简介

内核态,用户态,线程,进程,协程基本概念不再赘述。
原生线程和用户线程
-
原生线程
在内核态中创建的线程,只服务于内核态
-
用户线程
由User Application创建的线程,该线程会在内核态与用户态中间来回穿梭
比如Throw Exception,就会由CLR 线程触发,从用户态切换到内核态,再切换回用户态。
时钟中断与时间片
时钟中断的底层,是由主板上的硬件定时器产生,以固定的时间间隔(15.6ms)触发。windows作为消费端,来处理多线程任务调度/定时任务。
操作系统获取到中断后,再自行分配时间片,每个线程在一个时间片里获得CPU的运行时间,等时间片用完后,再由操作系统分配给下一个线程
windows 客户端一个时间片为 2个时钟中断 (15.62=31.5ms)
windows 服务端一个时间片为 12个时钟中断 (15.612=187.2ms,主要是为了更高的吞吐量)
CLR via C# 一文中说windows每30ms切换一次就是这个原因。
当一个线程时间片用完后,操作系统会将新的时间片转移给其它线程。以实现"多线程"效果。
单个核心在同一时间只能处理一个线程的任务。
眼见为实
- 中断多久触发一次?
使用windbg进入内核态,使用nt!KeMaximumIncrement命令查看看它的值
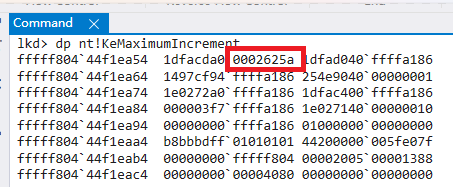
注意,单位为100ns,因此156250*100/1000/1000=15.625ms
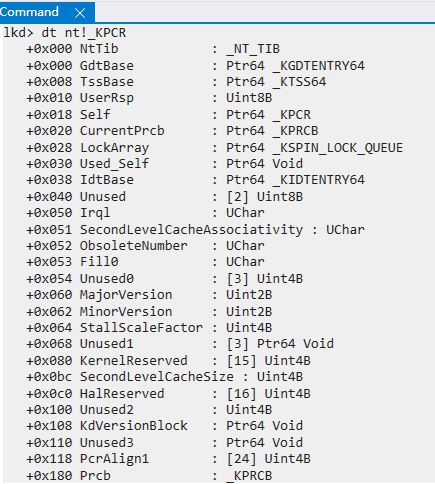
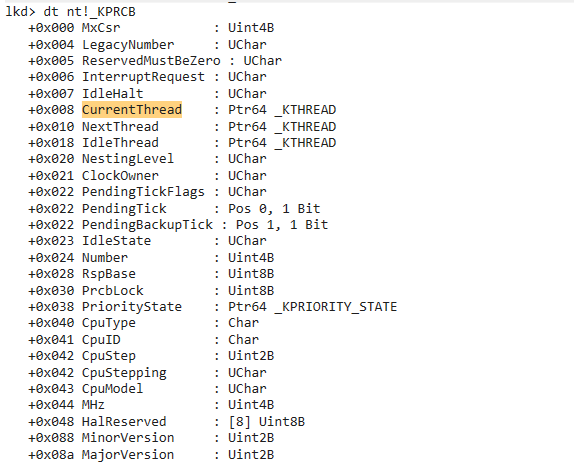
Windows下CPU核的数据结构
Windows会给每一个 CPU核 分配一个_KPCR的内存结构,用来记录当前CPU的状态。并拓展了_KPRCB来记录更多信息。
关键信息就是存储着 CuurentThread/NextThread/IdleThread(空闲线程)
眼见为实
使用dt命令来查看
dt命令是一个非常有用的显示类型信息的工具,主要用于查看和分析数据结构的布局和内容
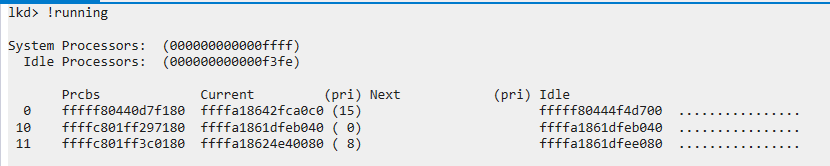
CPU当前正在执行哪个线程?
