1. 缓存中的多核问题
1.1 多核系统中的缓存
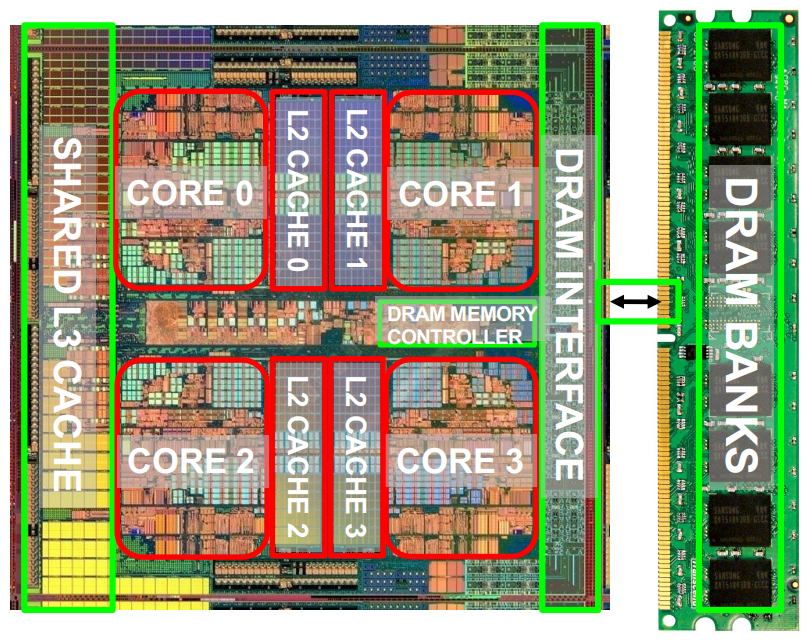
- Intel Montecito缓存
- 两个 core,每个都有一个私有的12 MB的L3缓存和一个1 MB的L2缓存,图中深蓝色部分均为L3缓存。

- 在多核/多线程系统中,缓存效率变得更加重要
- 存储器带宽非常宝贵
- 缓存空间是各内核/线程的有限资源
- 如何设计多核系统中的缓存?
- 共享(shared)缓存 vs. 私有(private) 缓存
- 如何最大限度地提高整个系统的性能?
- 如何为共享缓存中的不同线程提供 QoS(Quality of Service)?
- 缓存管理算法是否应该感知线程(即是否应该知道不同的线程在访问它们)?
- 如何为共享缓存中的线程分配空间?
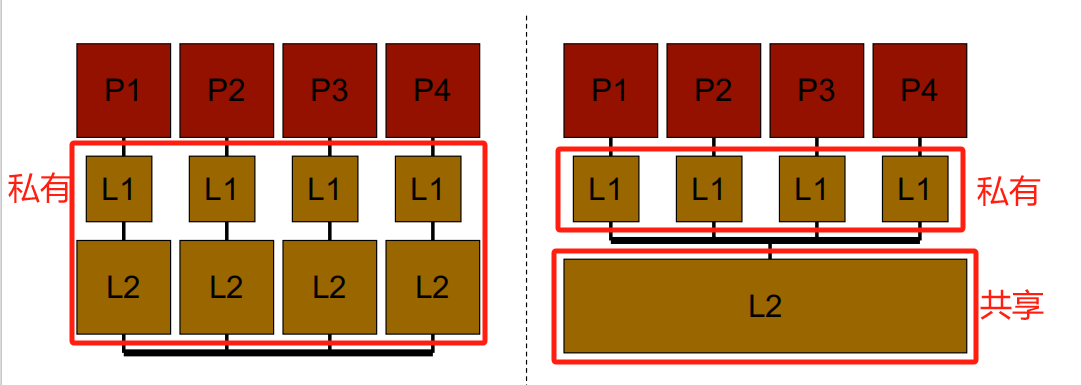
1.2 私有(Private) vs. 共享(Shared)缓存
- 私有缓存: 缓存只属于一个内核(一个共享 block 可存在多个缓存中)
- 共享缓存: 缓存由多个内核共享
L3一般是共享的。
1.2.1 资源共享的概念和优点
**Idea:**与其将一个硬件资源专门分配给一个上下游的硬件,不如让多个上下游的硬件共享使用它。
- 资源示例:功能单元、流水线、缓存、总线、内存、互连、存储
优点:
- 资源共享提高利用率/效率 -> 吞吐量
- 当一个线程闲置资源时,另一个线程可以使用它;无需复制共享数据
- 减少通信延迟
- 例如,在多线程处理器中,多个线程共享的数据可以保存在同一个缓存中
- 与共享内存编程模型兼容
- 如 cuda
1.2.2 资源共享的缺点
-
资源共享导致资源争夺
- 当资源未闲置时,另一个线程无法使用
- 如果空间被一个线程占用,另一个线程需要重新占用它
-
有时会降低每个或某些线程的性能
- 线程性能可能比单独运行时更差
-
消除性能隔离,即运行时性能不一致
- 线程性能取决于共同执行的线程
- 当前运行程序与共享缓存的其他运行程序获得不同数量的缓存空间,程序运行性能由其他运行程序决定,若其他运行程序占据了大部分缓存,则性能降低
- 线程性能取决于共同执行的线程
-
无控制(自由共享)共享会降低QoS
- 造成不公平、资源枯竭
因此,需要高效、公平地利用共享资源。
1.2.3 多核中的共享缓存与私有缓存
- 共享缓存的优点:
- 空间在内核之间动态分配
- 不会因为复制而浪费空间
- 缓存一致性可能更快(更容易在未命中时定位数据)
- 私有缓存的优势:
- L2 小 -> 更快的访问时间
- 通向 L2 的专用总线 -> 更少的竞争
1.2.4 内核间共享缓存
优点:
- 有效容量大
- 动态划分 可用的缓存空间
- 没有静态划分造成的碎片化
- 如果一个内核没有使用某些空间,另一个内核可以使用
- 更容易保持缓存一致性(缓存块位于单一位置)
缺点:
- 访问速度较慢(缓存与内核不紧密耦合)
- 内核因其他内核的访问而产生冲突丢失
- 内核间干扰导致的丢失
- 某些内核会破坏其他内核的命中率(某些内核会将其他内核需要的 block 踢出缓存)
- 保证每个内核的最低服务水平(或公平性)更加困难(多少空间、多少带宽?)
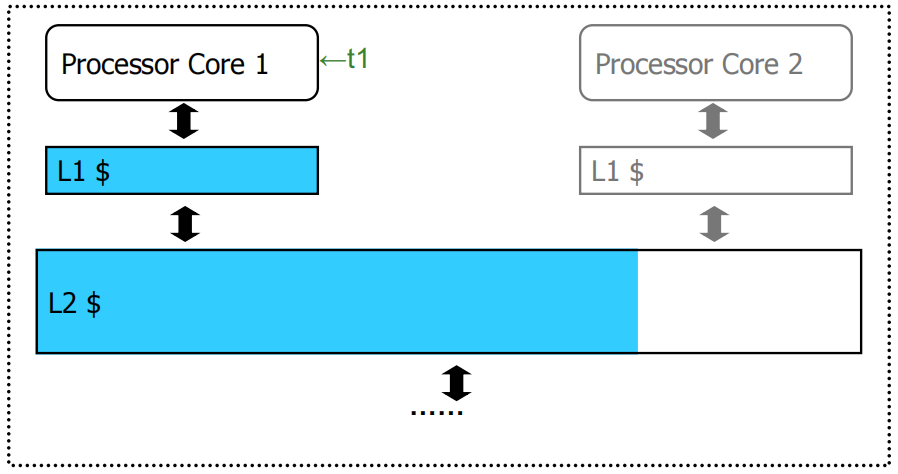
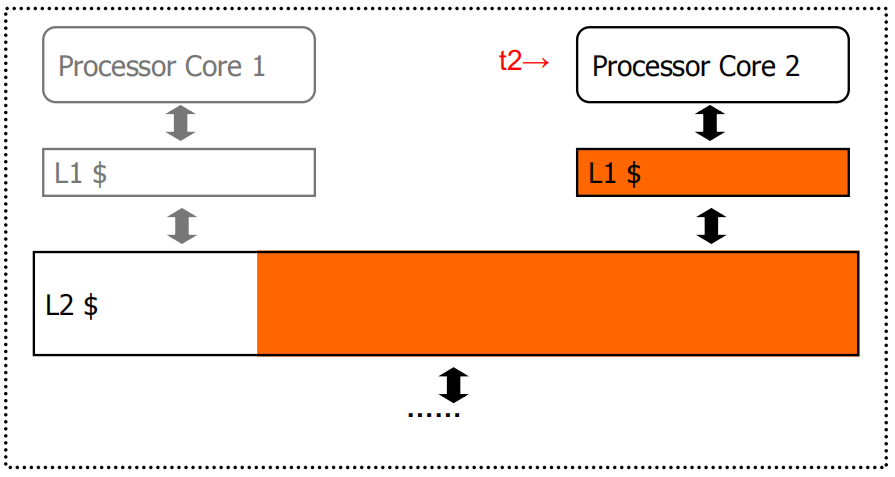
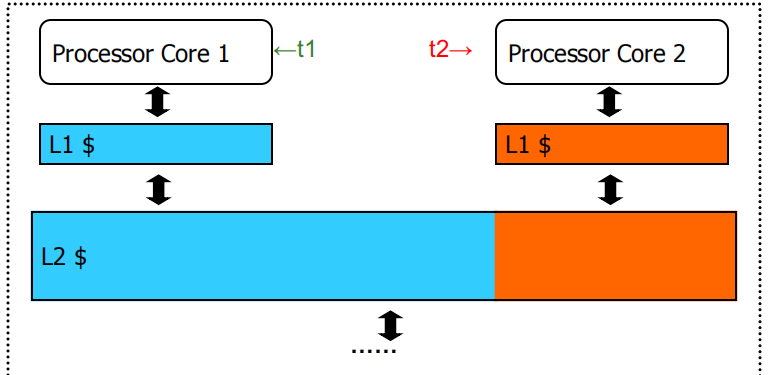
Example:
