本文基于 Netty 4.1.112.Final 版本进行讨论
本文是 Netty 内存管理系列的最后一篇文章,在第一篇文章 《聊一聊 Netty 数据搬运工 ByteBuf 体系的设计与实现》 中,笔者以 UnpooledByteBuf 为例,从整个内存管理的外围对 ByteBuf 的整个设计体系进行了详细的拆解剖析,随后在第二篇文章 《谈一谈 Netty 的内存管理 ------ 且看 Netty 如何实现 Java 版的 Jemalloc》 中,笔者又带大家深入到 Netty 内存池的内部,对整个池化内存的管理进行了详细拆解。
不知大家有没有注意到,无论是非池化内存 ------ UnpooledByteBuf 的分配还是池化内存 ------ PooledByteBuf 的分配,最后都会被 Netty 包装成一个 LeakAwareBuffer 返回。
java
public final class UnpooledByteBufAllocator {
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
final ByteBuf buf;
if (PlatformDependent.hasUnsafe()) {
buf = noCleaner ? new InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf(this, initialCapacity, maxCapacity) :
new InstrumentedUnpooledUnsafeDirectByteBuf(this, initialCapacity, maxCapacity);
} else {
buf = new InstrumentedUnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
// 是否启动内存泄露探测,如果启动则额外用 LeakAwareByteBuf 进行包装返回
return disableLeakDetector ? buf : toLeakAwareBuffer(buf);
}
}
java
public class PooledByteBufAllocator {
// 线程本地缓存
private final PoolThreadLocalCache threadCache;
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
// 获取线程本地缓存,线程第一次申请内存的时候会在这里与 PoolArena 进行绑定
PoolThreadCache cache = threadCache.get();
// 获取与当前线程绑定的 PoolArena
PoolArena<ByteBuffer> directArena = cache.directArena;
final ByteBuf buf;
if (directArena != null) {
// 从固定的 PoolArena 中申请内存
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
// 申请非池化内存
buf = PlatformDependent.hasUnsafe() ?
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
// 如果内存泄露探测开启,则用 LeakAwareByteBuf 包装 PooledByteBuf 返回
return toLeakAwareBuffer(buf);
}
}笔者之前曾提到过,相比于 JDK DirectByteBuffer 需要依赖 GC 机制来释放其背后引用的 Native Memory , Netty 更倾向于手动及时释放 DirectByteBuf 。因为 JDK DirectByteBuffer 的释放需要等到 GC 发生,由于 DirectByteBuffer 的对象实例所占的 JVM 堆内存太小了,所以一时很难触发 GC , 这就导致被引用的 Native Memory 的释放有了一定的延迟,严重的情况会越积越多,导致 OOM 。而且也会导致进程中对 DirectByteBuffer 的申请操作有非常大的延迟。
而 Netty 为了避免这些情况的出现,选择在每次使用完之后手动释放 Native Memory ,但是不依赖 JVM 的话,总会有内存泄露的情况,比如在使用完了 ByteBuf 却忘记调用 release() 方法释放。
手动释放虽然及时可控,但是却很容易出现内存泄露。Netty 为了应对内存泄露的发生,从而引入了 LeakAwareBuffer,从命名上就可以看出,LeakAwareBuffer 主要是为了识别出被其包装的 ByteBuf 是否有内存泄露情况的发生。
现在大家是不是对这个 LeakAwareBuffer 非常的好奇,它究竟拥有怎样的魔力,居然能够自动探测内存泄露,但现在我们先把 LeakAwareBuffer 丢在一边,先不用管它,因为它只是 ByteBuf 一个简单的套壳,背后真正核心的是与内存泄露相关的一些探测模型设计,所以笔者决定先从最核心的设计原理开始谈起~~~
1. 内存泄露探测的设计原理
首先我们来看第一个核心的问题,我们究竟该选择一个什么样的时机来对内存泄露进行探测 ?
正在使用的内存肯定不能算是泄露,别管我已经消耗了多么大的内存,但这些内存确实是正在使用的,你不能说我是内存泄露对吧。当我不需要这些内存了,但仍然继续持有着不释放,这种情况,我们才能定义为内存泄露。
所以当内存不再被使用的时候,才是我们进行内存泄露探测的时机,而正在使用的内存,压根就没有内存泄露,自然也不需要进行探测,那么接下来的问题就是,我们如何判断某一块内存是正在被使用的 ? 还是已经不在被使用了 ?
那肯定得靠 GC 啊!对吧。当一个 DirectByteBuf 已经没有任何强引用或者软引用的时候,那就说明它已经不在被使用了,GC 就会回收它。当它还存在强引用或者软引用的时候,说明它还在被使用,那么 GC 就不会回收它。
但是内存泄露探测的功能是在 JVM 之外实现的,JVM 不会意识到我们到底想要干嘛,它只管无脑回收 DirectByteBuf,对于 DirectByteBuf 背后引用的 Native Memory 是否发生泄露,JVM 压根就不会 Care 。
看上去靠 GC 是靠不住了,但如果我们能够在 DirectByteBuf 被 GC 的时候得到一个 JVM 的通知,然后在这个通知中,触发内存泄露的探测,是不是就可以了 ?那我们如何得到这个通知呢 ?
还记不记得笔者在 《以 ZGC 为例,谈一谈 JVM 是如何实现 Reference 语义的》 一文中介绍的 WeakReference 和 PhantomReference 以及 FinalReference ? 它们都可以拿到这个通知。
比如 JDK 中的 DirectByteBuffer ,其背后引用的 Native Memory 的回收需要依靠 Cleaner 机制,而 Cleaner 就是一个 PhantomReference 对象。
java
public class Cleaner extends PhantomReference<Object>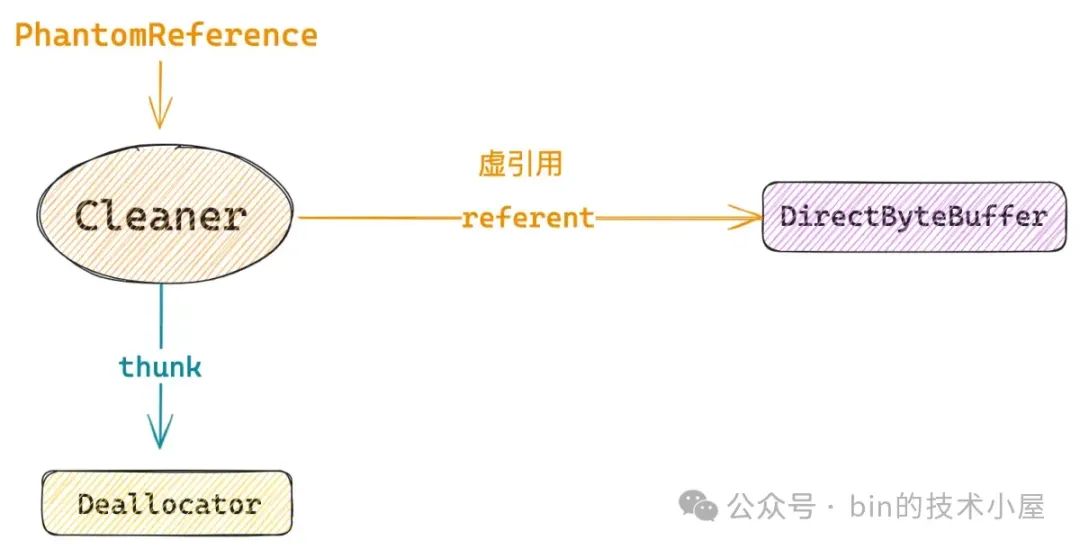
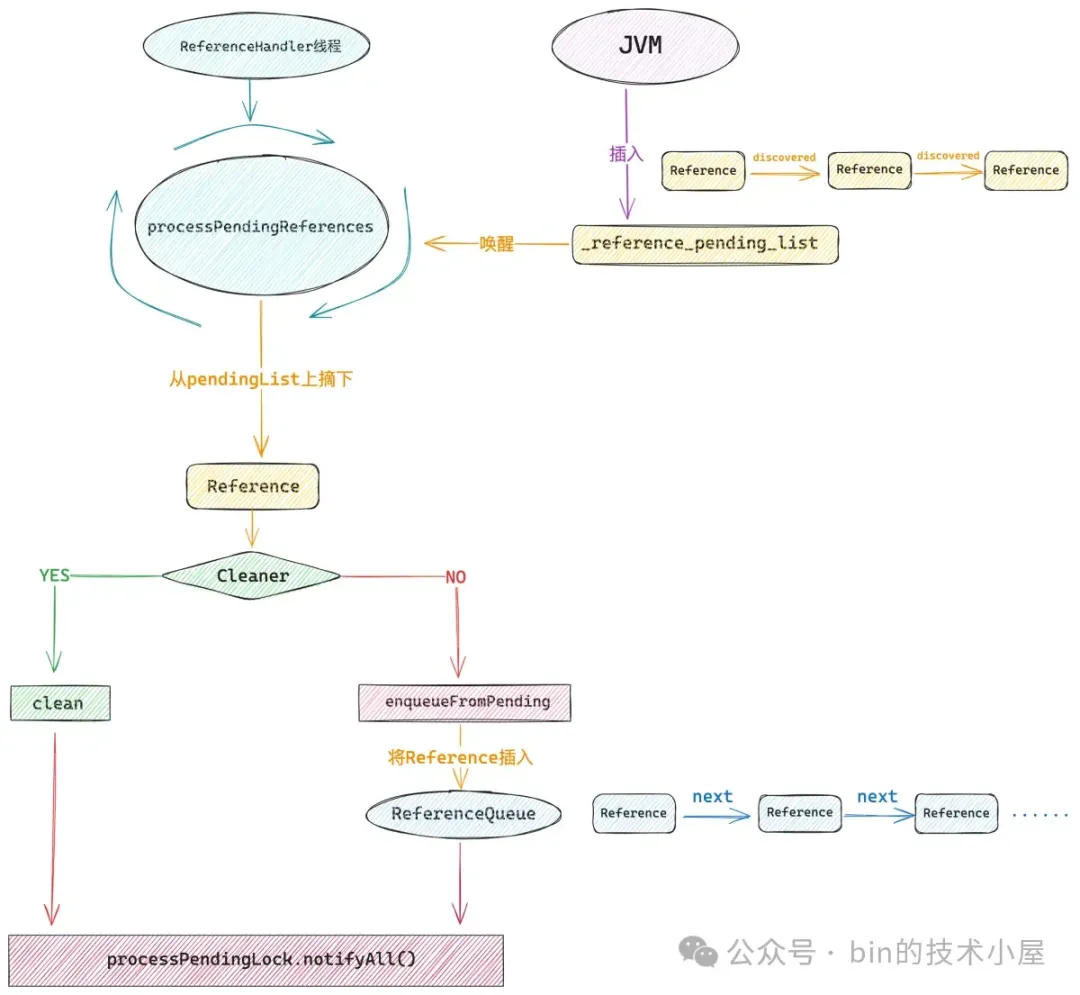
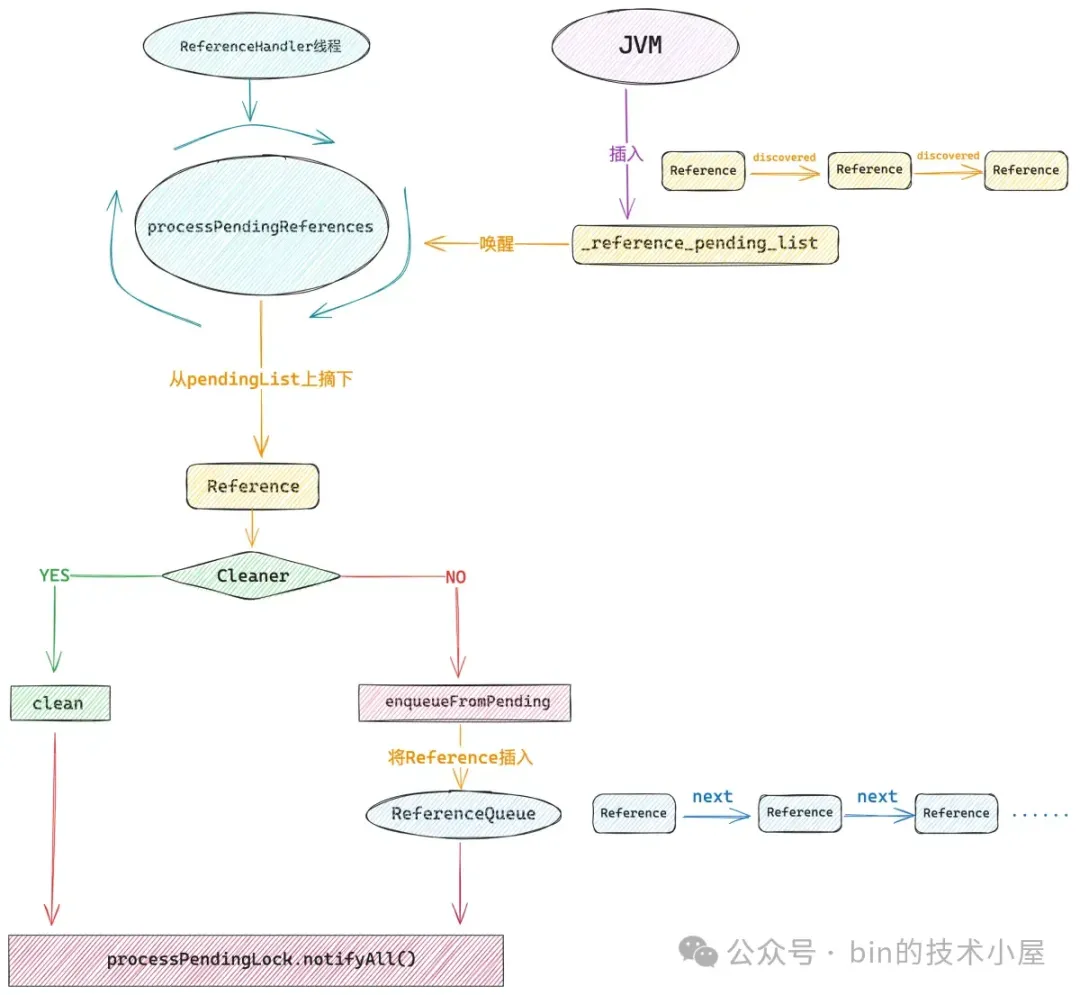
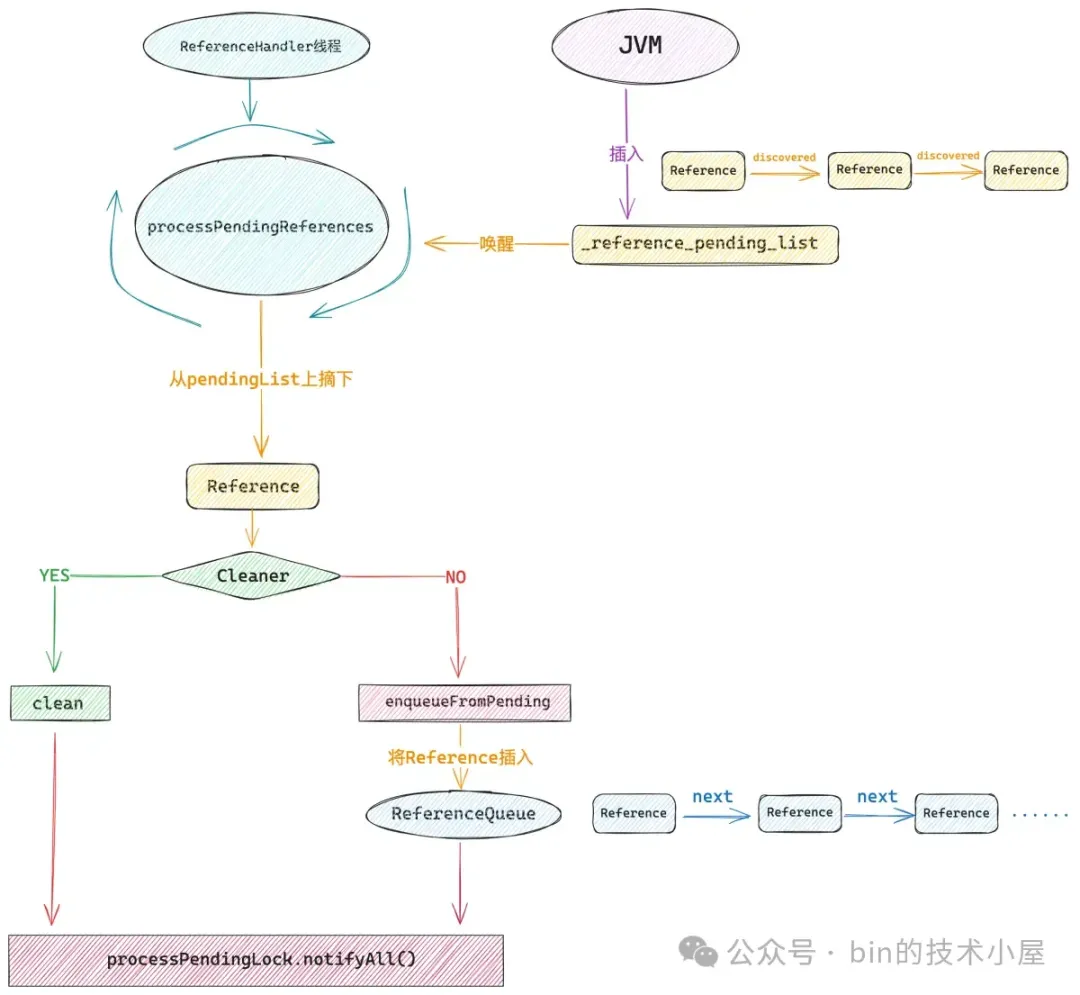
