前言
程序员的终极追求是什么?当系统流量大增,用户体验却丝滑依旧?没错!然而,在大量文件传输、数据传递的场景中,传统的"数据搬运"却拖慢了性能。为了解决这一痛点,Linux 推出了 零拷贝 技术,让数据高效传输几乎无需 CPU 操心。今天,我就用最通俗的语言讲解零拷贝的工作原理、常见实现方式和实际应用,彻底帮你搞懂这项技术!
1、传统拷贝:数据搬运的"旧时代"
为了理解零拷贝,我们先看看传统数据传输的工作方式。想象一下,我们需要把一个大文件从硬盘读取后发送到网络上。这听起来很简单,但实际上,传统的数据传输涉及多个步骤并占用大量 CPU 资源。
1.1 一个典型的文件传输过程(没有 DMA 技术):
假设我们要将一个大文件从硬盘读取后发送到网络。以下是传统拷贝方式的详细步骤:
- 读取数据到内核缓冲区 :使用
read()系统调用,数据从硬盘读取到内核缓冲区。此时,CPU 需要协调和执行相关指令来完成这一步。 - 拷贝数据到用户缓冲区 :数据从内核缓冲区被拷贝到用户空间的缓冲区。这一步由
read()调用触发,CPU 完全负责这次数据拷贝。 - 写入数据到内核缓冲区 :通过
write()系统调用,数据从用户缓冲区被再次拷贝回内核缓冲区。CPU 再次介入并负责数据拷贝。 - 传输数据到网卡:最终,内核缓冲区的数据被传输到网卡,发送到网络。如果没有 DMA 技术,CPU 需要拷贝数据至网卡。
1.2 来看个图,更直观点:
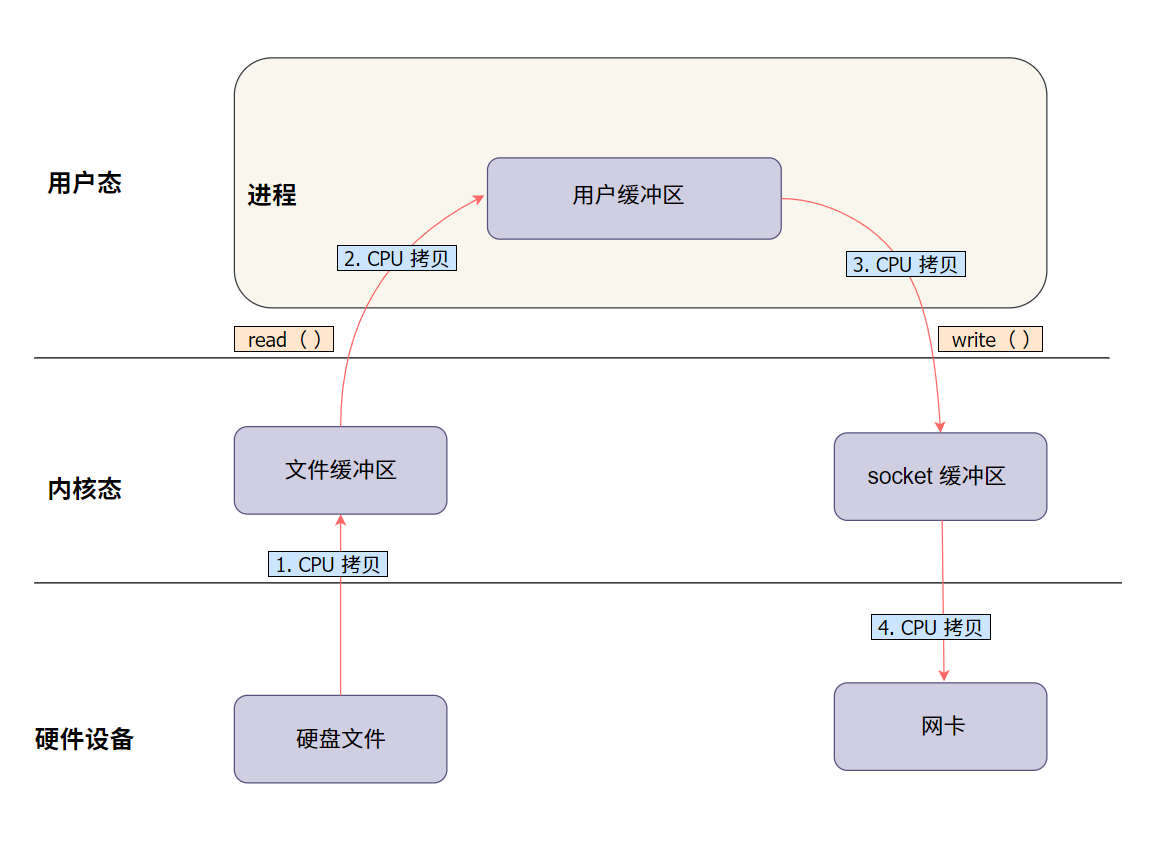
1.3 数据传输的"四次拷贝"
在这个过程中,数据在系统中经历了四次拷贝:
- 硬盘 -> 内核缓冲区(CPU 参与,负责数据读取和传输)
- 内核缓冲区 -> 用户缓冲区 (
read()调用触发,CPU 负责拷贝) - 用户缓冲区 -> 内核缓冲区 (
write()调用触发,CPU 负责拷贝) - 内核缓冲区 -> 网卡(最终发送数据,CPU 参与传输)
1.4 性能瓶颈分析
这种传统拷贝方式的问题显而易见:
- CPU 资源占用高 :每次
read()和write()调用都需要 CPU 进行多次数据拷贝,严重占用 CPU 资源,影响其他任务的执行。 - 内存占用:当数据量较大时,内存使用量明显增加,可能导致系统性能下降。
- 上下文切换开销 :每次
read()和write()调用涉及用户态和内核态的切换,加重了 CPU 的负担。