Core 1单独运行 t1 时需要共享缓存L2中蓝色区域大小的空间,Core 2 单独运行 t2 时需要共享缓存L2中橙色区域大小的空间,当这两个 Core 同时运行时,由于不公平的缓存共享,t2 的吞吐量会大幅降低。
1.3 UCA & NUCA
目前,小尺寸缓存都是统一缓存访问(Uniform Cache Access, UCA):即无论数据在哪里被找到,访问延迟都是一个恒定的值。
对于大型的多兆字节缓存,按最坏情况的延迟来限制访问时间代价太高,因此引入了非均匀缓存架构(Non-Uniform Cache Architecture)。
1.3.1 大型 NUCA
在 NUCA 架构中,CPU与多个缓存单元相连接,每个缓存单元可能有不同的访问延迟,这与传统的统一缓存访问架构不同。由于缓存较大,无法保证所有缓存单元的访问延迟相同,因此引入了NUCA架构来解决这个问题。

NUCA架构中需要解决的几个关键问题:
-
Mapping(映射):如何将内存地址映射到不同的缓存单元,以便高效地存取数据。
-
Migration(迁移):如何在不同缓存单元之间移动数据,以尽量减少访问延迟。例如,频繁使用的数据可以迁移到更接近CPU的缓存单元中。
-
Search(查找):如何高效地搜索缓存中的数据,确保找到目标数据所在的缓存单元。
-
Replication(复制):如何在不同缓存单元中复制数据,以提高访问速度并减少通信延迟。
1.3.2 共享的 NUCA 缓存
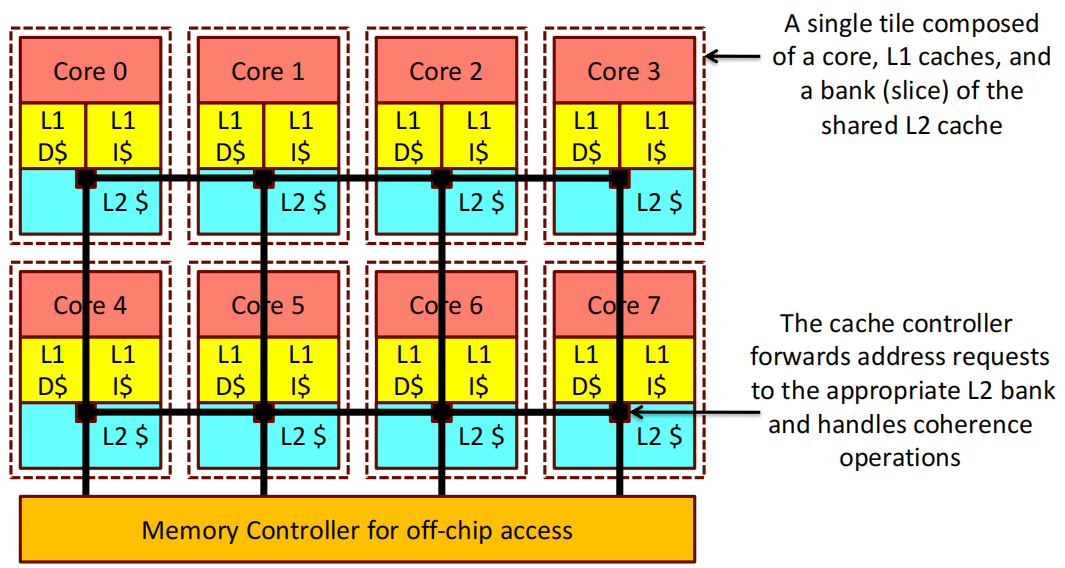
这张图片展示了一个多核处理器的结构,其中每个 Core 都有自己的L1缓存 (L1 D 和 L1 I)以及共享的L2缓存切片 。并且每个 Core 的L1缓存和L2缓存切片组合在一起,构成了一个独立的单元(Tile)。
- 共享的L2缓存:整个L2缓存被分割成多个部分,每个核心拥有一部分L2缓存切片。这种分布式的L2缓存设计可以降低缓存访问延迟,并提升缓存的可扩展性。
- 缓存控制器功能:图中的缓存控制器负责转发地址请求,将请求引导到对应的L2缓存切片,并处理缓存一致性操作。这对于多核处理器中的数据一致性非常重要,确保每个 Core 对共享数据的访问是正确的。
2. 虚拟内存(Virtual Memory)
2.1 虚拟(Virtual) vs. 物理(Physical)内存
-
程序员 看到的是虚拟内存
- 可以认为内存是 "无限的"
-
事实上,物理内存大小比程序员假设的小得多
-
系统 (系统软件+硬件,相互配合)将虚拟内存地址映射到物理内存
- 系统自动管理物理内存空间,对程序员透明
-
**优点:**程序员不需要知道内存的物理大小,也不需要对其进行管理
- 对于程序员来说,一个小的物理内存可能看起来像一个巨大的内存
-
**缺点:**更复杂的系统软件和架构
2.1.1 自动管理内存的优势
-
程序员不处理物理地址
-
每个进程都有自己的虚拟地址与物理地址的映射关系
-
Enables
- 代码和数据可位于物理内存的任何位置**(重定位)**
- 物理内存中不同进程的代码和数据的隔离/分离**(保护和隔离)**
- 多个进程之间的代码和数据共享**(共享)**
2.1.2 仅有物理内存的系统
Examples:
- 早期系统
- 许多嵌入式系统
CPU 的加载或存储地址直接用于访问内存。

该系统存在的问题:
- 物理内存容量有限(成本)
- 程序员是否应该关注物理内存中代码/数据块的大小?
- 程序员是否应该管理从磁盘到物理内存的数据移动?
- 程序员是否应该确保两个进程(不同的程序)不使用相同的物理内存?
- 此外,ISA 的地址空间可以大于物理内存大小
- 例如,64 位地址空间具有字节寻址能力
- 如果没有足够的物理内存怎么办?
