1. 内存架构和子系统
1.1 如何控制访问?
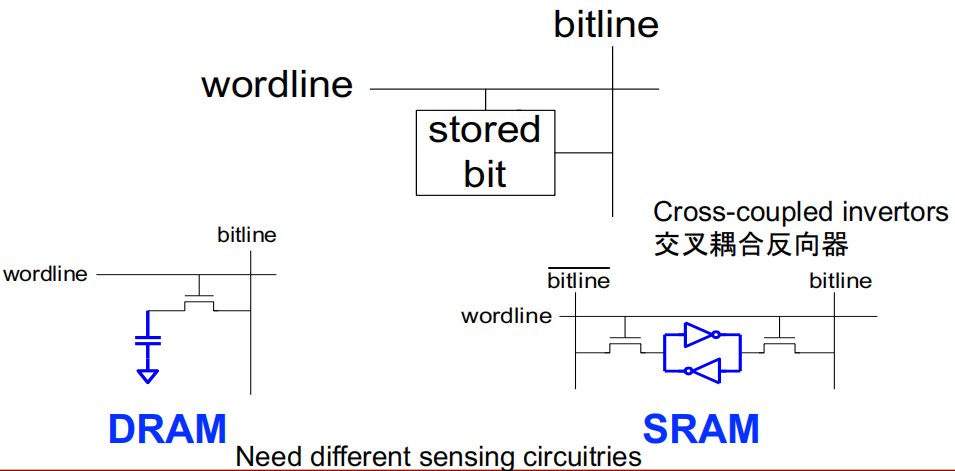
访问控制:
- 存储单元的访问是通过 访问晶体管(access transistors) 进行控制的。访问晶体管像开关一样,可以连接或断开存储单元和位线(bitline)的连接。
- 存取控制由 字线(wordline) 控制。当字线激活时,访问晶体管开启,允许存储单元的数据流入或流出位线。
DRAM(Dynamic random access memory)的结构:
- DRAM 中的存储单元通常由一个电容和一个晶体管组成。电容用来存储数据(1或0),而晶体管作为访问开关。
- 由于电容会泄漏电荷 ,DRAM 需要周期性刷新数据来保持信息的完整性。
SRAM 的结构:
- SRAM 中的存储单元由 交叉耦合反相器(cross-coupled inverters) 组成,通常是两个反相器互相连接,形成一个稳定的双稳态结构。
- SRAM 需要 4 个晶体管用于存储,2 个晶体管用于访问。
- SRAM 不需要像 DRAM 那样周期性刷新数据,因为它的电路结构使其能够长时间保持数据,直到被改写。
差异:
- DRAM 的电路结构相对简单,占用的物理空间小,因此具有更高的存储密度,但需要刷新电路。
- SRAM 的电路结构更复杂,占用更多的空间,因此存储密度较低,但其访问速度较快且不需要刷新。
1.2 内存架构
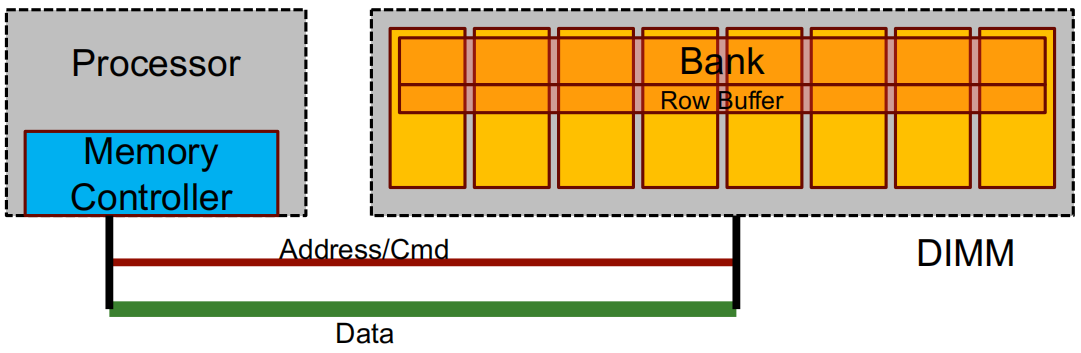
DIMM: 背面和正面装有 DRAM 芯片的印刷电路板。
Rank:一组 DRAM 芯片,它们协同工作以响应请求并保持数据总线满载。
64位 数据总线需要 8x8 DRAM 芯片 或 4x16 DRAM 芯片...
Bank :在一次请求期间 忙碌的一个rank的子集。
行缓冲区(Row buffer): 从组中读取的最后一行(如 8 KB),作用类似于缓存。
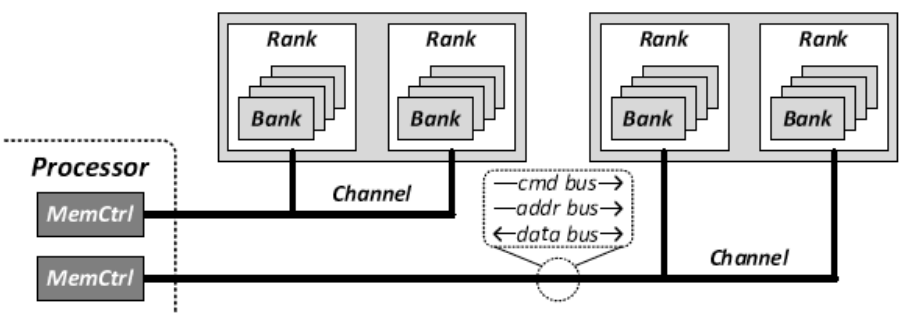
通道(Channel) :每个通道通过命令总线(cmd bus)、地址总线(addr bus)和数据总线(data bus)与处理器相连,用于发送命令、地址和数据。这些总线允许处理器并行地与多个内存模块进行交互 ,从而提高系统的并行性。
内存控制器(MemCtrl) :处理器通过内存控制器(MemCtrl)来管理对内存的访问。内存控制器负责内存请求的调度,并通过通道将数据发送到内存的特定区域。
Rank :在存储器模块中,每个通道包含一个或多个rank 。rank是由多个bank组成的 ,它们在处理数据时可以同时访问。
