Quartz定时任务
我们经常需要在某个特定的时间做业务处理,如发生生日祝福,除夕拜年短信等,那么就需要使用定时任务框架来解决;
一.quartz 介绍
Quartz是一个功能丰富的开源任务调度库,用于在Java应用程序中进行任务调度。它提供了一种灵活而强大的方式来定义和安排任务的执行时间,支持周期性任务、延迟任务、固定间隔任务等。
- **灵活的任务调度:**Quartz可以根据各种调度规则定义任务的执行时间,如固定延迟、固定间隔、Cron表达式等。可以轻松地创建简单或复杂的任务调度方案。
- **分布式调度支持:**Quartz支持分布式任务调度,可在多个节点上运行并协调任务的执行。这种分布式架构提供了可靠、高可用的任务调度解决方案。
- **持久化存储:**Quartz支持将任务和触发器的状态信息存储在数据库中,以便在应用程序重启后能够保持任务的持久化和恢复。它提供了与多种数据库的集成,并有内置的任务存储机制。
- **错误恢复和重试机制:**Quartz提供了丰富的错误处理和恢复机制,以确保任务执行的稳定性。如果任务执行失败,Quartz会根据预定义的策略进行错误处理和任务重试。
- **监控和管理:**Quartz提供了一套管理和监控API,可用于手动管理任务调度器、查询任务和触发器的状态、查看执行日志等。这些API可以方便地集成到的应用程序或管理工具中。
- **插件扩展性:**Quartz具有良好的扩展性,允许开发人员编写自定义的任务存储、调度器监听器、触发器监听器等插件,以满足特定的需求和业务逻辑。
二.案例
入门案例
引入依赖
java
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
java
// 1.job定义
public class HelloJob implements Job {
@Override
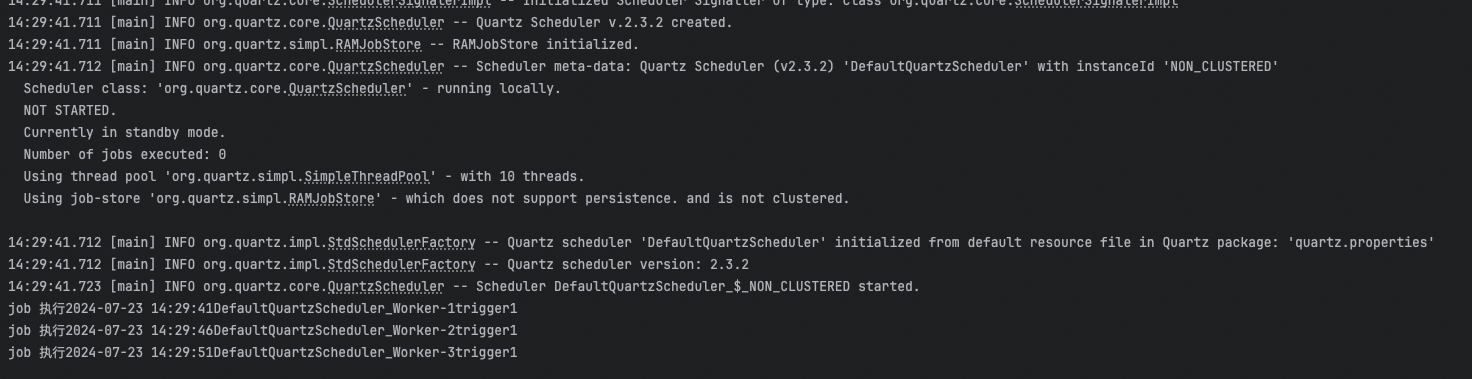
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
StringJoiner joiner = new StringJoiner("")
.add("job 执行")
.add(sdf.format(new Date()))
.add(Thread.currentThread().getName())
.add(jobExecutionContext.getTrigger().getKey().getName());
System.out.println(joiner);
}
}
java
// 2.测试
public class QuartzTest {
public static void main(String[] args) {
try {
// 获取一个默认的调度器
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 启动调度器(在哪启动都可以,启动的时候将任务和触发器关联起来也是没问题的)
scheduler.start();
// 创建一个名为 job 的任务细节,指定任务的执行类为 HelloJob ,并为其设置标识 job1 和所属组 group1
JobDetail job = newJob(HelloJob.class)
.withIdentity("job1","group1")
.build();
// 创建一个名为 trigger 的触发器,设置标识为 trigger1 ,所属组为 group1 ,立即开始执行,并且设置执行的时间间隔为每 5 秒执行一次,永远重复
Trigger trigger = newTrigger()
.withIdentity("trigger1","group1")
.startNow()
.withSchedule(simpleSchedule()
.withIntervalInSeconds(5)
.repeatForever())
.build();
// 使用 scheduler.scheduleJob 方法将任务和触发器关联起来,让调度器按照设定的规则执行任务
scheduler.scheduleJob(job,trigger);
Thread.sleep(20000000);
// scheduler.shutdown 方法关闭调度器
scheduler.shutdown();
