k8s技术全景:架构、应用与优化
参考:
- K8S 基本概述、设计架构和设计理念:https://cloud.tencent.com/developer/article/1718383
- 设计理念:https://www.kubernetes.org.cn/kubernetes设计理念
这是之前调研k8s的时候写过的一篇总结,现在分享出来,后面可能会做一些补充。
一、介绍
1、Kubernetes 的历史和演进
Kubernetes(简称 K8s)是一个开源的容器编排系统,用于自动化应用程序的部署、扩展和管理。它最初是由 Google 内部的 Borg 系统启发并设计的,于 2014 年作为开源项目首次亮相。
1.1 初始阶段
Kubernetes 的诞生源于 Google 内部对大规模容器管理的需求。早在 2014 年之前,Google 已经在其内部系统 Borg 上积累了大量关于容器编排和管理的经验。这些经验和技术最终孕育出 Kubernetes。
1.2 发展阶段
随着云计算和微服务架构的兴起,Kubernetes 迅速成为行业标准。它的设计哲学、可扩展性和社区支持是其成功的关键因素。2015 年,Cloud Native Computing Foundation(CNCF)成立,并接管了 Kubernetes 的发展。在 CNCF 的支持下,Kubernetes 经历了快速发展,吸引了一大批贡献者和用户。
1.3 演进阶段
Kubernetes 不断演进,增加了对多种云平台的支持,改进了网络和存储功能,增强了安全性。其社区也不断扩大,衍生出众多相关项目和工具,形成了一个庞大的生态系统
2、k8s 的核心概念和设计理念
2.1 核心概念(简单列举几个)
- 1、Pod:Pod 是 Kubernetes 的基本运行单位,代表了在集群中运行的一个或多个容器的组合。
- 2、Volumes:属于存储类别,是用来生命在 Pod 中的容器可以访问的文件目录的,是一个抽象的对象,不仅支持本地存储,也支持网络存储和分布式存储。
- 3、Deployment:Deployment 提供了对 Pods 和 ReplicaSets(副本集)的声明式更新能力。
- 4、Service:Service 是对一组提供相同功能的 Pods 的抽象,它提供了一个稳定的网络接口。
- 5、Label:对 k8s 中各种资源进行分类、分组,添加具有特别属性的标签,相当于给资源打标签,从而过滤出匹配的资源。
- 6、Namespace:提供一种机制,将同一集群中的资源划分为相互隔离的组。用于给集群中任何对象组进行分类、筛选和管理(便于划分团队、项目、产品阶段、权限访问控制等)。
- 7、Master:指的是集群控制节点,负责整个集群的管理和控制,支持高可用部署,可以看作"控制面"。
- 8、Worker:工作负载节点,特指一台物理机,可以看作"数据面"。
2.2 设计理念
-
声明式配置:Kubernetes 使用声明式配置(而非命令式),用户定义期望状态,系统负责实现这一状态。
-
自我修复:系统能够自动替换、重启、复制和扩展集群中的节点(达到用户期望的状态)。
-