2.1.3 直接物理地址访问的困难
程序员需要管理物理内存空间
- 不方便且难以实现
- 在存在多个进程时更难管理
难以支持代码和数据的重分配
- 地址直接在程序中指定,导致灵活性不足
难以支持多个进程
- 难以实现进程之间的保护和隔离
- 共享物理内存空间的问题
难以支持跨进程的数据/代码共享
- 无法方便地在不同进程之间共享数据和代码
2.2 Virtual Memory(虚拟内存)
-
Idea:让程序员产生地址空间大而物理内存小的错觉
- 这样程序员就不用担心物理内存的管理问题了
-
程序员可以假设拥有"无限"的物理内存
-
硬件和软件协同自动管理物理内存空间,以提供这种假象
- 这种假象对每个独立的进程都得以维持
2.2.1 基本机制
-
寻址中的不定向
- 间接层寻址
-
程序中每条指令生成的地址是一个**"虚拟地址"**
- 即,它不是用于访问主存的物理地址
- 在x86架构中称为"线性地址(linear address)"
-
地址翻译 机制将虚拟地址映射到物理地址
-
在x86架构中称为"实际地址(real address)"
-
地址翻译机制可以通过硬件和软件共同实现。
-
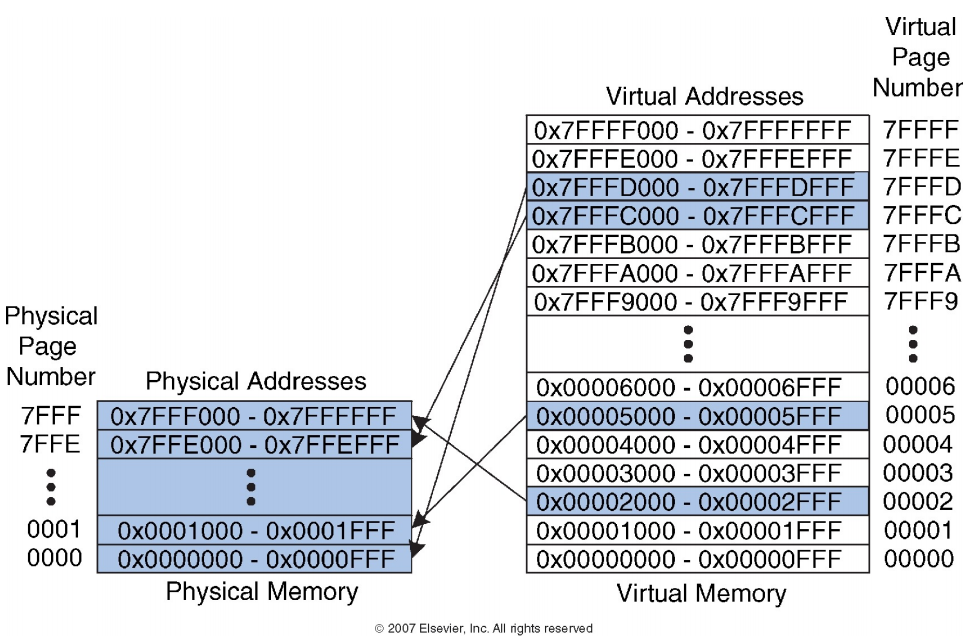
2.2.2 虚拟内存与物理内存之间的映射
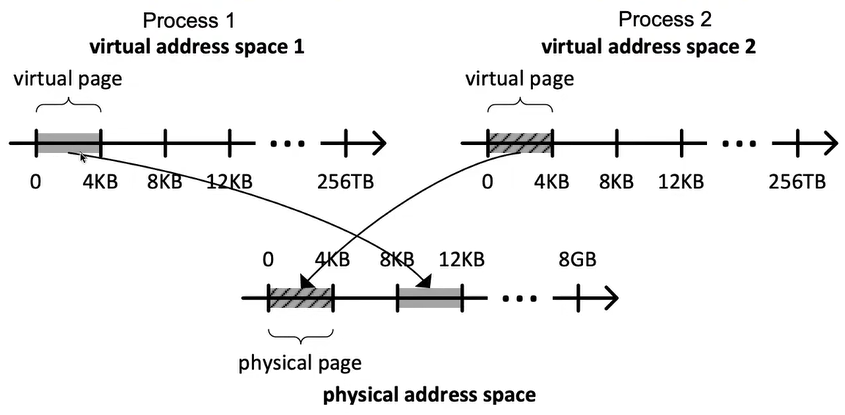
虚拟地址空间:
-
每个进程都有自己的虚拟地址空间,分别标为**"virtual address space 1"** 和**"virtual address space 2"**
-
每个虚拟地址空间大小可以达到 256TB
-
虚拟地址空间被分成虚拟页面(virtual page),每个虚拟页面为4KB
物理地址空间:
- 物理内存空间被分成物理页面(physical page),这些页面与虚拟地址空间中的虚拟页面大小一致(也是 4KB)
地址映射:
- Process 1 的虚拟地址空间中 0-4KB 的虚拟页面映射到物理地址空间中的 8-12KB 物理页面。
- Process 2 的虚拟地址空间中 0-4KB 的虚拟页面映射到物理地址空间中的 0-4KB 物理页面。
2.2.3 拥有虚拟内存的系统(Page based)
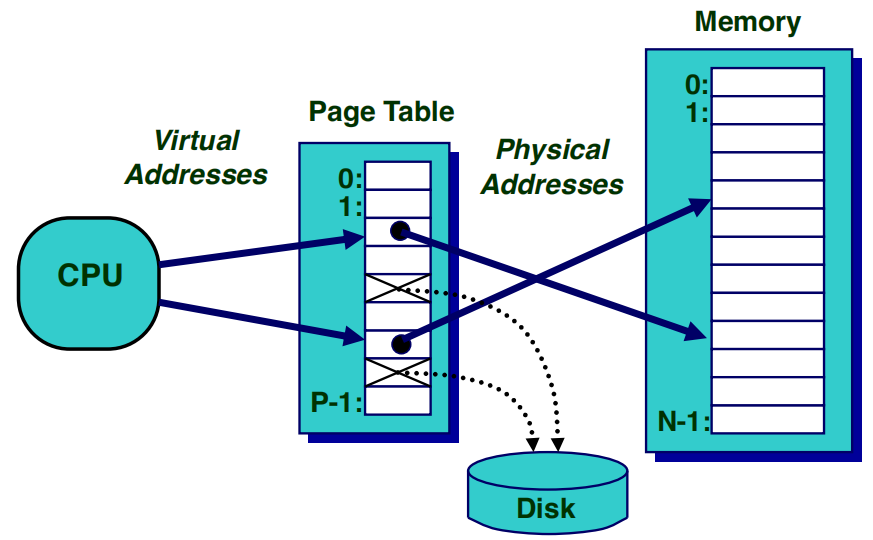
这张图片展示了基于分页机制的虚拟内存系统的工作原理,解释了虚拟地址如何通过页表转换为物理地址。
- 页表(Page Table) :
- 它是一个映射表,用于将虚拟地址转换为物理地址
- 每个虚拟页面(虚拟地址的固定大小块)通过页表映射到对应的物理页面(物理地址的固定大小块)
- 页表是由操作系统管理的,每个进程通常有自己独立的页表,这样不同进程的虚拟地址空间不会相互干扰
- 地址转换 :
- 地址转换(Address Translation)是通过查找页表实现的
- 当 CPU 想要访问某个虚拟地址时,会查询页表以找到对应的物理地址。如果映射存在,虚拟地址被转换成物理地址并访问相应的物理内存
- 如果虚拟地址没有对应的物理页面,可能会发生页缺失(page fault) ,此时需要从磁盘(Disk)中加载所需页面到物理内存中
2.2.4 虚拟页面、物理帧/页(Virtual Pages, Physical Frames)
- Virtual address space divided into pages
- 虚拟地址空间划分为多个页
- Physical address space divided into frames
- 物理地址空间划分为多个物理帧
- 虚拟页面 可以映射到:
- 物理帧(如果该页在物理内存中)
- 磁盘中的某个位置(如果该页不在物理内存中)
- 如果访问的虚拟页不在内存中,而在磁盘上:
- 虚拟内存系统将该页从磁盘载入物理页,并建立映射关系 ------ 这称为需求分页
- **页表(Page Table)**是存储虚拟页与物理页框映射关系的表
2.2.5 物理内存作为缓存
换句话说,物理内存是用于存储在磁盘上的页面的缓存。
事实上,在现代系统中,它是一个全关联缓存(虚拟页面可以映射到任何物理帧)