Bank :每个rank包含多个bank,bank是rank的子集,每次访问期间只有一个bank处于繁忙状态。 每个bank可以独立 进行数据的存储和访问,使得系统能够在不同的bank之间并行处理数据,进一步提高内存的效率和带宽。
这种分层结构允许内存系统在不同的bank和rank之间进行并行访问,提高了内存带宽和数据处理效率。这种设计被广泛应用于DRAM中,以减少延迟并提高数据吞吐量。
1.3 DRAM 阵列访问
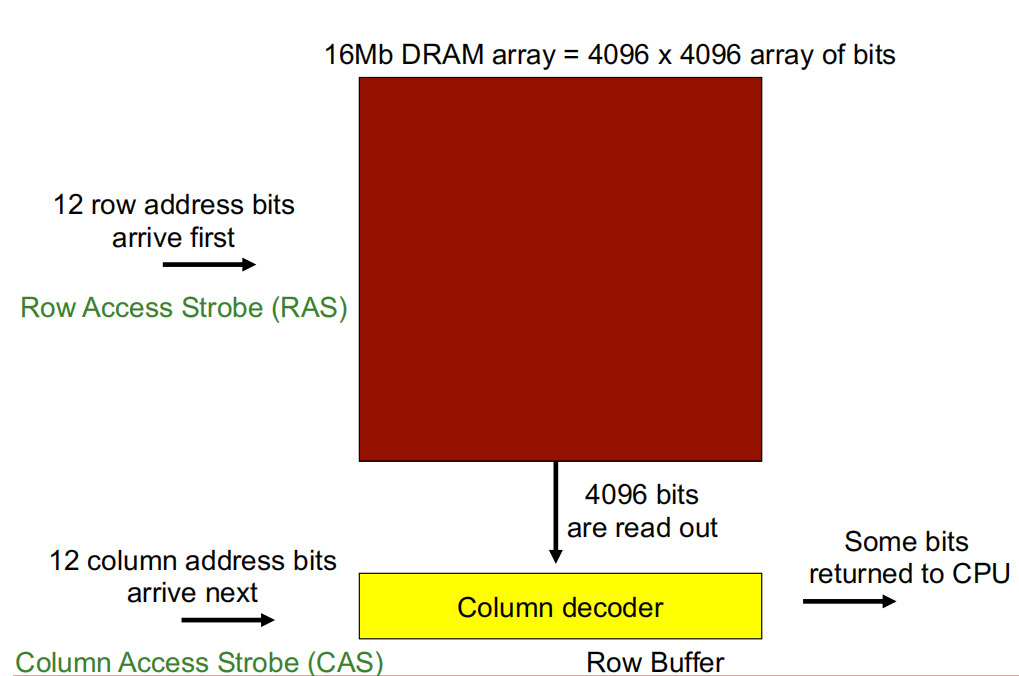
这是一个 \(16Mb\) 的DRAM阵列,即有 \(4096\times4096\) 阵列的bits。
行访问选通 (Row Access Strobe, RAS): 由于该DRAM阵列有4096行,因此有\(log_{2}^{4096}=12 bits\)行地址,在访问数据时,12bits 行地址位最先到达。
列访问选通(Column Access Strobe,CAS): 由于该DRAM阵列有4096列,因此有\(log_{2}^{4096}=12 bits\)列地址,在访问数据时,12bits 列地址位比行地址位后到达。
行访问选通到达后,DRAM读取一行数据(即4096bits)至行缓冲区(Row buffer) ,随后列访问选通到达,经过**列解码器(Column decoder)**从 Row buffer 读取数据返回 CPU。
1.4 内存 Bank 的组织和运行
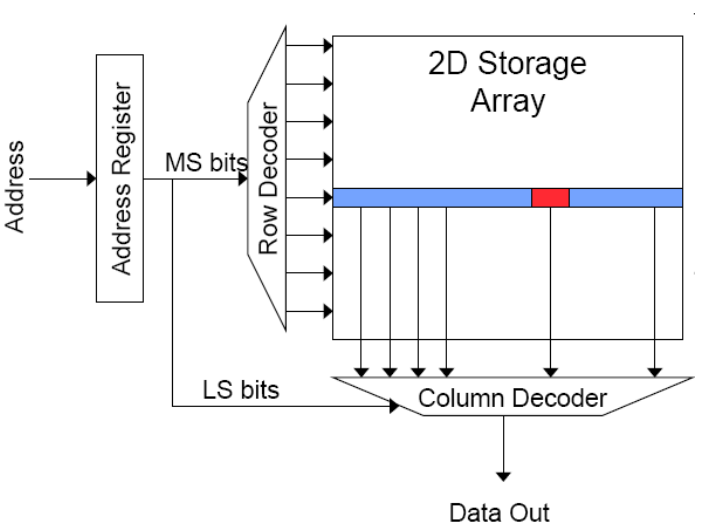
读取访问顺序:
- 解码行地址并驱动字线(word-lines)
- 选定位并驱动位线(bit-lines) - 整行读取
- 放大行数据
- 解码列地址并选择行的子集 - 发送至输出端
- 位线(bit-lines)预充电 - 用于下一次访问
1.5 DRAM 主存储器
-
主存储器存储在 DRAM 单元中,其存储密度要高得多
-
DRAM 单元会随着时间的推移而丢失状态 - 必须定期刷新,因此被称为动态存储器
-
DRAM 存取时间长,能源开销大
1.6 DRAM vs. SRAM
DRAM:
- 访问速度较慢(电容器)
- 密度较高(1T 1C cell)
- 成本较低
- 需要刷新(功率、性能、电路)
- 制造时需要将电容器和逻辑器件放在一起
SRAM:
- 访问速度较快(无电容器)
- 密度较低(6T cell)
- 成本较高
- 无需刷新
- 制造时与逻辑工艺兼容(无电容器)
1.7 Rank 的组织结构
-
DIMM、rank、bank、array -> 在存储组织中形成一个层次结构
-
由于电气限制,总线上只能连接几个 DIMM
-
一个 DIMM 可有 1~4 ranks
-
