小说下载
python
# 引入框架
import tkinter as tk
import requests
from lxml import etree
# 类
class Query:
# 类里面的一个固定方法
def __init__(self, master) -> None:
self.wd_1 = master
# 设置窗口大小
self.wd_1.geometry("400x330+700+20")
# 设置窗口标题
self.wd_1.title("小说下载")
# 设置窗口的图标
self.wd_1.iconbitmap("./小说下载/小说.ico")
# tk 特殊变量 绑定输入框
self.index_url = tk.StringVar()
self.create_page()
self.handle_event()
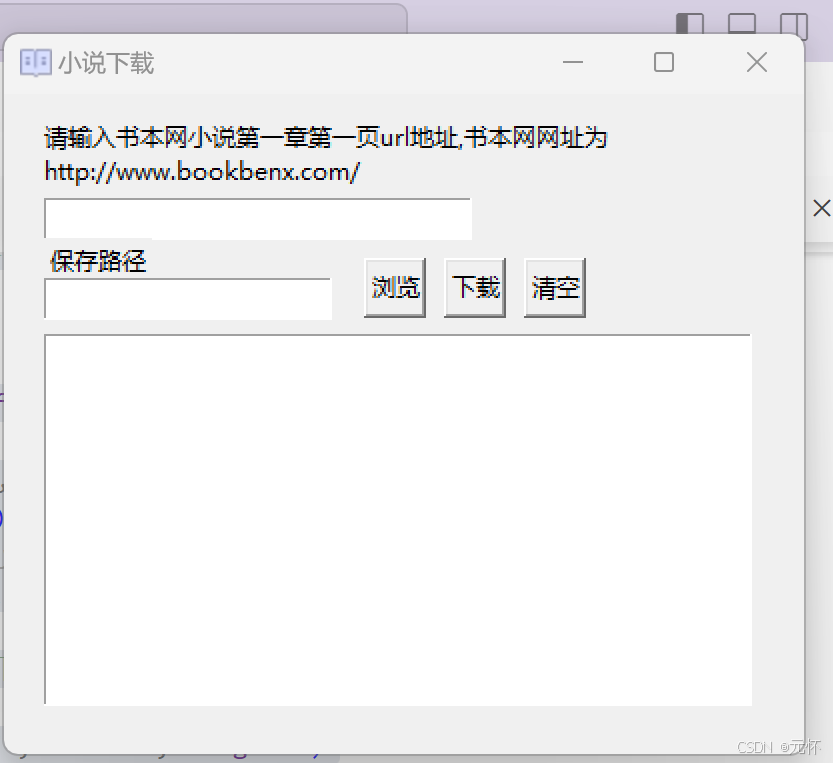
def create_page(self):
"""创建页面"""
# label 文本
tk.Label(
self.wd_1,
text="请输入书本网小说第一章第一页url地址,书本网网址为\nhttp://www.bookbenx.com/",
justify=tk.LEFT,
).place(x=17, y=10)
# entry 输入框
tk.Entry(self.wd_1, width=30, textvariable=self.index_url).place(x=20, y=52)
# 保存路径 lable
tk.Label(self.wd_1, text="保存路径").place(x=20, y=72)
tk.Entry(self.wd_1, width=20).place(x=20, y=92)
# tk.Label(self.wd_1, text="浏览").place(x=20, y=82)
self.button_1 = tk.Button(self.wd_1, text="浏览", width=3, height=1)
self.button_1.place(x=180, y=82)
self.bt_download = tk.Button(self.wd_1, text="下载", width=3, height=1)
self.bt_download.place(x=220, y=82)
self.button_3 = tk.Button(self.wd_1, text="清空", width=3, height=1)
self.button_3.place(x=260, y=82)
# 文本框
self.text_1 = tk.Text(self.wd_1, width=50, height=14)
self.text_1.place(x=20, y=120)
def handle_event(self):
# 点击下载开始下载小说
# 拿到小说链接
# 当下在按钮被点击的时候 获取下载地址,然后进行下载
self.bt_download["command"] = self.download_book
def download_book(self):
book_url = self.index_url.get()
# 下载小说
# 伪装自己
while True:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0"
}
# 发送请求
resp = requests.get(book_url, headers=headers)
# 设置编码
resp.encoding = "utf-8"
# 响应
##print(resp.text)
# 保存
e = etree.HTML(resp.text)
# 小说内容
# 书本网
info = "\n".join(e.xpath("//div//article/p/text()"))
# 全本小说网
# info = "\n".join(e.xpath('//div[@id="booktxt"]/p/text()'))
# 小说标题
# 书本网
title = e.xpath('string(//div//p[@class="style_h1"])')
# 全本小说网
# title = e.xpath("//h1/text()")[0]
# 小说名字
# 书本网
book_name = e.xpath('//meta[@property="og:title"]/@content')[0]
# 全本小说网
# book_name = e.xpath('//div[@id="header_title"]/a')
# 下一页 or 下一章
# 书本网
next_url = e.xpath('//div//a[@id="next_url"]/@href')[0]
# url 重新赋值
book_url = "http://www.bookbenx.com" + next_url
# 全本小说网
# 获取下一页的小说内容
# requests.get(next_url, headers=headers)
# 输出到txt里
# print(next_url)
# print(title)
# print(info)
# print(book_name)
next_name = e.xpath('//div//a[@id="next_url"]/text()')[0]
# print(next_name)
if next_name == "没有了 ":
break
with open(book_name + "." + "txt", "a", encoding="utf-8") as f:
f.write(title + "\n\n" + info + "\n\n")
self.text_1.insert("insert", f"{title}下载完成\n")
self.text_1.update()
if __name__ == "__main__":
# 窗口对象
wd_1 = tk.Tk()
# 调用页面类,传入窗口对象
Query(wd_1)
# 事件循环
wd_1.mainloop()