与我们之前讨论的缓存问题类似,这里也有类似的问题:
- 放置:如何在缓存中放置或找到一个页面?
- 替换:当缓存空间不足时,移除哪个页面以腾出空间?
- 管理粒度:页面应该是大、小还是统一大小?
- 写入策略:如何处理写操作?是写回还是其他策略?
2.2.6 虚拟内存定义
很多概念都可以进行类比:
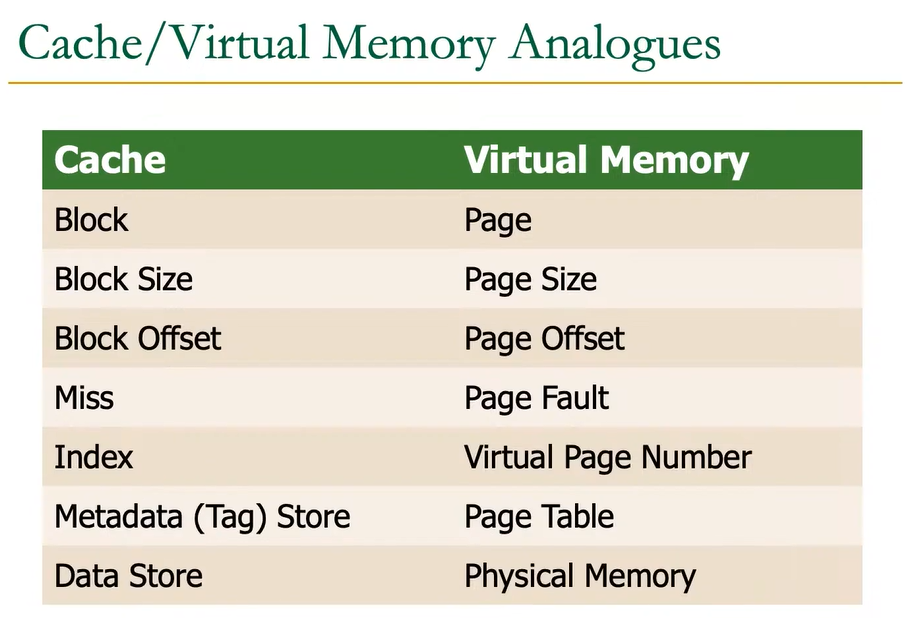
- 页面大小(Page Size):一次从硬盘传输到 DRAM 的内存量
- 地址转换(Address translation): 从虚拟地址确定物理地址
- 页表(Page table):用于将虚拟地址转换为物理地址(并查找关联数据的位置)
2.2.7 虚拟地址和物理地址
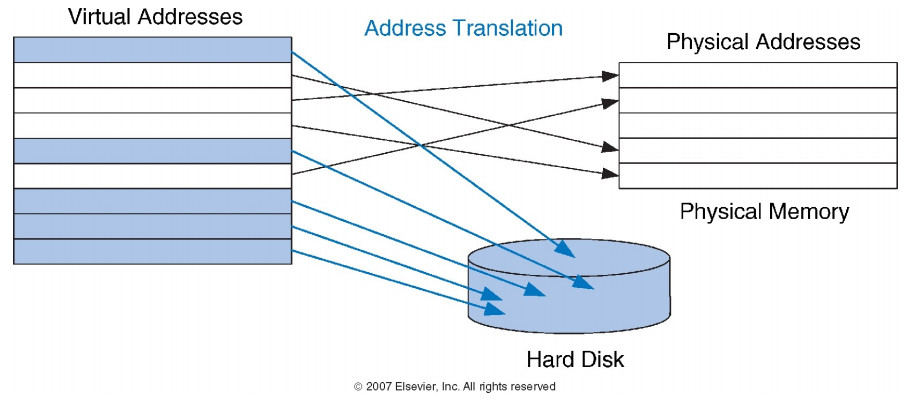
-
大多数访问都在物理内存中进行
-
但程序看到的虚拟内存容量很大
Example:
虚拟页面映射到物理页面的灵活性使得物理内存可以作为一个缓存,存储当前活跃的页面,同时支持地址空间隔离和更大的虚拟地址空间。
2.3 地址转换(Address translation)
- 虚拟内存和物理内存被分成若干页
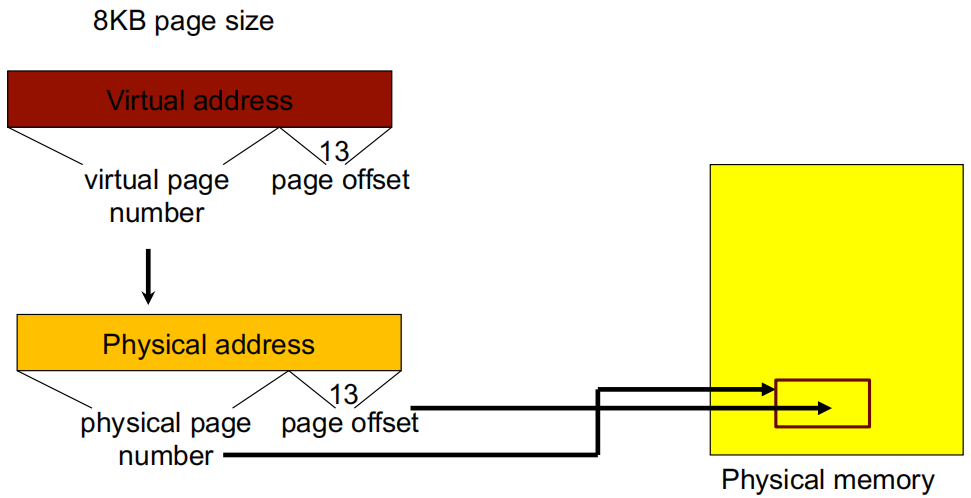
如上图所示,虚拟内存和物理内存都被划分为页(pages),每页大小为8KB。
-
**虚拟地址(Virtual Address)**分为两部分:
-
虚拟页号(Virtual Page Number):用于定位虚拟内存中的具体页。
-
页内偏移(Page Offset):13位偏移量,用于指定该页内的具体位置。
-
-
**物理地址(Physical Address)**分为两部分:
- 物理页号(Physical Page Number):虚拟页号通过页表转换得到的物理页号。
- 页内偏移(Page Offset):与虚拟地址中的偏移保持不变,直接映射到物理地址的偏移位置。

- 页表(Page Table): 每个进程有自己独立的页表。虚拟页号 (VPN) 作为页表的索引,用于在页表中查找对应的页表条目 (PTE)。
- 页表条目 (Page Table Entry, PTE): 每个 PTE 提供与页面相关的信息,包括有效位 (valid) 和物理帧号 (PFN) 。有效位指示页面是否在内存中。如果有效位为 0,表示页面不在内存中,会触发缺页异常 (page fault)。
- 物理地址生成: 通过查找页表,获取对应的物理帧号 (PFN) ,然后与页偏移 (page offset) 结合生成物理地址。
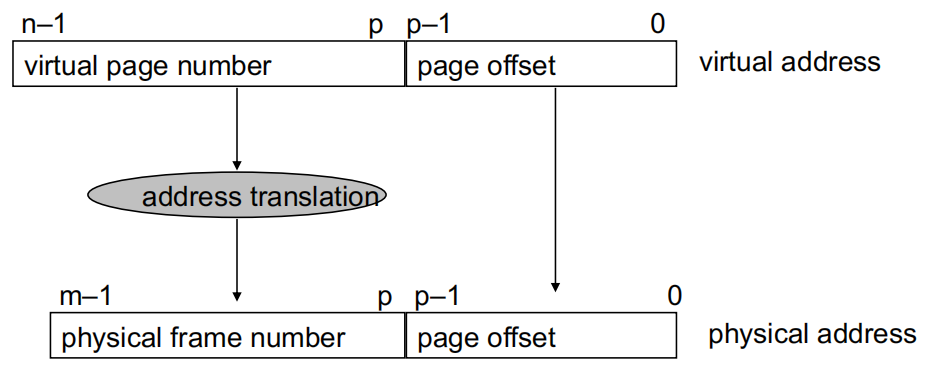
-
参数定义:
-
\(P=2^p\):页面大小,以字节为单位。
-
\(N=2^n\):虚拟地址空间大小。
-
\(M=2^m\):物理地址空间大小。
-
-
页偏移位在转换过程中不会改变。
2.3.1 Example
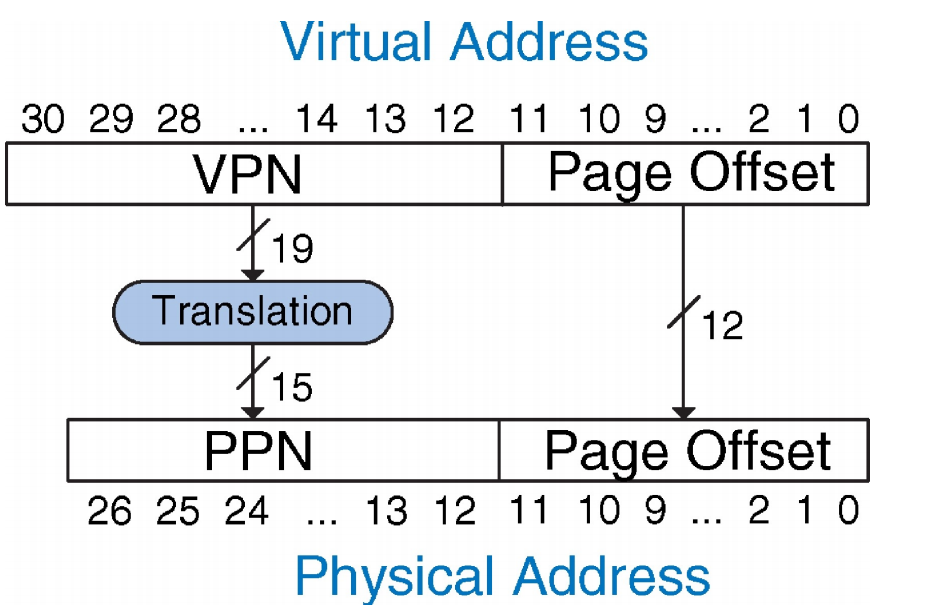
如上图所示:
-
系统配置:
-
虚拟内存大小:\(2\ GB = 2^{31}\ bytes\)
-
物理内存大小:\(128\ MB = 2^{27}\ bytes\)
-
页大小:\(4\ KB = 2^{12}\ bytes\)
-
-
组织结构:
-
虚拟地址:31 位
-
物理地址:27 位
-
页偏移:12 位
-
虚拟页数量 = \(2^{31} / 2^{12} = 2^{19}\)(虚拟页号占 19 位)
-
物理页数量 = \(2^{27} / 2^{12} = 2^{15}\)(物理页号占 15 位)
-
2.3.2 我们如何翻译地址?
-
页表(Page Table)
- 每个虚拟页面都有页表条目
-
每个页表条目都有:
- **有效位(Valid bit):**虚拟页是否位于物理内存中(如果不是,则必须从硬盘获取)
- **物理页码(Physical page number):**虚拟页在物理内存中的位置
- (替换策略,脏位)
2.3.3 页表访问
-
我们如何访问页表?