Cleaner 虚引用了 DirectByteBuffer,这样一来当这个 DirectByteBuffer 没有任何强引用或者软引用的时候,也就是不会再被使用了,后面就会被 GC 回收掉,与此同时 JVM 会将它的虚引用 Cleaner 放入 JVM 内部一个叫做 _reference_pending_list 的链表中。
随后 JVM 会唤醒 JDK 中的 1 号线程 ------ ReferenceHandler。
java
Thread handler = new ReferenceHandler(tg, "Reference Handler");
// 设置 ReferenceHandler 线程的优先级为最高优先级
handler.setPriority(Thread.MAX_PRIORITY);
handler.setDaemon(true);ReferenceHandler 线程会从 JVM 的 _reference_pending_list 中挨个将所有的 Cleaner 摘下,调用它的 clean() 方法,最终在 Deallocator 中释放 Native Memory 。
java
private static class Deallocator implements Runnable {
public void run() {
// 底层调用 free 来释放 native memory
UNSAFE.freeMemory(address);
}
}
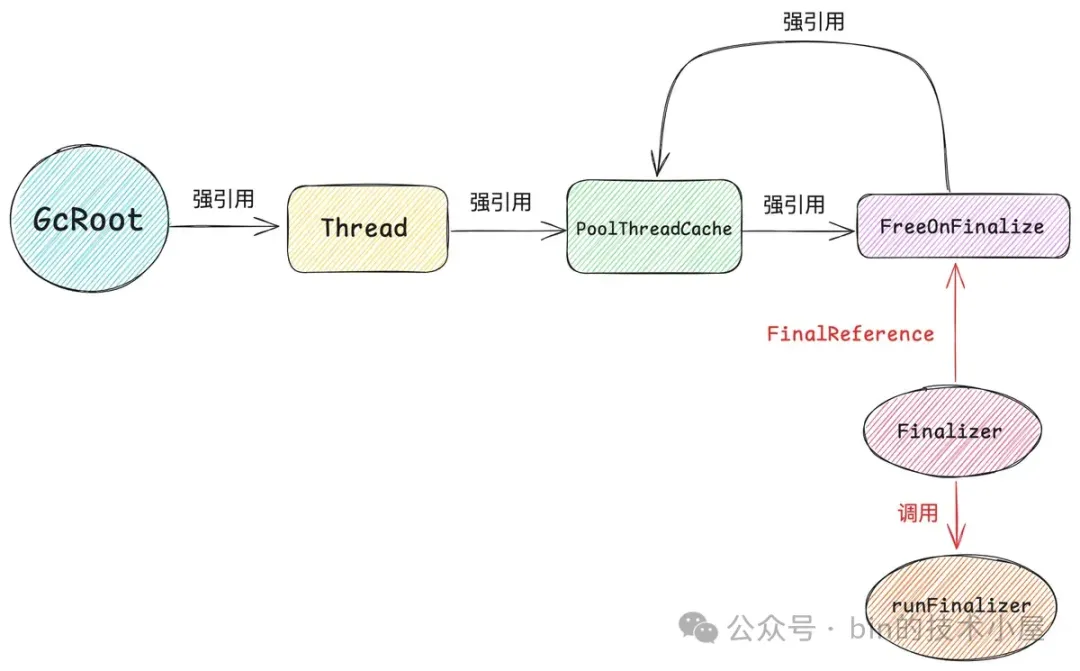
再比如 Netty 内存池中的线程本地缓存 PoolThreadCache,其背后缓存的池化 Native Memory 的回收依赖的是 Finalizer 机制。
java
private static final class FreeOnFinalize {
// 待释放的 PoolThreadCache
private volatile PoolThreadCache cache;
private FreeOnFinalize(PoolThreadCache cache) {
this.cache = cache;
}
@Override
protected void finalize() throws Throwable {
try {
super.finalize();
} finally {
PoolThreadCache cache = this.cache;
this.cache = null;
// 当 FreeOnFinalize 实例要被回收的时候,触发 PoolThreadCache 的释放
if (cache != null) {
cache.free(true);
}
}
}
}FreeOnFinalize 的作用主要就是为了回收 PoolThreadCache , 内部重写了 finalize() 方法,JVM 会为其创建一个 Finalizer 对象(FinalReference 类型),Finalizer 引用了 FreeOnFinalize ,但这种引用关系是一种 FinalReference 类型。
java
final class Finalizer extends FinalReference<Object> {
private static ReferenceQueue<Object> queue = new ReferenceQueue<>();
private Finalizer(Object finalizee) {
// 这里的 finalizee 就是 FreeOnFinalize 对象,被 FinalReference 引用
super(finalizee, queue);
......
}
}
Finalizer 中有一个全局的 ReferenceQueue,这个 ReferenceQueue 非常的重要,因为 JVM 中的 _reference_pending_list 是属于 JVM 内部的,除了 ReferenceHandler 线程,其它普通的 Java 线程是访问不了的,所以我们要想在 JVM 的外部处理这些 Reference(其引用的对象已经被回收),就需要用到一个外部队列,这个外部队列就是 Finalizer 中的 ReferenceQueue。
java
Reference(T referent, ReferenceQueue<? super T> queue) {
// FreeOnFinalize 对象
this.referent = referent;
// Finalizer 中的 ReferenceQueue 实例(全局)
this.queue = (queue == null) ? ReferenceQueue.NULL : queue;
}当线程终结的时候,那么 PoolThreadCache 与 FreeOnFinalize 对象将会被 GC 回收,但由于 FreeOnFinalize 被一个 FinalReference(Finalizer) 引用,所以 JVM 会将 FreeOnFinalize 对象再次复活,由于 FreeOnFinalize 对象也引用了 PoolThreadCache,所以 PoolThreadCache 也会被复活。
随后 JVM 会将这个 Finalizer(FinalReference 对象)放入到内部 _reference_pending_list 中,然后 ReferenceHandler 线程会从 _reference_pending_list 中将 Finalizer 对象挨个摘下,并将其放入到 ReferenceQueue 中。
最后 JDK 中的 2 号线程 ------ FinalizerThread 被唤醒,从 ReferenceQueue 中将收集到的 Finalizer 对象挨个摘下,并执行它的 runFinalizer 方法,最终在 FreeOnFinalize 对象的 finalize() 方法中将 PoolThreadCache 释放。
java
Thread finalizer = new FinalizerThread(tg);
finalizer.setPriority(Thread.MAX_PRIORITY - 2);
finalizer.setDaemon(true);
finalizer.start();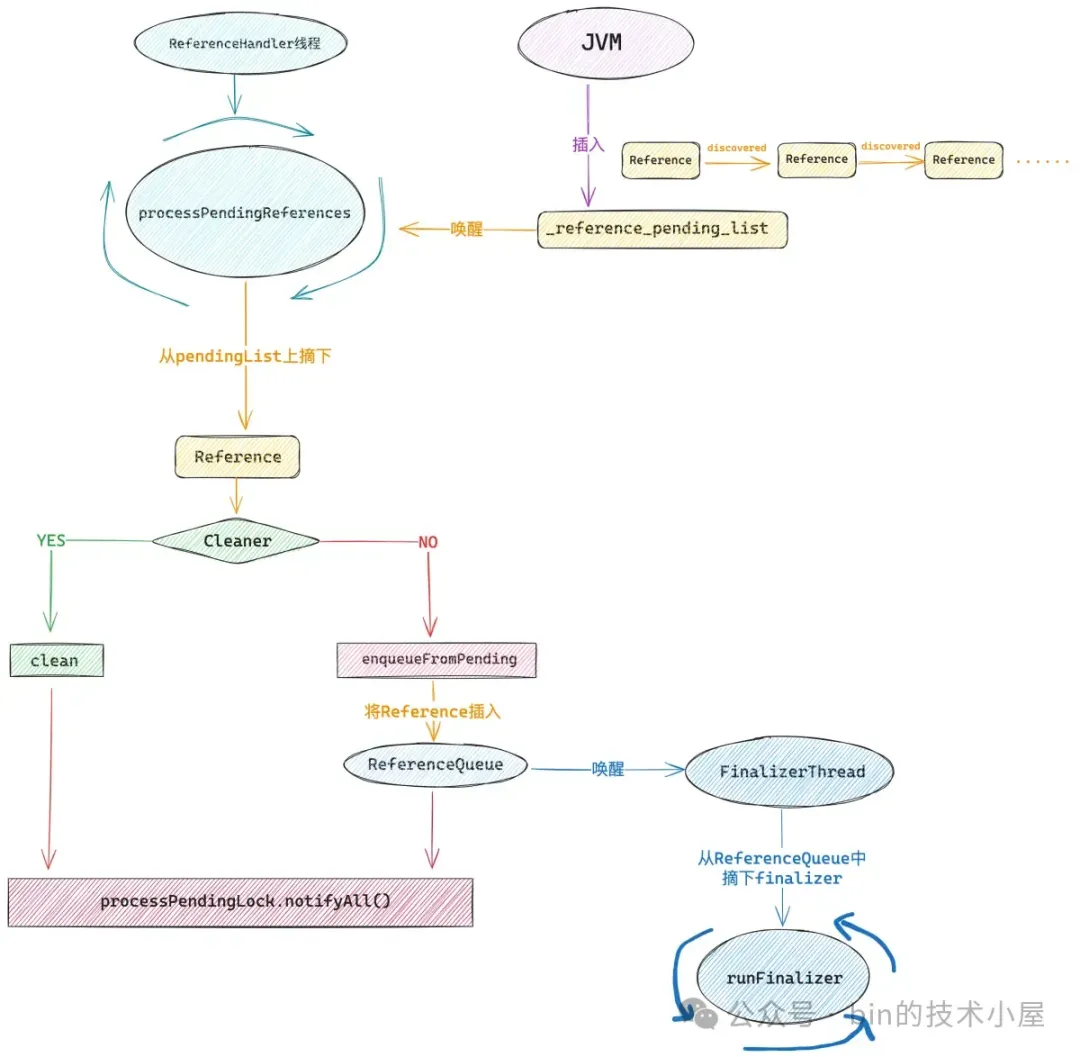
以上就是针对 Native Memory 回收的一些例子实现,同样的道理,关于 Native Memory 的泄露探测也是一样,它们的共同触发时机都是需要等到 DirectByteBuf 不在被使用的时候,也就是被 GC 的时候。
Netty 这里使用了 WeakReference 来获取 DirectByteBuf 被 GC 的通知。
java
final class DefaultResourceLeak<T> extends WeakReference<Object>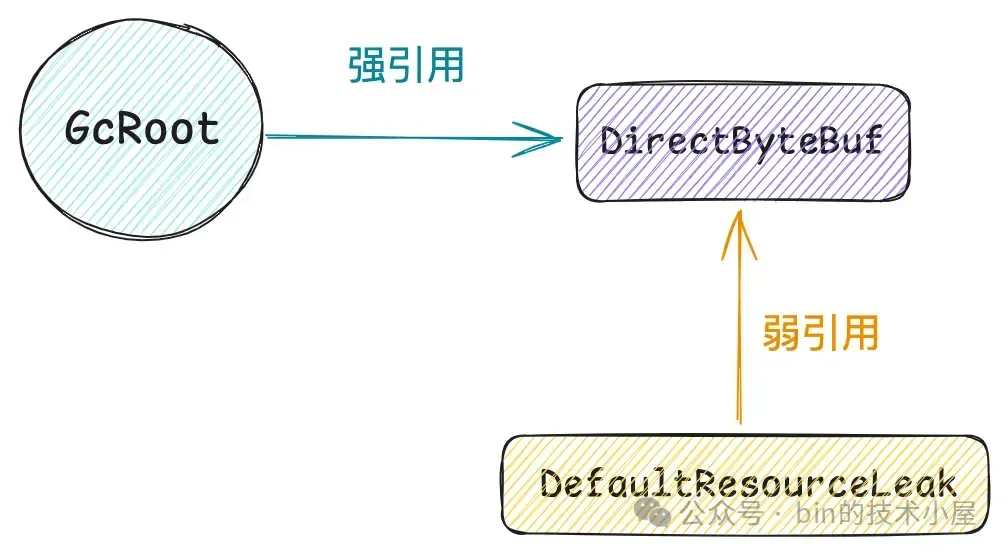
前面笔者提过,_reference_pending_list 是一个 JVM 内部的队列,如果我们想要在 JVM 外部处理 DefaultResourceLeak ,就必须在创建 DefaultResourceLeak 的时候传入一个全局的 ReferenceQueue,Netty 用于内存泄露探测的 ReferenceQueue 定义在 ResourceLeakDetector 中。
java
public class ResourceLeakDetector<T> {
private final ReferenceQueue<Object> refQueue = new ReferenceQueue<Object>();