这些问题在处理大文件或高频率传输时尤为明显,CPU 被迫充当"搬运工",性能因此受到严重限制。那么, 有没有一种方法能够减少 CPU 的"搬运"工作?此时,DMA(Direct Memory Access,直接内存访问)技术登场了。
2、DMA:零拷贝的前奏
DMA(Direct Memory Access,直接内存访问) 是一种让数据在硬盘和内存之间直接传输的技术,不需要 CPU 逐字节参与。简单来说,DMA 是 CPU 的"好帮手",减少了它的工作量。
2.1 DMA 如何帮 CPU?
在传统的数据传输中,CPU 需要亲自把数据从硬盘搬到内存,再送到网络,这很耗费 CPU 资源。而 DMA 的出现让 CPU 可以少干活:
- 硬盘到内核缓冲区:由 DMA 完成,CPU 只需要下指令,DMA 就自动将数据拷贝至内核缓冲区。
- 内核缓冲区到网卡:DMA 也能处理这部分,把数据直接送到网卡,CPU 只需监督整体流程。
有了 DMA,CPU 只需要说一句:"嘿,DMA,把数据从硬盘搬到内存去!" 然后 DMA 控制器就会接过这活,自动把数据从硬盘传到内核缓冲区,CPU 只需要在旁边监督一下。
2.2 有了 DMA , 再来看看数据传输的过程:
为了更好地理解 DMA 在整个数据搬运中的角色,我们用图来说明:
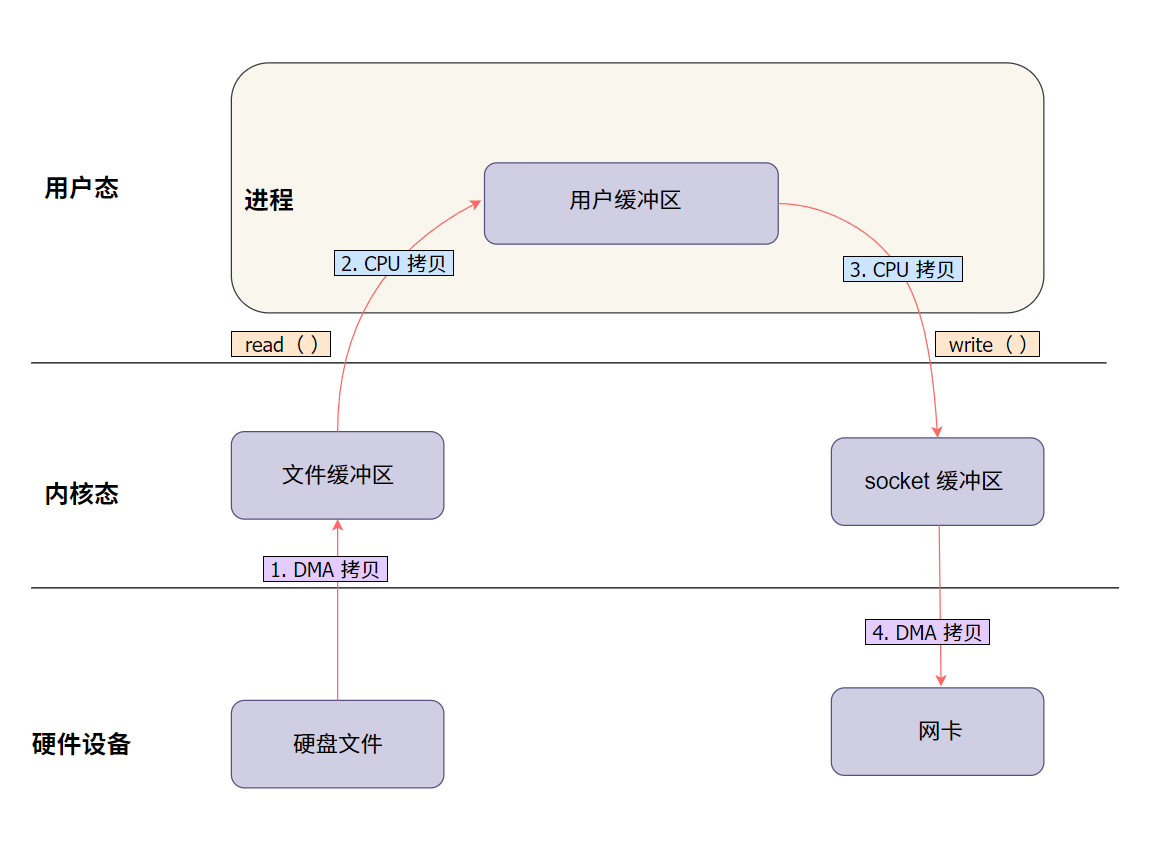
说明:
- DMA 负责硬盘到内核缓冲区和内核到网卡的传输。
- CPU 仍需处理内核和用户缓冲区之间的数据传输。
2.3 哪些步骤仍需 CPU 参与?
虽然 DMA 能帮 CPU 分担一些任务,但它并不能全权代理所有数据拷贝工作。CPU 还是得负责以下两件事:
- 内核缓冲区到用户缓冲区:数据需要被 CPU 拷贝到用户空间供程序使用。
- 用户缓冲区回到内核缓冲区:程序处理完数据后,CPU 还得把数据拷回内核,准备进行后续传输。
就像请了一个帮手,但有些细致活儿还得自己干。所以,在高并发或大文件传输时,CPU 依旧会因为这些拷贝任务感到压力。
2.4 总结一下
总结来说,DMA 确实减轻了 CPU 在数据传输中的负担,让数据从硬盘传输到内核缓冲区和内核缓冲区到网卡时几乎无需 CPU 的参与。然而,DMA 无法彻底解决数据在内核和用户空间之间的拷贝问题。CPU 依然需要进行两次数据搬运,特别是在高并发和大文件传输场景下,这个限制变得尤为突出。
3、零拷贝:让数据"直达"
因此,为了进一步减少 CPU 的参与,提升传输效率,Linux 推出了 零拷贝 技术。这项技术的核心目标是:让数据在内核空间内直接流转,避免在用户空间的冗余拷贝,从而最大限度减少 CPU 的内存拷贝操作,提高系统性能。
