Google Gemini 是 Google AI 创建的大型语言模型 (LLM) 系列,可提供最先进的 AI 功能。Gemini 模型包括:
- Gemini Ultra --- 最大、最强大的模型,擅长处理编码、逻辑推理和创意协作等复杂任务。可通过 Gemini Advanced(原名 Bard)获得。
- Gemini Pro --- 针对各种任务优化的中型模型,提供与 Ultra 相当的性能。可通过 Gemini Chatbot 以及 Google Workspace 和 Google Cloud 获得。Gemini Pro 1.5 的性能有所提升,包括在长上下文理解方面取得突破,可理解多达一百万个词元,包括文本、代码、图像、音频和视频。
- Gemini Nano --- 专为设备端使用而设计的轻量级模型,为手机和小型设备带来 AI 功能。适用于 Pixel 8 和三星 S24 系列。
- Gemma --- 受 Gemini 启发的开源模型,在较小的尺寸下提供最先进的性能,设计时考虑到了负责任的 AI 原则。
在这篇博客中,我将解释如何使用 Gemini API 抓取任何网站的网站信息并提取必要的信息。
NSDT工具推荐 : Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
例如,让我们从以下网站抓取所有征求建议书和联合征求建议书:1, 2。
别忘了先获取 Gemini API。
登录Google AI Studio,向下滚动到"获取 Gemini API 密钥"并单击"立即开始"。
点击"继续":
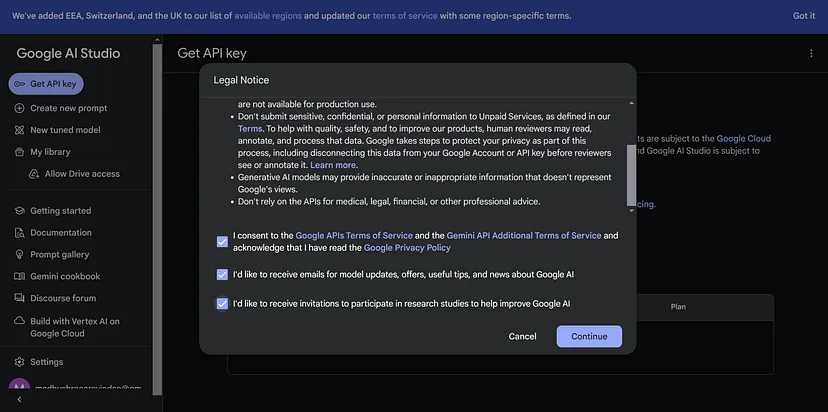
点击"创建API Key":
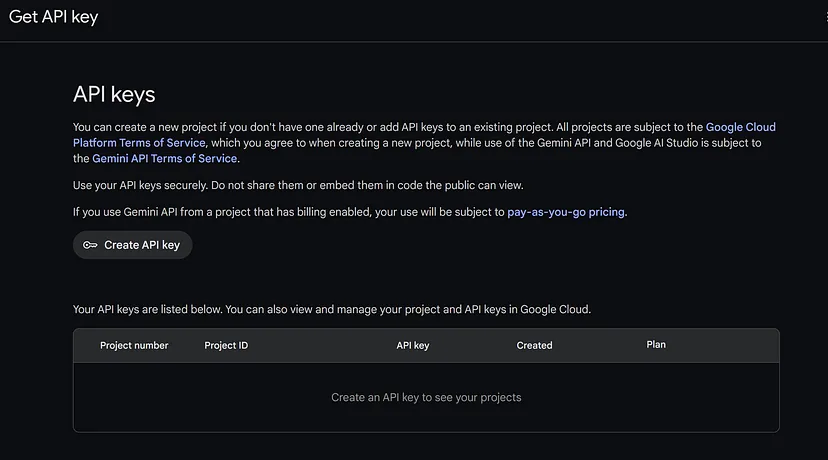
点击"在新项目中创建 API 密钥"
现在你的 Gemini API 密钥已创建!!

现在,一切就绪。让我们开始编码吧!!
我使用的是 Pycharm IDE。确保安装 google.generativeai、streamlit、requests 和 BeautifulSoup 库。
导入上述库:
import streamlit as st
import requests
from bs4 import BeautifulSoup
import os
import google.generativeai as genai初始化Google API密钥并导入Gemini-pro模型:
st.title("Proposal Calls") # Title for the page
os.environ['GOOGLE_API_KEY'] = "********************************"
genai.configure(api_key = os.environ['GOOGLE_API_KEY'])
model = genai.GenerativeModel('gemini-pro')创建一个函数 read_input() 来从网站提取原始数据。然后将其输入到模型中作为构建数据的提示:
def read_input():