}有了这个 ReferenceQueue 之后,当 DirectByteBuf 在系统中没有任何强引用或者软引用的时候,那么就只剩下一个弱引用 DefaultResourceLeak 在引用它了,这时 DirectByteBuf 就会被 GC 回收,后面的 WeakReference 处理流程和前面的 PhantomReference , FinalReference 都是一样的。
JVM 会将 DefaultResourceLeak 放入到内部的 _reference_pending_list 中,随后 ReferenceHandler 线程会从 _reference_pending_list 中将 DefaultResourceLeak 摘下,并将它放入到与其关联的 ReferenceQueue 中,这里的 ReferenceQueue 就是 ResourceLeakDetector 中定义的全局 refQueue,会在创建 DefaultResourceLeak 对象的时候传入。
当这个 DefaultResourceLeak 对象被 ReferenceHandler 线程放入到 ReferenceQueue 之后,后面的处理流程就和前面的不一样了。
Cleaner 是由 ReferenceHandler 线程直接进行处理,Finalizer 是由 FinalizerThread 线程进行处理,那这里的 DefaultResourceLeak 又该由哪个线程来处理呢 ?这是我们面临的第二个核心问题。
Cleaner 与 Finalizer 都是 JDK 内部实现的一个机制,所以 JDK 都会配有专门的守护线程来处理它们,而 DefaultResourceLeak 是 Netty 在 JDK 外部实现的内存泄露探测机制,Netty 不可能专门起一个守护线程来处理内存泄露的探测,也没这个必要。
事实上,Netty 中的任何一个线程都可以处理 DefaultResourceLeak,因为内存分配是一个非常频繁的操作,在分配内存的时候顺带探测一下是否有内存泄露的情况发生就可以了,没有必要专门配备一个线程来探测内存泄露。这样资源消耗不仅少,内存泄露探测的还更快更及时一些。
当某一个线程在调用 ByteBufAllocator 申请内存的时候,Netty 就会触发对 ReferenceQueue 的检测,如果队列中包含 DefaultResourceLeak 就将它拿下来检查一下是否有内存泄露发生。那么我们依据什么来判断一个 DirectByteBuf 是否发生内存泄露呢 ?这是我们面临的第三个核心问题。
Netty 为每个 ByteBuf 都维护了一个引用计数 ------ refCnt 。
java
public abstract class AbstractReferenceCountedByteBuf extends AbstractByteBuf {
// 引用计数
private volatile int refCnt;
}我们可以通过 refCnt() 方法来获取 ByteBuf 当前的引用计数 refCnt。当 ByteBuf 在其他上下文中被引用的时候,我们需要通过 retain() 方法将 ByteBuf 的引用计数加 1。每当我们使用完 ByteBuf 的时候就需要手动调用 release() 方法将 ByteBuf 的引用计数减 1 。当引用计数 refCnt 变成 0 的时候,Netty 就会通过 deallocate 方法来释放 ByteBuf 所引用的 Native Memory。
java
public interface ReferenceCounted {
int refCnt();
ReferenceCounted retain();
boolean release();
}于是我们很容易想到能不能在这个引用计数 refCnt 身上做做文章,当一个 DirectByteBuf 被 GC 的时候,如果它的引用计数为 0 ,表示它引用的 Native Memory 已经及时地被释放掉了,不存在内存泄露。如果它的引用计数不为 0 ,那就说明它背后引用的 Native Memory 没有被释放,内存泄露就发生了。
想法很好,但是非常可惜,我们现在已经拿不到 DirectByteBuf 了,它的引用计数更是无从获取,因为它已经被 GC 了,而现在我们只能从 ReferenceQueue 中拿到与 DirectByteBuf 弱引用关联的 DefaultResourceLeak 。那该怎么办呢 ?
我们判断一个 DirectByteBuf 是否存在内存泄露最根本的依据还是要看它的引用计数是否为 0 ,但现在 DirectByteBuf 已经被 GC 了,它的引用计数也获取不到了,但是我们还可以在另一个维度实现 "引用计数是否为 0" 的这层语义 ------ 曲线救国。
如何实现呢 ? 我们还是重新到 Cleaner 和 Finalizer 机制中去找找灵感,在 Cleaner 的内部都会有一个全局的双向链表 ------ first 。
java
public class Cleaner extends PhantomReference<Object>
{
private static Cleaner first = null;
private Cleaner next = null, prev = null;
}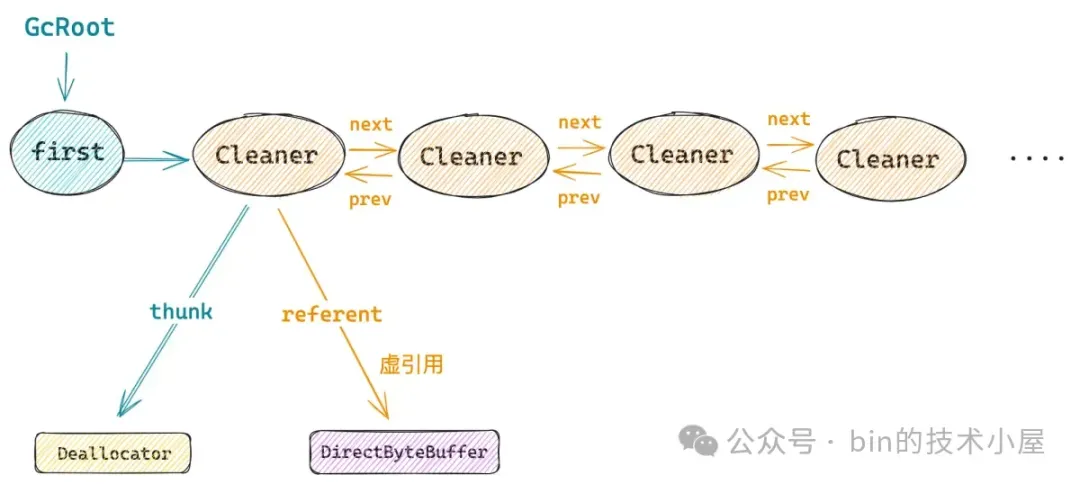
每当一个 Cleaner 对象被创建出来之后,JDK 就会将新的 Cleaner 对象采用头插法插入到该双向链表中。
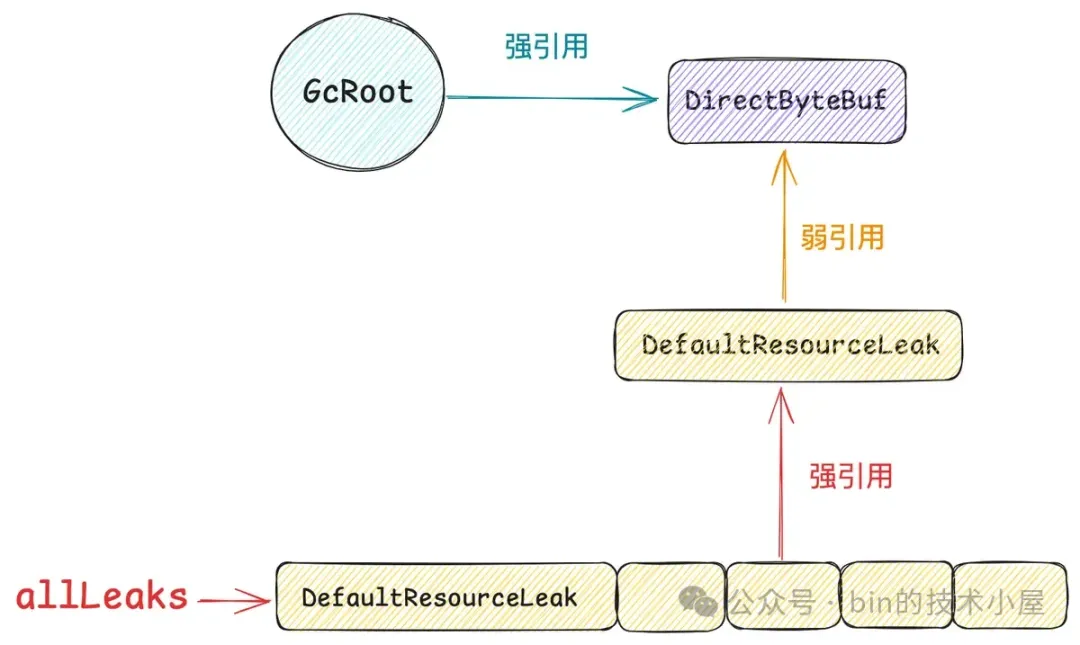
这么做的目的就是为了让系统中的这些 Cleaner 对象始终与 GcRoot 关联,始终保持一条强引用链的存在。
这样一来就可以保证被 Cleaner 对象虚引用的这个 DirectByteBuffer 对象,无论在它被 GC 回收之前还是回收之后,与它关联的这个 Cleaner 对象始终保持活跃不会被 GC 回收掉,因为我们最终要依靠这个 Cleaner 对象来释放 native memory 。
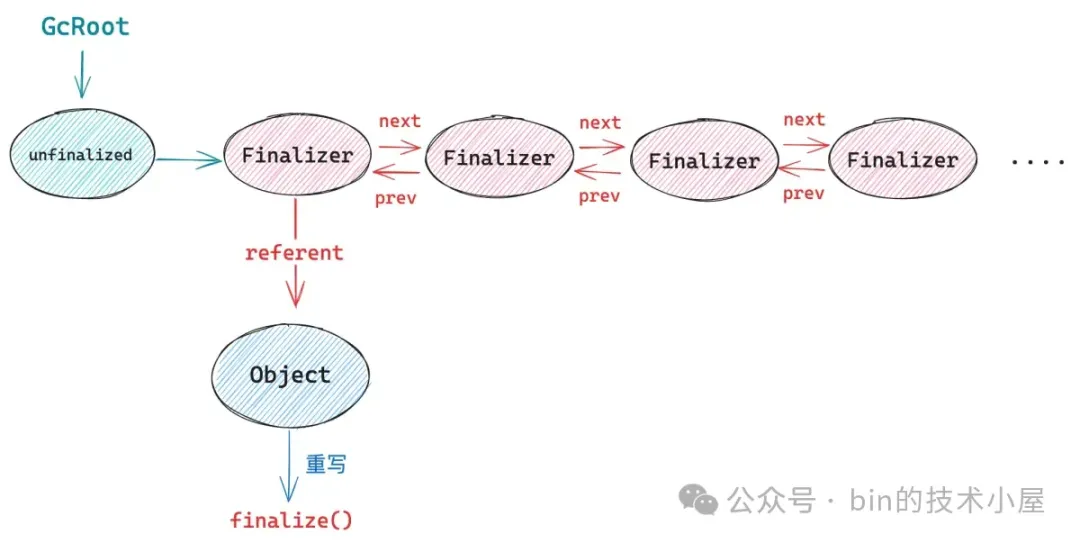
同理,为了确保这些 Finalizer 在执行 finalizee 对象的 finalize() 方法之前不会被 GC 回收掉。Finalizer 的内部也有一个双向链表 ------ unfinalized,用来强引用 JVM 堆中所有的 Finalizer 对象。
java
final class Finalizer extends FinalReference<Object> {
// 双向链表,保存 JVM 堆中所有的 Finalizer 对象,防止 Finalizer 被 GC 掉
private static Finalizer unfinalized = null;
private Finalizer next, prev;
}
一模一样的套路,Netty 为了保证在 DirectByteBuf 被 GC 之前,与其弱引用关联的 DefaultResourceLeak 始终保持活跃不被 GC , 也需要在某一个地方来全局持有 DefaultResourceLeak 的强引用。
但和 Cleaner 与 Finalizer 不同的是,Netty 并没有采用双向链表的结构来持有 DefaultResourceLeak 的强引用,而是选择了 Set 结构。
java
public class ResourceLeakDetector<T> {
private final Set<DefaultResourceLeak<?>> allLeaks =
Collections.newSetFromMap(new ConcurrentHashMap<DefaultResourceLeak<?>, Boolean>());
}
之所以这里采用 Set 结构就是为了实现 "引用计数是否为 0" 的这层语义,那么如何实现呢 ?