接下来,我们来详细看看 Linux 中的几种主要零拷贝实现方式:

注意:Linux 中零拷贝技术的实现需要硬件支持 DMA。
3.1 sendfile:最早的零拷贝方式
sendfile 是最早在 Linux 中引入的零拷贝方式,专为文件传输设计。
3.2 sendfile 的工作流程
- DMA(直接内存访问)直接将文件数据加载到内核缓冲区。
- 数据从内核缓冲区直接进入网络协议栈中的 socket 内核缓冲区。
- 数据通过网络协议栈处理后,通过网卡直接发往网络。
通过 sendfile,整个传输过程 CPU 只需要一次数据拷贝,减少了 CPU 的使用。
3.3 简单图解:
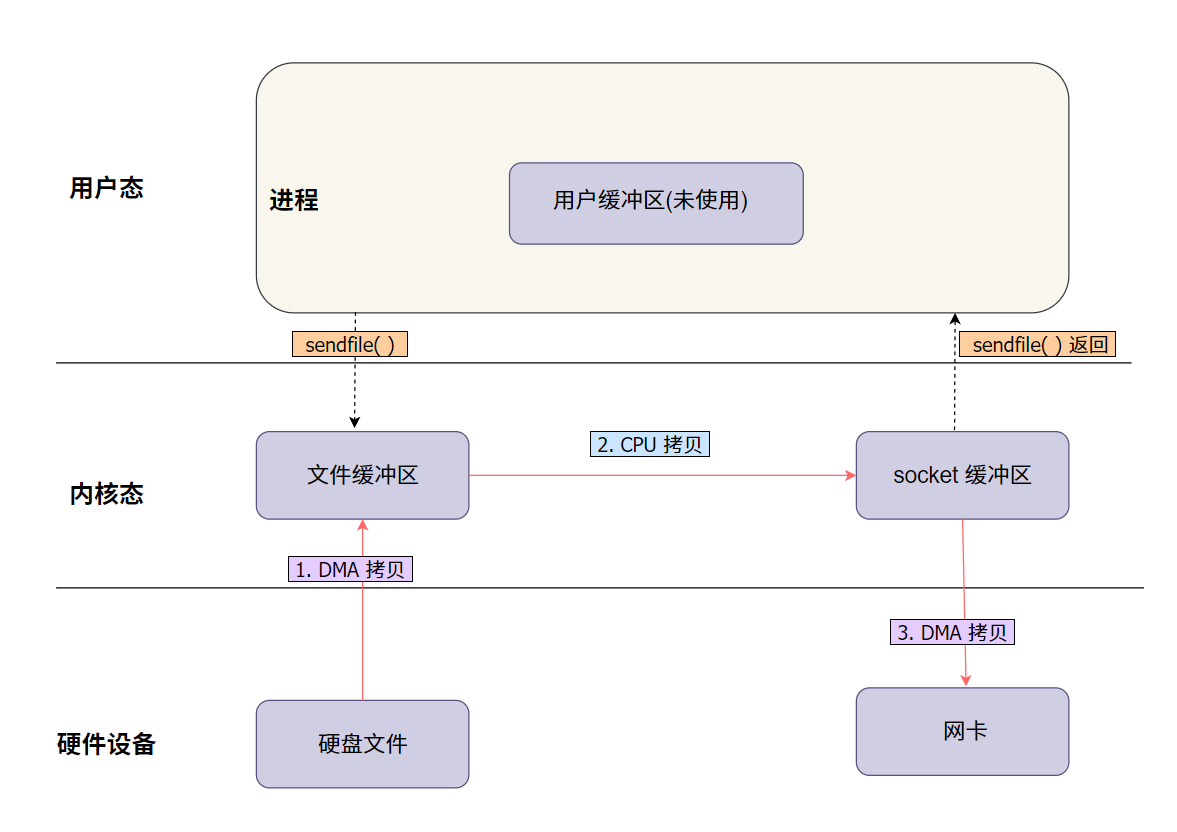
sendfile 图解说明:
- 从硬盘读取数据:文件数据通过 DMA 从硬盘读取,直接加载到内核缓冲区,这个过程不需要 CPU 的参与。
- 拷贝数据至网络协议栈的 socket 缓冲区:数据不进入用户空间,而是从内核缓冲区直接进入网络协议栈中的 socket 缓冲区,在这里经过必要的协议处理(如 TCP/IP 封装)。
- 数据通过网卡发送:数据最终通过网卡直接发往网络。
3.4 sendfile 接口说明
sendfile函数定义如下:
C++
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);out_fd:目标文件描述符,一般是 socket 描述符,用于网络发送。in_fd:源文件描述符,通常是从硬盘读取的文件。offset:偏移量指针,用于指定从文件的哪个位置开始读取。如果为NULL,则从当前偏移位置开始读取。count:要传输的字节数。
返回值是实际传输的字节数,出错时返回 -1,并设置 errno 来指示错误原因。
3.5 简单代码示例
C++
#include <sys/sendfile.h>
int main() {
int input_fd = open("input.txt", O_RDONLY);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
sendfile(client_fd, input_fd, NULL, 1024);
close(input_fd);
close(client_fd);
close(server_fd);
return 0;