可扩展性: CRD(Custom Resource Definition)、可扩展接口、Device Plugin、CNI(Container Network Interface)、CRI(Container Runtime interface)、CSI(Container Storage Interface)、调度框架扩展
-
高内聚、低耦合(代码层面):API 对象是彼此互补而且可组合的。
二、k8s 架构
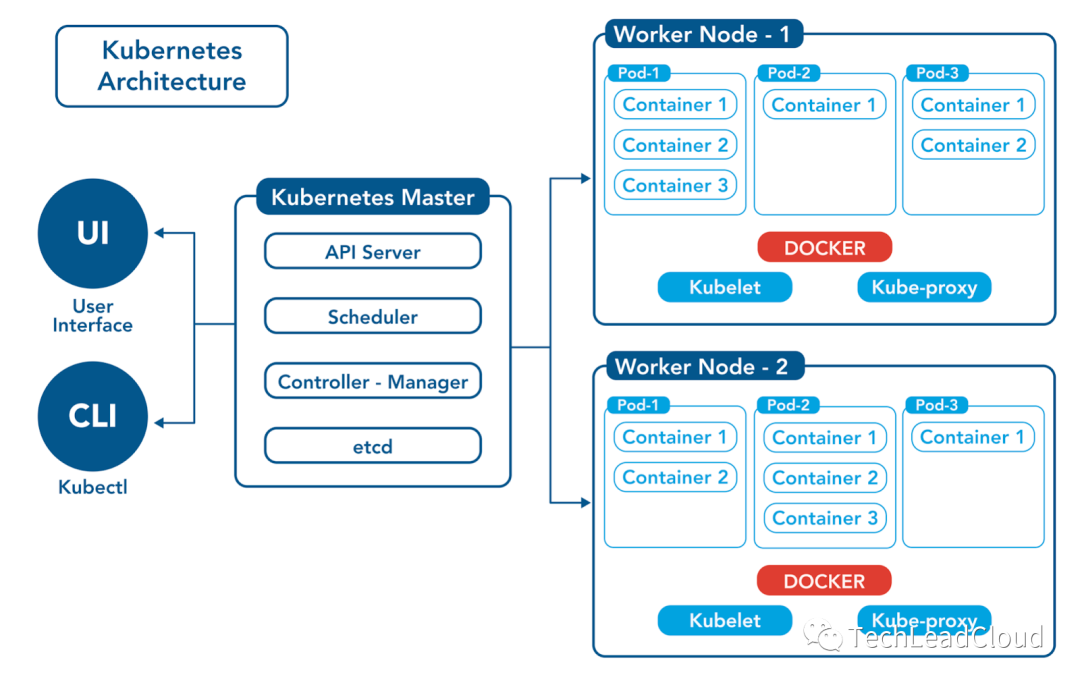
2.1 主要组件和节点类型
1. 控制平面(Master 节点)
控制平面是 Kubernetes 的大脑,负责整个集群的管理和协调。它包含几个关键组件:
- API 服务器(kube-apiserver) :作为集群的前端,处理 REST 请求,是所有通信的枢纽。
- 集群数据存储(etcd) :一个轻量级、高可用的键值存储,用于保存所有集群数据。
- 控制器管理器(kube-controller-manager) :运行控制器进程,这些控制器包括节点控制器、副本控制器等。(维护 k8s 资源对象)
- 调度器(kube-scheduler) :负责决定将新创建的 Pod 分配给哪个节点。
2. 工作节点(Worker 节点)
工作节点是运行应用程序容器的物理服务器或虚拟机。它们包括:
- Kubelet:确保容器在 Pod 中运行,并向控制平面汇报节点的状态。(管理本机运行容器的生命周期,负责 pod 对应的容器的创建、启停等任务)
- Kube-Proxy:负责节点上的网络代理,实现服务发现和负载均衡。
- 容器运行时:负责运行容器,例如 Docker 或 containerd。
2.2 控制平面和数据平面的工作原理
1. 控制平面
控制平面维护着集群的全局状态,如调度决策、响应 Pod 生命周期事件、控制器的逻辑等。它确保集群始终处于用户定义的期望状态。
2. 数据平面
数据平面包括所有工作节点,负责实际运行用户的应用程序。它通过 Kubelet 和 Kube-Proxy 来维护 Pod 的生命周期和网络规则。
三、高可用和灾难恢复
在 Kubernetes 集群管理中,实现高可用性和灾难恢复策略是至关重要的。这些机制确保在硬件故障、软件错误、网络问题等不可预测情况下,集群和应用能够持续运行或快速恢复。
3.1 集群的高可用配置
1. 控制平面的高可用
- 多节点控制平面:部署多个控制平面节点,以避免单点故障。
- 负载均衡器:在控制平面节点前设置负载均衡器,以分散请求。
- etcd 集群:运行多个 etcd 实例,形成一个高可用的键值存储集群。
2. 工作节点的高可用
- 自动扩展和自愈:使用集群自动扩展器和自动修复策略确保足够的工作节点数量和健康状态。
- 跨区域部署:在不同的地理位置或云区域部署节点,以抵御区域性故障。
3.2 备份与恢复策略
1. 数据备份
- etcd 备份:定期备份 etcd 数据,这对于恢复集群状态至关重要。
- 持久卷备份:对 PersistentVolumes 进行定期备份,以保证数据安全。
2. 集群资源备份
- Kubernetes 资源备份:使用工具如 Velero 备份 Kubernetes 资源和配置,包括 Deployments、Services 等。