} catch (SchedulerException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
springBoot整合

1.引入依赖
java
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>2.定义job类
java
@PersistJobDataAfterExecution
@DisallowConcurrentExecution
public class QuartzJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
try {
Thread.sleep(2000);
System.out.println(context.getScheduler().getSchedulerInstanceId());
System.out.println("taskName=" + context.getJobDetail().getKey().getName());
System.out.println("执行时间:" + new Date());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (SchedulerException e) {
e.printStackTrace();
}
}
}3.配置调度器
java
@Configuration
public class SchedulerConfig {
@Autowired
private DataSource dataSource;
@Bean
public Scheduler scheduler() throws IOException {
return schedulerFactoryBean().getScheduler();
}
@Bean
public SchedulerFactoryBean schedulerFactoryBean() throws IOException {
SchedulerFactoryBean factory = new SchedulerFactoryBean();
factory.setSchedulerName("cluster_scheduler");
// 注入数据源
factory.setDataSource(dataSource);
// 选填
factory.setApplicationContextSchedulerContextKey("application");
factory.setQuartzProperties(quartzProperties());
// 读线程池配置
factory.setTaskExecutor(schedulerThreadPool());
// 等待设置其他属性
return factory;
}
@Bean
public Properties quartzProperties() throws IOException {
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
propertiesFactoryBean.setLocation(new ClassPathResource("/spring-quartz.properties"));
propertiesFactoryBean.afterPropertiesSet();
return propertiesFactoryBean.getObject();
}
@Bean
public Executor schedulerThreadPool() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
// 处理器的核心数
taskExecutor.setCorePoolSize(Runtime.getRuntime().availableProcessors());
// 最大线程数
taskExecutor.setMaxPoolSize(Runtime.getRuntime().availableProcessors());
// 容量
taskExecutor.setQueueCapacity(Runtime.getRuntime().availableProcessors());