为提高能效 ,应使用宽输出 DRAM 芯片 ------ 每次请求只激活 \(4\times16bits\) 芯片比激活 \(16\times 4bits\) 芯片更好
-
为高容量 ,应使用窄输出 DRAM 芯片 ------ 由于通道上的 rank 数有限 ,使用 \(16 \times 4bits\ 2Gb\) 芯片比使用 \(4 \times 16bits\ 2Gb\) 芯片可提高每个 rank 的容量
1.8 Banks 和 Arrays 的组织结构
- 一个 rank 被分成多个 banks(4~16 个),以提高 rank 内的并行性,通过在不同的bank之间进行操作,可以实现并行访问。
- ranks 和 banks 提供内存级并行性,通过将数据分散在不同的ranks和banks中,内存系统能够同时处理多个内存请求,从而提升内存的并行处理能力。
- 一个 bank 由多个 arrays(subarrays、tiles、mats)组成
- 为了最大限度地提高密度,bank 中的 arrays 要做得很大: 为了在有限空间内存储更多数据,每个 bank 内的 array 被设计得很大。这意味着 array 中的行很宽,因此行缓冲区(row buffer) 也很宽。例如,当内存请求为 \(64Bytes\) 时,实际上可能会读取 8KBytes 的数据(称为 过量读取(overfetch)),以充分利用宽行缓冲区的特性。
- 每个array每个周期向输出引脚提供一位数据:为了实现更高的存储密度,每个 array 在每个时钟周期内只提供1位数据到输出引脚。这种设计虽然降低了单次传输的数据量,但提高了系统的总存储密度,适合需要存储大量数据的情况。
这种组织方式通过多个层次(ranks、banks、arrays)的划分,实现了高密度的存储,同时也通过并行访问多个banks和ranks,提升了内存系统的并行性和性能。
1.9 行缓冲区(Row Buffers)
- 每个 bank 都有一个行缓冲器
- 行缓冲区在DRAM中充当缓存的作用。
- **行缓冲器命中(Row buffer hit):**约 20 ns 访问时间(只需将数据从行缓冲区移至引脚)
- 空行缓冲区访问(Empty row buffer access):约 40ns(首先需要读取array,然后将数据从行缓冲区移到引脚)。
- 行缓冲区冲突(Row buffer conflict):约 60ns(首先需要预充电 bit-lines,然后读取新行,再将数据移到引脚)。
- 另外,还需在队列中等待(数十ns),并且还要经历地址/命令/数据传输延迟(约10ns)。
1.10 构建更大的存储器
我们需要更大的存储阵列,但是大阵列意味着访问速度慢。