3. 灾难恢复
- 恢复计划:制定详细的灾难恢复计划,包括如何快速恢复集群和应用。
- 演练:定期进行灾难恢复演练,以验证和改进恢复流程。
4. 容灾策略
- 多集群部署:部署多个 Kubernetes 集群,作为彼此的备份,以保证至少有一个集群始终可用。
- 数据复制:跨集群复制关键数据和配置,以确保在主集群不可用时能够快速切换。
通过这些高可用和灾难恢复策略,Kubernetes 能够最大限度地减少系统停机时间,保证业务连续性和数据完整性。这些策略对于运行关键业务应用的企业来说尤为重要。
四、全景总结
可参考了解:
可参考:
- https://www.kubernetes.org.cn/kubernetes%e8%ae%be%e8%ae%a1%e7%90%86%e5%bf%b5
- https://zhuanlan.zhihu.com/p/348012213
- https://draveness.me/cloud-native-kubernetes-extension/
- https://cloud.tencent.com/developer/article/1718383
- https://marksuper.xyz/2022/03/01/k8s-design/
- https://draveness.me/understanding-kubernetes/
- https://cloud.tencent.com/developer/article/2088377
4.1 列举概念 + 功能
| 大模块 | 小模块 | 概念 | 功能 |
|---|---|---|---|
| 控制器 | Pod | Pod 是 Kubernetes 的基本运行单位, 代表了在集群中运行的一个或多个容器的组合, 是传统容器的抽象和封装。 | 承受所有的工作负载 提供启动后和删除前的钩子功能 提供对 Pod 内服务的健康检查功能 提供容器组之间的共享功能 |
| RC & RS | 复制控制器,可以确保 Pod 副本数达到期望值, 与手动创建 Pod 方式的不同之处在于使用 RC & RS 维护的 Pod 在失败、删除、或终止时会自动替换。 | 提供 Pod 副本的自动扩缩容的功能 | |
| deployment | 用于部署无状态应用,提供一种声明式的方式来描述应用的期望状态。 | 版本控制 弹性伸缩 滚动更新 自动灾难恢复 暂停 or 继续 | |
| StatefulSet | 主要用于管理有状态应用的工作负载,如:Redis 集群、Kafka 集群等, 与 deployment 不同的是,每个 Pod 都有一个持久的标识符。 | 部署有状态应用 稳定的、持久的存储(删除或者扩缩 StatefulSet 并不会删除它关联的存储卷) 有序的、优雅的部署和扩缩容 有序的、自动的滚动更新 稳定的域名 | |
| DaemonSet | DaemonSet 是一个确保全部或者某些节点上必须运行一个 Pod 的工作负载资源(守护进程), 当有节点加入集群时, 也会为他们新增一个 Pod。 | 在每个节点上运行集群守护进程 部署对集群至关重要的基础设施 | |
