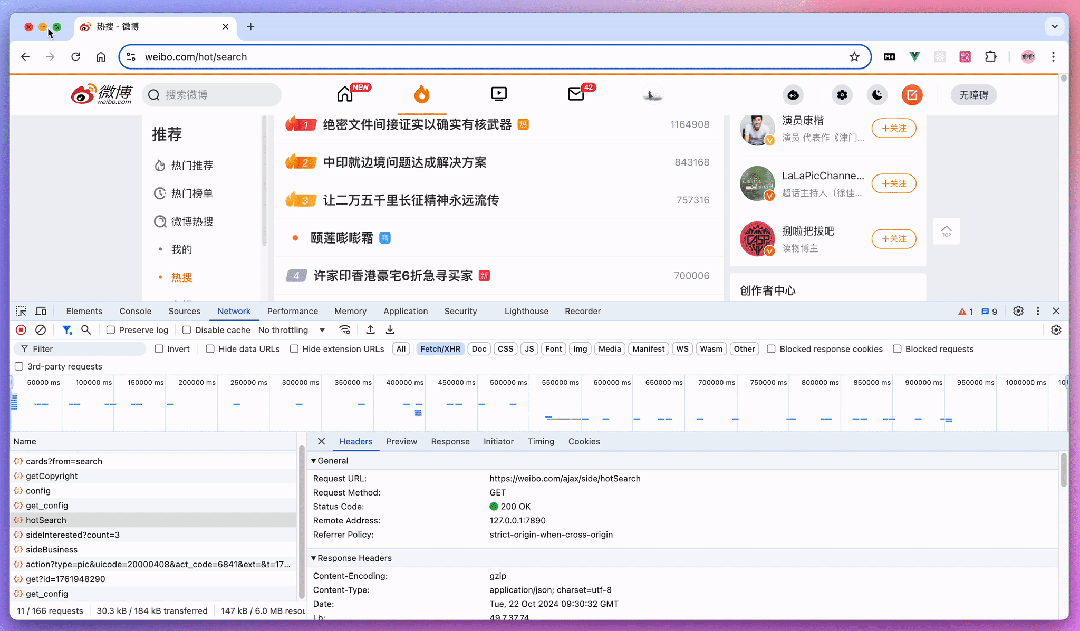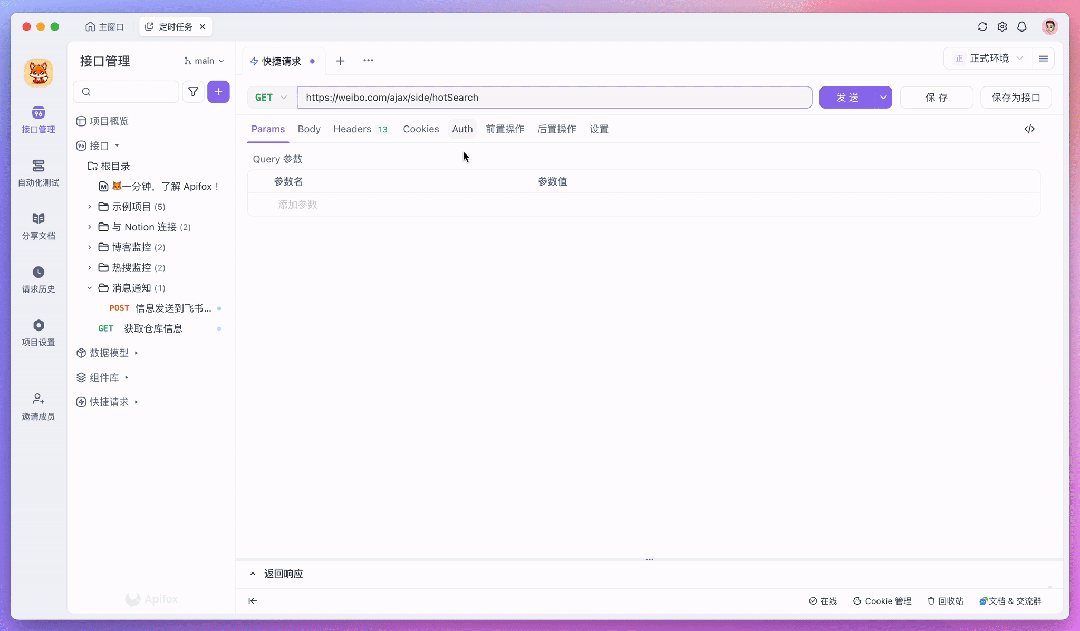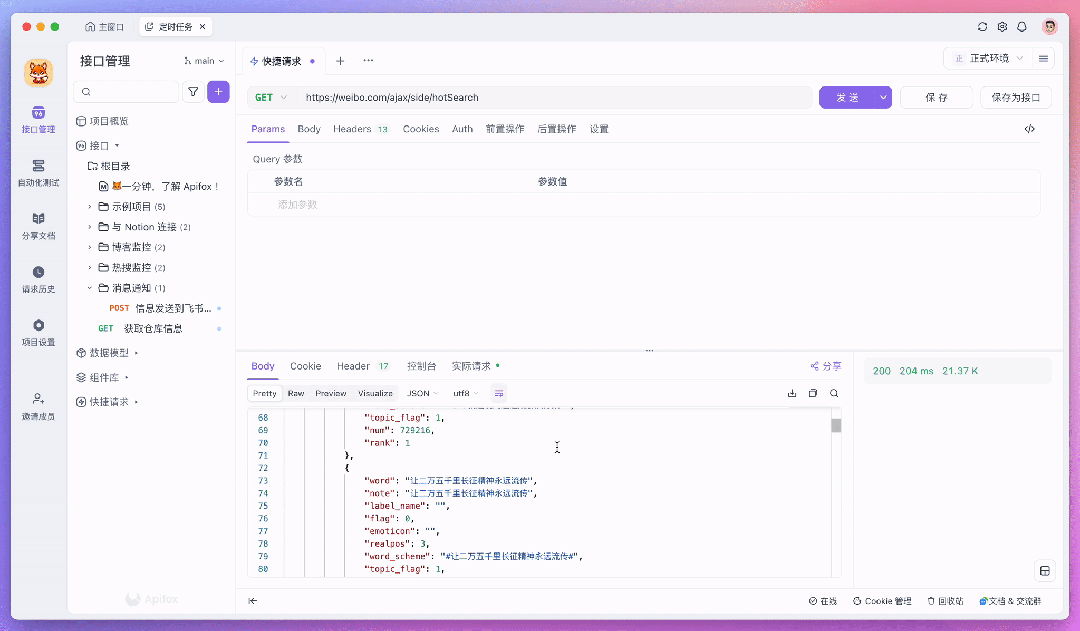
假设我们要监控微博热搜,我们可以在浏览器里打开微博热搜页面,然后按 F12 或 ctrl + shift + i 打开开发者工具,切换到 Network 标签。刷新页面,你就能看到一堆请求。找到获取热搜数据的那个请求,右键复制为 cURL。然后呢,打开 Apifox,新建一个接口,把刚才复制的 cURL 粘贴到输入框。Apifox 自动就帮我们解析好了,超级方便!
除了抓包外,一些第三方开发者可能已经逆向工程了某些服务的 API,你可以在 Github 上搜搜,有需要的话直接拿来用就行。
以上就是本文的内容,希望能给你一些启发,以用 Apifox 的定时任务功能实现一些有趣的自动化操作。
更多详细的功能介绍请参考帮助文档的 API 版本模块进行查看,如果有任何问题或建议,欢迎在评论区留言讨论。