如何在保证存储器容量大的同时不使其变得非常慢?
Idea:将存储器划分为更小的阵列,并将这些阵列与输入/输出总线互连。
- 大容量存储器通常是分层的阵列结构。
- DRAM的分层结构:通道(Channel)→ Rank → 存储体 → 子阵列(Subarrays)→ 矩阵(Mats)
2. DRAM 子系统组织
2.1 通用内存结构
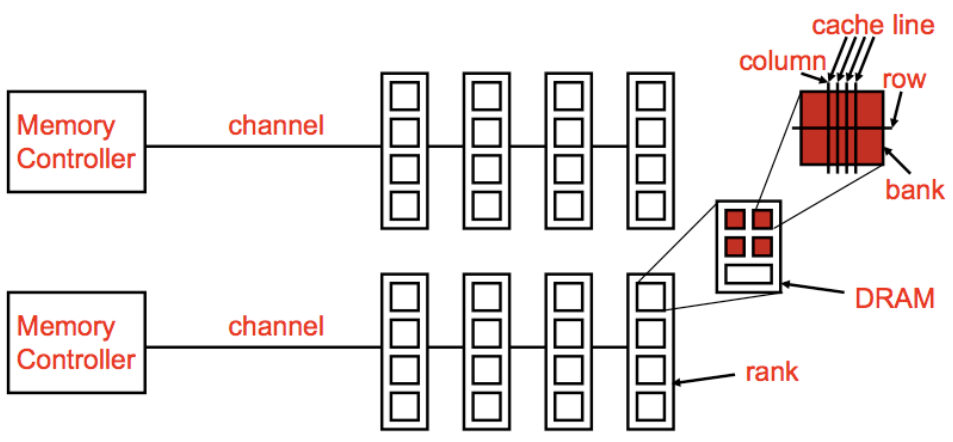
上图展示了一个通用的内存结构,主要包括以下组件:
- Memory Controller(内存控制器):负责管理内存数据的读写操作。图中显示了两个内存控制器,每个控制器通过一个通道(channel)与内存模块相连。
- Channel(通道):内存控制器和内存之间的数据传输通道,允许多个控制器访问不同的内存模块,提高内存的带宽。
- DRAM(动态随机存取存储器):DRAM模块通过多个"rank"组织,每个rank又包含若干个"bank",进一步提高并行性和效率。
- Rank:内存中的一个逻辑组织单元,由多个物理内存芯片组成,便于内存控制器的访问管理。
- Bank:内存的更小单位,支持多路并发访问。每个bank内又包含多个行(row)和列(column)。
- Row(行)和 Column(列):bank内存储数据的基本单位,通过行和列的地址确定具体的数据位置。
- Cache Line(缓存行):CPU读取数据的基本单位,一次读取的数据块大小。通过cache line的设计提高数据传输效率。
2.2 通用原则:交替访问(Banking)
交替访问(Interleaving)(banking 存储库)
- Problem:一个单一的大型内存阵列访问时间长,且无法实现并行的多次访问。
- Goal:降低内存阵列的访问延迟,并实现并行的多次访问。
- Idea :将一个大型阵列划分为多个可以独立访问的存储库(bank),这些 bank 可以在同一个周期或连续的周期内进行访问。
- 每个 bank 都比整个内存存储要小。
- 对不同 bank 的访问可以重叠。
- 访问延迟是可控的。
2.3 内存 Banking 示例
- 内存分为多个存储库(banks):这些存储库可以独立访问,从而实现并行的多次访问。这种结构将内存划分为多个bank,每个bank可以独立完成数据的读写操作,减少了等待时间。
- 共享地址和数据总线 :多个存储库共享地址总线和数据总线,这样设计可以减少内存芯片的引脚数量,从而降低硬件复杂度和成本。
- 每周期完成一个bank的访问:通过并行访问不同的bank,在每个周期内可以启动和完成对一个存储库的访问,提升了整体的内存访问效率。