-
页表基址寄存器(Page Table Base Register, PTBR)(x86 中为 CR3)
-
页表限制寄存器(Page Table Limit Register, PTLR)
-
如果虚拟页号 (VPN) 超出范围(超过 PTLR),则表示该进程未分配此虚拟页 -> 产生异常
-
页表基址寄存器是进程上下文的一部分
-
就像程序计数器 (PC)、状态寄存器和通用寄存器一样
-
当进程进行上下文切换时需要加载
-
2.3.4 页表地址转换Example
- 示例页表:
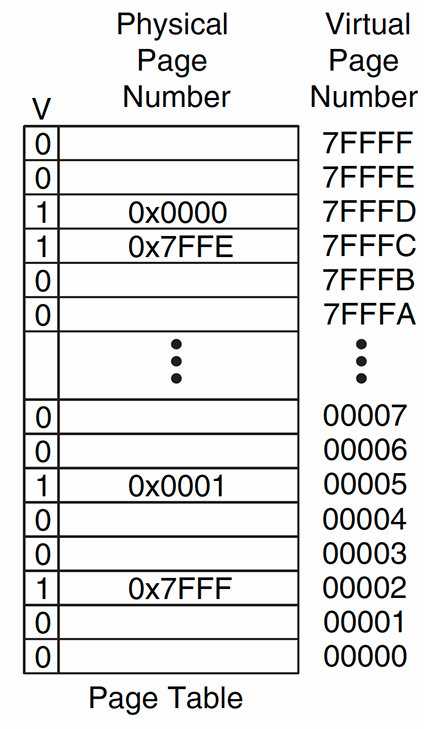
2.3.4.1 Example1
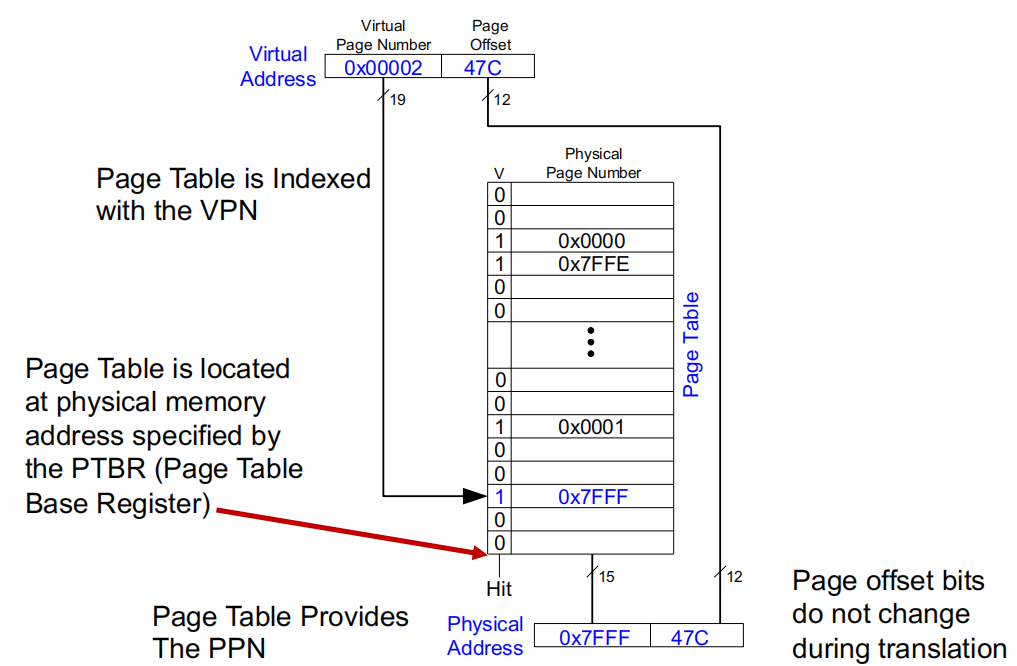
虚拟地址结构 :虚拟地址由虚拟页号 (VPN) 和页偏移组成。在上图中,虚拟地址的虚拟页号为 0x00002,页偏移为 47C。
页表的索引:页表使用 VPN 作为索引,用于查找对应的物理页号 (PPN)。在图片中,页表中每一行代表一个页面映射条目,其中"V"位表示该条目是否有效。
页表基址寄存器 (PTBR) :页表位于物理内存中,通过页表基址寄存器 (PTBR) 指定其起始地址。PTBR 提供了访问页表的入口。
页表提供 PPN :页表条目中包含物理页号 (PPN)。对于 VPN 为 0x00002 的条目,页表给出了相应的物理页号 0x7FFF。
地址转换 :最终的物理地址由 PPN 和页偏移组合而成。在这个例子中,转换得到的物理地址是 0x7FFF47C。
页偏移不变:在地址转换过程中,页偏移部分不发生变化,直接从虚拟地址传递到物理地址。
2.3.4.2 Example2
- 我们首先需要找到包含对应 VPN 转换的页表条目。
- 在地址
PTBR + VPN * PTE-size处查找 PTE。
**Problem:**虚拟地址 0x5F20 的物理地址是什么?
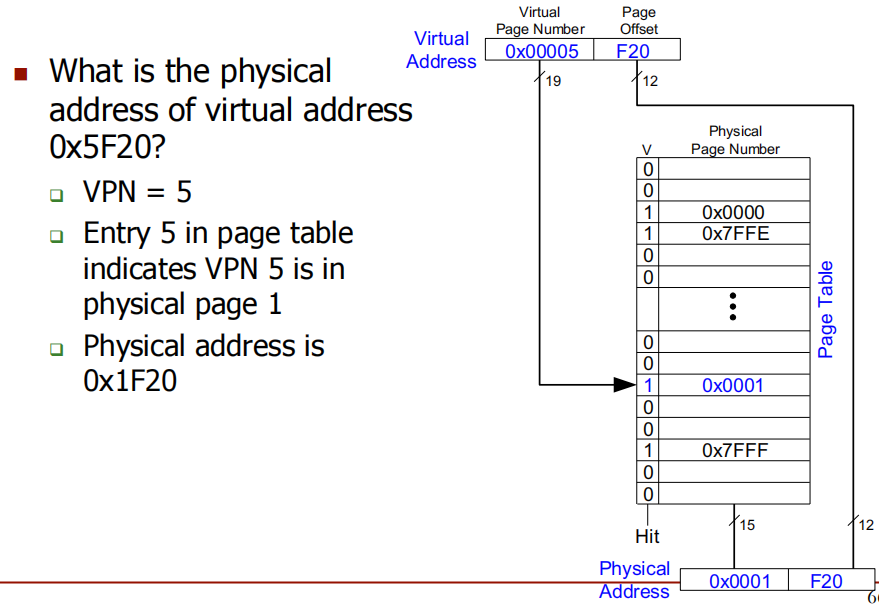
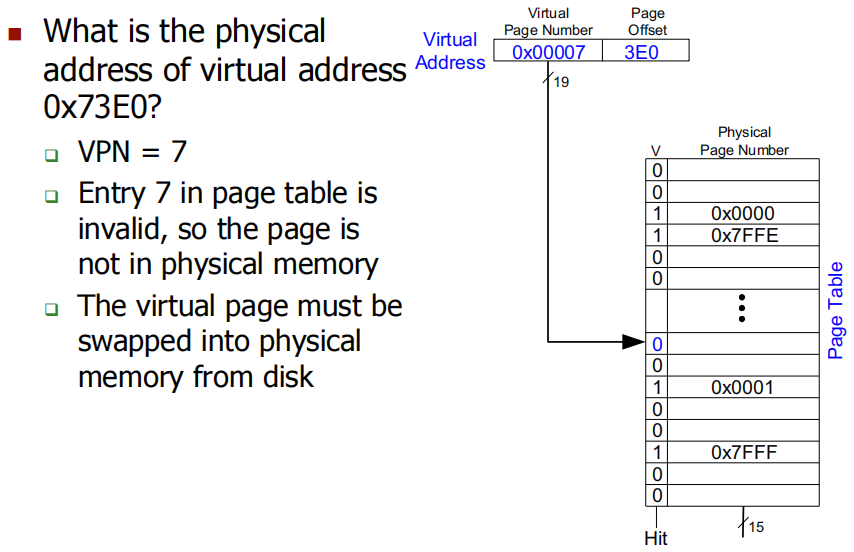
**Problem:**虚拟地址 0x73E0 的物理地址是什么?invalid,需要去Disk找
2.3.5 内存层次结构属性
-
虚拟内存页可以放置在物理内存中的任意位置(全相联)。
-
替换通常使用 LRU 策略(因为缺页的代价很大,所以我们可以投入一些努力来减少缺页)。
-
使用页表(按虚拟页号索引)将虚拟页号转换为物理页号。
-
内存-磁盘层次结构可以是包含式或排除式 ,写策略为写回(write-back)。
3. 虚拟内存面临的一些挑战
3.1 页表(Page Table)挑战
-
Challenge 1: Page table is large 页表很大
- 至少有一部分需要位于物理内存中
- 解决方案:多级页表
-
Challenge 2:每个指令获取或数据访存至少两次内存访问:
- 一个用于地址转换(页表读取)
- 一个是使用物理地址访问数据(地址转换后)
- 两次内存访问指令获取或数据访存会大大降低执行时间
- 加快地址转换速度
-
Challenge 3:我们什么时候进行与缓存访问相关的转换?
3.2 Challenge1:页表大小

64 位虚拟地址(VA)被分成两部分,前52位是虚拟页号(VPN),后12位是页偏移(Page Offset),经过地址转换后变为 40 位物理地址(PA)。
- 假设 64 位 VA 和 40 位 PA,页表有多大?
- \(2^{52}个条目 \times 4\ bytes \approx 2^{54}\ bytes\)
- 而这仅仅是针对一个进程!而且该进程可能并没有使用整个虚拟机空间!
