文章目录
一、List数据类型
- 1.1 简介
- 1.2 应用场景
- 1.3 底层结构
二、数据结构
- 2.1 压缩列表ZipList
- 2.2 双向链表LinkedList(后续已废弃)
- 2.3 快速链表QuickList
三、List常见命令

一、List数据类型
1.1 简介
详细介绍:Redis五种数据类型、String、List、Set、Hash、ZSet
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构,按插入顺序排序,你可以添加一个元素到头部(左边)或尾部(右边)。在 Redis 中,列表最多可以包含 2^32 - 1 个元素。既可以支持正向检索和也可以支持反向检索。特征也与LinkedList类似:
- 有序
- 元素可重复
- 插入和删除快
- 查询速度一般。
1.2 应用场景
根据 Redis 双向列表的特性,因此其也被用于异步队列的使用。实际开发中将需要延后处理的任务结构体序列化成字符串,放入 Redis 的队列中,另一个线程从这个列表中获取数据进行后续处理。
- 消息队列:可以利用 List 的 push 和 pop 操作,实现生产者消费者模型。
- 时间线、动态消息:比如微博的时间线,可以将最新的内容放在 List 的最前面。
- 常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等
1.3 底层结构
- 在3.2版本之前,Redis List底层采用压缩链表ZipList 和双向链表LinkedList来实现List。当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则将自动采用LinkedList编码
- 在3.2版本之后,Redis统一采用快速链表QuickList来实现List
二、数据结构
Redis的List结构类似一个双端链表,可以从首、尾操作列表中的元素:
- 在Redis 3.2版本之前,Redis List底层采用压缩链表ZipList 和双向链表LinkedList来实现List。当元素数量小于512个并且元素大小小于64字节时采用ZipList编码,超过则将自动采用LinkedList编码。
