下载地址
https://download.csdn.net/download/woshichenpi/89922797
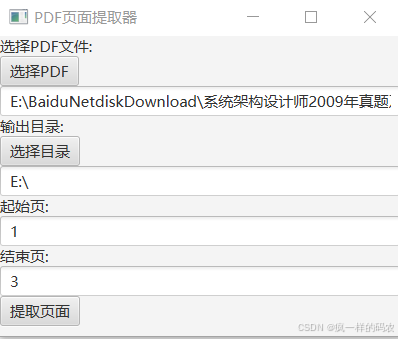
使用说明:PDF页面提取工具
1. 启动应用程序
- 双击程序的启动图标或者通过命令行运行程序。
2. 选择PDF文件
- 在应用程序窗口中找到"选择PDF"按钮并点击它。
- 在弹出的文件选择对话框中,浏览并选择您想要提取页面的PDF文件。
- 选中文件后,点击"打开",所选文件的路径将显示在文本框中。
3. 选择输出目录
- 点击"选择目录"按钮。
- 在弹出的目录选择对话框中,浏览并选择您想要保存提取页面的目录。
- 选中目录后,点击"确定",所选目录的路径将显示在文本框中。
4. 输入页面范围
- 在"起始页"文本框中输入您想要提取的页面的起始页码。
- 在"结束页"文本框中输入您想要提取的页面的结束页码。
5. 提取页面
- 确认所有信息无误后,点击"提取页面"按钮。
- 如果输入的信息有效并且没有发生错误,程序将在您指定的输出目录下生成一个新的PDF文件,其中包含从原PDF文件中提取的指定页面范围。
注意事项
- 页面号格式:请输入有效的整数作为起始页和结束页。例如,如果您想提取第1页到第5页,请分别在"起始页"和"结束页"文本框中输入"1"和"5"。
- 错误提示 :
- 如果页面号格式不正确,程序会弹出提示框显示"页面号格式不正确"。
- 如果在提取过程中遇到任何问题(例如文件不存在、页数超出范围等),程序会弹出提示框显示"页面提取失败"。
- 成功提示:如果页面提取成功,程序会弹出提示框显示"页面提取成功"。
示例
假设您有以下需求:
- 您有一个名为
example.pdf的文件,位于C:\Documents\example.pdf。 - 您希望提取第2页到第4页,并将它们保存在一个名为
C:\Documents\Extracted_Pages的目录中。
按照以下步骤操作:
- 选择PDF文件 :点击"选择PDF",选择
C:\Documents\example.pdf。 - 选择输出目录 :点击"选择目录",选择
C:\Documents\Extracted_Pages。 - 输入页面范围 :在"起始页"输入框中输入
2,在"结束页"输入框中输入4。 - 提取页面:点击"提取页面"。
如果一切正常,您将在 C:\Documents\Extracted_Pages 目录下找到一个名为 提取页面-[时间戳].pdf 的新文件,其中包含第2页到第4页的内容。
这份使用说明应该能帮助用户顺利地使用此PDF页面提取工具。如果有任何问题或需要进一步的帮助,请随时联系支持。