解决方法:多级页表
将页表组织成层次结构,这样只有一小部分的第一级页表需要位于物理内存中。
- 一级页表必须位于物理内存中
- 物理内存中只能保留所需的二级页表
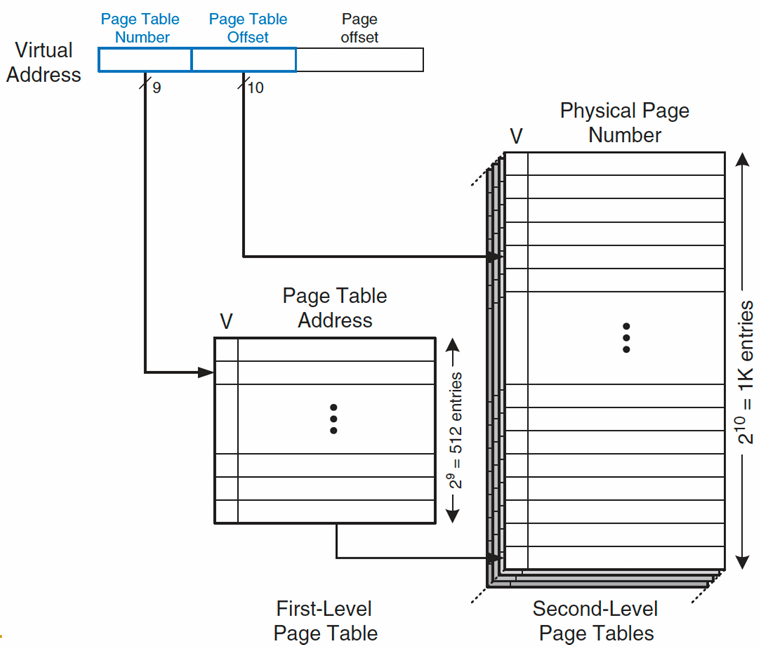
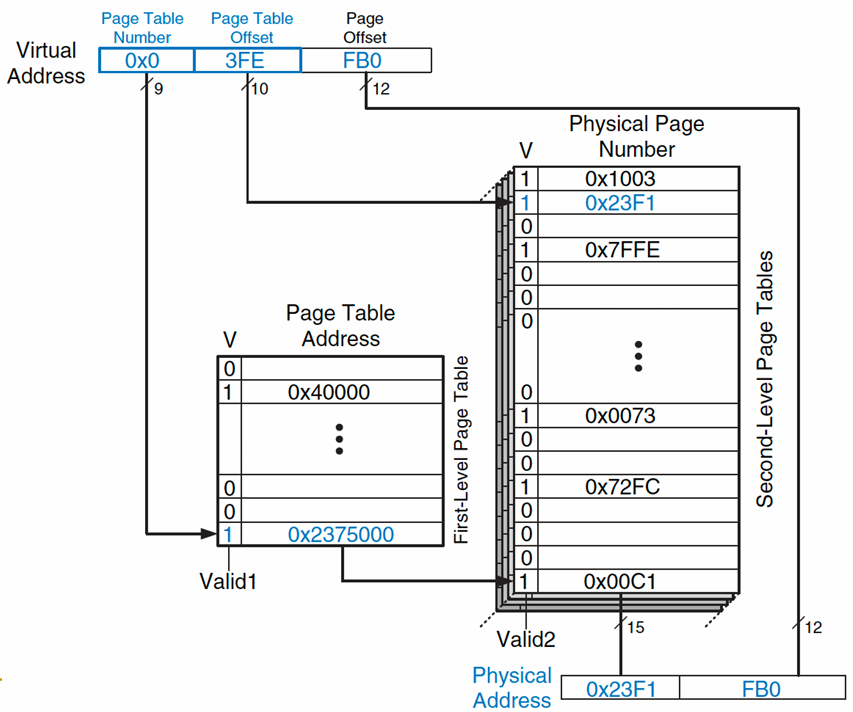
- 对于 N 级页表,我们需要 N 次访问页表才能找到 PTE
x86 架构示例:
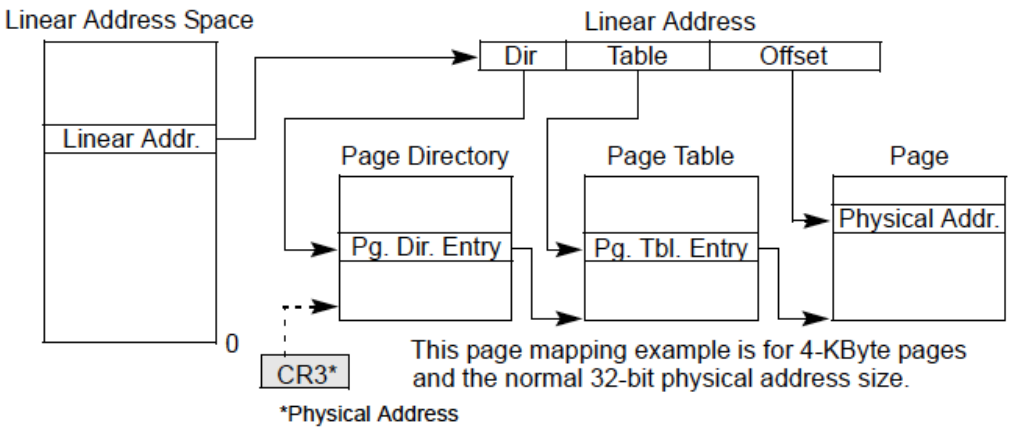
上图展示了线性地址到物理地址的映射过程,采用了两级页表的地址转换机制。这是一个基于 4KB 页表大小、32位物理地址空间的例子。
-
线性地址空间:线性地址由"目录"(Dir)、"表项"(Table)和"偏移"(Offset)三部分组成。这些字段用于索引分页结构以找到对应的物理地址。
-
页目录和页表:
-
页目录(Page Directory):线性地址的"目录"部分用于索引页目录,从而找到对应的页目录项(Pg. Dir. Entry)。
-
页表(Page Table):页目录项指向页表的位置。线性地址的"表项"部分用于索引页表,找到对应的页表项(Pg. Tbl. Entry)
-
-
物理地址:
- 页表项包含了指向具体物理页面的地址。在页表项中找到物理页面后,再加上线性地址中的"偏移"部分,就得到了完整的物理地址。
-
CR3寄存器:CR3寄存器保存页目录的物理地址,在地址转换时用于定位页目录。
优点:这种方法在不需要用到所有虚拟地址空间时特别有效,因为每一级的页表只有在需要时才会分配,从而减少了内存的浪费。
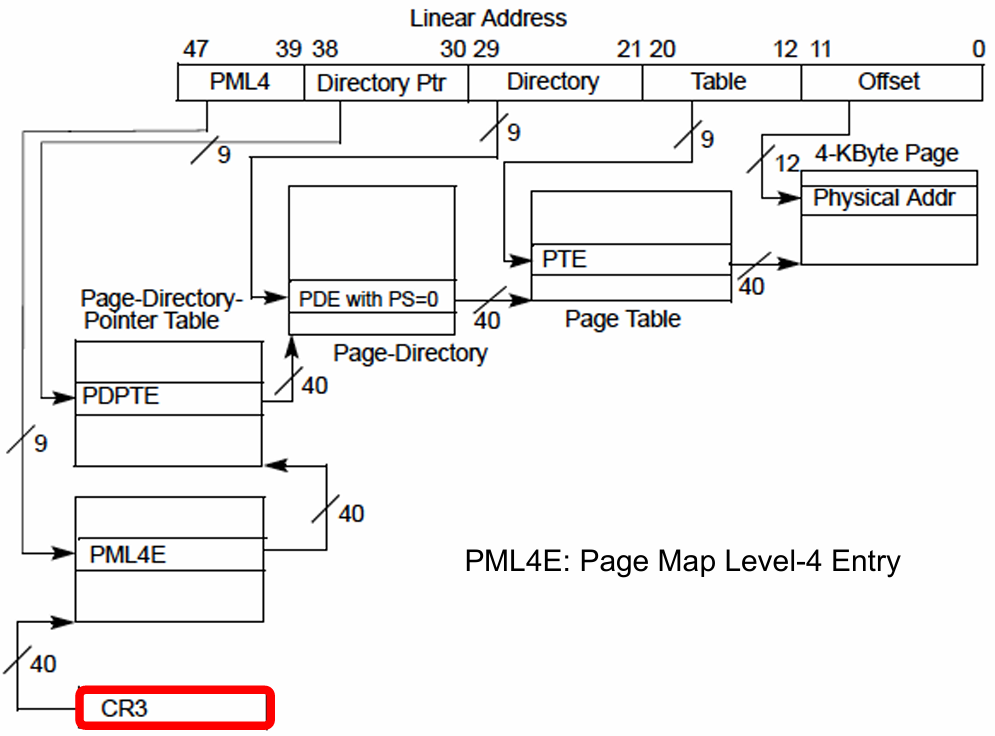
x84-64的4级页表:
3.3 Challenge2:至少两次内存访问
- Idea :使用一种硬件结构来缓存页表项(PTE) → 转译后备缓冲区(Translation lookaside buffer,TLB)
- TLB 未命中 时该如何处理?
- 替换哪个 TLB 条目?
- 谁来处理 TLB 未命中?硬件 还是软件?
- 页面错误 时该如何处理?
- 从物理内存中替换哪个虚拟页?
- 谁来处理页面错误?硬件 还是软件?