return taskExecutor;
}
}4.监听
java
@Component
public class StartApplicationListener implements ApplicationListener<ContextRefreshedEvent> {
@Autowired
private Scheduler scheduler;
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
// 开启调度
// 可以先判断触发器是否存在
/**
* JobDetail有一个类型为JobKey的重要属性key,相当于是该任务的键值,JobDetail注册到任务调度器Schedule中的时候,key值不允许重复。***整个任务调度过程中,Quartz都是通过Jobkey来唯一识别JobDetail的。试图将重复键值的JobDetail注册到任务调度器中而不指定覆盖的话,是不被允许的。***
*
* JobKey可以通过JobBuiler的withIdentity方法指定,该方法接收name或name+group参数,从而唯一确定一个任务JobDetail。
*
* 如果在JobDetail创建过程中不指定JobKey的话,Quartz会通过UUID的方式为该任务生成一个唯一的key值。
*
* ***所以,同一个Job实现类(也就是同一个任务),可以通过不同的JobKey值注册到任务调度器中、绑定不同的触发器执行!
*/
TriggerKey triggerKey = TriggerKey.triggerKey("trigger1", "group1");
try {
Trigger trigger = scheduler.getTrigger(triggerKey);
if (trigger == null) {
// 触发器
TriggerBuilder.newTrigger().withIdentity(triggerKey)
.withSchedule(CronScheduleBuilder.cronSchedule("0/10 * * * * ?")).build();
//
JobDetail jobDetail = JobBuilder.newJob(QuartzJob.class)
.withIdentity("job1", "group1")
.build();
scheduler.scheduleJob(jobDetail, trigger);
scheduler.start();
}
} catch (SchedulerException e) {
e.printStackTrace();
}
}
}基本配置
- Scheduler配置
java
#============================================================================
# Scheduler 调度器属性配置
#============================================================================
# 调度标识名 集群中每一个实例都必须使用相同的名称,可以为任意字符串,对于scheduler来说此值没有意义,但是可以区分同一系统中多个不同的实例
org.quartz.scheduler.instanceName = ClusterQuartz
# ID设置为自动获取 每一个必须不同
org.quartz.scheduler.instanceId= AUTO
org.quartz.scheduler.rmi.export = false
org.quartz.scheduler.rmi.proxy = false
# 默认false,若是在执行Job之前Quartz开启UserTransaction,此属性应该为true。
#Job执行完毕,JobDataMap更新完(如果是StatefulJob)事务就会提交。默认值是false,可以在job类上使用@ExecuteInJTATransaction注解,
# 以便在各自的job上决定是否开启JTA事务。
org.quartz.scheduler.wrapJobExecutionInUserTransaction = false