}这个例子展示了如何使用 sendfile 将本地文件发送到一个通过网络连接的客户端。只需要调用 sendfile,数据就能从 input_fd 直接传输到 output_fd。
3.6 适用场景
sendfile 主要用于将文件数据直接传输到网络,非常适合需要高效传输大文件的情况,例如文件服务器、流媒体传输、备份系统等。
在传统的数据传输方式中,数据需要经过多个步骤:
- 首先,数据从硬盘读取到内核空间。
- 然后,数据从内核空间拷贝到用户空间。
- 最后,数据从用户空间再拷贝回内核,送到网卡发出去。
总结来说,sendfile 可以让数据传输更加高效,减少 CPU 的干预,特别适合简单的大文件传输场景。然而,如果遇到更复杂的传输需求,比如要在多个不同类型的文件描述符之间移动数据,splice 则提供了一种更加灵活的方法。接下来我们来看看 splice 是如何实现这一点的。
4. splice : 管道式零拷贝
splice 是 Linux 中另一种实现零拷贝的数据传输系统调用,专为在不同类型的文件描述符之间高效地移动数据而设计,适用于在内核中直接传输数据,减少不必要的拷贝。
4.1 splice 的工作流程
- 从文件读取数据 :使用
splice系统调用将数据从输入文件描述符(例如硬盘文件)读取,数据直接通过 DMA(直接内存访问)进入内核缓冲区。 - 传输到网络 socket :随后,
splice继续将内核缓冲区中的数据直接传输到目标网络 socket 的文件描述符中。
整个过程在内核空间内完成,避免了数据从内核空间到用户空间的往返拷贝,大大减少了 CPU 的参与,提高了系统性能。
4.2 简单图解:
和 sendfile 图解类似,只是接口不一样。
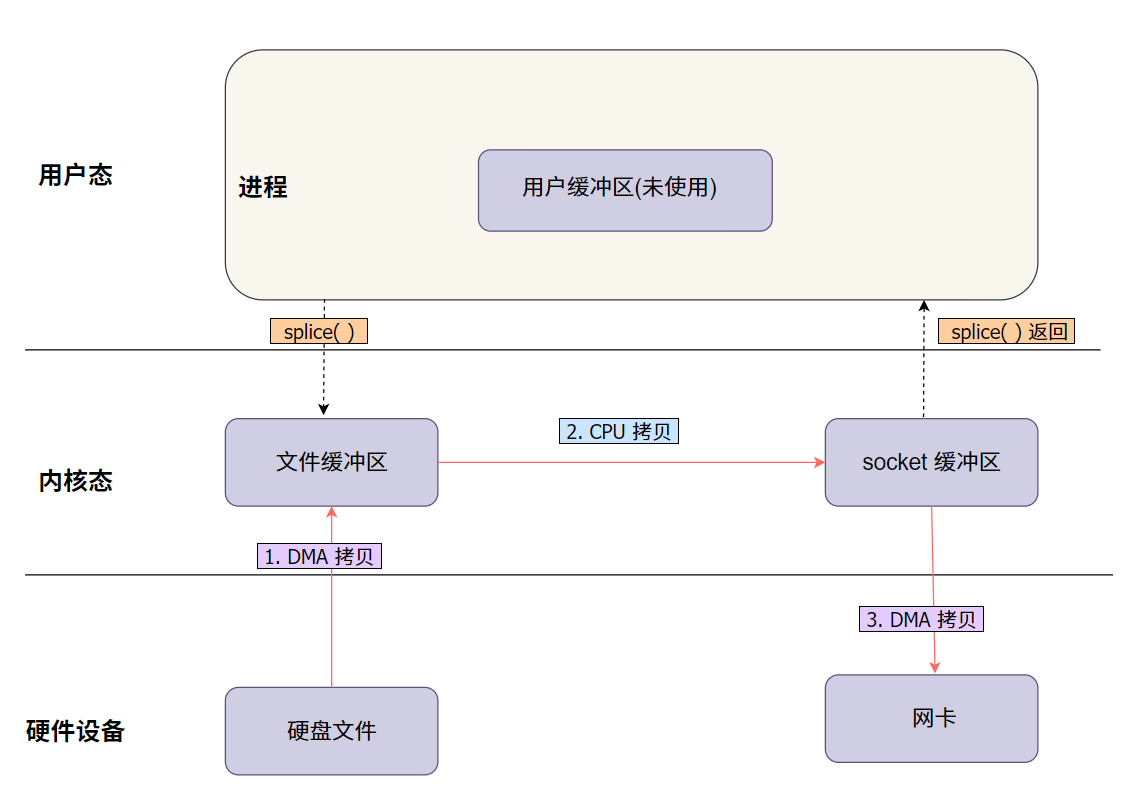
splice 图解说明:
数据通过 splice 从文件描述符传输到网络 socket。数据首先通过 DMA 进入内核缓冲区,然后直接传输到网络 socket,整个过程避免了用户空间的介入,显著减少了 CPU 的拷贝工作。
4.3 splice 接口说明
splice 函数的定义如下:
C++
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);fd_in:源文件描述符,数据从这里读取。off_in:指向源偏移量的指针,如果为NULL,则使用当前偏移量。fd_out:目标文件描述符,数据将被写入这里。off_out:指向目标偏移量的指针,如果为NULL,则使用当前偏移量。len:要传输的字节数。flags:控制行为的标志,例如SPLICE_F_MOVE、SPLICE_F_MORE等。