3.3.1 转译后备缓冲区(Translation lookaside buffer,TLB)
-
Idea:将页表条目(PTE)缓存在处理器的硬件结构中,以加快地址转换
-
Translation lookaside buffer(TLB):
-
缓存最近使用的 PTE
-
将大多数指令获取和数据访存所需的内存访问次数减少到只有一个
-
-
页表访问具有很大的时间局部性
- 数据访问具有时间和空间局部性
- Large page size (say 4KB, 8KB, or even 1-2GB)
- 连续的指令和访存大概率会访问同一页面
-
TLB
- 小:在 ~ 1 个周期内访问
- 一般为 16 - 512 个条目
- 高关联性
- \(>95-99\%\) 的典型命中率(取决于工作量)
- 将大多数指令获取和加载/存储的内存访问次数减少到只有一次
3.3.2 使用 TLB 加快地址转换速度
- 本质上是最近地址转换的缓存
- 避免每次引用都进入页表
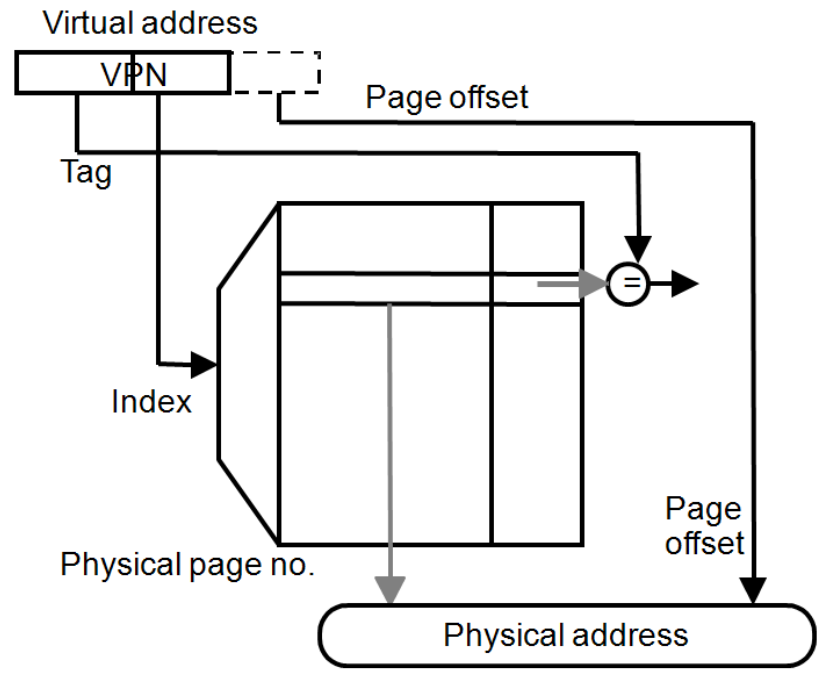
-
Index:使用虚拟页号(VPN)的低位作为索引,用于快速查找对应的条目。
-
Tag:使用 VPN 的未使用位和进程 ID 组成标签,用于确保唯一识别虚拟页。
-
Data:存储页表项(PTE)的内容,即物理页号(PPN)。
-
Status:记录状态信息,如条目的有效性(valid)和是否被修改(dirty)。
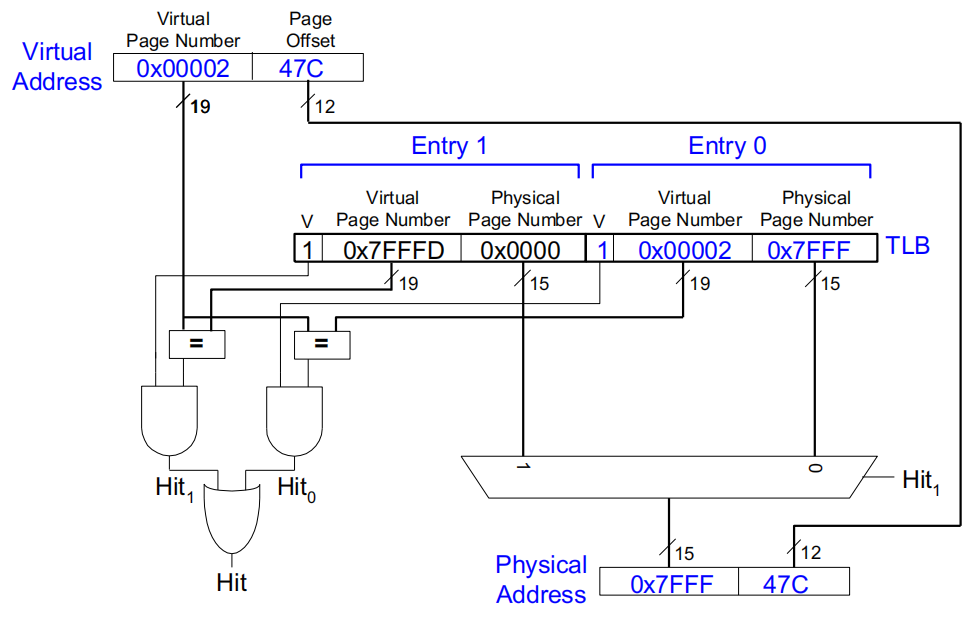
流程:
-
输入的虚拟地址由 VPN 和页偏移(Page offset)组成。
-
使用 VPN 与 TLB 的索引匹配,通过标签验证条目是否有效。
-
如果找到有效条目,将物理页号与页偏移组合得到物理地址。
-
如果没有找到有效条目(TLB 缺失),则需要查找页表。
3.3.3 处理 TLB Misses
- TLB容量很小,无法容纳所有PTE
- 某些转译不可避免地会在TLB中miss
- 必须访问内存才能找到合适的PTE
- 称为走页目录/表
- 性能损失大
- 谁来处理 TLB 的miss? 硬件还是软件?
方法 1. 硬件管理(如 x86)
- 硬件执行**走页(page walk)**操作
- 硬件获取 PTE 并将其插入 TLB
- 如果 TLB 已满,条目将替换另一个条目
- 对系统软件透明完成
方法 2. 软件管理(如 MIPS)
- 硬件引发异常
- 操作系统执行**走页(page walk)**操作
- 操作系统获取 PTE
- 操作系统在 TLB 中插入/删除条目
3.4 Challenge3:什么时候进行与缓存访问相关的转换
- TLB 和 L1 缓存之间的关系
- 地址转换和缓存
- 何时进行地址转换?
- 在访问 L1 缓存之前还是之后?
4. 虚拟内存支持和示例
4.1 支持虚拟内存
虚拟内存需要硬件和软件的支持:
- 页表存储在内存中
- 可以缓存在称为转译后备缓冲区(TLB)的特殊硬件结构中
硬件组件称为 MMU(memory management unit 内存管理单元):
- 包括页表基地址寄存器、TLB 和页表遍历器
软件的职责是利用 MMU 来:
- 填充页表,并在物理内存中决定替换哪些页面
- 在进程切换时更改页表寄存器(以使用当前运行线程的页表)
- 处理页错误并确保正确的映射
4.2 地址转换
页大小由 ISA(指令集架构)指定
- 目前常用的页大小:4KB、8KB、2GB......(小页和大页混合使用)
- 权衡因素?(类比缓存块)
每个虚拟页都有一个页表项(PTE)
- 页表项(PTE)中包含什么内容?
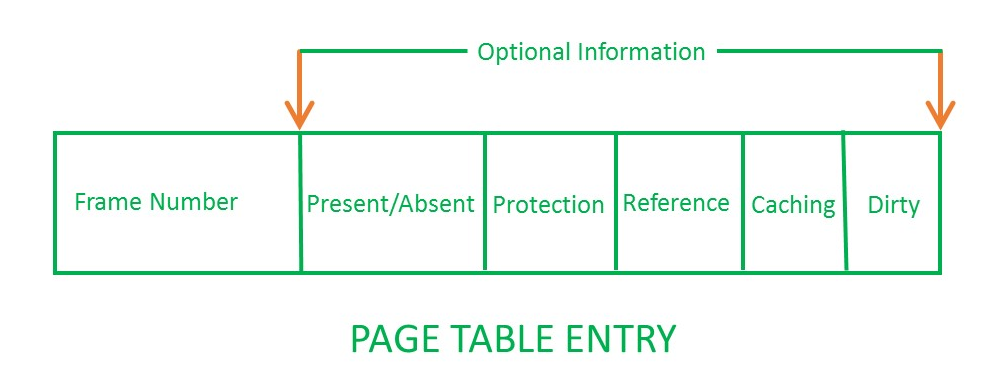
4.3 页表项 (Page Table Entry,PTE) 的内容
页表是物理内存数据存储的"Tag Store":
- 一个虚拟内存和物理内存之间的映射表
页表项(PTE)是内存中虚拟页的"Tag Store Entry":
- 需要一个有效位(valid bit)来指示在物理内存中的有效性/存在性(图中对应"Present/Absent"位)
- 需要标签位(物理帧号 PFN)来支持地址转换(图中对应"Frame Number"位)
- 需要位来支持替换机制(图中对应"Reference"位)
- 需要一个脏位(dirty bit)来支持"写回缓存"
- 需要保护位(protection bits)来启用访问控制和保护
4.4 页面故障(Page Fault)("A Miss in Physical Memory")
如果页面不在物理内存中而在磁盘中:
- 页面表条目(Page Table Entry)会指示该虚拟页面不在内存中。
- 访问此类页面会触发页面错误异常(Page Fault Exception)。
- 操作系统的异常处理程序会被调用,将数据从磁盘移动到内存中。
- 在此期间,其他进程可以继续执行。
- 操作系统可以完全控制数据的放置。
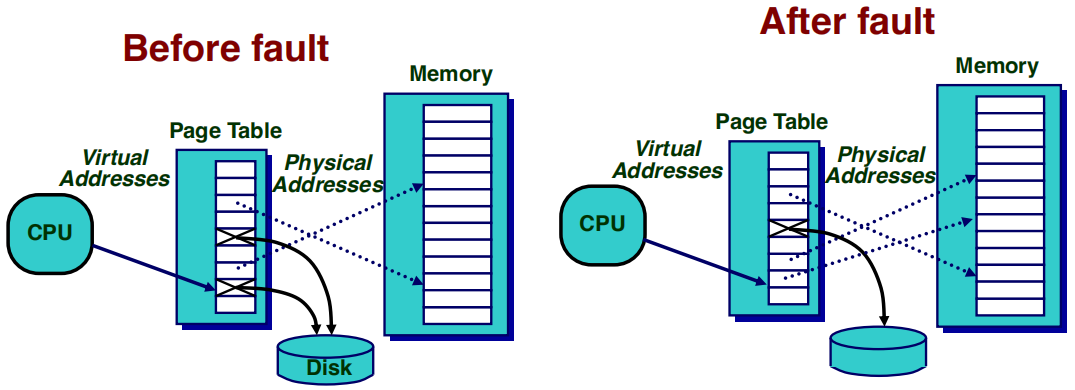
Before Fault(发生页面错误之前):
- CPU试图访问一个虚拟地址,对应的页面表项指示页面并不在物理内存中。