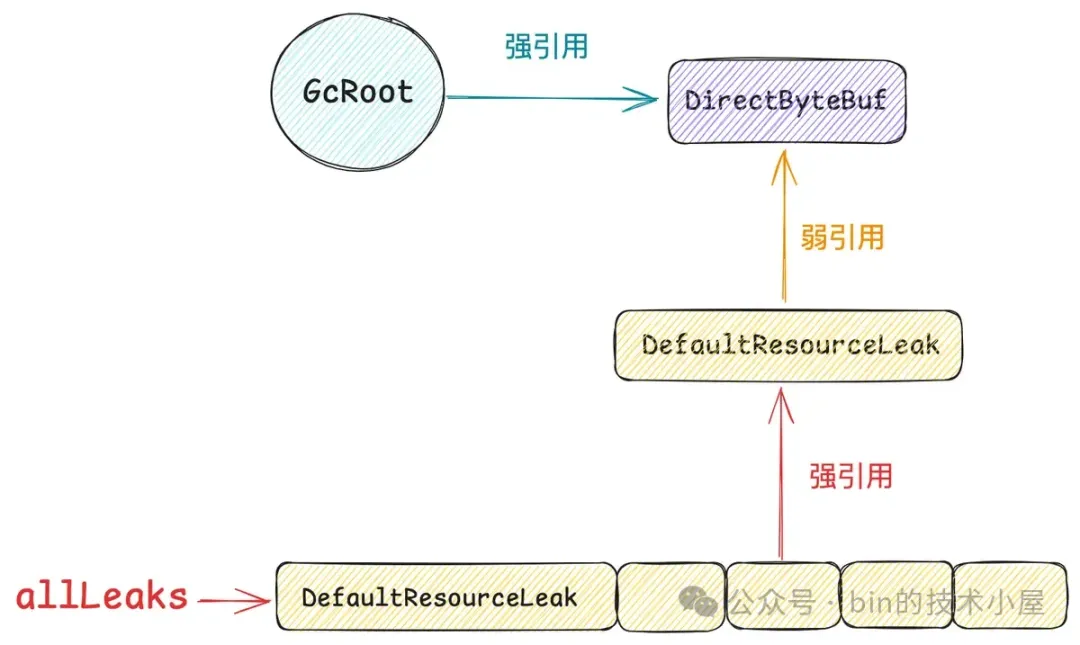
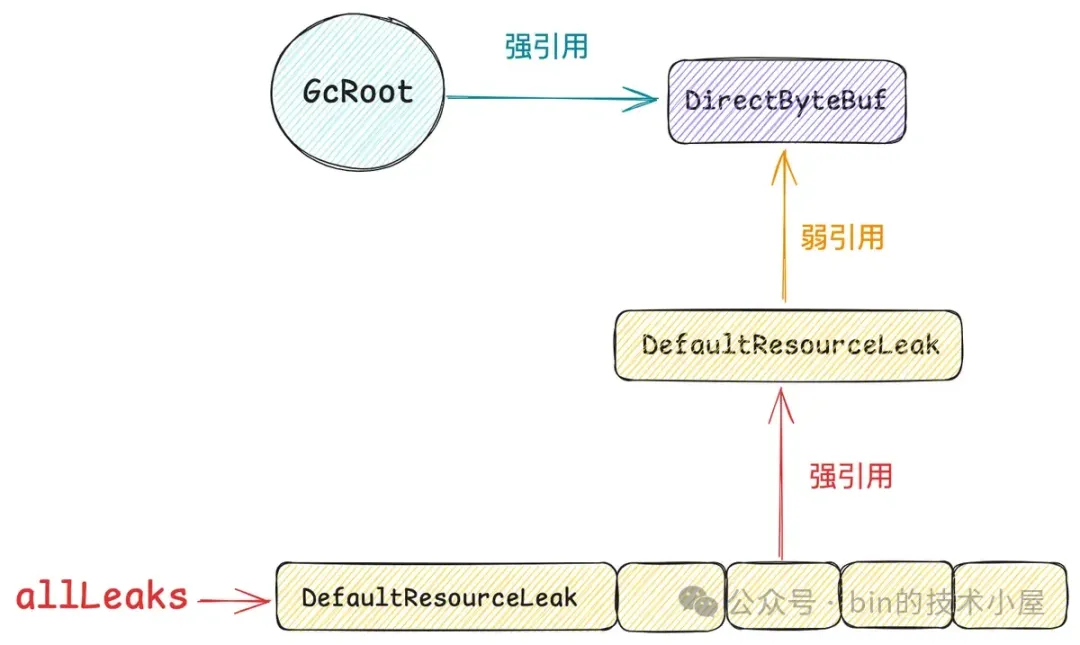
Netty 在分配一个 DirectByteBuf 的同时也会创建一个 DefaultResourceLeak 对象来弱引用这个 DirectByteBuf,随后会将这个 DefaultResourceLeak 对象放入到 allLeaks 集合中。
当我们使用完 DirectByteBuf 并调用 release() 方法释放其 Native Memory 的时候,如果它的引用计数为 0 ,那么 Netty 就会将它的 DefaultResourceLeak 对象从 allLeaks 集合中删除。
如果我们使用完 DirectByteBuf 忘记调用 release() 方法,那么它的引用计数就会一直大于 0 ,同时也意味着它对应的 DefaultResourceLeak 对象会一直停留在 allLeaks 集合中。
从另一个层面上来说,只要是停留在 allLeaks 集合中的 DefaultResourceLeak 对象,那么被其弱引用的 DirectByteBuf 的引用计数一定是大于 0 的。
当这个 DirectByteBuf 给 GC 回收之后,JVM 会将其对应的 DefaultResourceLeak 插入到 _reference_pending_list 中,随后 ReferenceHandler 线程会再一次将 DefaultResourceLeak 对象从 _reference_pending_list 中转移到 ReferenceQueue 中。
当某一个普通的 Java 线程在向 Netty 申请 DirectByteBuf 的时候,这个申请内存的线程就会顺带到 ReferenceQueue 中查看一下是否有 DefaultResourceLeak 对象,如果有,那么就证明被其弱引用的 DirectByteBuf 已经被 GC 了。
紧接着,就会查看这个 DefaultResourceLeak 对象是否仍然停留在 allLeaks 集合中 ,如果还在,那么就说明 DirectByteBuf 背后的 Native Memory 仍然没有被释放,这样一来 Netty 就探测到了内存泄露的发生。
好了,现在我们已经清楚了 Netty 内存泄露探测的核心设计原理,那么下面的内容就很简单了,我们把视角在切换一下,从内存泄露探测的内部在转换到外部,站在应用的角度再来从整体上完整地看一下整个内存泄露探测机制。
2. Netty 的内存泄露探测机制
从总体上来讲,触发内存泄露的探测需要同时满足以下五个条件:
-
应用必须开启内存泄露探测功能。
-
必须要等到 ByteBuf 被 GC 之后,内存泄露才能探测的到,如果 GC 一直没有触发,那么即使是 ByteBuf 没有任何强引用或者软引用了,内存泄露的探测也将无从谈起。
-
当 GC 发生之后,必须是要等到下一次分配内存的时候,才会触发内存泄露的探测。如果没有内存申请的行为发生,那么内存泄露的探测也不会发生。
-
Netty 并不会探测每一个 ByteBuf 的泄露情况,而是根据一定的采样间隔,进行采样探测。所以要想触发内存泄露的探测,还需要达到一定的采样间隔。
-
应用的日志级别必须开启
Error级别,因为内存泄露的报告,Netty 是以Error级别的日志打印出来的,如果日志级别在Error以下,那么内存泄露的报告则无法输出。
除此之外,Netty 还为内存泄露的探测设置了四种级别:
java
public enum Level {
DISABLED,
SIMPLE,
ADVANCED,
PARANOID;
}我们可以通过 JVM 参数 -Dio.netty.leakDetection.level 为应用设置不同的探测级别,其中 DISABLED 表示禁用内存泄露探测,因为内存泄露探测开启之后,应用对于 ByteBuf 的访问链路会变长,而且 Netty 需要记录 ByteBuf 的创建位置堆栈,以及访问链路堆栈,这样在内存泄露报告中,我们才可以清楚的知道泄露的 ByteBuf 是在哪里创建的,又是在哪里泄露的,它的访问路径有哪些。
而报告中的每一个堆栈在内存中占用 2K 大小,所以内存消耗还是非常可观的,所以笔者一般建议在生产环境中,要将 Netty 的内存泄露探测关闭掉。而在测试环境中,则仍然开启内存泄露探测。
当内存泄露探测开启之后,Netty 为我们提供了三种不同的探测级别,级别越高,消耗越大,信息也越详细。第一种探测级别是 SIMPLE , 这也是 Netty 默认的探测级别。
SIMPLE 级别下,Netty 并不会探测每一个 ByteBuf 的泄露情况,而是选择进行采样探测,默认的采样间隔是 128 。
java
public class ResourceLeakDetector<T> {
// 采样间隔,默认 128
static final int SAMPLING_INTERVAL;
private static final String PROP_SAMPLING_INTERVAL = "io.netty.leakDetection.samplingInterval";
private static final int DEFAULT_SAMPLING_INTERVAL = 128;
SAMPLING_INTERVAL = SystemPropertyUtil.getInt(PROP_SAMPLING_INTERVAL, DEFAULT_SAMPLING_INTERVAL);
}我们可以通过 JVM 参数 -Dio.netty.leakDetection.samplingInterval 来设置内存泄露探测的采样间隔。那么 Netty 如何根据这个采样间隔来决定到底为哪一个具体的 ByteBuf 探测内存泄露呢 ?
事实上,这个探测频率的实现也很简单,在每一次内存申请之后,Netty 都会生成 [ 0 , samplingInterval ) 之间的一个随机数,如果这个随机数是 0 ,Netty 将会为本次申请到的 ByteBuf 进行内存泄露探测,如果这个随机数不为 0 ,Netty 将放弃探测。
java
PlatformDependent.threadLocalRandom().nextInt(samplingInterval) == 0从效果上来看,就是每申请 samplingInterval 个 ByteBuf , Netty 就会触发一次内存泄露的探测。
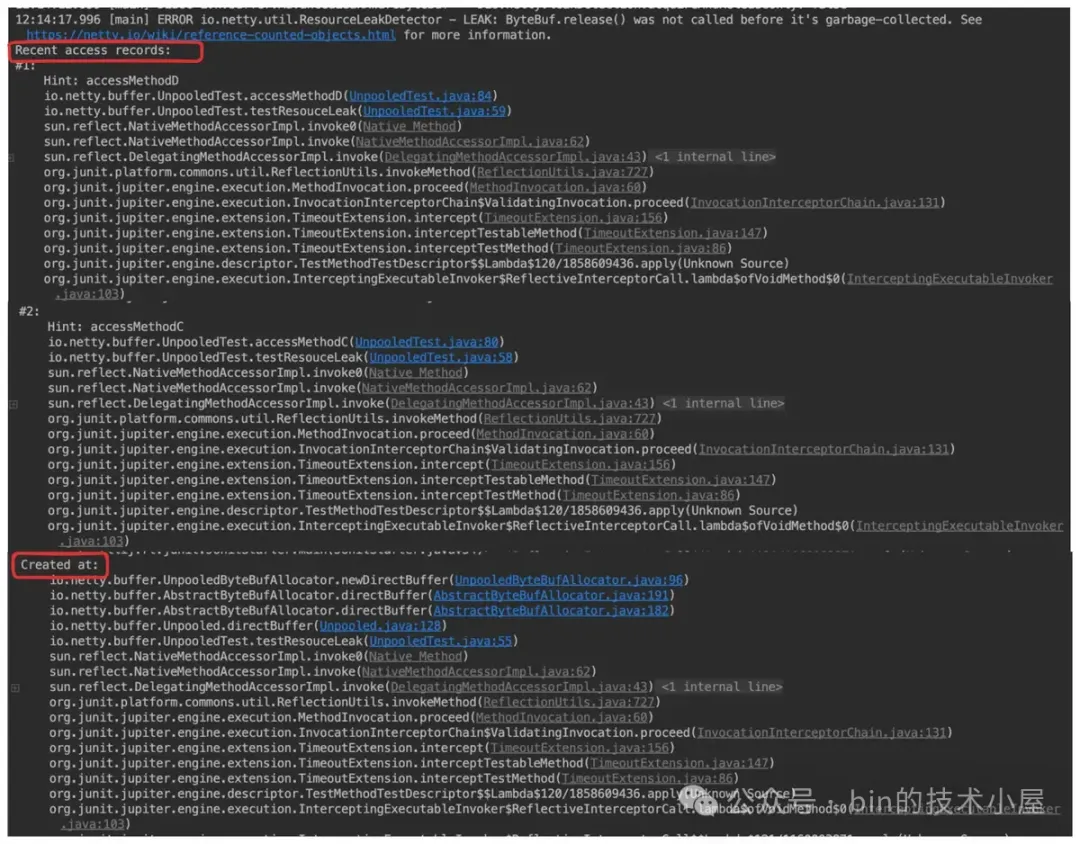
除了受到这个采用频率的限制之外,SIMPLE 级别下的内存泄露报告信息是最少的,只会包含 ByteBuf 的创建位置,后面针对 ByteBuf 的访问堆栈信息 Netty 就不会跟踪了,也就是日志中的 Recent access records: 信息,在 SIMPLE 级别下是没有的。
ADVANCED 级别和 SIMPLE 级别一样,在这两种探测级别下,Netty 都会选择进行采样探测,而不是为每一个 ByteBuf 进行探测,同样都会受到采样频率的限制。
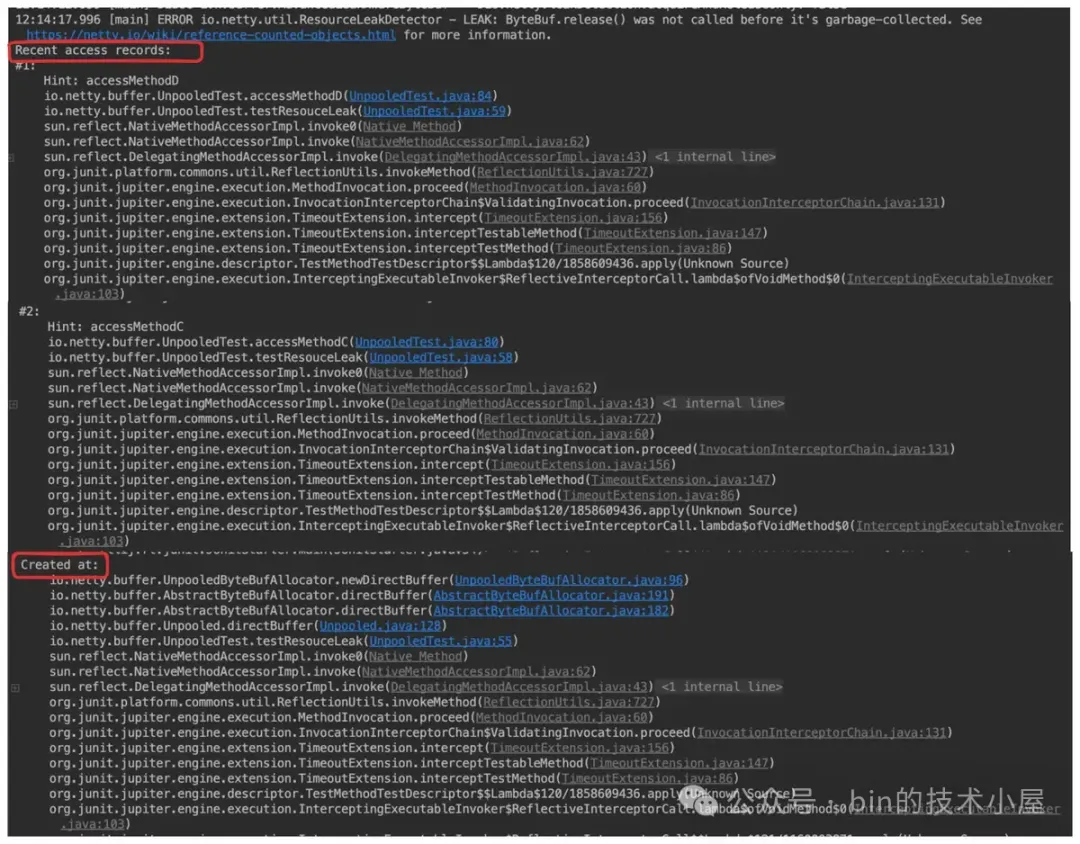
那么 ADVANCED 究竟比 SIMPLE 高级在哪里呢 ?SIMPLE 级别只会报告泄露的 ByteBuf 是在哪里创建的, ADVANCED 级别则除了泄露 ByteBuf 的创建位置之外,还会跟踪 ByteBuf 的每一次访问堆栈,也就是下面内存泄露报告日志中的 Recent access records 相关信息。
前面笔者也提过,追踪 ByteBuf 的访问堆栈是需要消耗非常可观的内存的,对于 ByteBuf 的每一次访问堆栈,如果要记录的话,每个堆栈占用 2K 的内存,堆栈信息 Netty 会记录在一个 TraceRecord 结构中。
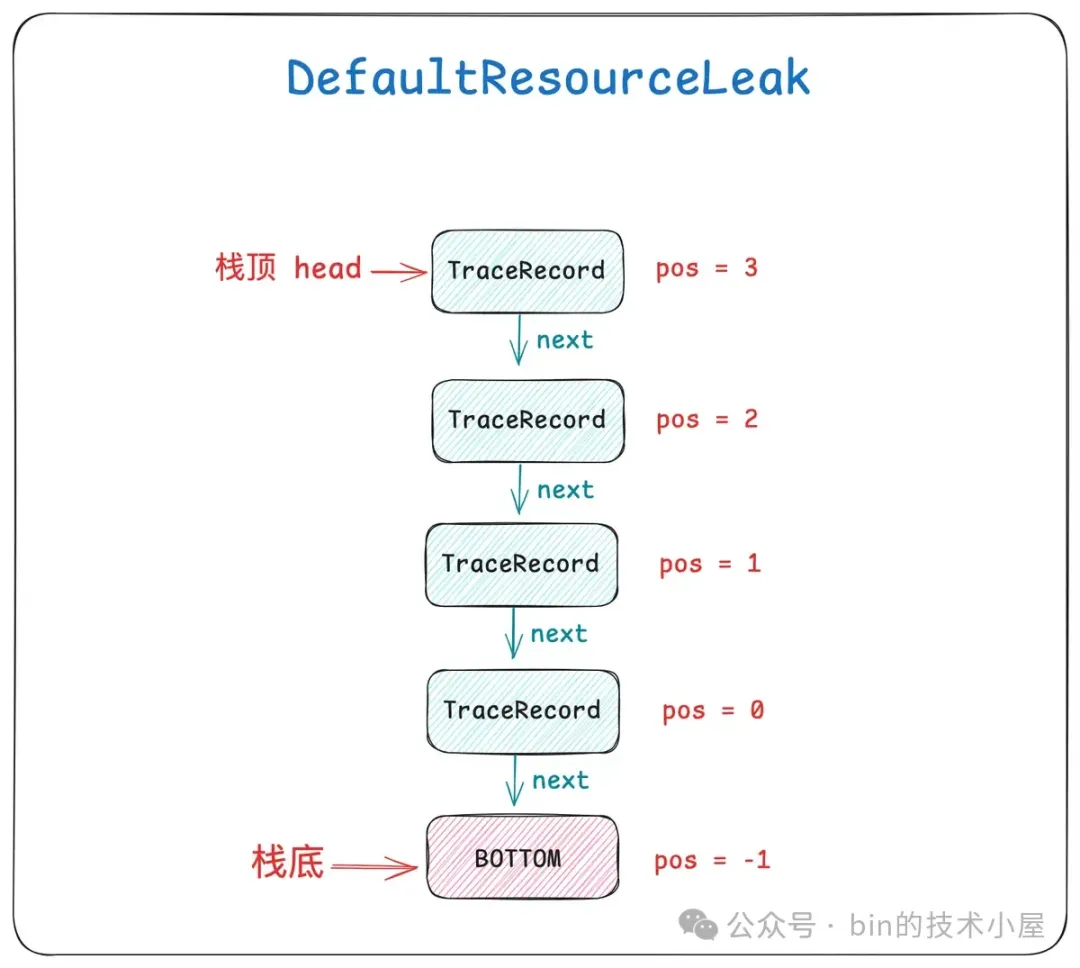
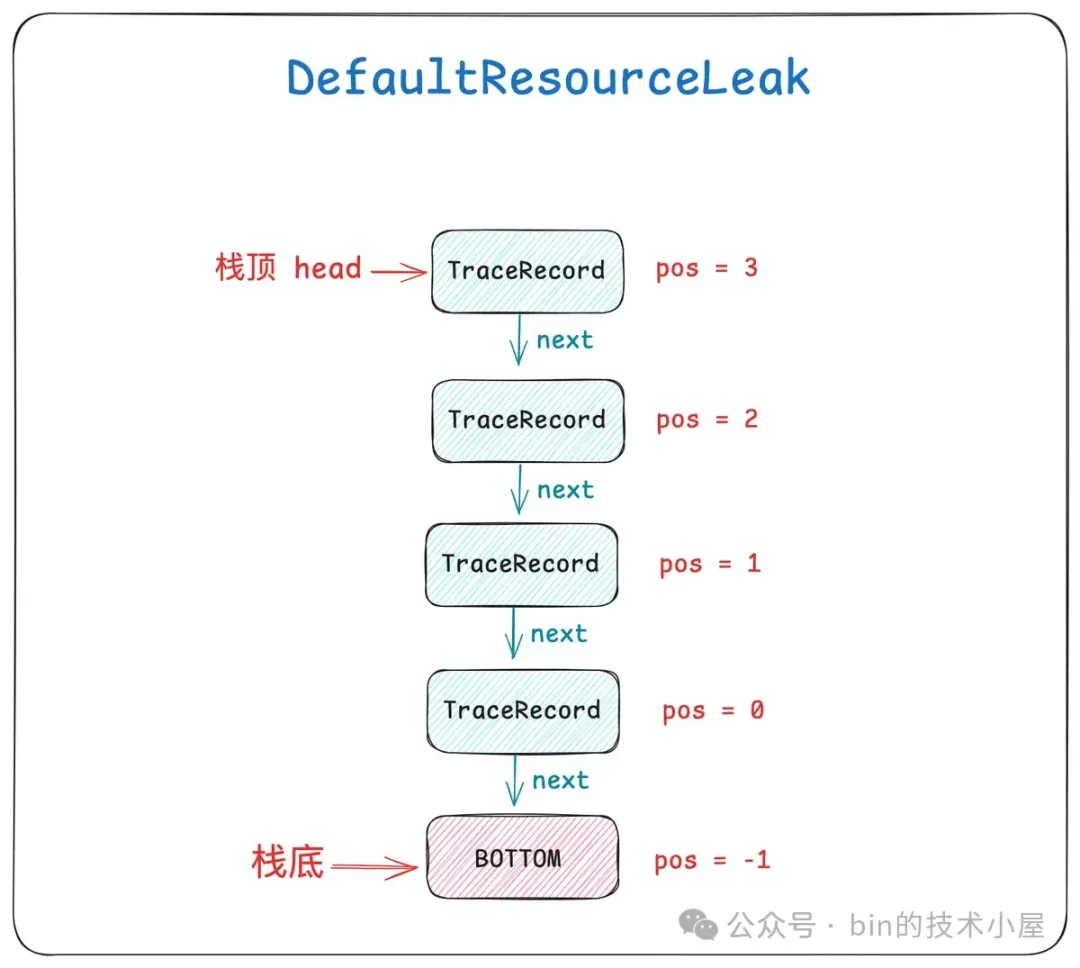