# dictionary of all the links to be webscraped.
# You can add more if you want to
links = {
"1":["DST","https://dst.gov.in/call-for-proposals"],
"2":["BIRAC","https://birac.nic.in/cfp.php"]
}
for i in range(1,3):
url = links[str(i)][1] # Get URL of each organization
r = requests.get(url) # Request for data
soup = BeautifulSoup(r.text, 'html.parser') # Parse the HTML elements
data = soup.text # Get raw data in string format
link = soup.find_all('a', href=True) # Get list of all links on the site in html formet
l = ""
for a in link:
l = l +"\n"+ a['href'][1:] # Get the actual links
# Create a query
query = data + "name of organization is"+links[str(i)][0]+ "Jumbled links of calls for proposals:"+l+"\n Create a table with the following columns: Call for proposals or joint call for proposals along with respective link, opening date, closing date and the name of the organization."
llm_function(query)给予 Gemini 的非结构化数据一瞥:
创建另一个函数 llm_function() 来生成响应:
def llm_function(query):
response = model.generate_content(query) # Generate response
st.markdown(response.text) # Print it out using streamlit调用主函数:
if __name__ == __main__:
read_input()让我们在终端上运行以下命令来运行该站点:
streamlit run app.py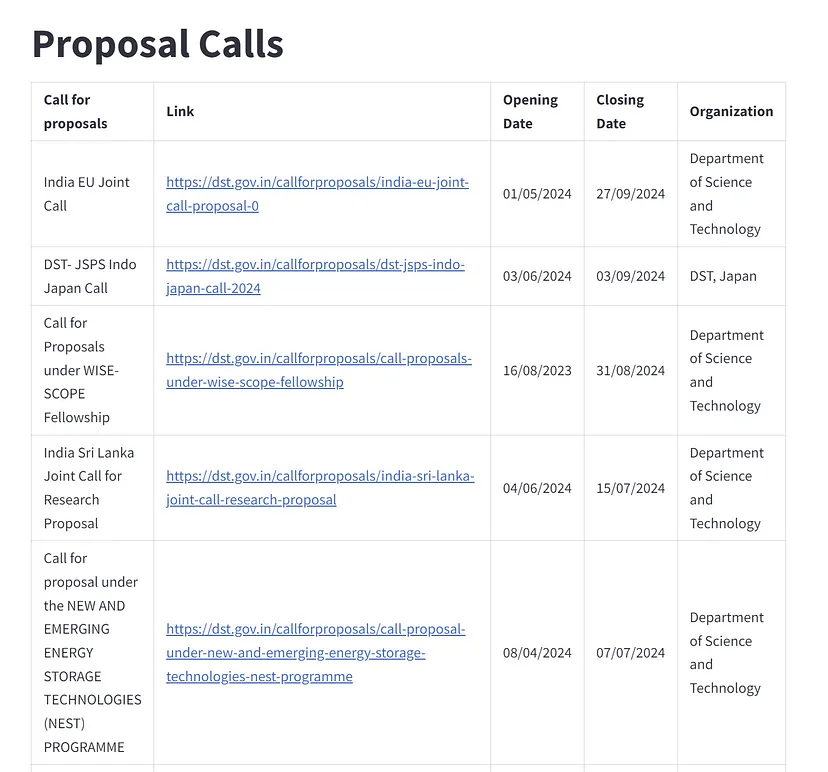
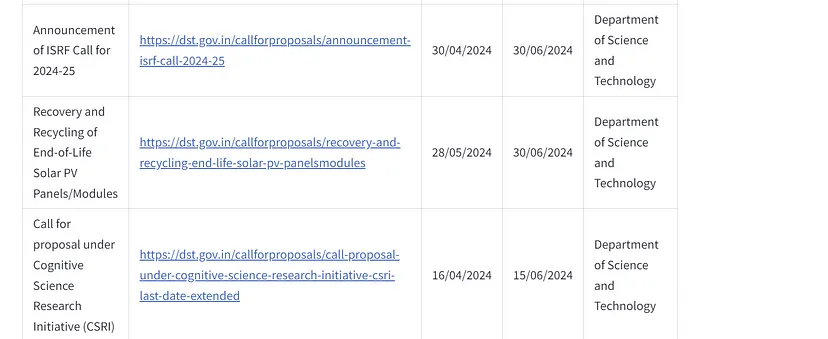

现在,我们可以看到非结构化数据是如何转换为干净的结构化数据的。这只是一个开始,AI模型很快就能帮助我们以 100% 的准确率从互联网上抓取数据。
上面的网站只是如何利用 Gemini 模型进行网页抓取的基本演示。为了使其有用,我们可以在网站上添加一个选项来获取要抓取的网站的链接和来自用户的提示,然后该模型提供结构化数据作为输出。