| Job/CronJob | Job 是 Kubernetes 用来控制批处理型任务的资源对象。 CrobJob 则就是在 Job 上加上了时间调度,用来执行一些周期性的任务。 | 支持单个 or 多个任务并行执行 支持挂起 Job 定时任务(例如:周期备份、发邮件等等任务) | |
| HPA | 水平 Pod 自动缩放器。 | 自动扩缩容 指标监控 | |
| RuntimeClass | 用于指定容器运行时的类型和配置。 | 将容器运行时的选择权交给了用户, 使其能够根据实际需求选择最合适的容器运行时 | |
| 调度器 | Label & Selector | Label 对 k8s 中各个资源进行分类、分组,添加一个具有特别属性的标签 Selector 通过一个过滤的语法进行查找到对应标签的资源。 | 资源的标识和分类 资源的选择和过滤 资源间的关联关系 |
| NodeSelector | 节点选择器,用于将 Pod 调度到匹配 label 的 node 上。 | 可以动态调度到具有指定 Label 的节点上, 或者说调度到具有指定特性的物理机上 | |
| nodeAffinity & NodeAntiAffinity | 节点亲和器和反亲和器(比 NodeSelector 更强大的节点选择器)。 | 资源隔离(将有冲突的服务部署在不同物理机) 性能优化(通信量较大的服务部署在同一台物理机) 实现服务容灾(同一个服务的副本部署在不同物理机) 资源灵活选择(如选择 sgx 节点) | |
| podAffinity & podAntiAffinity | Pod 亲和器和反亲和器。 | ||
| taint & tolerations | 污点和容忍度。 | 避免某些节点被调度,比如:master 污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上 | |
| 存储 | secret | 是一种包含少量敏感信息例如密码、令牌或密钥的对象。 | 减少敏感信息的暴露面 |
| configMap | 用来存储配置文件的 kubernetes 资源对象。 | 以存储卷或 env 的方式注入配置信息 支持热更新 配置信息与容器的解耦 | |
| Volumes | 属于存储类别,是用来声明在 Pod 中的容器可以访问的文件目录的,是一个抽象的对象。 | 容器间文件目录共享 为不同种类的卷提供了统一的接入方式 | |
| PV & PVC | PersistentVolume(持久卷,简称 PV)是集群内,由管理员提供的网络存储的一部分 PersistentVolumeClaim(持久卷声明,简称 PVC)是用户的一种存储请求 PVC 与 PV 的绑定是一对一的映射 | 实现对存储的动态管理 实现存储与容器的解耦 实现持久化存储 抽象存储资源 | |
| 网络 | 网络模型: 集群里的每个 Pod 都会有唯一的一个 IP 地址 Pod 里的所有容器共享这个 IP 地址 集群里的所有 Pod 都属于同一个网段 Pod 直接可以基于 IP 地址直接访问另一个 Pod,不需要做麻烦的网络地址转换(NAT) 共享 namespace : Pod 里面的容器共享 network namespace (IP and MAC address) | Pod-to-Pod 网络模型:Pod 直连 Service-to-Pod 网络模型: Pod 根据需求动态扩缩、故障恢复时,IP 地址发生变化时可能无法访问, k8s 抽象出 Service 当作一组 Pod 的入口,入口不会变化,解决了该问题 | |