- 在3.2版本之后,Redis统一采用快速链表QuickList结构来实现List
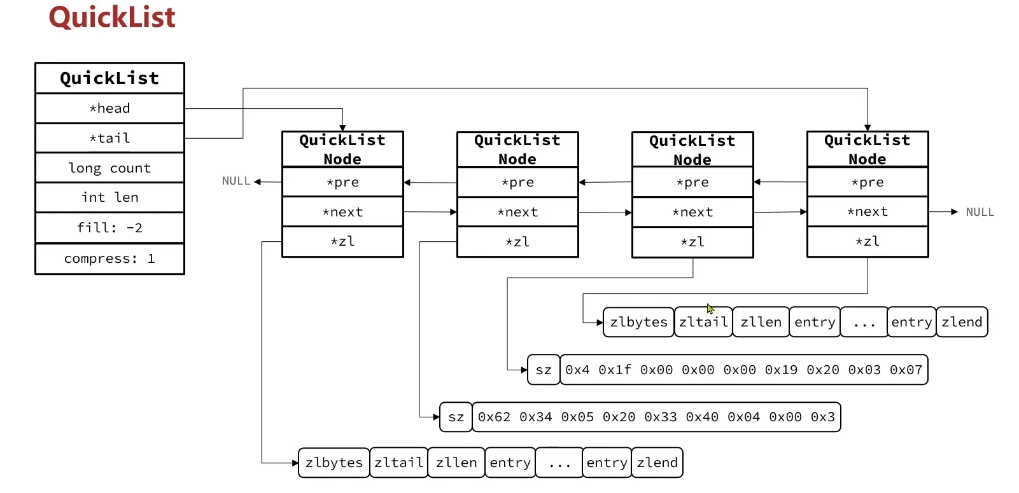
QuickList结构如下:
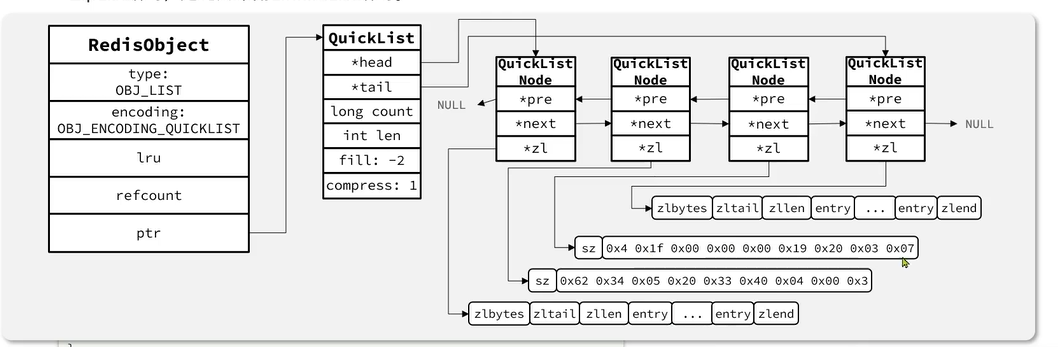
在 Redis3.2 版本前,Redis 列表 List 使用两种数据结构作为底层实现:
- 压缩列表 ZipList:插入元素过多或字符串太大,就需要调用 Realloc 扩展内存;
- 双向链表 LinkedList:需附加指针 Prev 和 Next,较浪费空间,加重内存的碎片化
2.1 压缩列表ZipList
在 Redis3.2 版本前 压缩列表不仅是 List 的底层实现之一,同时也是 Hash、 ZSet 两种数据类型底层实现之一。
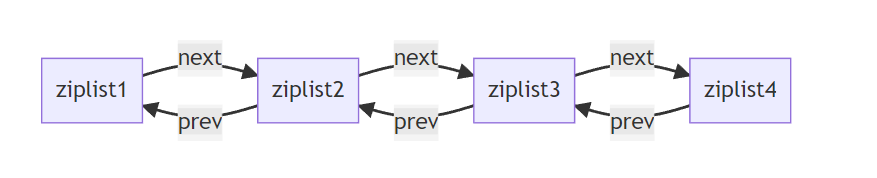
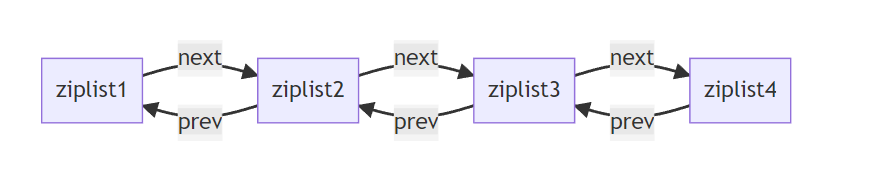
ZipList是一种特殊的"双端链表"(并非链表),由一系列特殊编码的连续内存块组成,像内存连续的数组。可以在任意一端进行压入/弹出操作,并且该操作的时间复杂度为O(1)。

压缩列表 底层数据结构:本质是一个数组,增加了列表长度、尾部偏移量、列表元素个数、以及列表结束标识,有利于快速寻找列表的首尾节点;但对于其他正常的元素,如元素2、元素3,只能一个个遍历,效率仍没有很高效。
当我们的 List 列表数据量比较少的时候,且存储的数据轻量的(如小整数值、短字符串)时候, Redis 就会通过压缩列表来进行底层实现。


| 属性 | 类型 | 长度 | 说明 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 一个 4 字节的整数,表示整个压缩列表占用的字节数量,包括 <zlbytes> 自身的大小 |
| zltail | uint32_t | 4字节 | 一个 4 字节的整数,记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,可以确定表尾节点的地址 |
| zllen | uint16_t | 2字节 | 一个 2 字节的整数,表示压缩列表中的节点数量。最大值为UINT16_MAX(65534),如果超过这个数,此处会记录为65535,但节点的真实数量需要遍历整个压缩列表才能计算出 |