如果一个 ByteBuf 被访问了多次,那么就会对应多个 TraceRecord 结构,ByteBuf 的这些 TraceRecord , 被 Netty 组织在对应 DefaultResourceLeak 里的一个栈结构中,位于栈底的 TraceRecord 记录的是 ByteBuf 的创建堆栈,位于栈顶的 TraceRecord 记录的是 ByteBuf 最近一次被访问的堆栈。
java
private static final class DefaultResourceLeak<T> {
// 栈顶指针
private volatile TraceRecord head; // 栈结构,存放对应 ByteBuf 的访问堆栈
}
private static class TraceRecord extends Throwable {
// 栈底
private static final TraceRecord BOTTOM = new TraceRecord()
}由于每个 TraceRecord 中记录的访问堆栈信息占用 2K 的内存,因此无论在什么探测级别下,Netty 都不可能为 ByteBuf 的每一次访问都记录下堆栈信息,所以要对 DefaultResourceLeak 栈中 TraceRecord 的个数进行限制。默认栈中的 TraceRecord 最大个数为 4 , 我们可以通过 -Dio.netty.leakDetection.targetRecords 参数进行调节。
java
public class ResourceLeakDetector<T> {
// ByteBuf 访问堆栈记录个数限制,默认为 4
private static final int TARGET_RECORDS;
private static final String PROP_TARGET_RECORDS = "io.netty.leakDetection.targetRecords";
private static final int DEFAULT_TARGET_RECORDS = 4;
TARGET_RECORDS = SystemPropertyUtil.getInt(PROP_TARGET_RECORDS, DEFAULT_TARGET_RECORDS);
}但更加准确的说,targetRecords 只是对栈中的 TraceRecord 个数进行限制,避免无限的增长,但不会限制死。事实上, 栈中 TraceRecord 个数有一定的概率会超过 targetRecords 的限制。
比如,默认情况下 targetRecords 的值为 4 ,如果我们将栈中 TraceRecord 个数限制成 4 个的话,当一个 ByteBuf 的访问链路很长的话,那么栈中就只能记录前三个最远的 TraceRecord 和一个最近的 TraceRecord。中间的访问堆栈就丢失了。这样不利于我们排查 ByteBuf 的完整泄露路径。
事实上 targetRecords 的真正语义是,当 ByteBuf 的访问堆栈记录 TraceRecord 个数达到 targetRecords 的限定时,Netty 会根据一定的概率来丢弃当前栈顶 TraceRecord,并将新的 TraceRecord 作为栈顶。这个丢弃的概率是非常高的,从而避免了 TraceRecord 个数疯狂地增长。
但如果恰好命中了不丢弃的概率(非常低),那么原来栈顶的 TraceRecord 将不会被丢弃而是继续保留在栈中,新的 TraceRecord 作为栈顶加入到栈中,这样一来栈中 TraceRecord 个数就超过了 targetRecords 的限制。但是可以尽可能多的保留 ByteBuf 中间的访问堆栈记录。使得 ByteBuf 的泄露路径更加完整一些。
PARANOID 是 Netty 内存泄露探测的最高级别,信息最全,消耗也最大,它在 ADVANCED 的基础之上,绕开了采样频率的限制,会对每一个 ByteBuf 进行详细地泄露探测。一般用于需要在测试环境定位紧急的内存泄露问题才会开启。
3. 内存泄露探测相关的设计模型
现在我们已经清楚了内存泄露探测的设计原理以及相关应用,那么在本小节中就该正式介绍实现细节了,Netty 一共设计了 4 种探测模型,不同的模型封装不同的探测职责。
3.1 ResourceLeakDetector
首先第一个模型是 ResourceLeakDetector 。顾名思义,它主要负责内存泄露的探测,第一小节中介绍的原理实现,就是在这个模型中完成的。
java
public class ResourceLeakDetector<T> {
// 探测级别
private static Level level;
// 未被释放的 ByteBuf 对应的弱引用 DefaultResourceLeak 集合
private final Set<DefaultResourceLeak<?>> allLeaks =
Collections.newSetFromMap(new ConcurrentHashMap<DefaultResourceLeak<?>, Boolean>());
// 用于接收 ByteBuf 被回收的通知
private final ReferenceQueue<Object> refQueue = new ReferenceQueue<Object>();
// 探测的资源类型,这里是 ByteBuf
private final String resourceType;
// 采样间隔
private final int samplingInterval;
// 内存泄露监听器,一旦探测到内存泄露,Netty 就会回调 LeakListener
private volatile LeakListener leakListener;
}ResourceLeakDetector 中封装了内存泄露探测所需要的所有信息,其中最重要的就是 allLeaks 和 refQueue 这两个集合,allLeaks 主要用于保存所有未被释放的 ByteBuf 对应的弱引用 DefaultResourceLeak,在 ByteBuf 被创建之后,Netty 就会为其创建一个 DefaultResourceLeak 实例来弱引用 ByteBuf,同时这个 DefaultResourceLeak 会被添加到这里的 allLeaks 中。
如果应用程序及时的释放了 ByteBuf , 那么对应的 DefaultResourceLeak 也会从 allLeaks 中删除,如果 ByteBuf 被 GC 之后,其对应的 DefaultResourceLeak 仍然停留在 allLeaks 中,那么就说明该 ByteBuf 发生泄露了。
refQueue 主要用于收集被 GC 的 ByteBuf 对应的弱引用 DefaultResourceLeak,当一个 ByteBuf 被 GC 之后,那么其对应的 DefaultResourceLeak 就会被 JVM 放入到一个内部的 _reference_pending_list 中,随后 ReferenceHandler 线程被唤醒,将 DefaultResourceLeak 从 _reference_pending_list 中转移到这里的 refQueue。
后续 ResourceLeakDetector 就会从 refQueue 中将 DefaultResourceLeak 摘下,然后检查这个 DefaultResourceLeak 是否仍然停留在 allLeaks 集合中。如果存在,就说明对应的 ByteBuf 发生了泄露,最后将泄露路径以 ERROR 级别的日志打印出来。
除此之外,Netty 还提供了一个内存泄露监听器,让我们可以在内存泄露发生之后实现自主的处理逻辑。
java
public interface LeakListener {
/**
* Will be called once a leak is detected.
*/
void onLeak(String resourceType, String records);
}我们可以通过 ByteBufUtil.setLeakListener 方法来向 ResourceLeakDetector 注册 LeakListener。
java
public final class ByteBufUtil {
public static void setLeakListener(ResourceLeakDetector.LeakListener leakListener) {
AbstractByteBuf.leakDetector.setLeakListener(leakListener);
}
}一旦 ResourceLeakDetector 探测到内存泄露的发生,Netty 就会回调我们注册的 LeakListener。
Netty 在全局范围内只会有一个 ResourceLeakDetector 实例,被 AbstractByteBuf 的静态字段 leakDetector 所引用。
java
public abstract class AbstractByteBuf extends ByteBuf {
// 全局 ResourceLeakDetector 实例
static final ResourceLeakDetector<ByteBuf> leakDetector =
ResourceLeakDetectorFactory.instance().newResourceLeakDetector(ByteBuf.class);
}内存泄露探测器的默认实现是 ResourceLeakDetector,但我们也可以自定义实现内存泄露探测器,只需要继承 ResourceLeakDetector 类,并覆盖实现相关的核心探测方法,最后通过 JVM 参数 -Dio.netty.customResourceLeakDetector={className} 指定即可。
ResourceLeakDetector 最核心的方法莫过于 track(T obj) 和 reportLeak() 这两个方法。
java
public class ResourceLeakDetector<T> {
public final ResourceLeakTracker<T> track(T obj) {
return track0(obj, false);
}
// 采样频率,默认 128
private final int samplingInterval;
// 对 obj 进行资源泄露的探测
// force 表示是否强制探测
private DefaultResourceLeak track0(T obj, boolean force) {
Level level = ResourceLeakDetector.level;
if (force ||
level == Level.PARANOID ||
(level != Level.DISABLED && PlatformDependent.threadLocalRandom().nextInt(samplingInterval) == 0)) {
// 触发内存泄露探测,如果发生内存泄露,则在日志中 report
reportLeak();
// 创建 ByteBuf (obj) 对应的弱引用 DefaultResourceLeak
// ResourceLeakDetector 中的全局 refQueue , allLeaks 会在这里注册进去
return new DefaultResourceLeak(obj, refQueue, allLeaks, getInitialHint(resourceType));
}
return null;
}
}其中 track 方法用于触发内存泄露的探测,这里是对第二小节中的内容实现,如果我们设置的内存泄露探测级别为 PARANOID , 那么 Netty 就会对系统中所有的 ByteBuf 进行全量探测,内存泄露发生之后的报告日志也会包含详细的泄露堆栈路径。
如果内存泄露探测级别为 SIMPLE 或者 ADVANCED , 那么 Netty 就会对系统中的 ByteBuf 进行采样探测,采样间隔 SAMPLING_INTERVAL = 128 , 我们可以通过 JVM 参数 -Dio.netty.leakDetection.samplingInterval 进行设置。
具体的采样逻辑是,Netty 会生成 [ 0 , samplingInterval ) 之间的一个随机数,如果这个随机数是 0 ,那么就进行内存泄露探测,如果这个随机数不为 0 ,则放弃探测。从效果上来看,就是每申请 samplingInterval 个 ByteBuf , Netty 就会触发一次内存泄露的探测。
java
PlatformDependent.threadLocalRandom().nextInt(samplingInterval) == 0当符合内存泄露的探测条件之后,Netty 将会在 reportLeak() 方法中进行内存泄露的探测,如果有内存泄露的发生,那么就将泄露的 ByteBuf 相关访问路径以 ERROR 的日志级别打印出来。
既然内存泄露的日志级别是 ERROR , 那么在进行内存泄露探测之前,我们首先必须检查一下用户是否开启了 ERROR 日志级别。
java
protected boolean needReport() {
return logger.isErrorEnabled();
}如果用户选择的日志级别比较低,那么即使发生了内存泄露,相关的 ERROR 日志也不会打印,这种情况下内存泄露的探测也就没必要进行了。Netty 会调用 clearRefQueue() 方法,将 refQueue 中收集到的所有 DefaultResourceLeak 实例清空,并且将 DefaultResourceLeak 从 allLeaks 集合中删除。
java
private void clearRefQueue() {
for (;;) {
// 清空 refQueue
DefaultResourceLeak ref = (DefaultResourceLeak) refQueue.poll();
if (ref == null) {
break;
}
// 将 DefaultResourceLeak 从 allLeaks 集合中删除。
ref.dispose();
}
}如果用户的日志级别选择的是 ERROR , Netty 就会继续后面的内存泄露探测流程,首先一个 ByteBuf 如果被 GC 回收的话,那么与其弱引用关联的 DefaultResourceLeak 就会被 ReferenceHandler 线程转移到 refQueue 中。
也就是说当前 refQueue 中保留的所有 DefaultResourceLeak 其对应的 ByteBuf 已经被 GC 回收了,而内存泄露探测针对地就是这些被回收的 ByteBuf。
Netty 会从 refQueue 中将这些收集到的 DefaultResourceLeak 挨个摘下。
java
DefaultResourceLeak ref = (DefaultResourceLeak) refQueue.poll();然后调用 dispose() 方法检查 DefaultResourceLeak 实例是否仍然停留在 allLeaks 集合中。
java
boolean dispose() {
// 断开 DefaultResourceLeak 与 ByteBuf 的弱引用关联
clear();
// 检查 DefaultResourceLeak 实例是否仍然存在于 allLeaks 集合中。
return allLeaks.remove(this);
}如果仍然停留在 allLeaks 中,那么就说明该 DefaultResourceLeak 实例对应的 ByteBuf 出现内存泄露了。在探测到内存泄露发生之后,调用 getReportAndClearRecords() 方法获取 ByteBuf 相关的访问堆栈路径,然后通过 reportTracedLeak 方法将 ByteBuf 的泄露路径以 ERROR 级别的日志打印出来,最后回调内存泄露监听器 LeakListener。
java
// resourceType 为需要探测的资源类型,这里是 ByteBuf
// records 是发生内存泄露的 ByteBuf 相关的访问堆栈
protected void reportTracedLeak(String resourceType, String records) {
logger.error(
"LEAK: {}.release() was not called before it's garbage-collected. " +
"See https://netty.io/wiki/reference-counted-objects.html for more information.{}",
resourceType, records);
}reportLeak() 方法的实现逻辑正是笔者在第一小节中介绍的所有内容:
java
private void reportLeak() {
// 日志级别必须是 Error 级别
if (!needReport()) {
clearRefQueue();
return;
}
// Detect and report previous leaks.
for (;;) {
// 对应的 ByteBuf 必须已经被 GC 回收,才会触发内存泄露的探测
DefaultResourceLeak ref = (DefaultResourceLeak) refQueue.poll();
if (ref == null) {
break;
}
// 检查 ByteBuf 对应的 DefaultResourceLeak 是否仍然停留在 allLeaks 集合中
if (!ref.dispose()) {
// 如果不存在,则说明 ByteBuf 已经被及时的释放了,不存在内存泄露
continue;
}
// 当探测到 ByteBuf 发生内存泄露之后,这里会获取 ByteBuf 相关的访问堆栈
String records = ref.getReportAndClearRecords();
if (reportedLeaks.add(records)) { // 去重泄露日志
// 打印泄露的堆栈路径
if (records.isEmpty()) {
reportUntracedLeak(resourceType);
} else {
reportTracedLeak(resourceType, records);
}
// 回调 LeakListener
LeakListener listener = leakListener;
if (listener != null) {
listener.onLeak(resourceType, records);
}
}
}
}3.2 ResourceLeakTracker
上一小节介绍的 ResourceLeakDetector 只是负责内存泄露的探测,但如果探测到了内存泄露,相关的泄露路径信息从哪里来的呢 ?Netty 是如何收集的 ?这就引入了第二个探测模型 ------ ResourceLeakTracker。
Netty 对 ResourceLeakTracker 的默认实现是 DefaultResourceLeak,它是一个 WeakReference ,被 Netty 用来弱引用关联 ByteBuf , 目的是接收 ByteBuf 被 GC 回收的通知,从而可以判断是否有内存泄露的情况发生。

除此之外,ResourceLeakTracker 承担的另一个重要职责就是负责收集 ByteBuf 的访问链路堆栈,一旦 ByteBuf 发生泄露,ResourceLeakDetector 就会从 ResourceLeakTracker 中获取相关的泄露堆栈 ------ getReportAndClearRecords() 方法,并在日志中打印出来。
每一条 ByteBuf 相关的访问链路堆栈信息,Netty 用一个 TraceRecord 结构来封装,而一个 ByteBuf 会有多条访问链路,那么在它的 ResourceLeakTracker 结构中就对应多个 TraceRecords,这些 TraceRecords 被 Netty 组织在一个栈的结构中。
java
private static final class DefaultResourceLeak<T>
extends WeakReference<Object> implements ResourceLeakTracker<T>, ResourceLeak {
// 栈顶指针
private volatile TraceRecord head;
// 栈中被丢弃的 TraceRecord 个数
private volatile int droppedRecords;
// 指向 ResourceLeakDetector 中的全局 allLeaks
private final Set<DefaultResourceLeak<?>> allLeaks;
// 被追踪探测的 Bytebuf 的 hash 值
private final int trackedHash;
}当 Netty 新分配一个 ByteBuf 之后,如果符合 ResourceLeakDetector.track 中的探测条件,那么就会创建一个 DefaultResourceLeak 来弱引用这个 ByteBuf。同时将这个 DefaultResourceLeak 加入到 allLeaks 集合中,这里正是判断一个 ByteBuf 是否发生内存泄露的关键依据。
无论什么样的探测级别,DefaultResourceLeak 都会至少保留一个 TraceRecord , 这个 TraceRecord 用于保存 ByteBuf 的创建位置堆栈,在构建 DefaultResourceLeak 的时候会被加入到栈底。
java
DefaultResourceLeak(
Object referent,
ReferenceQueue<Object> refQueue,
Set<DefaultResourceLeak<?>> allLeaks,
Object initialHint) {
// 弱引用关联 ByteBuf (referent)
// 注册 refQueue
super(referent, refQueue);
// 保存 Bytebuf 的 hash 值
trackedHash = System.identityHashCode(referent);
// 加入到 allLeaks 中,如果 ByteBuf 被回收之后,DefaultResourceLeak 仍然停留在 allLeaks,则表示发生内存泄露。
allLeaks.add(this);
// 创建第一个 TraceRecord,记录 ByteBuf 的创建位置堆栈,保存在栈底
headUpdater.set(this, initialHint == null ?
new TraceRecord(TraceRecord.BOTTOM) : new TraceRecord(TraceRecord.BOTTOM, initialHint));
this.allLeaks = allLeaks;
}另外我们可以通过 record 相关方法,来向 DefaultResourceLeak 添加 ByteBuf 的当前访问堆栈。
java
@Override
public void record() {
record0(null);
}
@Override
public void record(Object hint) {
record0(hint);
}通过 record(Object hint) 添加的堆栈,会在泄露日志中出现我们自定义的提示信息。
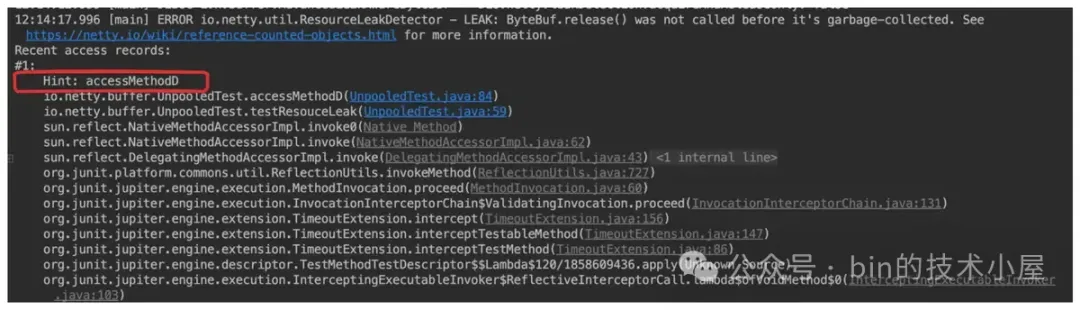
而通过 record() 添加的堆栈,在泄露日志中就没有这个提示信息。

向 DefaultResourceLeak 添加新 TraceRecord 的逻辑也很简单,就是将 ByteBuf 当前最新的访问堆栈信息 ------ TraceRecord 入栈即可。但也不能无限制的向栈中添加 TraceRecord。
第二小节笔者介绍过,每个 TraceRecord 中记录的访问堆栈信息占用 2K 的内存,Netty 不可能为 ByteBuf 的每一次访问都记录下堆栈信息,所以 DefaultResourceLeak 栈中的个数会受到 TARGET_RECORDS 的限制,默认为 4 , 我们可以通过 -Dio.netty.leakDetection.targetRecords 参数进行调节。
当 DefaultResourceLeak 栈中记录的 TraceRecord 个数达到 TARGET_RECORDS 的限定时,Netty 会根据一定的概率(比较高)来丢弃当前栈顶 TraceRecord,并将新的 TraceRecord 作为栈顶。从而避免了 TraceRecord 个数疯狂地增长。
但如果恰好命中了不丢弃的概率(非常低),那么原来栈顶的 TraceRecord 将不会丢弃而是继续保留在栈中,新的 TraceRecord 作为栈顶加入到栈中,这样一来栈中 TraceRecord 个数就超过了 TARGET_RECORDS 的限制。但是可以尽可能多的保留 ByteBuf 中间的访问堆栈记录。使得 ByteBuf 的泄露路径更加完整一些。
丢弃概率的计算逻辑也很简单,Netty 仍然是通过计算一个 [ 0 , 1 << backOffFactor ) 区间的随机数,如果这个随机数不为 0 ,那么就将当前的栈顶元素丢弃,这么看来,当 DefaultResourceLeak 栈中 TraceRecord 个数达到 TARGET_RECORDS 的限定,如果继续添加 TraceRecord,那么栈顶元素被丢弃的概率还是非常高的。
java
// numElements 为当前栈中的 TraceRecord 个数
final int backOffFactor = Math.min(numElements - TARGET_RECORDS, 30)
dropped = PlatformDependent.threadLocalRandom().nextInt(1 << backOffFactor) != 0TraceRecord 完整的入栈逻辑如下:
java
private void record0(Object hint) {
if (TARGET_RECORDS > 0) {
TraceRecord oldHead;
TraceRecord prevHead;
TraceRecord newHead;
boolean dropped;
do {
// 获取栈顶 TraceRecord,也就是 ByteBuf 最近一次的访问堆栈
if ((prevHead = oldHead = headUpdater.get(this)) == null) {
// 栈顶为 null ,表示 ByteBuf 已经被释放,对应的泄露探测已经关闭。
return;
}
// 获取当前栈中的 TraceRecord 个数
final int numElements = oldHead.pos + 1;
// 如果达到 TARGET_RECORDS 的限制,就开始概率性的丢弃当前栈顶
// 然后用新的 TraceRecord 作为栈顶
if (numElements >= TARGET_RECORDS) {
final int backOffFactor = Math.min(numElements - TARGET_RECORDS, 30);
// numElements 超出 TARGET_RECORDS 的限制越多,当前栈顶就越容易被 drop
if (dropped = PlatformDependent.threadLocalRandom().nextInt(1 << backOffFactor) != 0) {
// 命中丢弃的概率,则将当前栈顶 TraceRecord 丢弃
prevHead = oldHead.next;
}
} else {
// 保留当前栈顶,这样栈中的 TraceRecord 个数就会超过 TARGET_RECORDS 的限制
// 但 ByteBuf 中间的访问链路堆栈就会被概率性的保留下来
dropped = false;
}
// 创建的新的 TraceRecord(记录 ByteBuf 的当前访问堆栈)
// 并作为新的栈顶元素
newHead = hint != null ? new TraceRecord(prevHead, hint) : new TraceRecord(prevHead);
} while (!headUpdater.compareAndSet(this, oldHead, newHead));
if (dropped) {
// 统计被丢弃的 TraceRecord 个数
droppedRecordsUpdater.incrementAndGet(this);
}
}
}好了,现在我们已经清楚了,Netty 如何通过 DefaultResourceLeak 来收集 ByteBuf 相关的访问链路堆栈信息,那么当这个 ByteBuf 发生内存泄露之后,Netty 又是如何生成相关的泄露堆栈呢 ?
这就要依靠 DefaultResourceLeak 中的这个 TraceRecord 栈结构,栈顶 TraceRecord 永远保存的是 ByteBuf 最近一次的访问堆栈,栈底 TraceRecord 永远保存的是 ByteBuf 起始创建位置堆栈,中间的 TraceRecord 记录的是 ByteBuf 的访问链路堆栈。
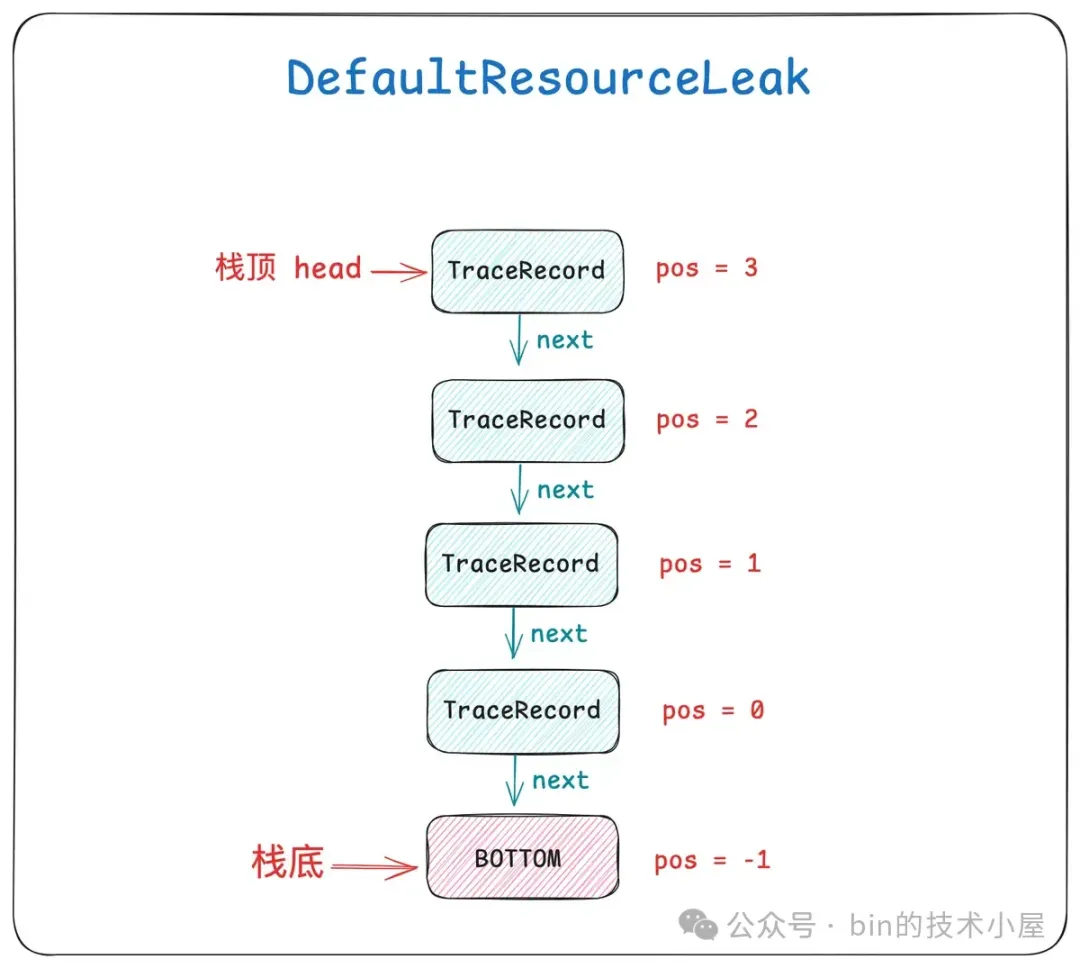
ByteBuf 的泄露堆栈是从栈顶的 TraceRecord 开始打印,一直到栈底 TraceRecord,也就是由近及远的输出 ByteBuf 的泄露路径。
java
String getReportAndClearRecords() {
// 获取栈顶 TraceRecord
TraceRecord oldHead = headUpdater.getAndSet(this, null);
// 由近及远的输出 ByteBuf 相关的 TraceRecords
return generateReport(oldHead);
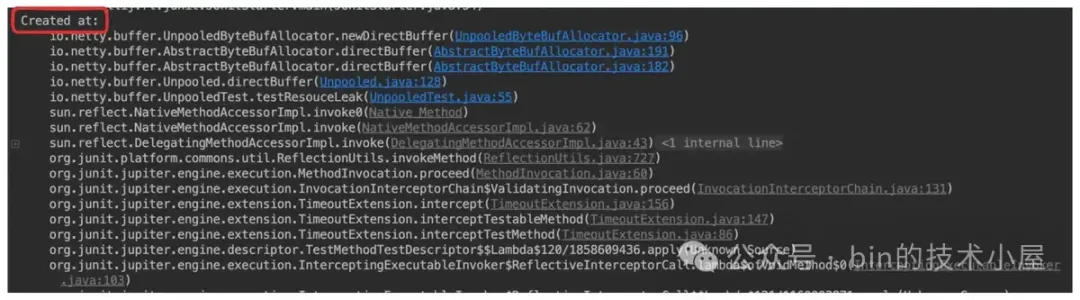
}首先 Netty 会打印一行 Recent access records: , 然后每一个 TraceRecord 在日志中都有一个 # 字编号,栈顶的 TraceRecord 编号为 #1 , 后面依次递增,栈底的 TraceRecord 由于记录的是创建位置堆栈,Netty 在日志中会提示 Created at:。
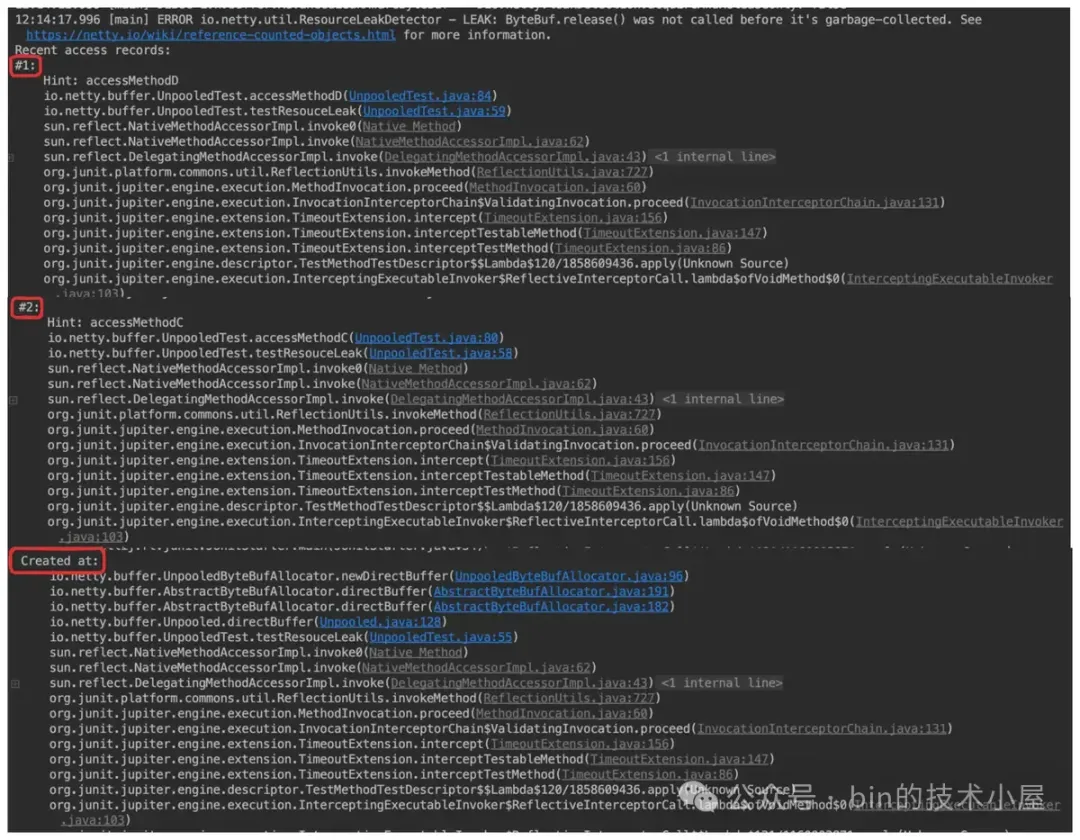
java
private String generateReport(TraceRecord oldHead) {
// 当前 DefaultResourceLeak 栈中一共有多少个 TraceRecord
int present = oldHead.pos + 1;
// 每个 TraceRecord 分配 2K 大小的内存
StringBuilder buf = new StringBuilder(present * 2048).append(NEWLINE);
buf.append("Recent access records: ").append(NEWLINE);
int i = 1;
// 防重集合
Set<String> seen = new HashSet<String>(present);
// 从栈顶开始生成泄露堆栈
for (; oldHead != TraceRecord.BOTTOM; oldHead = oldHead.next) {
// 获取 TraceRecord 记录的堆栈信息
String s = oldHead.toString();
if (seen.add(s)) {
if (oldHead.next == TraceRecord.BOTTOM) {
// 栈底 TraceRecord 记录了 Buffer 的创建位置
buf.append("Created at:").append(NEWLINE).append(s);
} else {
buf.append('#').append(i++).append(':').append(NEWLINE).append(s);
}
} else {
// 重复的 TraceRecord 个数
duped++;
}
}
// 生成泄露堆栈,并返回
buf.setLength(buf.length() - NEWLINE.length());
return buf.toString();
}3.3 TraceRecord
上述内存泄露日志中出现的每一条访问堆栈是如何生成的呢 ? 这就引入了第三个模型 ------ TraceRecord , 该模型在内存泄露探测中用于记录 ByteBuf 某次的访问堆栈。实现起来也很简单,只需要继承 Throwable 即可,这样在每次创建 TraceRecord 的时候,就会自动生成 ByteBuf 当前的访问堆栈。
由于 TraceRecord 在 DefaultResourceLeak 中是被组织在一个栈结构中,所以它的 next 指针指向栈中下一个 TraceRecord, pos 用于标识当前 TraceRecord 在栈中的位置,整个结构比较简单明了。
java
private static class TraceRecord extends Throwable {
// 空实现,用来标识栈底位置
private static final TraceRecord BOTTOM = new TraceRecord() {
@Override
public Throwable fillInStackTrace() {
return this;
}
};
// 出现在日志中的自定义 Hint 提示信息
private final String hintString;
// 栈中下一个 TraceRecord
private final TraceRecord next;
// 当前 TraceRecord 在栈中的位置
private final int pos;
}
TraceRecord 的 toString() 方法用于生成其中记录的堆栈信息,实现也很简单,就是直接打印 Throwable 中的堆栈即可。
java
@Override
public String toString() {
// 每个 TraceRecord 堆栈信息占用 2K 内存
StringBuilder buf = new StringBuilder(2048);
if (hintString != null) {
// 日志中显示我们自定义的提示信息 tHint
buf.append("\tHint: ").append(hintString).append(NEWLINE);
}
// 获取 TraceRecord 记录的堆栈信息
StackTraceElement[] array = getStackTrace();
// Skip the first three elements.
out: for (int i = 3; i < array.length; i++) {
StackTraceElement element = array[i];
....... 清理一些没用的堆栈信息 ......
// 生成有效的堆栈信息
buf.append('\t');
buf.append(element.toString());
buf.append(NEWLINE);
}
return buf.toString();
}3.4 LeakAwareByteBuf
关于内存泄露探测所有的核心设计,到这里笔者就为大家介绍完了,当我们清楚了这些背景之后,在回头来看笔者在文章开始处提出的疑问,是不是多多少少会有一些感觉了 ?
在 Netty 每次分配内存的时候,都会触发内存泄露的采样探测,如果命中采样概率,则会对本次分配的 ByteBuf 进行后续的内存泄露追踪。
java
public final class UnpooledByteBufAllocator {
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
final ByteBuf buf;
....... 分配 UnpooledByteBuf .....
// 是否启动内存泄露探测,如果启动则额外用 LeakAwareByteBuf 进行包装返回
return disableLeakDetector ? buf : toLeakAwareBuffer(buf);
}
}
public class PooledByteBufAllocator {
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
....... 分配 PooledByteBuf .....
// 如果内存泄露探测开启,则用 LeakAwareByteBuf 包装 PooledByteBuf 返回
return toLeakAwareBuffer(buf);
}
}Netty 为了实现对 ByteBuf 内存泄露的追踪,从而引入了第四个模型 ------ LeakAwareBuffer,从命名上就可以看出,LeakAwareBuffer 主要是为了识别出被其包装的 ByteBuf 是否有内存泄露情况的发生。
每当命中采样概率之后,Netty 都会将普通的 ByteBuf 包装成一个 LeakAwareBuffer 返回。
java
protected static ByteBuf toLeakAwareBuffer(ByteBuf buf) {
// DefaultResourceLeak 用于追踪 ByteBuf 的泄露路径
ResourceLeakTracker<ByteBuf> leak;
switch (ResourceLeakDetector.getLevel()) {
case SIMPLE:
// 触发内存泄露采样探测,如果命中采样频率
// 则为 ByteBuf 创建 DefaultResourceLeak(弱引用)
leak = AbstractByteBuf.leakDetector.track(buf); // 本文 3.1 小节内容
if (leak != null) {
// SIMPLE 级别对应的是 SimpleLeakAwareByteBuf
buf = new SimpleLeakAwareByteBuf(buf, leak);
}
break;
case ADVANCED:
case PARANOID:
// 触发内存泄露采样探测
leak = AbstractByteBuf.leakDetector.track(buf); // 本文 3.1 小节内容
if (leak != null) {
// ADVANCED , PARANOID 级别对应的是 AdvancedLeakAwareByteBuf
buf = new AdvancedLeakAwareByteBuf(buf, leak);
}
break;
default:
break;
}
// 如果命中采样频率,则用 LeakAwareByteBuf 包装返回
// 如果没有命中采样频率,则原样返回
return buf;
}内存泄露探测级别是 SIMPLE 的情况下,Netty 会用 SimpleLeakAwareByteBuf 对 ByteBuf 进行包装。内存泄露探测级别是 ADVANCED 或者 PARANOID 的情况下,Netty 会用 AdvancedLeakAwareByteBuf 对 ByteBuf 进行包装。
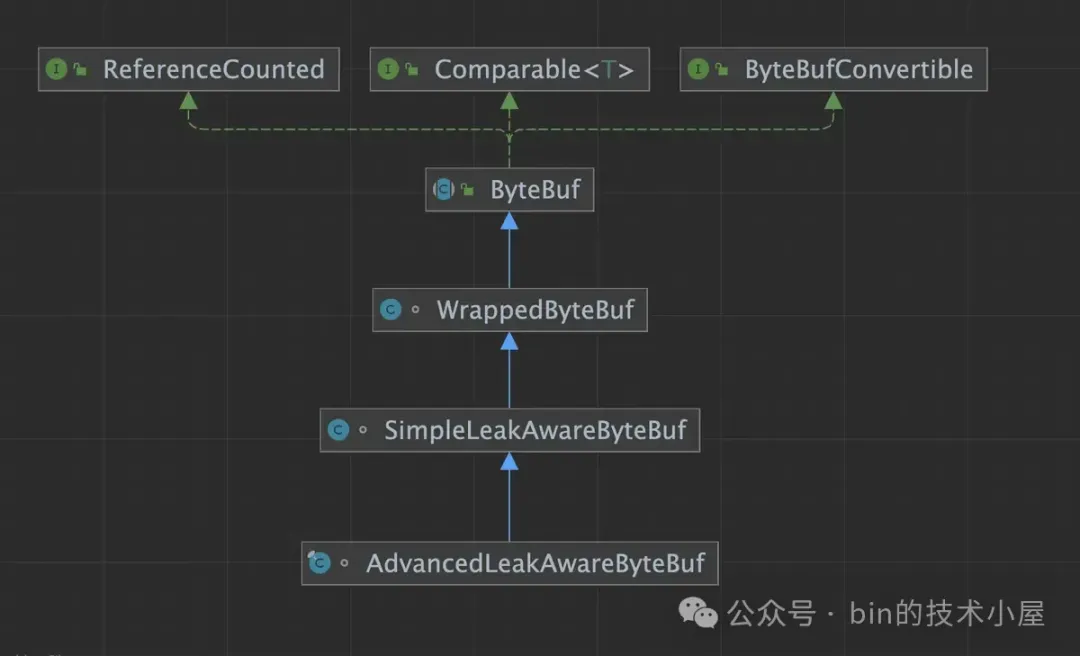
从类的继承结构图中我们可以看出,SimpleLeakAwareByteBuf 和 AdvancedLeakAwareByteBuf 均继承于 WrappedByteBuf,说明它们只是对原始普通 ByteBuf 的一个简单装饰(装饰者设计模型)。
java
class SimpleLeakAwareByteBuf extends WrappedByteBuf {
// 需要被探测的普通 ByteBuf
private final ByteBuf trackedByteBuf;
// ByteBuf 的弱引用 DefaultResourceLeak
final ResourceLeakTracker<ByteBuf> leak;
SimpleLeakAwareByteBuf(ByteBuf wrapped, ResourceLeakTracker<ByteBuf> leak) {
this(wrapped, wrapped, leak);
}
SimpleLeakAwareByteBuf(ByteBuf wrapped, ByteBuf trackedByteBuf, ResourceLeakTracker<ByteBuf> leak) {
super(wrapped);
this.trackedByteBuf = ObjectUtil.checkNotNull(trackedByteBuf, "trackedByteBuf");
this.leak = ObjectUtil.checkNotNull(leak, "leak");
}
}LeakAwareByteBuf 中最核心的一个装饰属性就是 leak ,它用来指向与 trackedByteBuf 弱引用关联的 DefaultResourceLeak。在 DefaultResourceLeak 刚被创建出来的时候,它会加入到全局的 allLeaks 集合中。
最开始 DefaultResourceLeak 栈中只包含一个 TraceRecord,位于栈底,用于记录 trackedByteBuf 的创建位置堆栈。在 SIMPLE 探测级别下,内存泄露日志中也只会出现 trackedByteBuf 的创建位置堆栈。
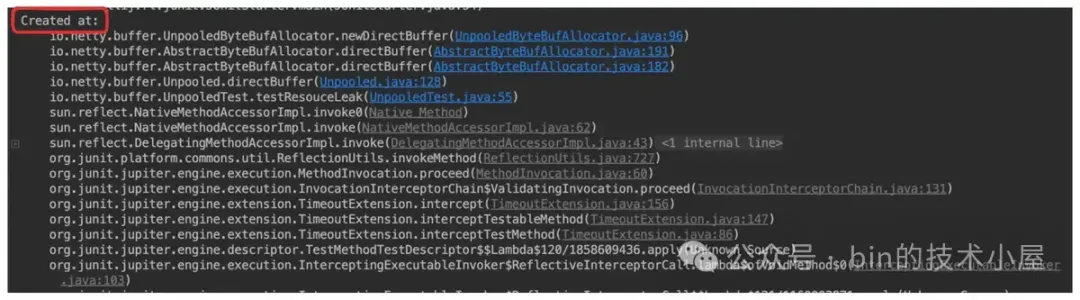
所以 SimpleLeakAwareByteBuf 相关的 read , write 方法并没有什么特别之处,都是对 trackedByteBuf 的简单代理。
java
class SimpleLeakAwareByteBuf extends WrappedByteBuf {
@Override
public byte readByte() {
return trackedByteBuf.readByte();
}
@Override
public ByteBuf writeByte(int value) {
trackedByteBuf.writeByte(value);
return this;
}
}值得聊一下的是 SimpleLeakAwareByteBuf 的 release() 方法,当我们使用完 SimpleLeakAwareByteBuf , 就需要及时的手动释放。如果 SimpleLeakAwareByteBuf 的引用计数为 0 ,就需要额外关闭内存泄露的探测,因为已经及时释放了,就不会存在内存泄露的情况。
java
@Override
public boolean release() {
// 引用计数为 0
if (super.release()) {
// 关闭内存泄露的探测
closeLeak();
return true;
}
return false;
}
private void closeLeak() {
boolean closed = leak.close(trackedByteBuf);
}关闭 trackedByteBuf 的内存泄露检测核心步骤是:
-
首先将 DefaultResourceLeak 从 allLeaks 集合中删除,因为 allLeaks 中保存的全部都是未被释放的 trackedByteBuf 对应的 DefaultResourceLeak 。
-
断开 DefaultResourceLeak 与 trackedByteBuf 的弱引用关联,这样一来,当 trackedByteBuf 被 GC 之后,JVM 将不会把 DefaultResourceLeak 放入到 _reference_pending_list 中,反而会将 DefaultResourceLeak 与 trackedByteBuf 一起回收。这样一来,refQueue 中自然也不会出现这个 DefaultResourceLeak ,ResourceLeakDetector 也不会错误地探测到它了。
java
public void clear() {
this.referent = null;
}- 将 DefaultResourceLeak 栈中保存的 TraceRecords 清空。
java
private static final class DefaultResourceLeak<T>
extends WeakReference<Object> implements ResourceLeakTracker<T>, ResourceLeak {
@Override
public boolean close() {
// 将 DefaultResourceLeak 从 allLeaks 集合中删除
if (allLeaks.remove(this)) {
// 断开 DefaultResourceLeak 与 trackedByteBuf 的弱引用关联
clear();
// 清空 DefaultResourceLeak 栈
headUpdater.set(this, null);
return true;
}
return false;
}如果这个 SimpleLeakAwareByteBuf 忘记释放了,那么它对应的 DefaultResourceLeak 就会一直停留在 allLeaks 集合中,当 SimpleLeakAwareByteBuf 被 GC 之后,JVM 就会将 DefaultResourceLeak 放入到 _reference_pending_list 中,随后唤醒 ReferenceHandler 线程将 DefaultResourceLeak 从 _reference_pending_list 中转移到 refQueue。
当下一次内存分配的时候,如果命中内存泄露采样检测的概率,那么 ResourceLeakDetector 就会从 refQueue 中将收集到的所有 DefaultResourceLeak 挨个摘下,并判断它们是否仍然停留在 allLeaks 中。
如果仍然在 allLeaks 中,就说明该 DefaultResourceLeak 对应的 ByteBuf 发生了内存泄露,而具体的泄露路径就保存在 DefaultResourceLeak 栈中,最后将泄露路径以 ERROR 的日志级别打印出来。
java
public class ResourceLeakDetector<T> {
private void reportLeak() {
// Detect and report previous leaks.
for (;;) {
DefaultResourceLeak ref = (DefaultResourceLeak) refQueue.poll();
if (ref == null) {
break;
}
// 检查 ByteBuf 对应的 DefaultResourceLeak 是否仍然停留在 allLeaks 集合中
if (!ref.dispose()) {
// 如果不存在,则说明 ByteBuf 已经被及时的释放了,不存在内存泄露
continue;
}
// 当探测到 ByteBuf 发生内存泄露之后,这里会获取 ByteBuf 相关的访问堆栈
String records = ref.getReportAndClearRecords();
// 打印泄露的堆栈路径
reportTracedLeak(resourceType, records);
}
}
}以上就是内存泄露探测级别 SIMPLE 的实现逻辑,而 ADVANCED , PARANOID 级别的特点在于它们会收集详细的访问堆栈,所以 AdvancedLeakAwareByteBuf 是在 SimpleLeakAwareByteBuf 的基础之上对相关的访问方法,比如 read , write 等方法进行装饰,装饰什么呢 ?就是每对 AdvancedLeakAwareByteBuf 进行一次访问,就向 DefaultResourceLeak 栈中添加一次最新的堆栈信息。
java
final class AdvancedLeakAwareByteBuf extends SimpleLeakAwareByteBuf {
AdvancedLeakAwareByteBuf(ByteBuf buf, ResourceLeakTracker<ByteBuf> leak) {
super(buf, leak);
}
@Override
public byte readByte() {
// 记录当前访问的堆栈信息
recordLeakNonRefCountingOperation(leak);
return super.readByte();
}
@Override
public ByteBuf writeByte(int value) {
// 记录当前访问的堆栈信息
recordLeakNonRefCountingOperation(leak);
return super.writeByte(value);
}
static void recordLeakNonRefCountingOperation(ResourceLeakTracker<ByteBuf> leak) {
if (!ACQUIRE_AND_RELEASE_ONLY) {
// 向 DefaultResourceLeak 添加新的堆栈
leak.record();
}
}
}但一个现实的问题是,ByteBuf 中有那么多的方法,如果对 ByteBuf 每一个方法的访问都要记录堆栈的话,那内存消耗就太大了,况且 DefaultResourceLeak 栈中的 TraceRecords 个数,是会受到 -Dio.netty.leakDetection.targetRecords 限制的,不能无限向栈中添加。
因此 Netty 又为我们提供了一个新的 JVM 参数 -Dio.netty.leakDetection.acquireAndReleaseOnly ,默认为 false , 表示默认情况下,对 ByteBuf 的每一个方法的访问都需要记录堆栈。
java
private static final String PROP_ACQUIRE_AND_RELEASE_ONLY = "io.netty.leakDetection.acquireAndReleaseOnly";
ACQUIRE_AND_RELEASE_ONLY = SystemPropertyUtil.getBoolean(PROP_ACQUIRE_AND_RELEASE_ONLY, false);设置为 true 表示,只对明确要求记录堆栈的方法进行记录,比如 touch 相关方法,retain() 方法,还有 release() 方法。其他的方法均不记录堆栈。
java
@Override
public ByteBuf touch() {
leak.record();
return this;
}
@Override
public ByteBuf touch(Object hint) {
leak.record(hint);
return this;
}
@Override
public ByteBuf retain() {
leak.record();
return super.retain();
}
@Override
public boolean release() {
leak.record();
return super.release();
}由于在 SIMPLE 探测级别下只会记录创建堆栈,不会记录访问堆栈,所以 SimpleLeakAwareByteBuf 的相关访问方法均不会调用 leak.record()。
java
class SimpleLeakAwareByteBuf extends WrappedByteBuf {
@Override
public ByteBuf touch() {
return this;
}
@Override
public ByteBuf touch(Object hint) {
return this;
}
}总结
要想触发 Netty 的内存泄露探测机制需要同时满足以下五个条件:
-
应用必须开启内存泄露探测功能。
-
必须要等到 ByteBuf 被 GC 之后,内存泄露才能探测的到,如果 GC 一直没有触发,那么即使是 ByteBuf 没有任何强引用或者软引用了,内存泄露的探测也将无从谈起。
-
当 GC 发生之后,必须是要等到下一次分配内存的时候,才会触发内存泄露的探测。如果没有内存申请的行为发生,那么内存泄露的探测也不会发生。
-
Netty 并不会探测每一个 ByteBuf 的泄露情况,而是根据一定的采样间隔,进行采样探测。所以要想触发内存泄露的探测,还需要达到一定的采样间隔。
-
应用的日志级别必须开启 Error 级别,因为内存泄露的报告,Netty 是以 Error 级别的日志输出出来的,如果日志级别在 Error 以下,那么内存泄露的报告则无法输出。
我们可以通过 JVM 参数 -Dio.netty.leakDetection.level 为应用设置不同的探测级别:
-
DISABLED 表示禁用内存泄露探测。
-
SIMPLE 则是进行内存泄露的采样探测,我们可以通过 JVM 参数
-Dio.netty.leakDetection.samplingInterval来设置内存泄露探测的采样频率。内存泄露报告中只会包含 ByteBuf 的创建位置堆栈信息。 -
ADVANCED 也是进行采样探测,但在内存泄露报告中会体现更详细的信息,比如,ByteBuf 的相关访问路径堆栈信息,能够采集到的泄露堆栈受到
-Dio.netty.leakDetection.targetRecords参数的限制。 -
PARANOID 则是在 ADVANCED 的基础之上,对系统中的所有 ByteBuf 进行全量探测。级别最高,信息最全,消耗也最大。
好了,今天的内容就到这里,我们下篇文章见~~~~~