返回值是实际传输的字节数,出错时返回 -1,并设置 errno 来指示错误原因。
4.4 简单代码示例
C++
int main() {
int input_fd = open("input.txt", O_RDONLY);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
splice(input_fd, NULL, client_fd, NULL, 1024, SPLICE_F_MORE);
close(input_fd);
close(client_fd);
close(server_fd);
return 0;
}这个例子展示了如何使用 splice 将本地文件直接发送到网络 socket,以实现高效的数据传输。
4.5 适用场景
splice 适用于在文件描述符之间进行高效、直接的数据传输,例如从文件到网络 socket 的传输,或在文件、管道和 socket 之间传递数据。在这种情况下,数据在内核空间内完成传输,无需进入用户空间,从而显著减少拷贝次数和 CPU 的参与。另外 splice 特别适合需要灵活数据流动和减少 CPU 负担的场景,例如日志处理、实时数据流处理等。
4.6 sendfile 与 splice 的区别
虽然 sendfile 和 splice 都是 Linux 提供的零拷贝技术,用于高效地在内核空间传输数据,但它们在应用场景和功能上存在一些显著区别:
数据流动方式:
- sendfile:直接将文件中的数据从内核缓冲区传输到 socket 缓冲区,适合文件到网络的传输。适合需要简单高效的文件到网络的传输场景。
- splice:更灵活,可以在任意文件描述符之间进行数据传输,包括文件、管道、socket 等。因此,splice 可以在文件、管道和 socket 之间实现更复杂的数据流转。
适用场景:
- sendfile:主要用于文件到网络的传输,非常适合文件服务器、流媒体等需要高效传输文件的场景。
- splice:更适合复杂的数据流动场景,例如在文件、管道和网络之间需要多步传输或灵活控制数据流向的情况。
灵活性:
- sendfile:用于直接、高效地将文件发送到网络,虽然操作单一,但性能非常高效。
- splice:可以结合管道使用,实现更复杂的数据流向控制,例如先通过管道对数据进行处理,再发送到目标位置。
5. mmap + write:映射式零拷贝