- 支持N个并发访问:如果所有N个访问请求都指向不同的bank,那么系统可以支持N个并发的内存访问请求。这意味着如果内存访问请求均匀分布到不同的bank上,可以充分利用内存带宽,实现高效的并行处理。
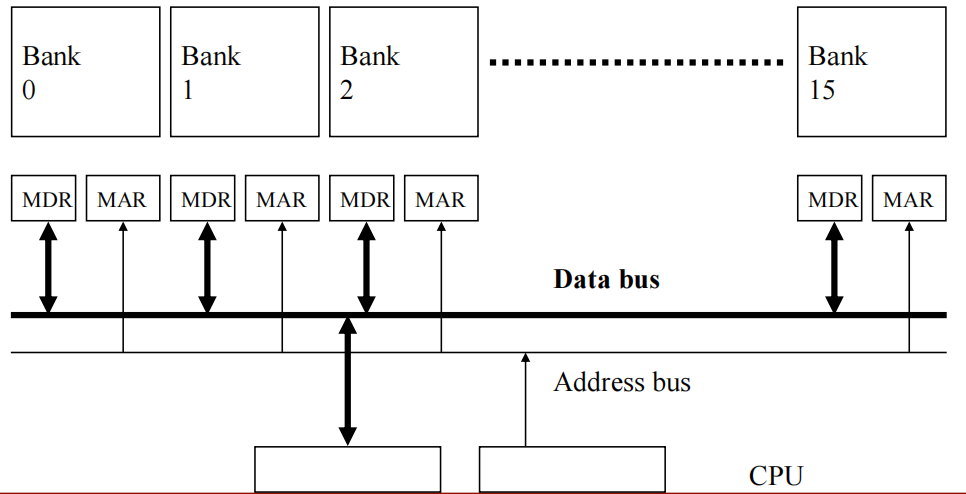
- 图中显示了16个存储库(Bank 0 至 Bank 15)。
- 每个bank都有其独立的内存数据寄存器(MDR) 和内存地址寄存器(MAR),用于存储正在传输的数据和地址信息。
- 这些存储库通过数据总线与CPU相连,数据总线负责数据的传输,地址总线负责地址信息的传输。
2.4 DRAM 子系统
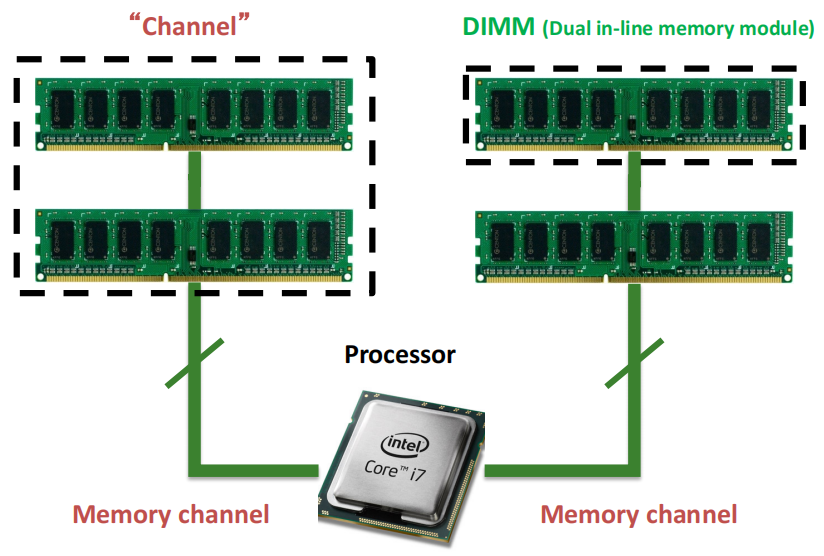
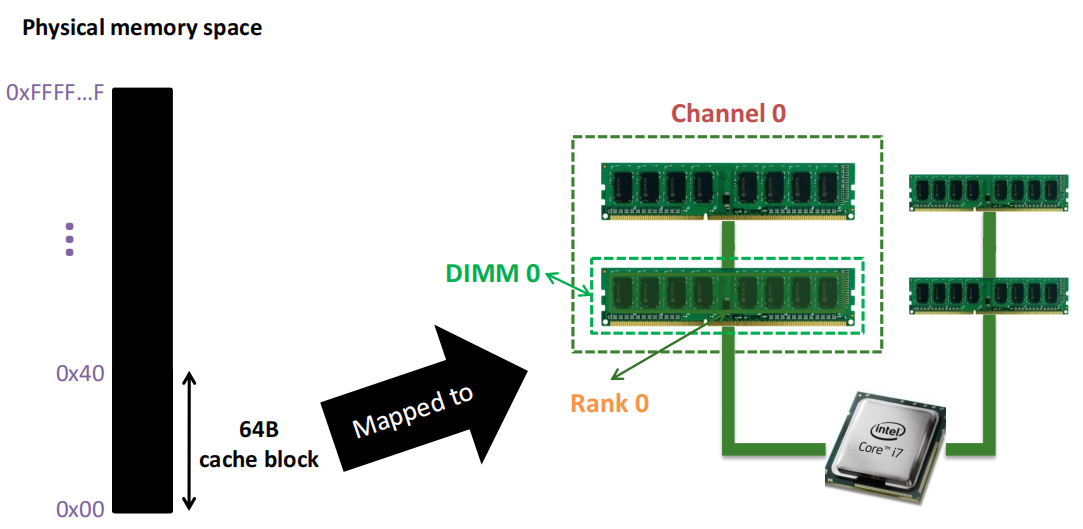
图中间的处理器通过两个独立的内存通道与内存模块相连,每个通道内可以插入多条内存条(DIMM,即双列直插内存模块),通道负责将数据传输到内存和处理器之间。
2.4.1 分解 DIMM(模块)
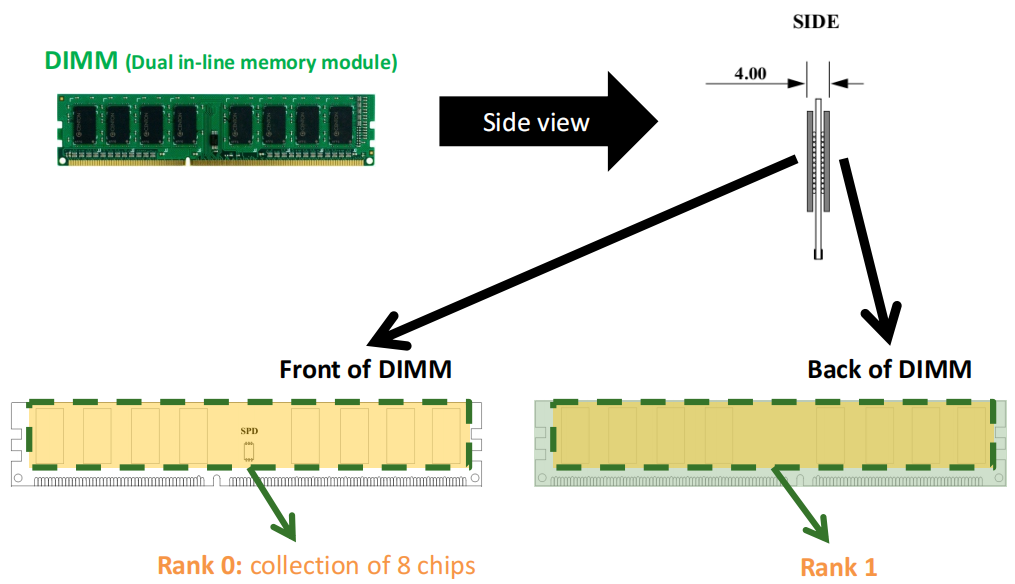
上图中展示了DIMM的正面 和背面:
- Rank 0:位于DIMM的正面,由8个芯片组成。
- Rank 1:位于DIMM的背面,也由8个芯片组成。
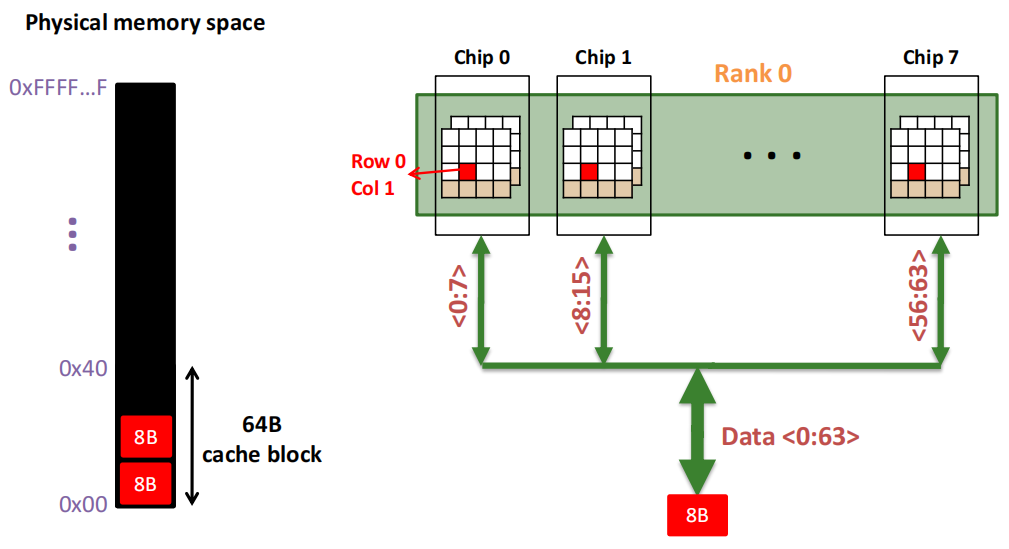
2.4.2 分解 Rank
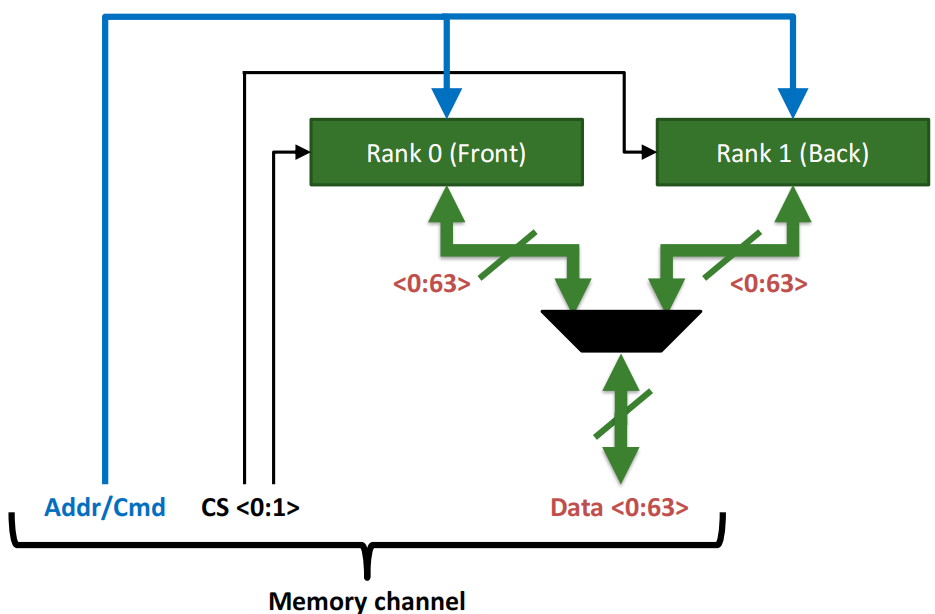
每个 Memory channel 包括:
- Addr/Cmd:表示地址和指令信号,用于向不同的Rank发送内存访问请求。
- CS(Chip Select):选择信号,用于选择哪个Rank进行操作。在图中,CS <0:1> 表示控制信号,选择Rank 0 或 Rank 1。
- Data <0:63>:数据总线,提供64位数据通道,用于传输数据。
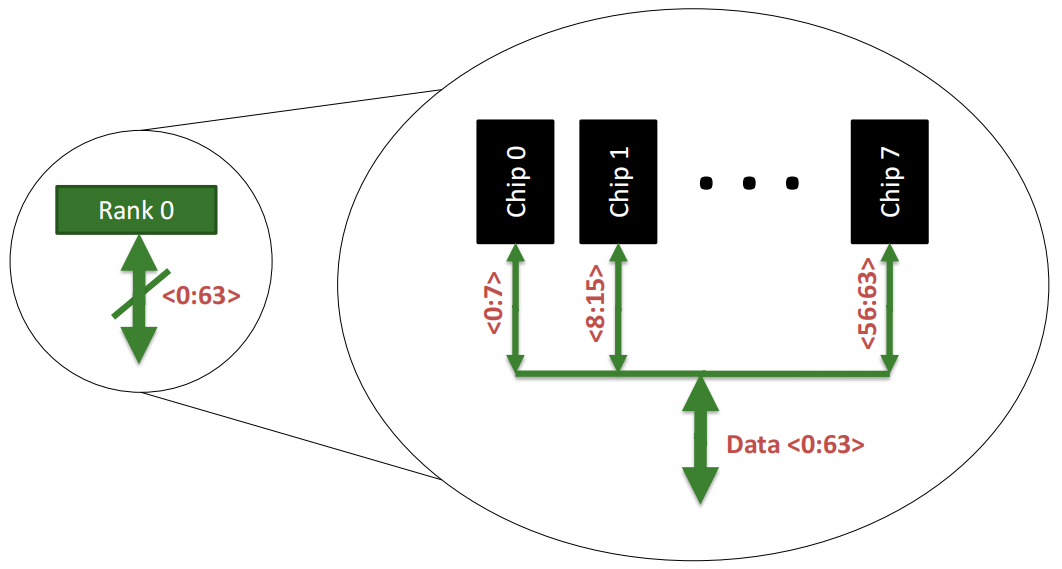
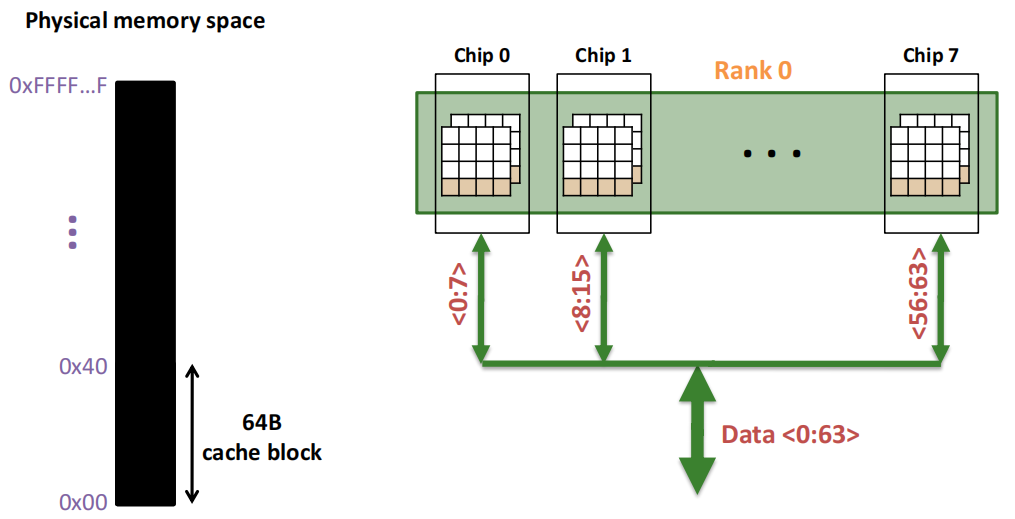
一个内存 Rank 内部是由**多个芯片(Chip)**构成的:
Rank 0被分解为多个芯片,从Chip 0到Chip 7。每个芯片负责部分数据位:
- Chip 0负责数据位0到7(<0:7>)。
- Chip 1负责数据位8到15(<8:15>)。
- 依此类推,直到Chip 7负责数据位56到63(<56:63>)。
64位数据通道:所有芯片通过各自负责的8位数据位共同组成了64位的数据通道(Data <0:63>),从而实现并行数据的传输。这种设计允许Rank内多个芯片同时工作,提高了数据访问效率。
2.4.3 分解 Chip