| entry | 列表节点 | 不定 | 压缩列表中的元素,每个元素都由一个或多个字节组成,节点的长度由节点保存的内容决定。每个元素的第一个字节(又称为"entry header")用于表示这个元素的长度以及编码方式 |
| zlend | uint8_t | 1字节 | 一个字节,特殊值0xFF(十进制255),表示压缩列表的结束 |

注意:
-
如果查找定位首个元素或最后1个元素,可以通过表头 "zlbytes"、"zltail_offset" 元素快速获取,复杂度是 O(1)。但是查找其他元素时,就没有这么高效了,只能逐个查找下去,比如 entryN 的复杂度就是 O(N)
-
ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请效率较低。
2.2 双向链表LinkedList(后续已废弃)
LinkedList 是标准的双向链表,Node 节点包含 prev 和 next 指针,分别指向后继与前驱节点,因此从双向链表中的任意一个节点开始都可以很方便地访问其前驱与后继节点。

LinkedList 可以进行双向遍历;添加删除元素快 O(1),查找元素慢 O(n),高效实现了 LPUSH 、RPOP、RPOPLPUSH,但由于需要为每个节点分配额外的内存空间,所以会浪费一定的内存空间。这种编码方式适用于元素数量较多或者元素较大的场景。
LinkedList 结构为链表提供了表头指针 head、表尾指针 tail,以及节点数量计算 len。下图展示一个由 list 结构和三个 listNode 节点组成的链表:
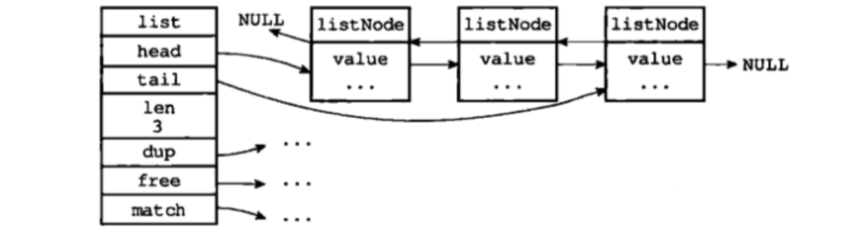
Redis 的链表实现的特性可以总结如下:
- 双端:链表节点带有 prev 和 next 指针,获取某个节点的前一节点和后一节点的复杂度都是 O(1);
- 无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问以 NULL 为终点;
- 表头指针/表尾指针:通过 list 结构的 head 指针和 tail 指针,获取链表的表头节点和表尾节点的复杂度为 O(1);