除了以上两种方式,mmap + write 也是一种常见的零拷贝实现方式。这种方式主要是通过内存映射来减少数据拷贝的步骤。
5.1 mmap + write 的工作流程
- 使用
mmap系统调用将文件映射到进程的虚拟地址空间中,这样数据就可以直接在内核空间和用户空间共享,而不需要额外的拷贝操作。 - 使用
write系统调用将映射的内存区域直接写入到目标文件描述符中(比如网络 socket),完成数据传输。
这种方式减少了数据拷贝,提高了效率,适合需要灵活操作数据后再发送的场景。通过这种方式,数据不需要显式地从内核空间拷贝到用户空间,而是通过映射的方式共享,从而减少了不必要的拷贝。
5.2 简单图解:
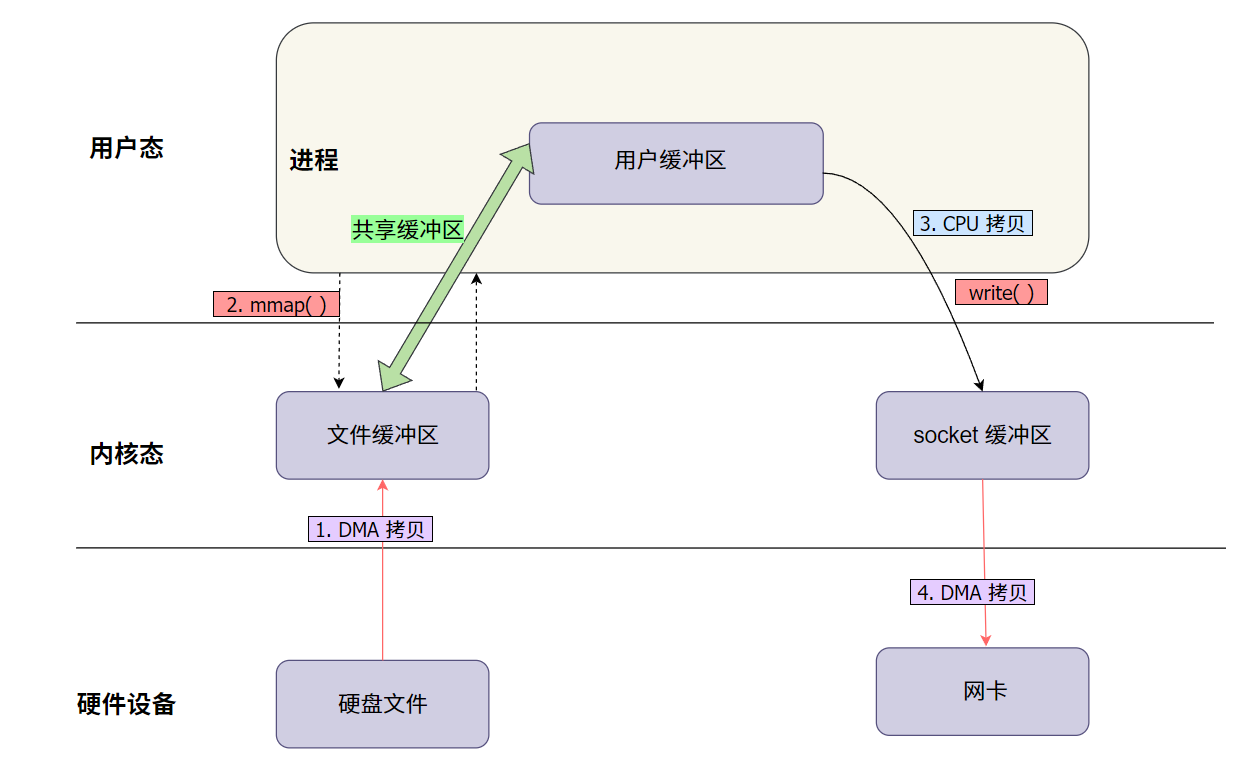
mmap + write 图解说明:
- 使用
mmap将文件数据映射到进程的虚拟地址空间,避免显式的数据拷贝。 - 通过
write直接将映射的内存区域数据发送到目标文件描述符(如网络 socket)。
5.3 mmap 接口说明
mmap 函数的定义如下:
C++
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);addr:指定映射内存的起始地址,通常为NULL由系统决定。length:要映射的内存区域的大小。prot:映射区域的保护标志,例如PROT_READ、PROT_WRITE。flags:影响映射的属性,例如MAP_SHARED、MAP_PRIVATE。fd:文件描述符,指向需要映射的文件。offset:文件中的偏移量,表示从文件的哪个位置开始映射。
返回值为映射内存区域的指针,出错时返回 MAP_FAILED,并设置 errno。
5.4 简单代码示例
C++
int main() {
int input_fd = open("input.txt", O_RDONLY);
struct stat file_stat;
fstat(input_fd, &file_stat);
char *mapped = mmap(NULL, file_stat.st_size, PROT_READ, MAP_PRIVATE, input_fd, 0);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
write(client_fd, mapped, file_stat.st_size);
munmap(mapped, file_stat.st_size);