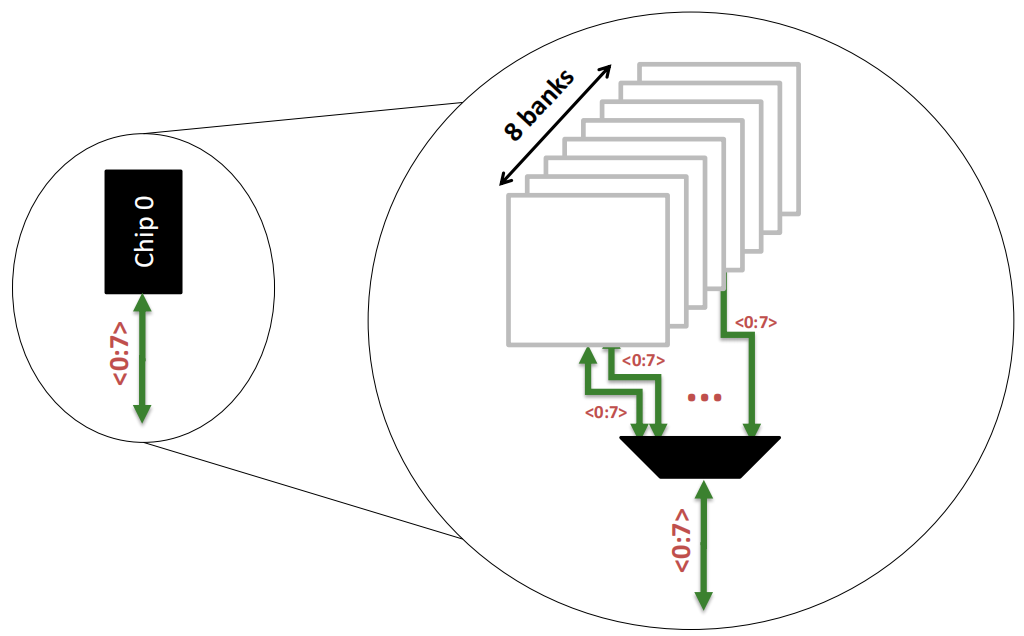
一个内存 Chip 内部是由**多个存储库(Banks)**构成的:
Chip 0:图的左侧的 Chip 0,它负责8位的数据通道(<0:7>),表示该芯片只传输数据的0到7位。
内部存储单元(Banks):在右侧的放大图中,Chip 0进一步被分解为8个独立的存储单元(称为"Banks")。每个Bank都可以独立地存储和读取数据,允许芯片同时处理多个数据请求,提高数据传输的并行性。
2.4.4 分解 Bank
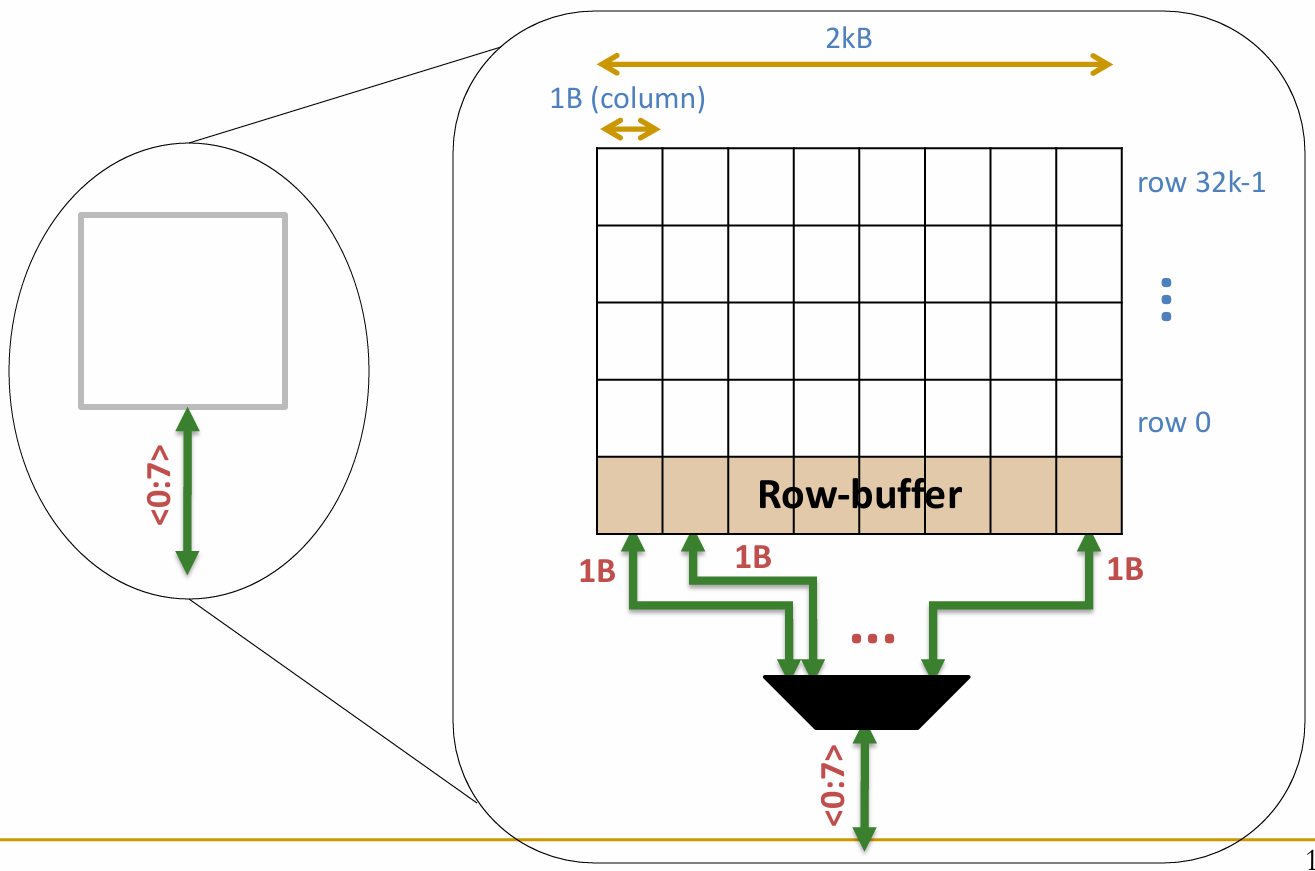
一个内存 Bank 内部是由多个大小为 1Byte 的 Arrays构成的:
- 先读取一个行,将该行缓存到 Row-buffer 中
- 再根据 column 地址从 Row-buffer 中取出大小为 1Byte(即 8bits)的数据
2.4.5 深入挖掘:DRAM Bank 操作
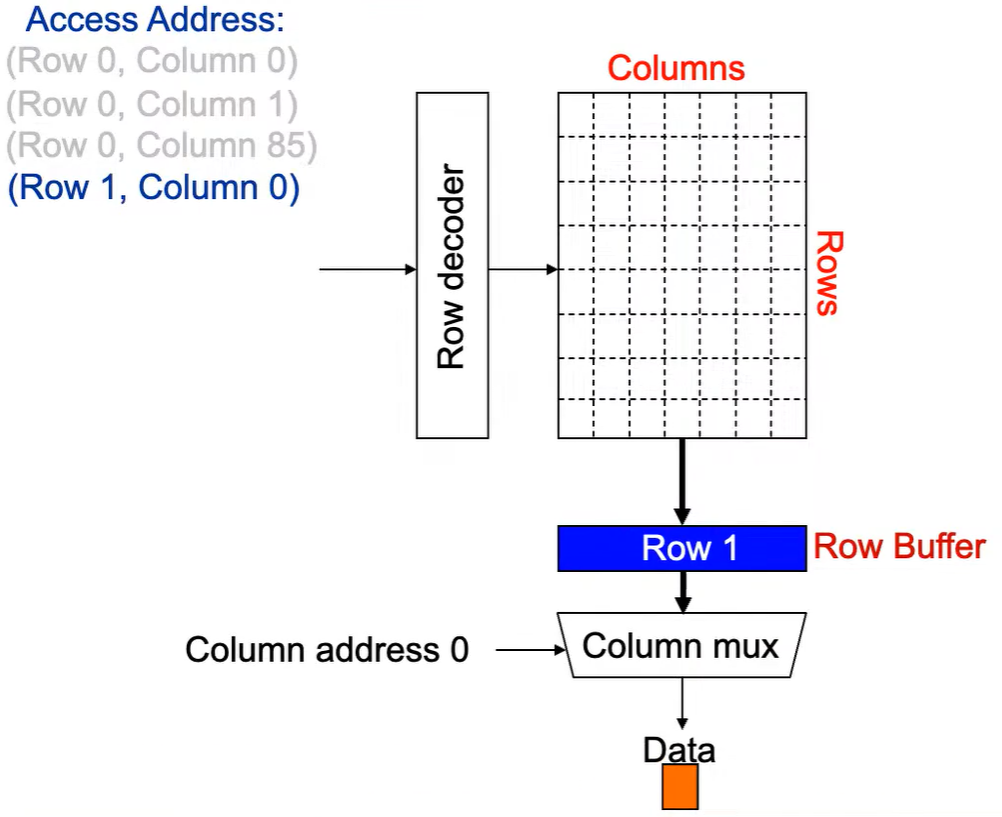
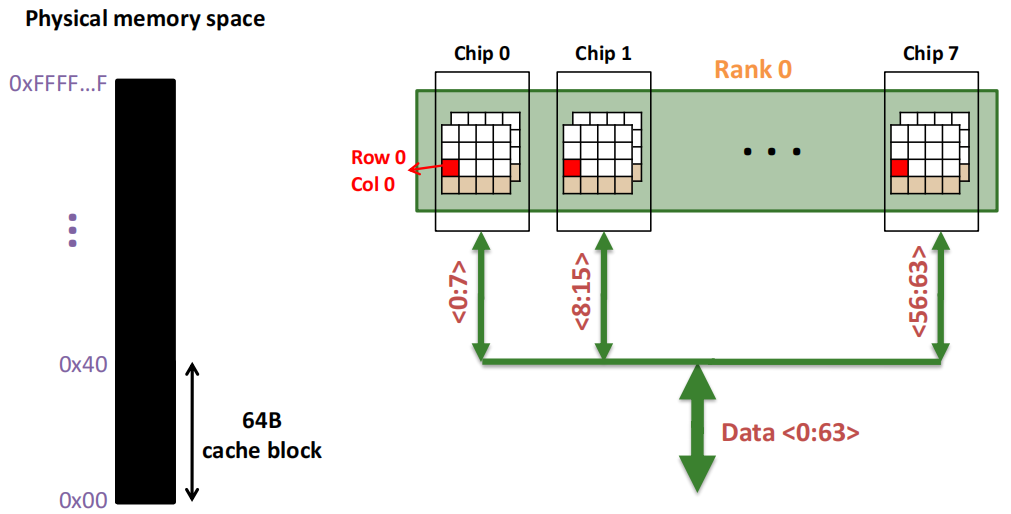
第1次访问(Row,Column 0):
Step 1: Row address 0到达,word-lines 被激活,bit-lines 被连接到感测放大器。
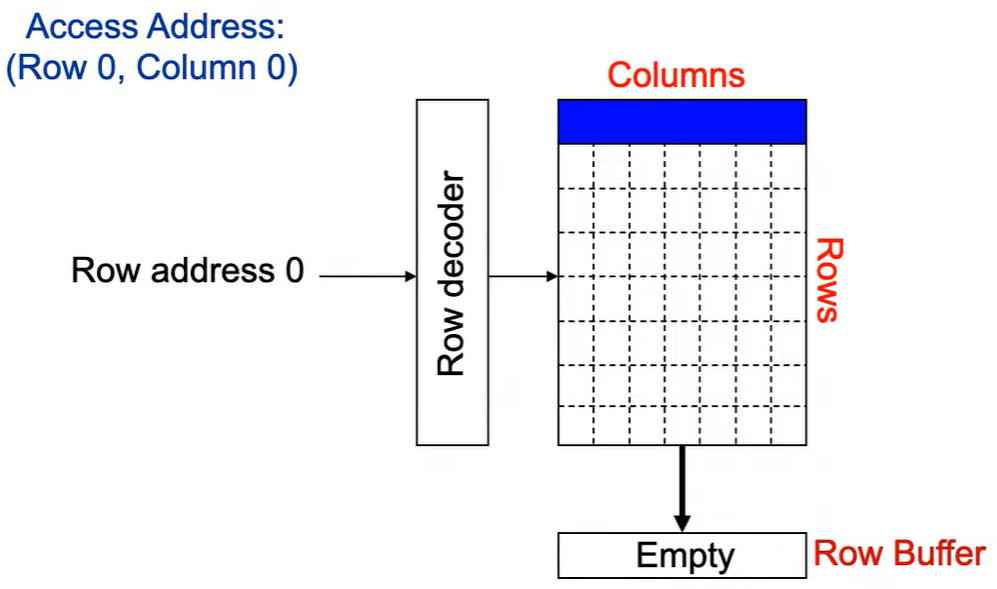
**Step 2:**感测放大器感知该行内容,捕捉数据放入 Row Buffer。
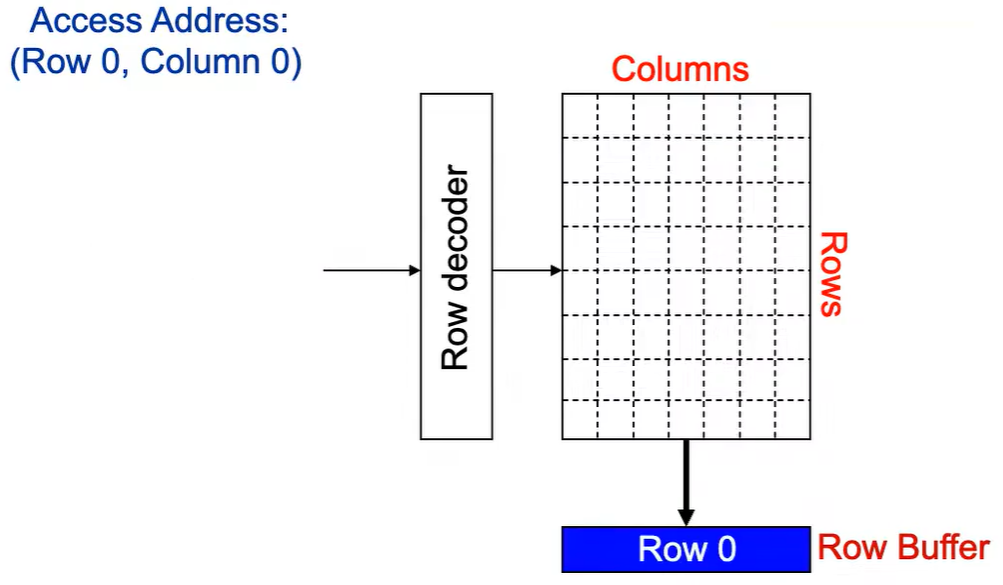
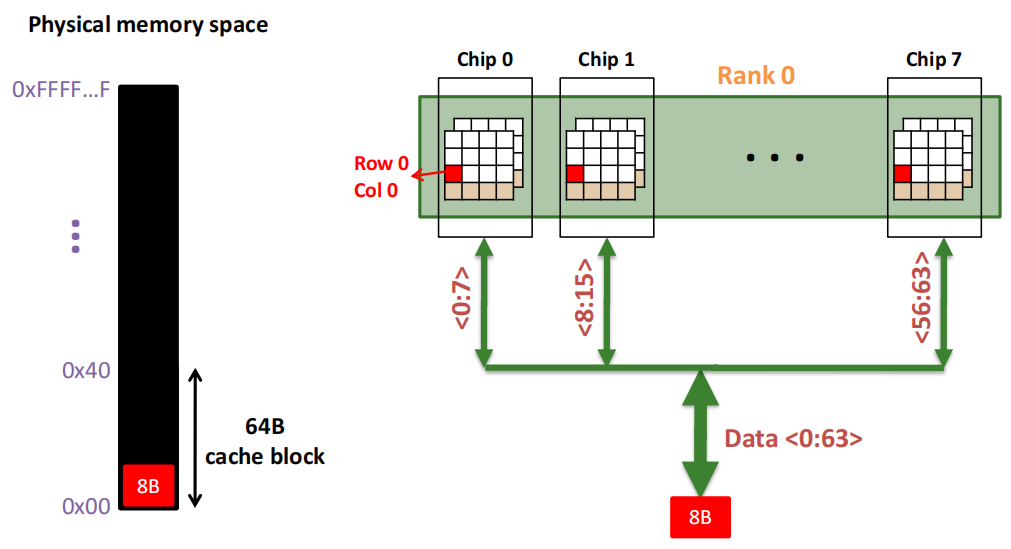
**Step 3:**Column address 0到达,选择列。
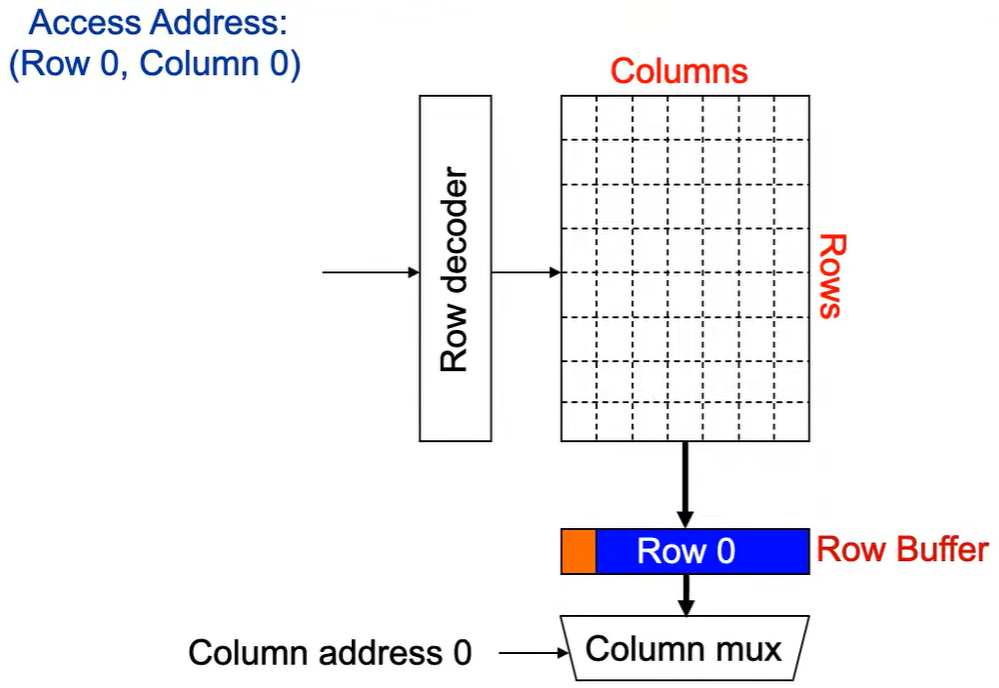
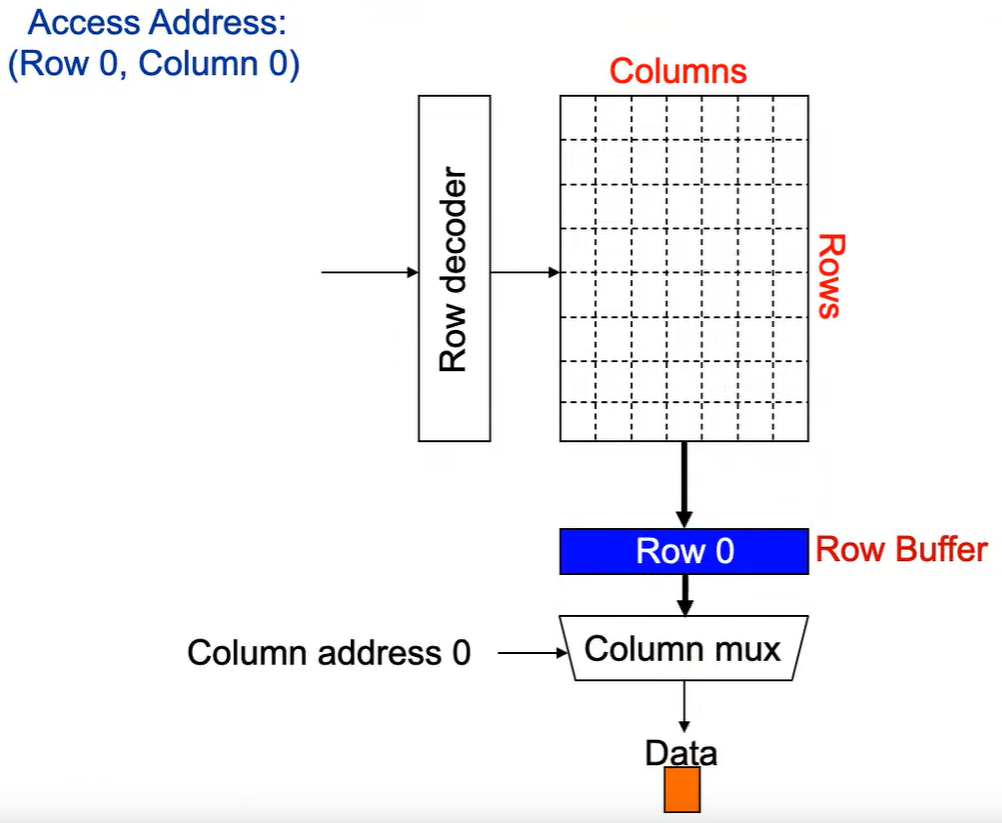
**Step 4:**最后数据被读出。
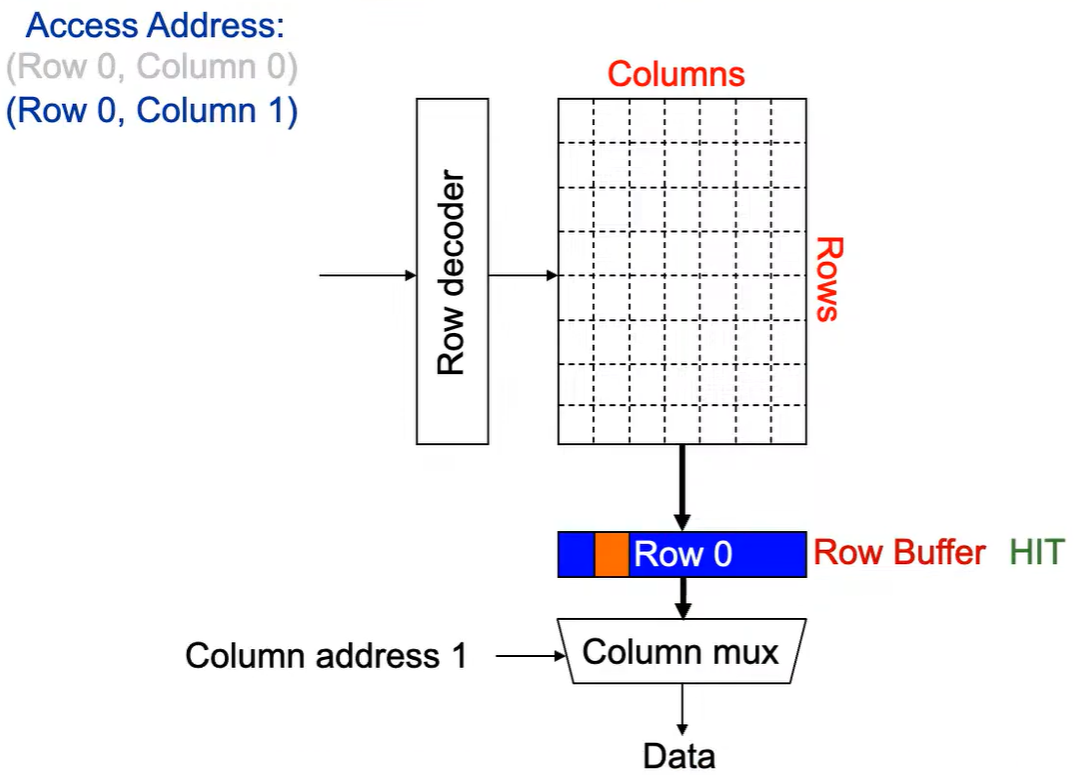
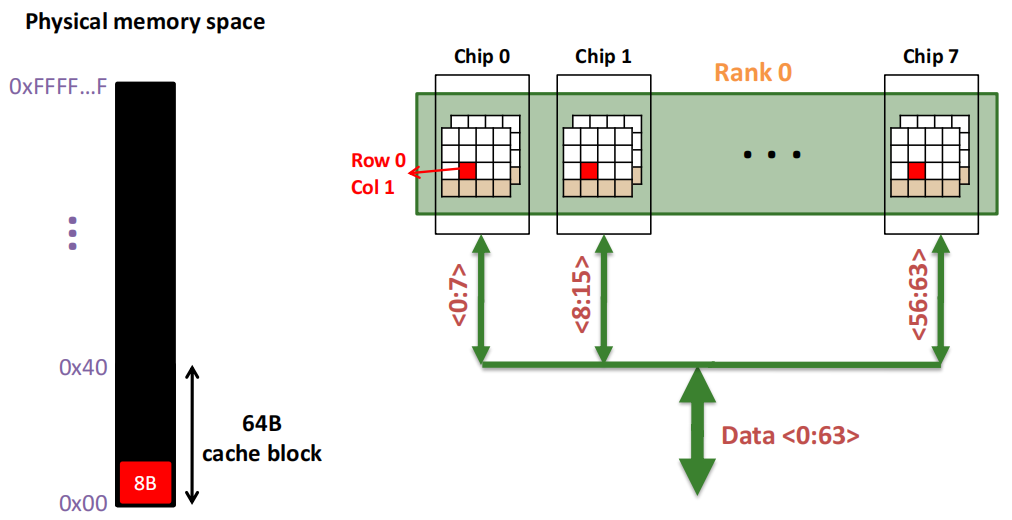
第2次访问(Row 0,Column 1):
由于 Row Buffer HIT,数据很快被读取出。
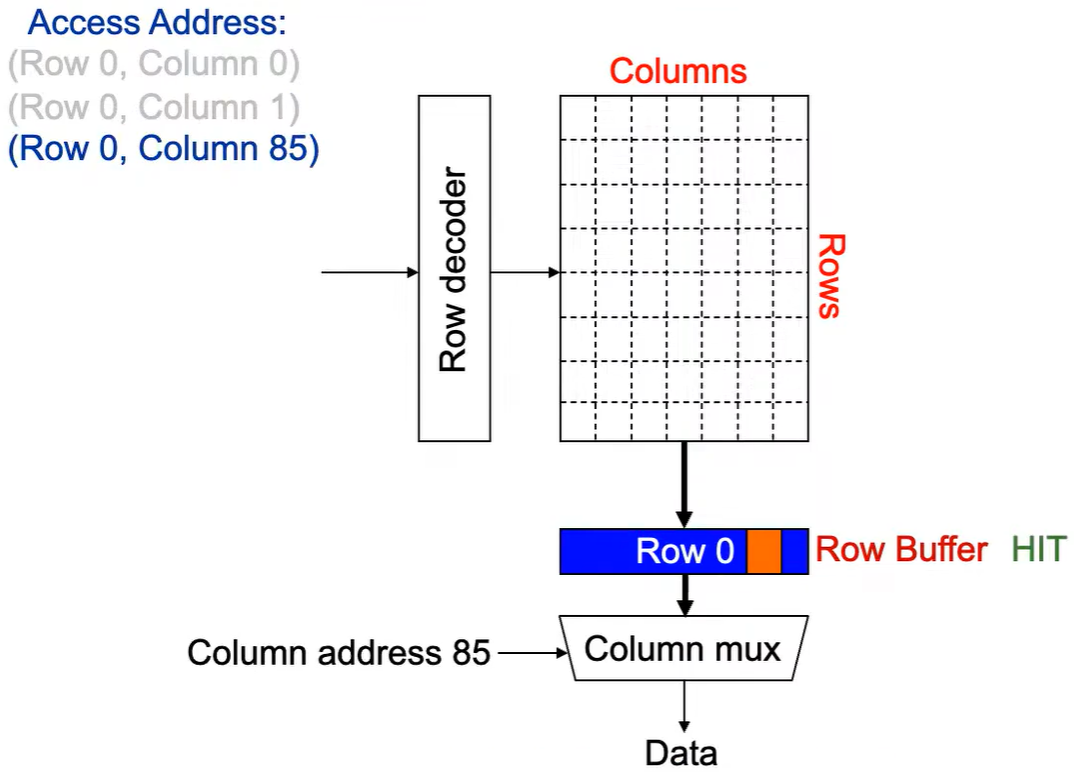
第3次访问(Row 0,Column 85):
同样由于 Row Buffer HIT,数据很快被读取出。
第4次访问(Row 1,Column 0):
出现 Row Buffer Conflict(冲突)!