| 集群安全机制 | 认证 | 认证阶段负责识别客户端的身份。 | 方式:PKI、HTTP token、Service Account |
| 授权 | 授权阶段判断请求是否具有相应的权限。 | 方式:ABAC(基于属性的访问控制)、RBAC(基于角色的访问控制) | |
| 准入控制 | 用于拦截(在认证和授权之后)对 API 的请求 | 如:PodSecurityPolicies、ResourceQuotas、NamespaceLifecycle 等 | |
| Pod 安全 | 主要包含一些限制容器内权限的机制 | 如:安全上下文、Pod 安全策略、最小权限原则 | |
| 服务发现 | Ingress | Ingress 相当于一个 7 层的负载均衡器,是 kubernetes 对反向代理的一个抽象,它的工作原理类似于 Nginx。 | 提供 URL 路由、负载均衡、HTTPS 入口和名称基础的虚拟主机 |
| Service | 一种抽象,定义了访问一组 Pod 的方式。 | 相当于四层代理 公开集群内的 Web 服务 提供了一个稳定的网络接口 |
4.2 全景关系图


4.3 总结
4.3.1 架构、高可用
从全景图 1 来看 k8s 的 master 节点支持多台物理机分布式部署,抵抗单节点故障。etcd 是一个分布式的 key-value 数据库,能很好的支持这种高可用架构,通过 etcd 来维护集群状态。所有组件都通过 API Server 与 etcd 交互,获取或更改集群的状态信息。同时,也可以给多个 master 的 API Server 服务设置负载均衡器,分散请求,减小压力。
API Server 是所有请求的入口,无论是内部请求(worker 节点的 kube-proxy、kubelet 也会与 API server 交互,通过 API Server 向 etcd 写入数据)还是外部请求。但是,进入 API Server 的请求需要经过集群安全机制的验证,主要包含认证、授权、准入控制,如 PKI 证书体系、基于角色的访问控制。同时,基于角色的访问控制,在我理解看来,主要是结合实现对资源的处理限制,比如对 Pod 资源可能本来有增删改查四种操作,经过限制后只保留了增删,而没有改查,这种限制会绑定到特定的账户,账户又可以绑定到特定的资源来实现对资源的限制。
4.3.2 调度器
Kubernetes 调度器采用多步骤的过程来选择最佳节点:
- 过滤:基于资源需求、策略限制、亲和性规则等过滤掉不适合的节点,其实就是对应:nodeSelector、nodeAffinity、podAffinity 等调度器协助实现的,这些模块都是基于对资源打的 Label 实现的。
- 评分:对于剩余节点,基于资源使用率、网络拓扑等因素计算评分。
- 选择:选择得分最高的节点来部署 Pod。