- 页面在磁盘中,所以页面表中没有有效的物理地址。
- 操作系统检测到页面错误,触发异常处理,将页面从磁盘加载到物理内存中。
After Fault(页面错误处理完成后):
- 处理程序完成后,页面被成功加载到物理内存中。
- 页面表项更新,现在指向物理内存中的实际地址。
- CPU再次访问该虚拟地址时,可以直接通过更新后的页面表找到物理地址。
4.5 地址转换:Page Hit
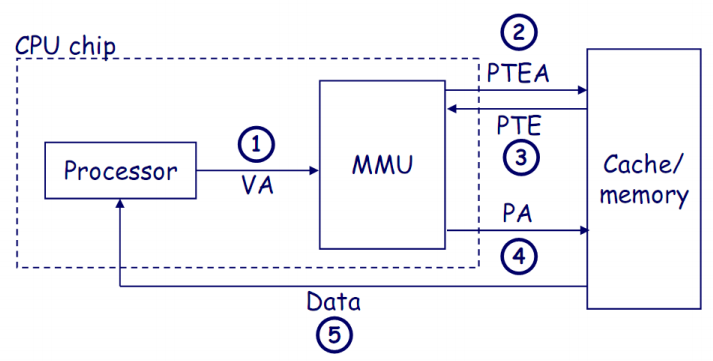
上图展示了处理器通过MMU(内存管理单元)将虚拟地址转换为物理地址,并从缓存或内存中获取数据的过程。
- **处理器发送虚拟地址(VA)到MMU:**处理器生成一个虚拟地址(VA)并将其发送给MMU,以请求访问存储在内存中的数据。
2-3. **MMU从内存中的页表获取PTE(页表项):**MMU使用虚拟地址查找页表项(PTE),以获取虚拟地址和物理地址之间的映射关系。如果页表项不在TLB中,MMU会从内存中获取相应的PTE。
- **MMU从页表获取PTE并生成物理地址(PA)并发送到一级缓存(L1 Cache):**通过PTE中的信息,MMU将虚拟地址转换为物理地址(PA),转换后的物理地址传递给L1缓存,从而加快数据访问速度。
- **L1缓存将数据字发送到处理器:**L1缓存从相应的物理地址获取数据,并将数据字传回处理器,完成数据请求。
4.6 地址转换:Page Fault
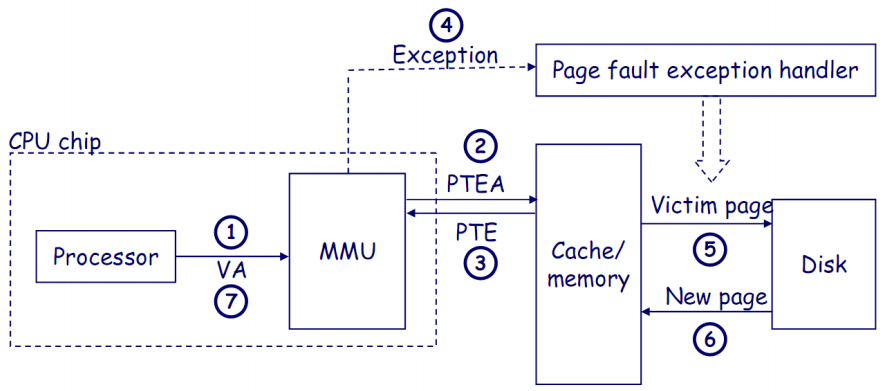
上图展示了在地址转换过程中发生缺页异常(Page Fault)的处理过程。
-
处理器发送虚拟地址(VA)到MMU:处理器生成一个虚拟地址并将其发送给MMU,MMU负责将虚拟地址转换为物理地址。
-
MMU从页表中获取页表项地址(PTEA):MMU通过虚拟地址查找对应的页表项地址(PTEA)以获取页表项(PTE)。
-
MMU从页表中获取页表项(PTE):MMU访问内存中的页表项(PTE),以确定虚拟地址是否在物理内存中。
-
有效位(valid bit)为0,MMU触发缺页异常:如果页表项中的有效位为0,表示该页面不在物理内存中,MMU触发缺页异常(Page Fault Exception),将控制权交给缺页异常处理程序。
-
异常处理程序识别替换页面,如果页面是脏页,则写回磁盘:异常处理程序选择一个页面作为"牺牲页"(Victim Page),如果该页面是脏页,则将其内容写回磁盘,以便腾出空间。
-
异常处理程序从磁盘加载新页面,并更新内存中的页表项(PTE):异常处理程序从磁盘加载所需的页面到物理内存中,并更新页表项,使得虚拟地址可以正确映射到新的物理地址。
-
处理程序返回原进程,重新执行引发缺页的指令:在页面加载完成后,处理器重新执行引发缺页的指令,使用正确的物理地址完成操作。
4.7 缓存 vs. 页面替换
-
物理内存(DRAM)是 Disk 的缓存
- 通常由系统软件通过虚拟内存子系统进行管理
-
页面替换与缓存替换类似
-
页表是物理内存数据存储的 "tag store"
-
区别是什么?
- 缓存与物理内存的访问速度要求
- 缓存与物理内存的 block 数
- 找到替代候选块的 "可容忍 "时间(Disk 与内存的访问延迟)
- 硬件与软件的作用
4.8 页面替换算法
-
如果物理内存已满(即可用物理页列表为空),则在错页时要替换哪个物理页?
-
使用 True LRU 是否可行?
- 4GB 内存,4KB 页面,排序的可能性有多少?
- 一共有 \(4GB/4KB=1000000\),因此排序可能性为其阶乘 \(1000000!\)
-
现代系统使用 LRU 的近似算法
- 例如 CLOCK 算法
-
以及考虑到使用 "频率 "的更复杂算法
- e.g. ARC算法
4.9 时钟页面替换算法
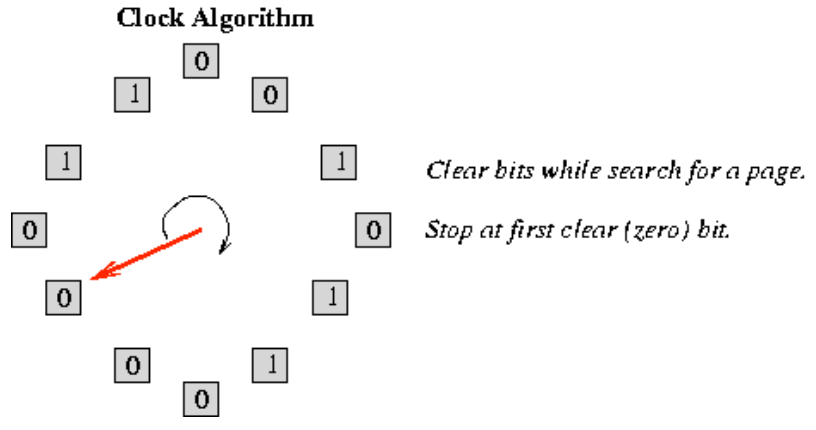
上图为 时钟页面替换算法 的工作原理。该算法用于决定在内存不足时需要将哪个页面置换出去,以便为新页面腾出空间。具体内容如下:
- 循环链表:操作系统会在内存中保持一个物理帧的循环列表。这个循环列表就像一个时钟的表盘,每个物理帧对应一个"钟点"。
- 指针(Hand):CLOCK算法使用一个"指针"或"手"(hand),指向最近被检查的帧。当需要进行页面置换时,指针会顺时针扫描列表,寻找合适的页面来置换。
- 引用位(R 位):当一个页面被访问时,其页表项(PTE)中的引用位(R 位)会被设置为1,以表示该页面最近被使用过。
- 替换规则 :
- 当需要替换页面时,CLOCK算法从指针所指的物理帧开始,顺时针扫描列表。如果找到一个引用位(R 位)为0的帧,就选择它作为替换目标。
- 如果扫描到的帧的R位为1,则将其清零,然后继续移动指针寻找下一个帧,直到找到R位为0的帧为止。
- 指针更新:当找到一个合适的页面进行置换后,指针会指向下一个帧,准备进行下一次置换。
CLOCK 算法的优势:
- CLOCK算法是一种改进的 FIFO 置换算法,它利用引用位来判断页面是否在近期被访问,避免频繁地置换活跃页面。
- 通过循环遍历的方式,CLOCK算法实现了页面的"近似LRU"置换,但实现成本低于真正的LRU算法。