close(input_fd);
close(client_fd);
close(server_fd);
return 0;
}这个例子展示了如何使用 mmap 将文件映射到内存,然后通过 write 将数据发送到网络连接的客户端。
5.5 适用场景
mmap + write 适用于需要对文件数据进行灵活操作的场景,例如需要在发送数据前进行修改或部分处理。与 sendfile 相比,mmap + write 提供了更大的灵活性,因为它允许在用户态访问数据内容,这对于需要对文件进行预处理的应用场景非常有用,例如压缩、加密或者数据转换等。
然而,这种方式也带来了更多的开销,因为数据需要在用户态和内核态之间进行交互,这会增加系统调用的成本。因此,mmap + write 更适合那些需要在数据传输前进行一些自定义处理的情况,而不太适合纯粹的大文件高效传输。
6. tee:数据复制的零拷贝方式
tee 是 Linux 中的一种零拷贝方式,它可以把一个管道中的数据复制到另一个管道,同时保留原管道中的数据。这意味着数据可以同时被发送到多个目标,而不影响原来的数据流,非常适合日志记录和实时数据分析等需要把同样的数据送往不同地方的场景。
6.1 tee 的工作流程
- 数据复制到另一个管道 :
tee系统调用可以将一个管道中的数据复制到另一个管道,而不改变原有的数据。这意味着数据可以在内核空间中被同时用于不同的目的,而无需经过用户空间的拷贝。
6.2 tee 接口说明
tee 函数的定义如下:
c++
ssize_t tee(int fd_in, int fd_out, size_t len, unsigned int flags);fd_in:源管道文件描述符,数据从这里读取。fd_out:目标管道文件描述符,数据将被写入这里。len:要复制的字节数。flags:控制行为的标志,例如SPLICE_F_NONBLOCK等。
返回值是实际复制的字节数,出错时返回 -1,并设置 errno 来指示错误原因。
6.3 简单代码示例
C++
int main() {
int pipe_fd[2];
pipe(pipe_fd);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
// 使用 tee 复制数据
tee(pipe_fd[0], pipe_fd[1], 1024, 0);
splice(pipe_fd[0], NULL, client_fd, NULL, 1024, SPLICE_F_MORE);