#一个scheduler节点允许接收的trigger的最大数,默认是1,这个值越大,定时任务执行的越多,但代价是集群节点之间的不均衡。
org.quartz.scheduler.batchTriggerAcquisitionMaxCount=1- Scheduler线程池配置
java
#============================================================================
# 配置ThreadPool
#============================================================================
# 线程池的实现类(一般使用SimpleThreadPool即可满足几乎所有用户的需求)
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
# 指定线程数,一般设置为1-100直接的整数,根据系统资源配置
org.quartz.threadPool.threadCount = 10
# 设置线程的优先级(可以是Thread.MIN_PRIORITY(即1)和Thread.MAX_PRIORITY(这是10)之间的任何int 。默认值为Thread.NORM_PRIORITY(5)。)
org.quartz.threadPool.threadPriority = 5
#加载任务代码的ClassLoader是否从外部继承
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread= true
#是否设置调度器线程为守护线程
org.quartz.scheduler.makeSchedulerThreadDaemon=true- JobStore作业存储配置
java
#============================================================================
# 配置JobStore
#============================================================================
# JobDataMaps是否都为String类型,默认false
# 若是true的话,便可不用让更复杂的对象以序列化的形式保存到BLOB列中
org.quartz.jobStore.useProperties=false
# 存储相关信息表的前缀,默认QRTZ_
org.quartz.jobStore.tablePrefix = QRTZ_
# 是否加入集群
#是否是应用在集群中,当应用在集群中时必须设置为TRUE,否则会出错。
#如果有多个Quartz实例在用同一套数据库时,必须设置为true。
org.quartz.jobStore.isClustered = true
# 调度实例失效的检查时间间隔 ms
#只用于设置了isClustered为true的时候,设置一个频度(毫秒),用于实例报告给集群中的其他实例。
#这会影响到侦测失败实例的敏捷度。
org.quartz.jobStore.clusterCheckinInterval = 5000
# 当设置为"true"时,此属性告诉Quartz 在非托管JDBC连接上调用setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED)。
org.quartz.jobStore.txIsolationLevelReadCommitted = true
# 数据保存方式为数据库持久化,选择JDBC的存储方式
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
# 数据库代理类,一般org.quartz.impl.jdbcjobstore.StdJDBCDelegate可以满足大部分数据库
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#这个值必须datasource的配置信息
org.quartz.jobStore.dataSource = myDataSource
#最大能忍受的触发超时时间,如果超时则认为"失误"
org.quartz.jobStore.misfireThreshold = 60000