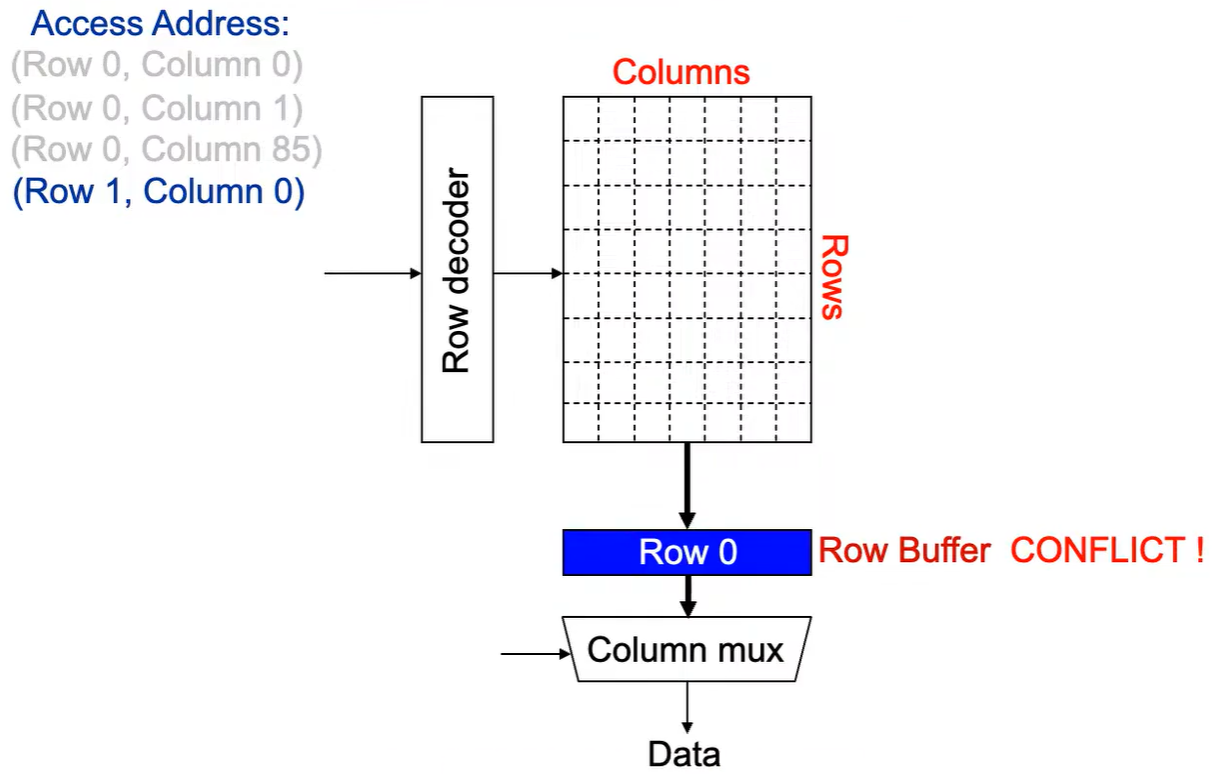
Step 1: 将行写回 ,即预充电 ,使得下次访问的数据可靠,增加了延迟。
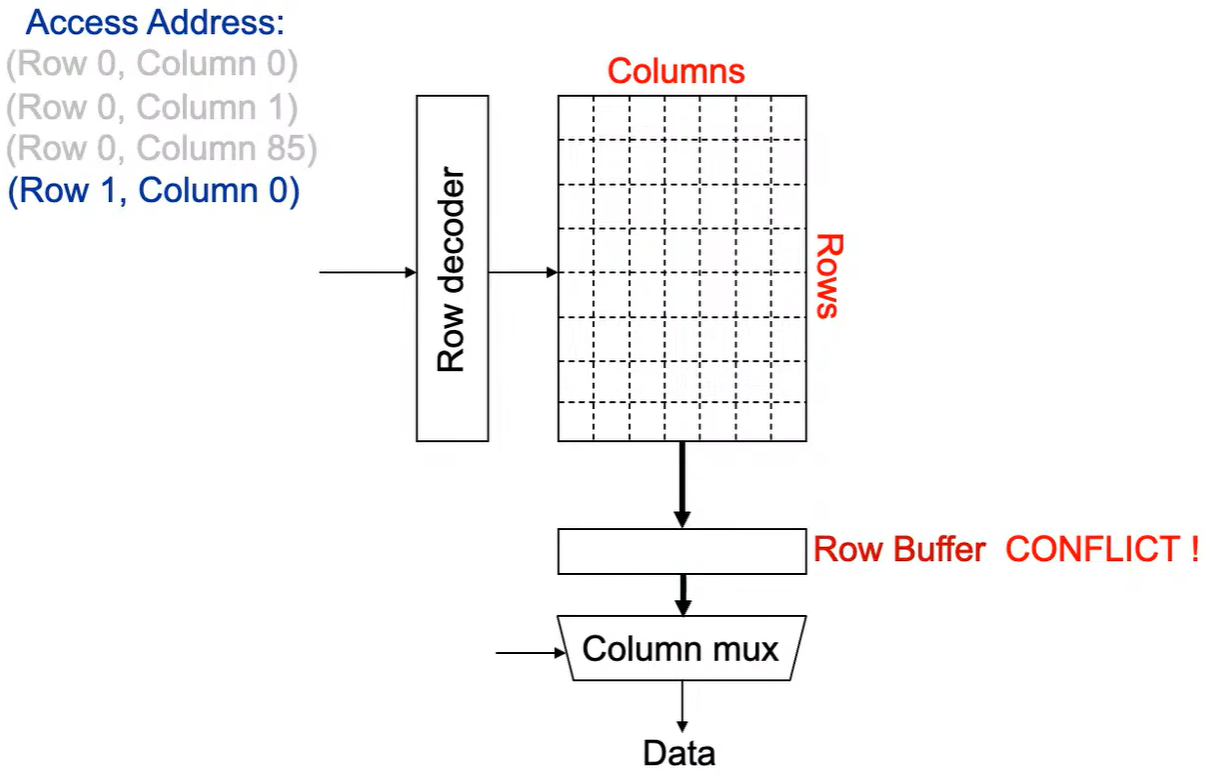
**Step 2:**Row address 1到达,word-lines 被激活,bit-lines 被连接到感测放大器。
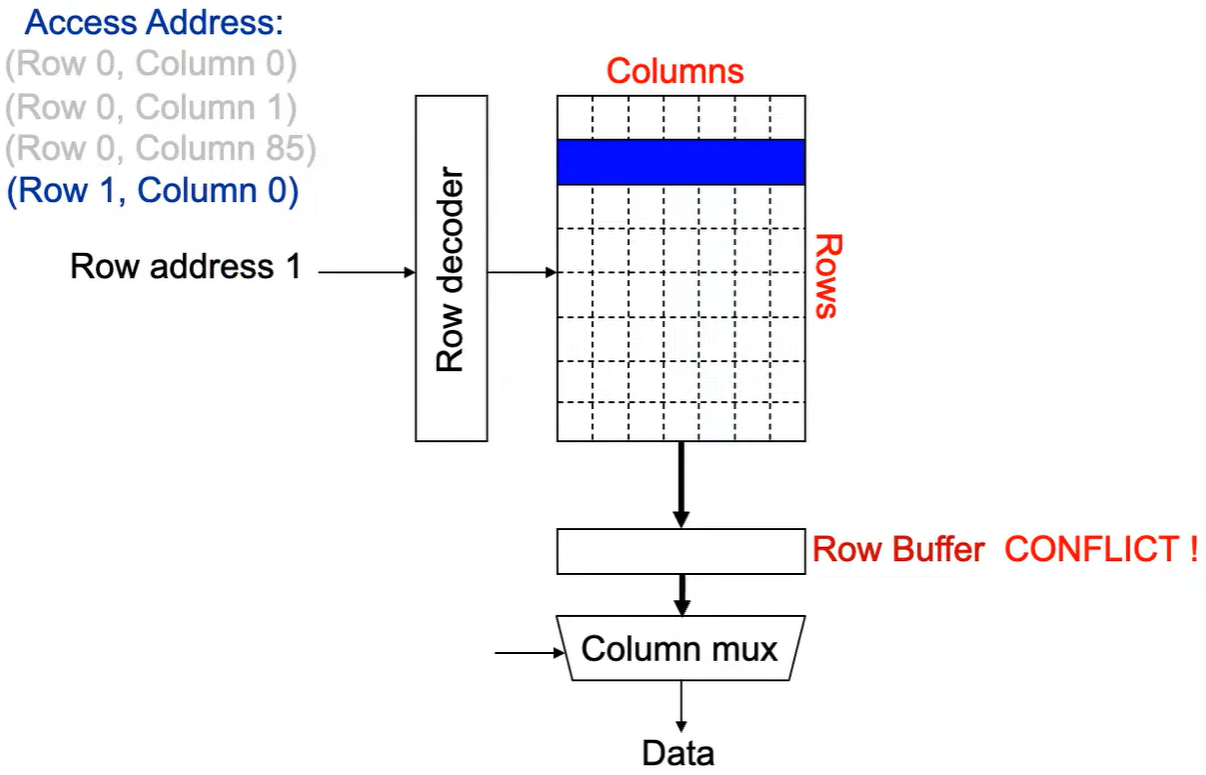
**Step 3:**感测放大器感知该行内容,捕捉数据放入 Row Buffer。
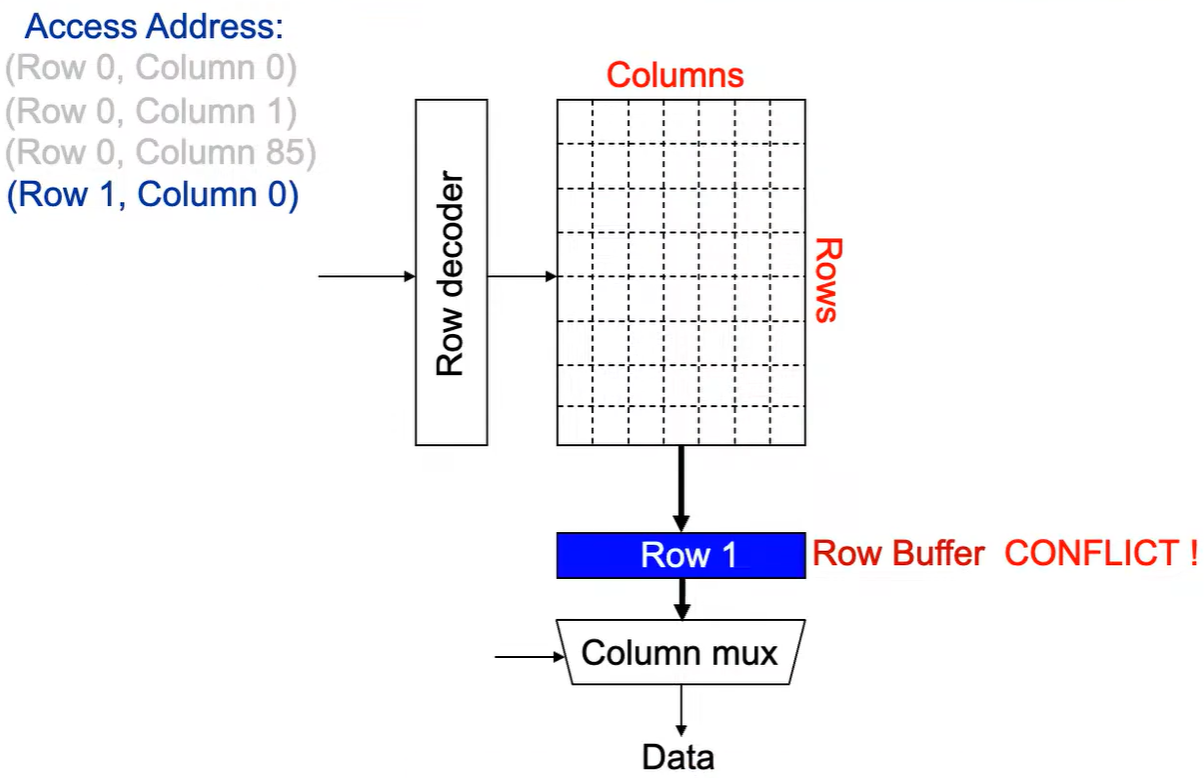
**Step 4:**Column address 0到达,选择列。
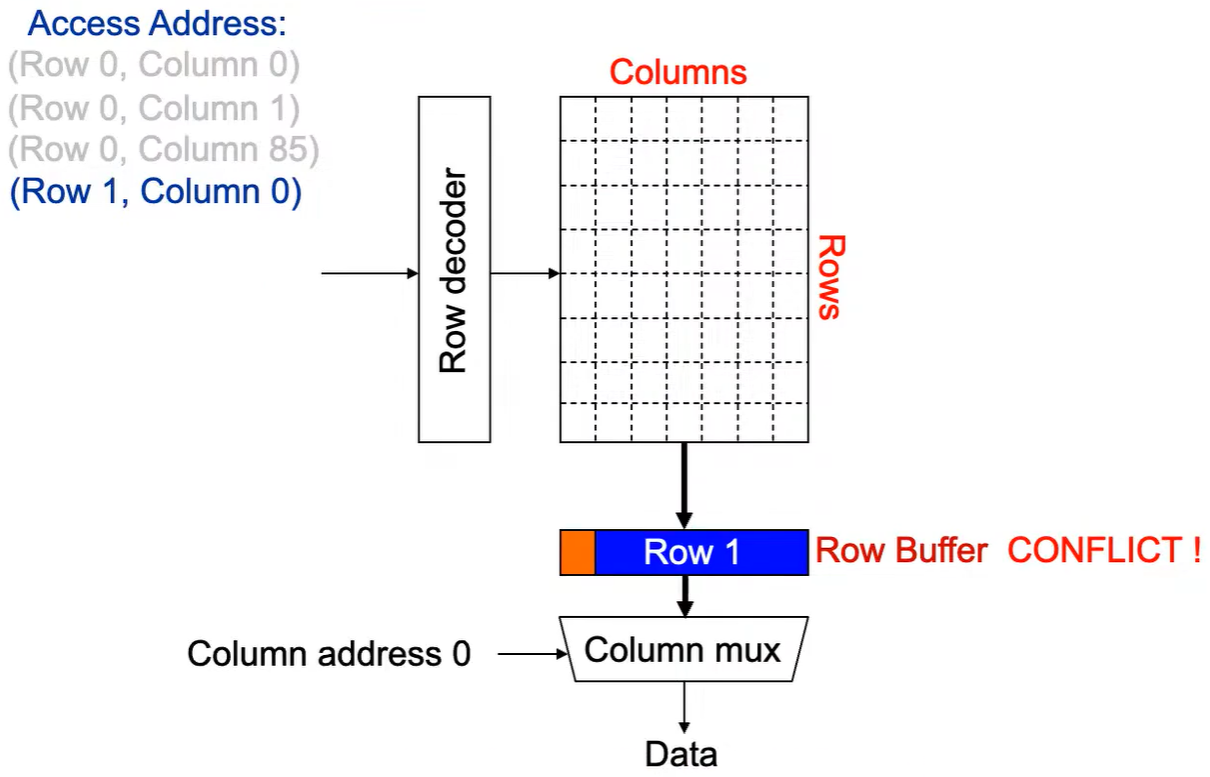
**Step 5:**最后数据被读出。
2.5 DRAM Bank 内部有 Sub-Banks
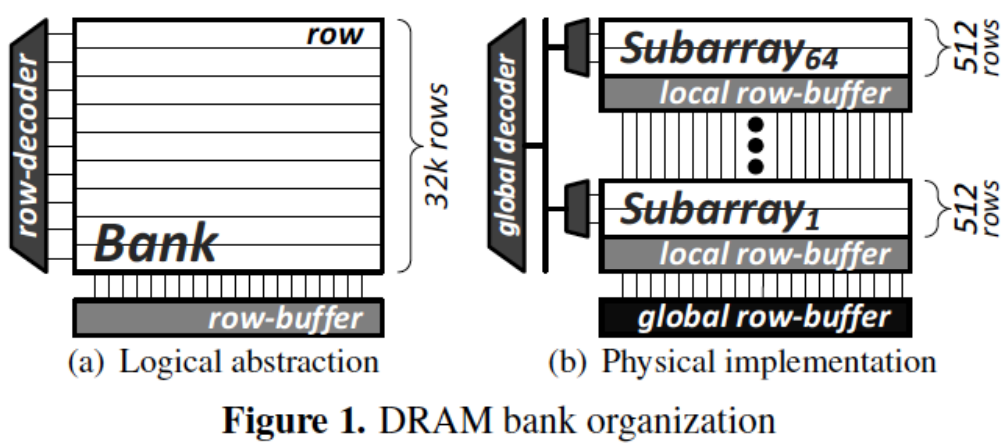
左图 (a) 是逻辑抽象图,展示了一个 DRAM bank 的传统表示法,其中包含行(row)、行解码器(row-decoder)和一个大的行缓冲区(row-buffer)。在逻辑抽象中,bank 似乎是一个整体,有着多达 32K 行的数据。
右图 (b) 是实际的物理实现。一个 DRAM bank 实际上被分割为多个子阵列 (Subarray),每个子阵列拥有自己的局部行缓冲区 (local row-buffer),并且每个子阵列由512行组成。这里显示了从第1个子阵列到第64个子阵列的结构。这些子阵列通过全局解码器 (global decoder) 连接到整个 bank 的全局行缓冲区 (global row-buffer)。
- 逻辑抽象:在逻辑上,bank 被认为是一个单一的整体结构,所有行共享一个行缓冲区。
- 物理实现:实际上,bank 被划分成多个子阵列以提升访问效率。每个子阵列具有自己的局部行缓冲区,使得在不同子阵列之间可以并行处理数据,以提高并行度和性能。
这种设计通过将 bank 分为多个子阵列来增强访问速度和并行性,从而减少等待时间并提升DRAM性能。
2.6 Example:传输缓存块
- 传输一个 64B 的高速缓存块需要 8 个 I/O 周期。
- 在此过程中,8 列按顺序被读取。
Step 1:
Step 2:
Step 3:
Step 4:
3. 内存控制器
3.1 打开/关闭页策略(Open/Closed Page Policies)
- 如果访问流具有局部性 ,则行缓冲区会保持打开状态
- 行缓冲命中成本低**(打开页策略(open-page policy))**
- 行缓冲未命中是存储库冲突,代价高昂,因为预充电在关键路径上
- 如果访问流几乎没有局部性 ,则位线(bit-lines)在访问后立即进行预充电(关闭页策略(close-page policy))
- 几乎每次访问都是行缓冲未命中
- 预充电通常不在关键路径上