- 链表长度计数器:通过 list 结构的 len 属性来对 list 的链表节点进行计数,获取节点数量的复杂度为O(1);
- 多态:链表节点使用 void* 指针来保存节点值,并通过 list 结构的 dup、free、match 三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。
- 使用链表的附加空间相对太高,因为 64bit 系统中指针是 8 个字节,所以 prev 和 next 指针需要占据 16 个字节,且链表节点在内存中单独分配,会加剧内存的碎片化,影响内存管理效率
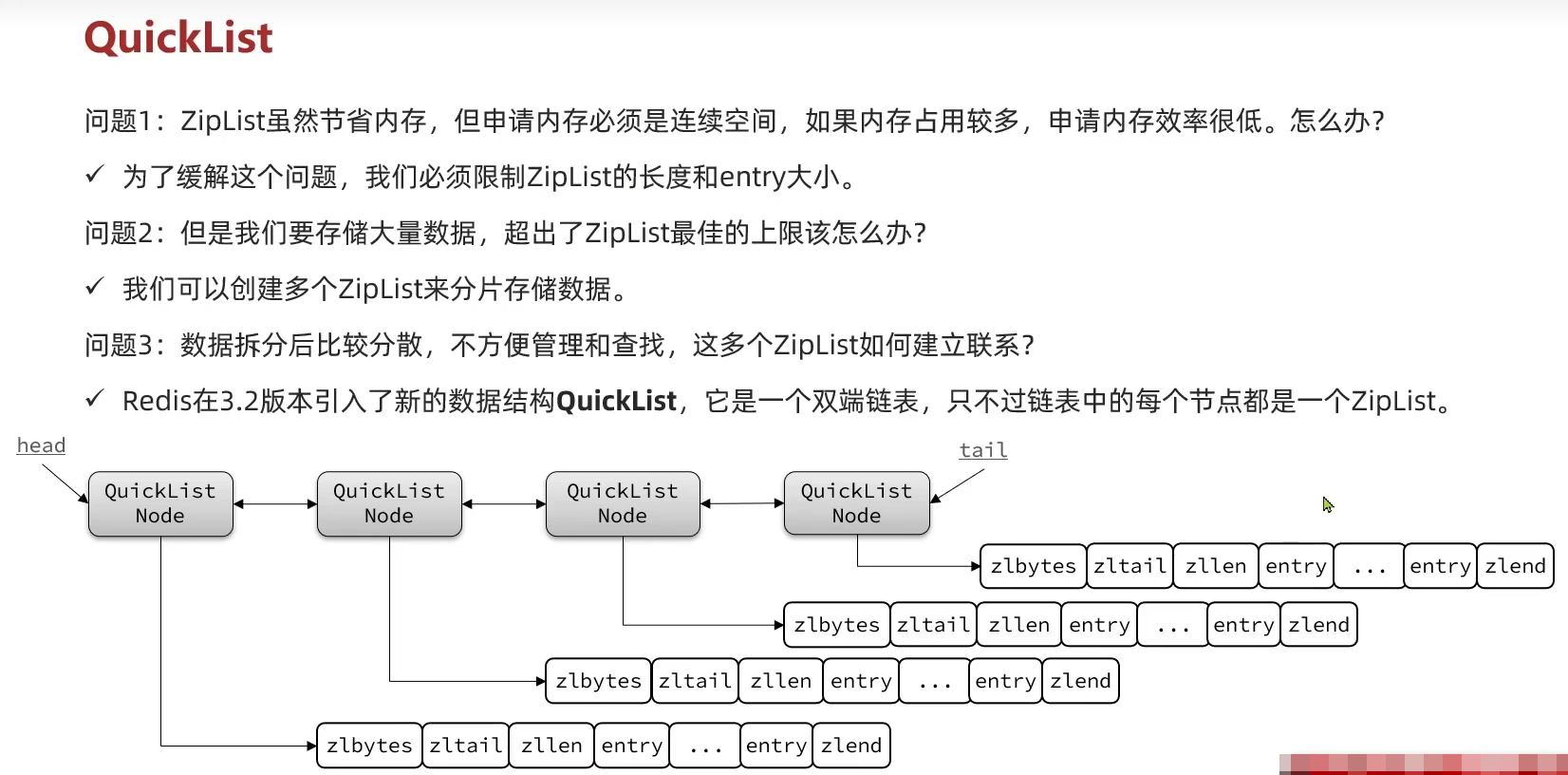
2.3 快速链表QuickList
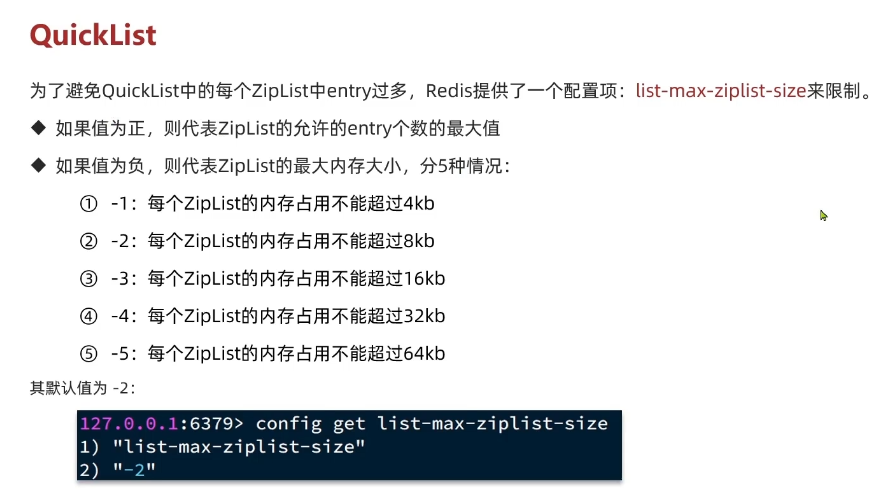
QuickList底层 LinkedList + ZipList,可以从双端访问,内存占用较低,保含多个ZipList,存储上限高。其特点:
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小,解决连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请效率较低。

三、List常见命令
List的常见命令有:
- LPUSH key value value ... :向列表左侧插入一个或多个元素
- LPOP key :移除并返回列表左侧的第一个元素,没有则返回nil
- RPUSH key value value ... :向列表右侧插入一个或多个元素
- RPOP key :移除并返回列表右侧的第一个元素
- LRANGE key start stop:返回一段角标范围内的所有元素
- BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil
- lindex key index:通过下标获得list当中的某一个值
- llen key:获取list的长度

-
如何利用List结构模拟一个栈?
- 入口和出口在同一边
-
如何利用List结构模拟一个队列?
- 入口和出口在不同边
-
如何利用List结构模拟一个阻塞队列?