#这是JobStore能处理的错过触发的Trigger的最大数量。处理太多(2打)很快就会导致数据库表被锁定够长的时间,
#这样会妨碍别的(还未错过触发)trigger执行的性能。
org.quartz.jobStore.maxMisfiresToHandleAtATime=20
#设置这个参数为true会告诉Quartz从数据源获取连接后不要调用它的setAutoCommit(false)方法。
#在少数情况下是有用的,比如有一个驱动本来是关闭的,但是又调用这个关闭的方法。但是大部分情况下驱动都要求调用setAutoCommit(false)
org.quartz.jobStore.dontSetAutoCommitFalse=false
#这必须是一个从LOCKS表查询一行并对这行记录加锁的SQL。假设没有设置,默认值如下。
#{0}会在运行期间被前面配置的TABLE_PREFIX所代替
org.quartz.jobStore.selectWithLockSQL=SELECT * FROM {0}LOCKS WHERE LOCK_NAME = ? FOR UPDATE
#值为true时告知Quartz(当使用JobStoreTX或CMT)调用JDBC连接的setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE) 方法。这有助于某些数据库在高负载和长时间事务时锁的超时。
org.quartz.jobStore.txIsolationLevelSerializable=false三.组件介绍
JobDetail介绍
在Quartz中,JobDetail是描述任务(Job)的具体细节的类。它包含了任务的标识、执行类、执行时所需的数据/参数等信息。
以下是JobDetail的一些主要属性:
- name:任务名称,同一个分组下必须是唯一的。
- group:任务分组,用于将任务进行分类,方便管理和调度。
- jobClass:任务执行类,即实现了org.quartz.Job接口的类。它负责实际执行任务任务的逻辑,真正的业务代码执行。
- jobDataMap:任务的数据/参数,可以传递一些额外的数据给任务类,供其使用。
- durability:任务的持久性标志,指示任务是否应该存储在调度器中,即使没有与之关联的触发器。
- requestsRecovery:任务的失败恢复标志,指示任务是否应该在调度器发生故障后恢复执行。
使用JobDetail,可以定义要执行的具体任务的细节,并为任务提供必要的信息。
以下是示例代码,展示如何创建一个JobDetail对象:
java
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("jobName", "jobGroup")
.usingJobData("param1", "value1")
.build();在上述示例中,创建了一个JobDetail对象,指定了任务的执行类为MyJob,名称为"jobName",分组为"jobGroup",并使用了一个名为"param1"的参数
JobDetail 和job 的关系
- 在设计上可以将job 包装成各种各样的 jobDetai,一个Job 可以对应为多个jobDetai,但是一个jobDetai 只能对用某一个job,但是通常在业务开发中 一个job 只创建一个jobDetai 。
- JobDetail是描述任务的具体细节的类,它包含了任务的标识、执行类、执行时所需的数据/参数等信息。它是任务的静态信息。Job是org.quartz.Job接口的实现类,负责实际执行任务任务的逻辑。它是任务的动态逻辑。
- Quartz中,通过将一个JobDetail实例与一个Trigger实例相关联,形成一个任务调度的单元。当触发器触发时,调度器会使用JobDetail中的信息创建一个Job实例,并执行该实例中的任务逻辑。
- JobDetail是任务的定义,而Job是任务的实例。这种设计能够使任务实例具有并发执行的能力。
Trigger介绍
在Quartz中,Trigger是用于定义任务(Job)执行时间的组件。它指定了任务应该何时运行、运行频率和执行规则。
Trigger可以分为以下几种类型:
- SimpleTrigger:简单触发器,用于指定任务在特定时间点触发一次或多次的执行。可以设置触发时间、重复次数、重复间隔等参数。