- 现代内存控制器策略介于这两者之间(通常是专有的)
3.2 读写操作
-
读取和写入操作使用同一条总线。
-
在切换读取和写入操作时,必须反转总线方向;这需要时间,并导致总线空闲。
-
因此,写入操作通常以突发方式进行;写缓冲区会存储待处理的写入,直到达到高水位标记。
-
写入操作会一直进行,直到达到低水位标记。
-
高水位标记(High Water Mark):这是缓冲区中数据达到的一个预定的上限。当缓冲区中的数据量达到这个标记时,系统就会触发某些操作,例如开始写入数据(如在存储器中)或停止进一步的数据写入到缓冲区中,以避免缓冲区溢出。
-
低水位标记(Low Water Mark):这是缓冲区中的数据量达到的一个预定的下限。当缓冲区中的数据量减少到这个标记时,系统可以重新开启数据写入或进行其他操作,确保缓冲区不会因为数据不足而影响性能。
3.3 地址映射策略
- 可将连续的缓存行放置在同一行 中,以提高行缓冲区命中率
- 可将连续的缓存行放置在不同行 中,以提高并行性
- 地址映射策略示例:
- row : rank : bank : channel : column : blkoffset
- row : column : rank : bank : channel : blkoffset
3.4 调度策略
-
FCFS(先到先服务):处理队列中第一个可以执行的读或写请求。
- 在FCFS策略中,系统按照请求到达的顺序依次执行。只要一个请求准备好(符合执行条件),就会立即被执行。这个方法简单,但在内存访问中可能无法充分利用行缓冲(row buffer)命中,导致性能不高。
-
First Ready - FCFS(优先行缓冲命中 - 先到先服务):优先处理行缓冲命中的请求,如果可能的话。
- 这个策略首先检查是否有请求可以命中行缓冲(即当前行已经在内存的行缓冲区中)。如果有,就优先处理这些命中请求,因为这样可以减少行开销,提高访问速度。如果没有行缓冲命中,则按照先到先服务的方式处理。
-
Stall Time Fair(等待时间公平):优先处理行缓冲命中的请求,除非其他线程被忽略了。
-
这个策略在优先行缓冲命中的基础上增加了公平性。如果多个线程在竞争内存访问,则该策略会在尽量优先行缓冲命中的同时,保证所有线程都能得到公平的访问机会,不让某些线程一直被延迟。这种方法有助于平衡多线程环境下的资源分配。
3.5 刷新(Refresh)
DRAM(动态随机存取存储器)中的每个存储单元都由电容存储电荷来表示数据。由于电容电荷会随时间逐渐泄漏,因此需要定期刷新来补充电荷,以确保数据不丢失。
-
刷新时间窗口:所有DRAM单元必须在64毫秒内刷新一次,防止数据因电荷泄漏而丢失。
-
自动刷新:当对某一行执行读或写操作时,该行会自动进行刷新,帮助延长数据保持时间。
-
刷新指令的影响:每次刷新指令会刷新一定数量的行。在刷新过程中,内存暂时不可用,这可能导致微小的延迟。
-
刷新频率:内存控制器通常会平均每7.8微秒发出一次刷新指令,以分散刷新负担,避免集中刷新带来的性能影响。