close(pipe_fd[0]);
close(pipe_fd[1]);
close(client_fd);
close(server_fd);
return 0;
}这个例子展示了如何使用 tee 将管道中的数据复制,并通过 splice 将数据发送到网络 socket,从而实现高效的数据传输和复制。
6.4 适用场景
tee 非常适合需要将数据同时发送到多个目标的场景,比如实时数据处理、日志记录等。 通过 tee,可以在内核空间内实现多目标数据复制,提高系统性能,减少 CPU 负担。
总结对比:
下面我将 Linux 的几种零拷贝方式做了总结,方便大家对比学习:
| 方法 | 描述 | 零拷贝类型 | CPU 参与度 | 适用场景 |
|---|---|---|---|---|
| sendfile | 直接将文件数据发送到套接字,无需拷贝到用户空间。 | 完全零拷贝 | 极少,数据直接传输。 | 文件服务器、视频流传输等大文件场景。 |
| splice | 在内核空间内高效地在文件描述符之间传输数据。 | 完全零拷贝 | 极少,完全在内核内。 | 文件、管道与 socket 之间的复杂传输场景。 |
| mmap + write | 将文件映射到内存并使用 write 发送数据,灵活处理数据 | 部分零拷贝 | 中等,需要映射和写入。 | 数据需要处理或修改的场景,如压缩加密。 |
| tee | 将管道中的数据复制到另一个管道,无需消耗原始数据。 | 完全零拷贝 | 极少,数据复制在内核。 | 日志处理、实时数据监控等多目标场景。 |
最后:
希望这篇文章让你对 Linux 的零拷贝技术有了更全面、更清晰的了解!这些技术看起来可能有些复杂,但一旦掌握后,你会发现它们非常简单, 并且在实际项目中非常实用。
如果觉得这篇文章对你有帮助,记得给我点个在看和赞 👍,并分享给有需要的小伙伴吧!也欢迎大家来关注我公众号 「跟着小康学编程」
关注我能学到什么?
-
这里分享 Linux C、C++、Go 开发、计算机基础知识 和 编程面试干货等,内容深入浅出,让技术学习变得轻松有趣。
-
无论您是备战面试,还是想提升编程技能,这里都致力于提供实用、有趣、有深度的技术分享。快来关注,让我们一起成长!
怎么关注我的公众号?
非常简单!扫描下方二维码即可一键关注。

此外,小康最近创建了一个技术交流群,专门用来讨论技术问题和解答读者的疑问。在阅读文章时,如果有不理解的知识点,欢迎大家加入交流群提问。我会尽力为大家解答。期待与大家共同进步!