- CronTrigger:Cron触发器,基于Cron表达式定义触发时间规则。Cron表达式可以更灵活地指定任务的触发时间,如每天的特定时间执行、每周的特定日期执行等。
- CalendarIntervalTrigger:日历间隔触发器,以特定的日历间隔来触发任务的执行。可以指定固定的时间间隔或基于日历规则定义触发时间。
- DailyTimeIntervalTrigger:每日时间间隔触发器,基于特定的时间间隔和每天的时间窗口来触发任务的执行。
通过使用这些不同类型的Trigger,可以灵活地定义任务的触发时间和执行规则。一旦触发器被触发,Quartz调度器将会调度与之相关联的任务(通过JobDetail),并按照预定义的规则执行任务逻辑。
以下是一个示例代码,展示如何创建一个简单触发器:
java
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("triggerName", "triggerGroup")
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(10)
.repeatForever())
.build();在上述示例中,创建了一个简单触发器,设置了触发器的名称为"triggerName",分组为"triggerGroup",开始时间为当前时间,每隔10秒触发一次任务执行,重复执行无限次。
Trigger是Quartz中重要的组件之一,它定义了任务的触发时间和执行规则。通过使用不同类型的触发器,可以根据需求灵活地调度和执行任务。同时,调度器会管理触发器的调度和执行,并自动触发与之关联的相应任务的执行。
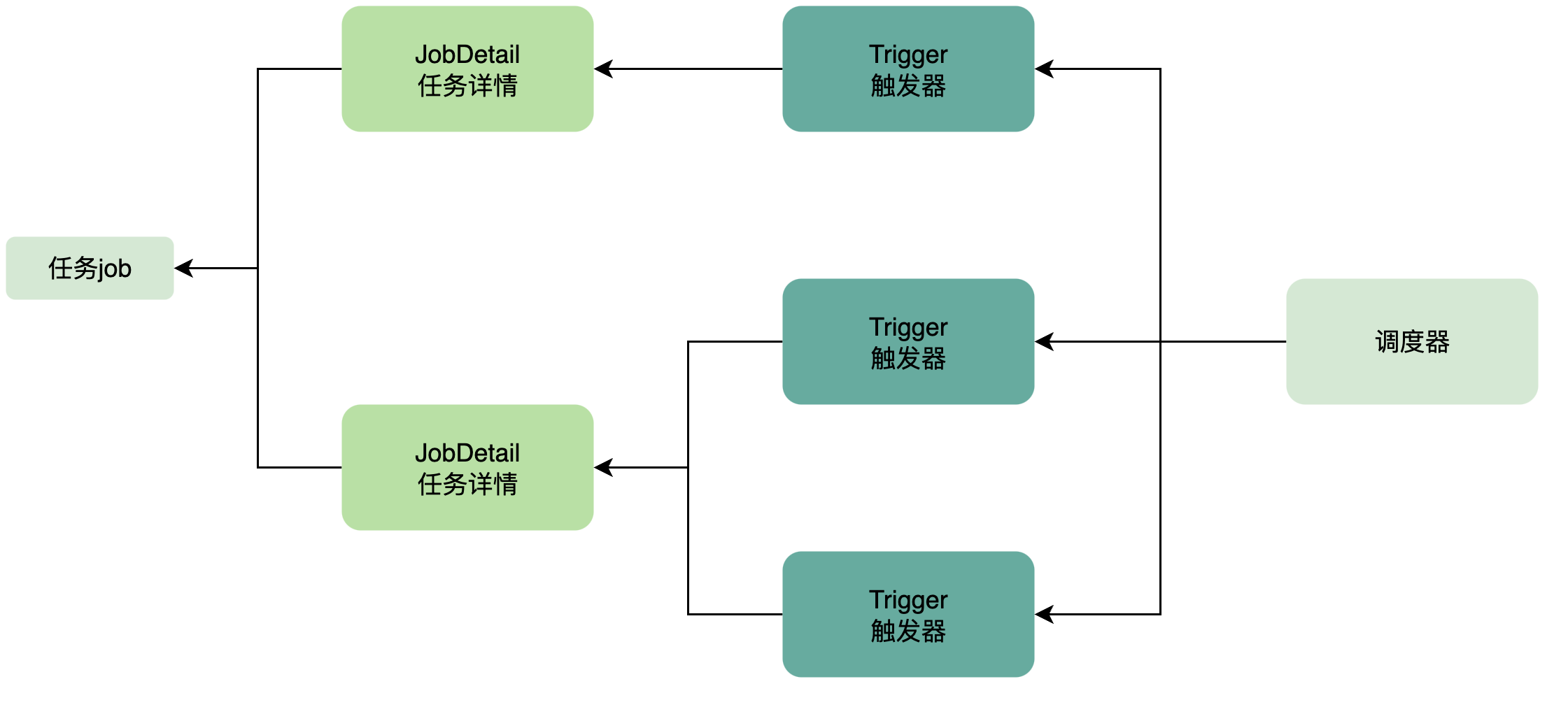
trigger 和jobDetail 的关系
- JobDetail是描述任务的静态信息,包括任务的标识、执行类、执行时所需的数据/参数等信息。Trigger是用于定义任务(Job)执行时间的组件,指定了任务应该何时运行、运行频率和执行规则。
- 在Quartz中,Trigger和JobDetail是密切相关的并且有着父子关系。一个jobDetail 可以被多个trigger 触发
- 在Quartz调度器中,当一个Trigger被触发时,调度器会使用与之关联的JobDetail信息创建一个Job实例,并执行该实例中定义的任务逻辑。这个Job实例是任务的动态实例。一个JobDetail可以有多个关联的Trigger,每个关联的Trigger都会创建一个新的Job实例并并发执行。
- JobDetail是描述任务的静态信息,而Trigger是定义任务触发时间和执行规则的组件。
以下是一个使用Quartz进行调度的简单示例代码:
java
// 创建JobDetail对象
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("myJob", "group1")
.build();
// 创建Trigger对象
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("myTrigger", "group1")
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(10))
.build();
// 创建调度器对象
Scheduler scheduler = new StdSchedulerFactory().getScheduler();
// 将JobDetail对象和Trigger对象关联起来
scheduler.scheduleJob(jobDetail, trigger);
// 启动调度器开始调度任务
scheduler.start();Schedule介绍
在Quartz中,调度(schedule)将一个具体的jobDetail 和trigger 关联起来,安排和管理任务的执行时间和频率。
调度过程包括以下步骤:
- 创建JobDetail对象,描述任务的具体细节,包括任务的标识、执行类、执行时所需的数据/参数等信息。创建Trigger对象,定义任务的触发时间和执行规则,例如简单触发器(SimpleTrigger)、Cron触发器(CronTrigger)等。