- 入口和出口在不同边
- 出队时采用BLPOP或BRPOP
sql
127.0.0.1:6379> lpush list1 18 20 Jenny #向列表左侧插入一个或多个元素
(integer) 3
127.0.0.1:6379> lpush list1 Happy
(integer) 4
127.0.0.1:6379> lrange list1 0 2 #返回一段角标范围内的所有元素
1) "Happy"
2) "Jenny"
3) "20"
127.0.0.1:6379> rpush list1 Jack Health 16 #向列表右侧插入一个或多个元素
(integer) 7
127.0.0.1:6379> lrange list1 0 -1 #通过区间获取具体的值
1) "Happy"
2) "Jenny"
3) "20"
4) "18"
5) "Jack"
6) "Health"
7) "16"
127.0.0.1:6379> lpop list1 #移除list的第一个元素:Happy
"Happy"
127.0.0.1:6379> rpop list1 #移除list的最后一个元素:16
"16"
127.0.0.1:6379> lindex list1 2 #通过下标获得list当中的某一个值
"18"
127.0.0.1:6379> llen list1 #获取list的长度
(integer) 5
127.0.0.1:6379> rpush list1 18 Jack
(integer) 7
127.0.0.1:6379> lrange list1 0 -1
1) "Jenny"
2) "20"
3) "18"
4) "Jack"
5) "Health"
6) "18"
7) "Jack"
127.0.0.1:6379> lrem list1 2 Jack #移除list集合指定个数的value,移除2个值为Jack的,精确匹配
(integer) 2
127.0.0.1:6379> lrange list1 0 -1
1) "Jenny"
2) "20"
3) "18"
4) "Health"
5) "18"
127.0.0.1:6379> ltrim list1 3 4 #截取list集合中下标为3到下标为4之间的元素集合,并覆盖原来的list集合
OK
127.0.0.1:6379> lrange list1 0 -1
1) "Health"
2) "18"
127.0.0.1:6379> lset list 1 17
(error) ERR no such key
127.0.0.1:6379> lset list1 1 17 #更新list集合当中下标为1的值为17,如果下标1的值不存在,则报错
OK
127.0.0.1:6379> linsert list1 AFTER Health 20 #将某个具体的值插入到某一个具体元素(默认第一个)的前面或者后面
(integer) 3
127.0.0.1:6379> linsert list1 BEFORE Health Jenny
(integer) 4
127.0.0.1:6379> lrange list1 0 -1
1) "Jenny"
2) "Health"
3) "20"
4) "17"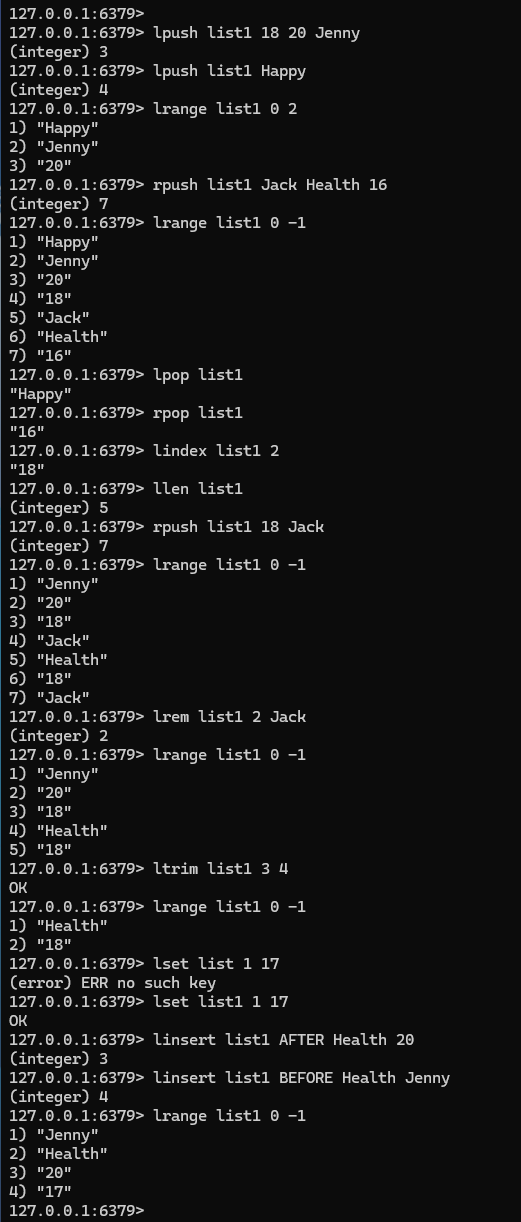
参考 Redis基础(超详解)一 :Redis定义、SQL与NoSQL区别、Redis常用命令、Redis五种数据类型、String、List、Set、Hash、ZSet;Redis的Java客户端 、Redis数据结构:List类型全面解析