此过程确保了有效的资源分配和负载平衡,同时满足用户对部署位置的具体要求。
4.3.3 控制器
k8s 中多种多样的控制器的组合运用,提供了:自动装箱、故障修复、水平扩展(自动)、滚动更新等功能。此外,也支持不同类型应用的部署:有状态、无状态、任务、定时任务。
4.3.4 存储
volumes 是 k8s 对容器的存储做了进一步的抽象,在声明 Pod 的配置时,可以指明卷的名称以及类型,4.1 中提到的 PVC、secret、configMap 都可以作为一种卷,不过 PVC 只是一个使用存储卷的声明,真正的卷是 PV,PV 代表一块存储空间,可以对接种类繁多的云存储,可以独立于 Pod 存在,是比 volumes 更高一级的抽象,可以在 Pod 间共享。这种对存储的抽象可以提供:数据存储、数据共享、数据备份和恢复、数据迁移和扩展和数据安全等功能。
4.3.5 网络、服务发现
Kubernetes 采用的是扁平化网络模型,可以叫做覆盖网络(Overlay Network),要求每个 Pod 都有一个独一无二的 IP 地址。这意味着在整个集群内,每个 Pod 都应该能够直接访问其他 Pod,而无需 NAT。同时,k8s 允许使用网络策略来控制 Pod 间的流量,这些策略基于标签和命名空间,允许定义复杂的规则集,以确定 Pods 间的通信权限。
服务发现,是借助 Service 和 Ingress 两个抽象模块实现,Service 相当于一个四层代理,将运行在一个或一组 Pod 上的服务公开为网络服务,可以通过 Service 的 IP 访问到 Pod 中的服务。此外,Service 可以提供端口映射、负载均衡的服务,这些功能的实现借助于 kube-proxy,proxy 会根据 Service 中配置的信息以及关联的 Pod,创建相关的 iptables 或 IPVS 规则。同时,Service 也可以用来代理集群外部的服务。
而 Ingress 相当于七层代理,是 Service 上层的模块,可以将请求转发到 service,里面包含 Service 的路由,类似 nginx。同时,Ingress 支持证书认证体系,和域名访问。
4.3.6 docker、kata
经过调研发现,创建常规 docker容器时,k8s 集群中的 worker 节点的 Kubelet 通过 CRI (例如 containerd 或 cri-o) 与 runC 进行通信,runC 负责运行 pod 中的容器。而创建 kata 容器时,需要一个与 kata 容器兼容的 containerd-shim-kata-v2,Kata Containers 的运行时在隔离的内核和命名空间中运行容器。
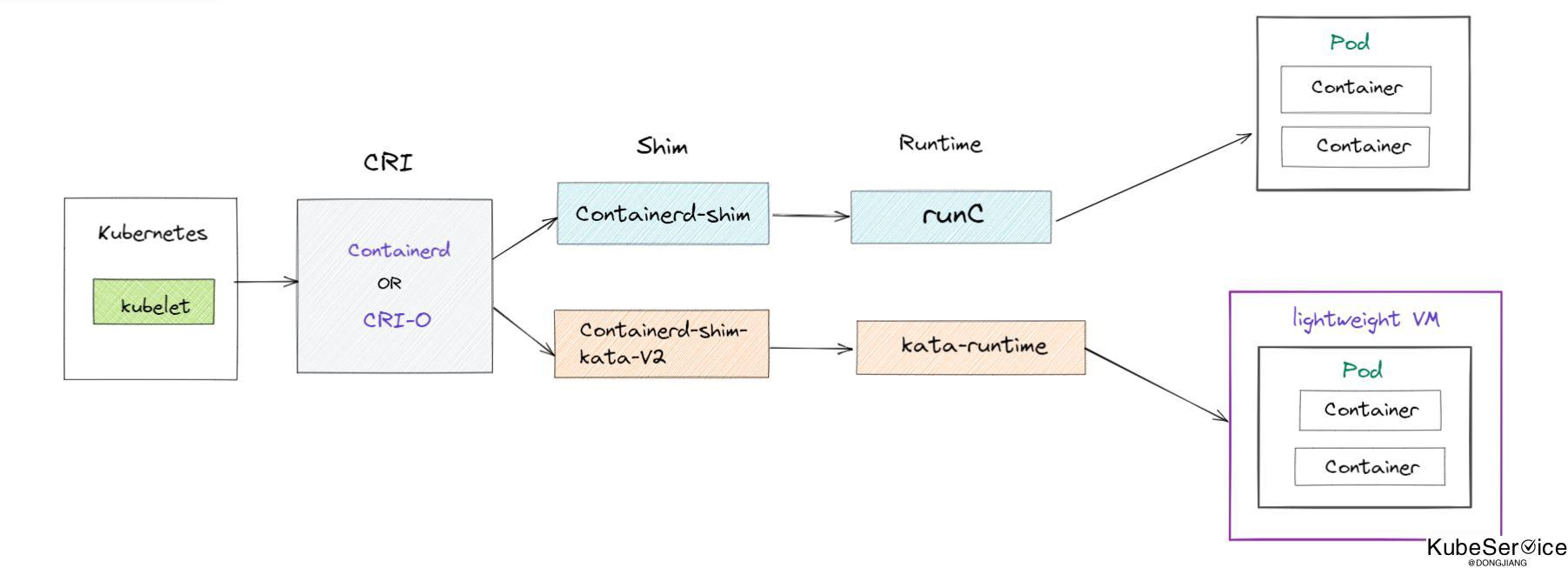
所以,安装 kata 时,只需要满足 kata 基本的运行环境(软件、Host kernel 开启 kvm 内核模块:qemu-system-x86_64),并且 k8s 的容器运行时接口使用了 contained 或 cri-o,就可以在 k8s 集群内的指定节点上搭建 kata runtime,通过调度器将 Pod 调度到具有 kata runtime 的节点上运行。