- 将JobDetail对象和Trigger对象关联起来,形成任务调度的单元。将任务调度单元通过调度器(Scheduler)的scheduleJob()方法进行调度,即安排任务的执行。调度器会根据Trigger定义的触发时间规则,按照预定的时间表执行任务。当触发时间到达时,调度器会创建一个Job实例,执行任务逻辑。任务执行完毕后,调度器会根据Trigger的定义,继续安排下一次任务的执行,并持续调度任务执行。
- 通过Quartz的调度功能,可以灵活地安排和管理任务的执行时间,实现定时任务和定时调度的需求。可以配置多个JobDetail和Trigger来实现不同的任务调度策略,并通过调度器进行统一管理和执行。
以下是一个使用Quartz进行调度的简单示例代码:
java
// 创建JobDetail对象
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("myJob", "group1")
.build();
// 创建Trigger对象
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("myTrigger", "group1")
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(10))
.build();
// 创建调度器对象
Scheduler scheduler = new StdSchedulerFactory().getScheduler();
// 将JobDetail对象和Trigger对象关联起来
scheduler.scheduleJob(jobDetail, trigger);
// 启动调度器开始调度任务
scheduler.start();在上述示例中,使用Quartz创建了一个任务调度的简单示例。创建了一个JobDetail对象来描述任务细节,并创建一个触发器Trigger来定义任务的触发规则,每10秒执行一次。然后将JobDetail对象和Trigger对象关联起来,并通过调度器调度任务的执行。
SimpleScheduleBuilder(简单调度器)和 CronScheduleBuilder(Cron 调度器)主要有以下区别:
- 时间表达的灵活性:
SimpleScheduleBuilder主要用于设置简单的重复模式,例如每隔固定的时间间隔执行任务,或者在一定次数内重复执行。CronScheduleBuilder基于Cron表达式,能够提供非常灵活和复杂的时间调度规则,可以精确到秒、分钟、小时、日期、月份、星期等,并且可以支持各种复杂的周期性和特定日期时间的组合。
- 复杂程度:
SimpleScheduleBuilder的配置相对简单直观,适合简单的周期性任务。CronScheduleBuilder由于Cron表达式的复杂性,配置可能相对较难理解和编写,需要对Cron表达式的语法有一定的了解。
- 功能丰富度:
CronScheduleBuilder能够实现更丰富的定时需求,比如在特定的月份、星期几、日期等特定条件下执行任务。SimpleScheduleBuilder的功能相对较为基础。
四.注解扩展
非并行执行
@DisallowConcurrentExecution 是否允许并行执行;加上这个注解,同一个任务不能被并行执行:
场景:定时任务每隔 3分钟,退款订单; 每次任务执行时间假如超过了3分钟;则在第二次任务触发时,则可能发生同一个订单重复退款的情况;
此时需要增加@DisallowConcurrentExecution 让其同一个job 不能并行的执行(是否同一个job 通过JobKey 判断,JobKey 包含了job name 和group )

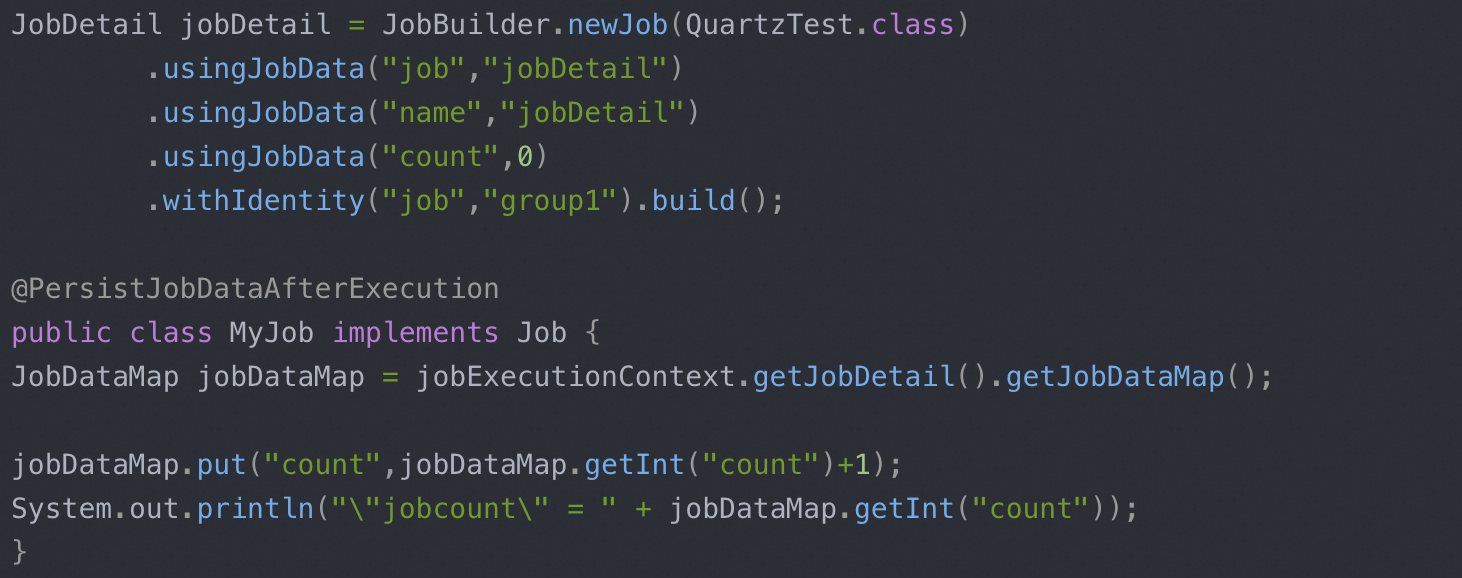
数据持久化
PersistJobDataAfterExecution 对数据持久化,在任务执行完成后持久化作业数据,以便下次再次执行该作业时能够使用上一次执行时修改的数据。
五.任务失火
misfire,中文意思是"失火"。在 quartz 中的含义是:到了任务触发时间,但是任务却没有被触发失火的原因可能是:
- 使用了 @DisallowConcurrentExecution 注解,而且任务的执行时间 >任务间隔
- 线程池满了,没有资源执行任务
- 机器宕机或者人为停止,过段时间恢复运行
SimpleScheduleBuilder 简单调度任务器失火策略:
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY:忽略失火,即不采取任何特殊处理,按照原定计划等待下一次触发。MISFIRE_INSTRUCTION_FIRE_NOW:立即触发执行一次任务。MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_COUNT:立即以当前时间为触发频率执行,并将重复次数设置为剩余的次数。此策略会导致 trigger 忘记原始设置的开始时间和重复次数。MISFIRE_INSTRUCTION_NEXT_WITH_EXISTING_COUNT:不立即触发,等待下次触发频率周期时刻,按照既定的结束时间(finalTime)执行剩余的周期次数,以调度或恢复调度的时刻为基准计算周期频率。即使中间出现暂停(pause),恢复(resume)后保持 finalTime 时间不变。MISFIRE_INSTRUCTION_NEXT_WITH_REMAINING_COUNT:与MISFIRE_INSTRUCTION_NEXT_WITH_EXISTING_COUNT类似,也是等待下次触发频率周期时刻执行剩余次数,但同样保持 finalTime 不变。MISFIRE_INSTRUCTION_NOW_WITH_EXISTING_COUNT(默认):立即以当前时间为触发频率执行,执行至 finalTime 的剩余周期次数,以调度或恢复调度的时刻为基准计算周期频率,调整后的 finalTime 会略大于根据开始时间计算得到的 finalTime 值。MISFIRE_INSTRUCTION_NOW_WITH_REMAINING_COUNT:类似于MISFIRE_INSTRUCTION_NOW_WITH_EXISTING_COUNT,也是立即以当前时间为触发频率执行剩余次数,并根据剩余次数和当前时间计算 finalTime,其值也会略大于根据开始时间计算的 finalTime 值。
CronScheduleBuilder Cron 调度器失火策略:
MISFIRE_INSTRUCTION_DO_NOTHING:不触发立即执行,而是等待下次 Cron 触发频率到达时刻开始按照 Cron 频率依次执行。MISFIRE_INSTRUCTION_FIRE_AND_PROCEED(默认):以当前时间为触发频率立刻触发一次执行,然后按照 Cron 频率依次执行。MISFIRE_INSTRUCTION_IGNORE_MISFIRES:以错过的第一个频率时间立刻开始执行,重做错过的所有频率周期,当下一次触发频率发生时间大于当前时间后,再按照正常的 Cron 频率依次执行。
六.异常处理
任务执行过程中抛出异常,后续任务正常执行,不影响后续的任务调度;如果是已知的异常,可以在catch 中进行一次处理后,重新发起下一次任务的调用;
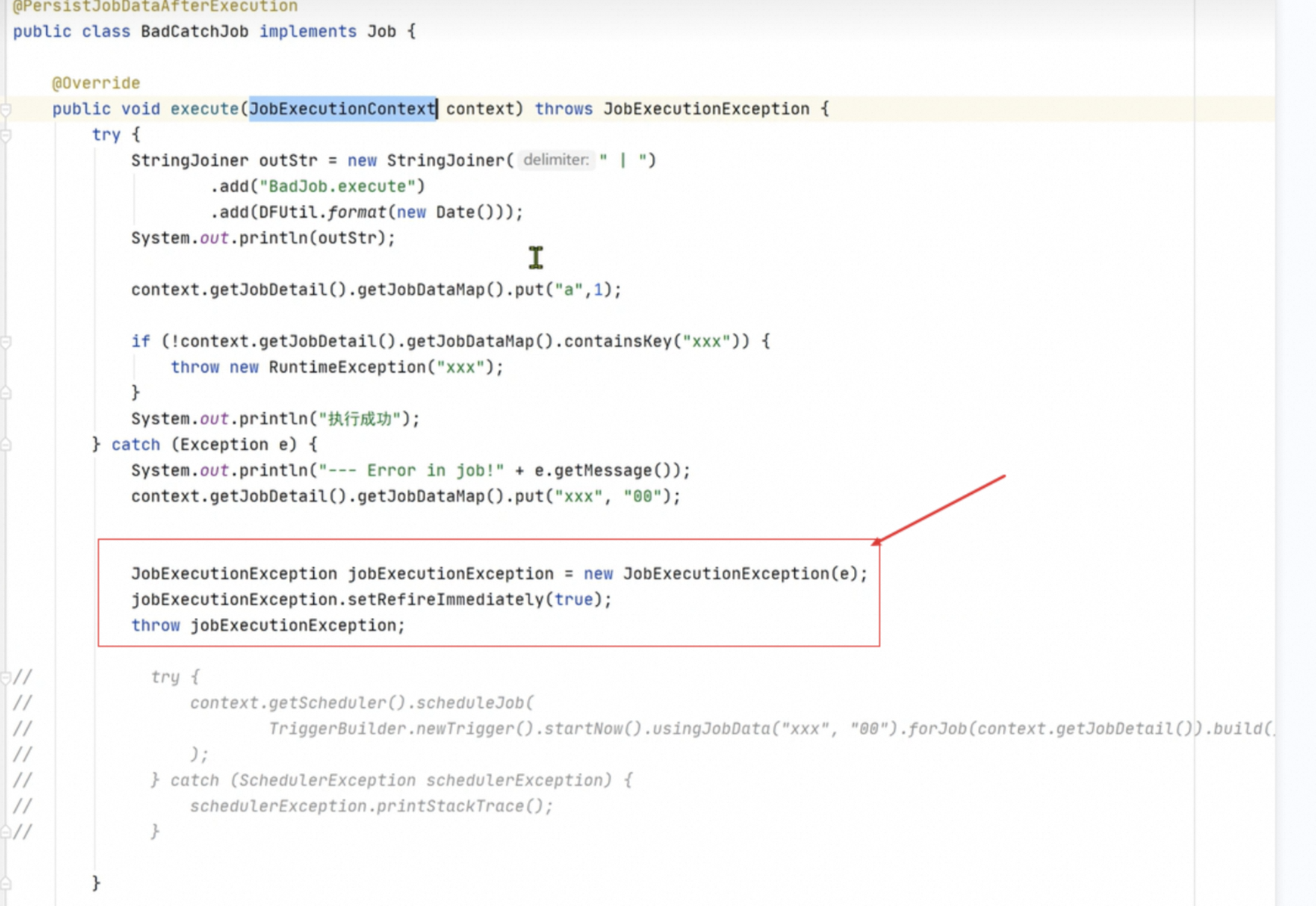
1.任务异常后手动触发补偿本次任务
第一种方式: 重新构建任务后 通过startNow 启动任务

第二种方式:每次 调用JobExecutionContext 都会产生一个新的context:使用同一个context,对job或者trigger中的JobDataMap 进行数据修改;
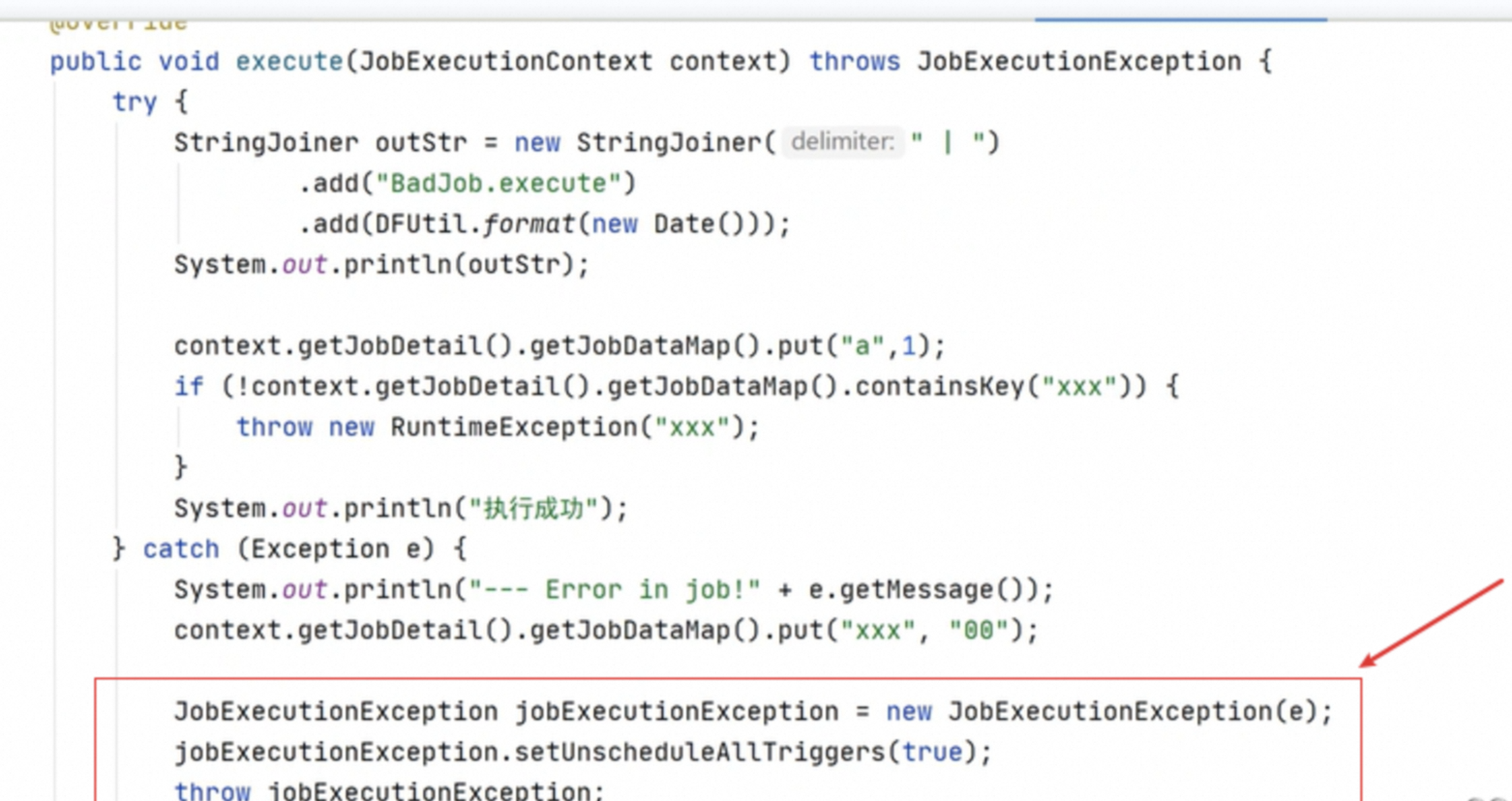
2.任务异常后续改关联任务不在执行
获取到跟当前job 所有的触发器,进行任务的停止执行;
第一种方式:

第二种方式:
七.日期排除
定时任务的执行,需要把某些时间排除在外;
想一下这样的场景,某产业园有家食堂,给 办过会员卡的用户 每天早上10点发一条短信"xxx您好,本店今日供应午餐xxx,欢迎前来就餐"此时就需要将节假日排除在外,quartz 中提供了几种类 来处理:
- CronCalendar 用来排除 给定CronExpression表示的 时间集
- AnnualCalendar 用来排除 年 中的 天
- HolidayCalendar 用来排除 某年 中的 某天 (与 AnnualCalendar 类似,区别是把年考虑进去了)
- MonthlyCalendar用来排除 月 中的 天
- WeeklyCalendar 用来排除 星期 中的 天
- DailyCalendar 用来排除 一天中的 某个时间段 (不能跨天)(可以反转时间段的作用)
用法示例:



