- Scala的包
- 定义包
- 定义包对象
- Scala的包的导入
- 导入重命名
一.Scala的包
package(包:一个容器。可以把类,对象,包,装入。
好处:
- 区分同名的类;
- 类很多时,更好地管理类;
- 控制访问访问
包名称应全部为小写,只能包含数字,字母,下划线,小圆点。不能使用数字开头,也不要用关键字。
例如:
package demo.class.execl
//错误,因为class是关键字
package demo.12a
// 错误,数字开头
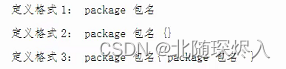
二.定义包
两种包的管理风格:
(1)一个源文件一个包,与路径名一一对应;
(2) 嵌套 package 表示层级关系。这样的好处是一个文件可以定义多个包,内层
可以访间外层的包的类和对象;
风格 1:将包名与包合 scale 文件的目承名相间
风格 2:铁套 packege 表示层级关系
四.Scala的包的导入

(演示)

五.导入重命名
:导入之后修改名字
格式:import 包名{原名字=>新名字}