使用!running命令,可以看到当前 CPU核 正在执行的线程
本质上就是对_KPCR/_KPRCB的提炼简化,
Windows下线程的数据结构
每个线程都有以下要素,这是创建线程无法避免的开销。
-
线程内核对象(Thread Kernel Object)
OS中创建的每一个线程都会分配数据结构来承载描述信息
Windows会给每一个 Thread 分配一个_ETHREAD的内存结构,用来记录当前线程的状态,其中就包括了线程上下文(Thread Context)
-
线程环境块(Thread Environment Block, TEB)
TEB是在用户态中分配的内存块,主要包括线程的Exception,Local Storage等信息
-
用户态线程栈(User-Mode Stack)
我们常说的栈空间就是指的这里,大名鼎鼎的OOM就出自于此
-
内核态线程栈(Kernel-Mode Stack)
处于安全隔离考虑,在内核态中复制了一个同样的栈空间。用来处理用户态访问内核态的代码。
眼见为实
-
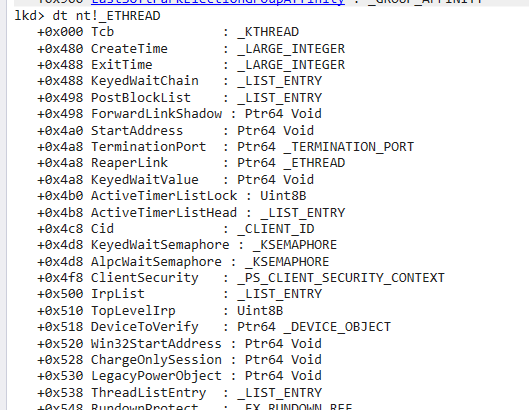
线程内核对象
使用命令dt nt!_ETHREAD
-
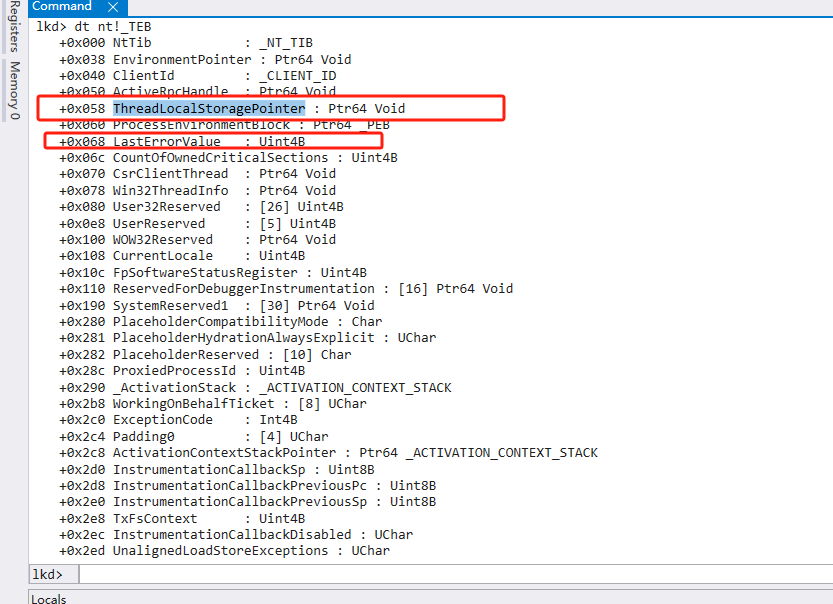
TEB
使用命令dt nt!_TEB
线程上下文切换的本质
上下文切换的本质就是,备份被切换线程寄存器的值,到该线程的上下文中。再从切换后的线程中,读取上下文到寄存器中。
举个简单的例子就是,我跟你轮流打游戏,我玩的时候要先加载我的存档,轮到你玩的时候,我再保存我的存档。你玩的时候重复这一过程。
线程切换的成本
上下文切换是净开销,不会带来任何性能上的收益。因此优化程序的一个思路就是降低上下文切换
-
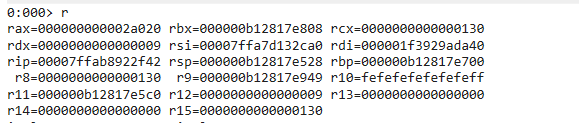
显式成本
保存寄存器的值到内存,从内存读取寄存器。
寄存器的数量越多成本就越高,以AMD 7840HS处理器为例,总共有17个寄存器
-
隐式成本
如果线程切换是在同一个进程中,它们共享用户态的虚拟内存空间。所以当线程切换的时候,就有可能命中CPU的缓存(比如线程之间共享的变量,代码)。
如果在不同的进程中,线程的切换则会导致用户态的虚拟内存空间都失效,进而导致CPU缓存失效。
眼见为实
说了这么多理论,不如直接看源码。
/*主代码入口*/
PUBLIC KiSwapContext
.PROC KiSwapContext
/* Generate a KEXCEPTION_FRAME on the stack */
/* 核心逻辑:把寄存器全部备份一遍 */
GENERATE_EXCEPTION_FRAME
/* Do the swap with the registers correctly setup */
/* 将新线程的地址,交换到R8寄存器上 */
mov r8, gs:[PcCurrentThread] /* Pointer to the new thread */
call KiSwapContextInternal
/* Restore the registers from the KEXCEPTION_FRAME */
/* 把之前保存的寄存器值恢复到CPU寄存器 */
RESTORE_EXCEPTION_STATE
/* Return */
ret
.ENDP
MACRO(GENERATE_EXCEPTION_FRAME)
/* Allocate a KEXCEPTION_FRAME on the stack */
/* -8 because the last field is the return address */
sub rsp, KEXCEPTION_FRAME_LENGTH - 8
.allocstack (KEXCEPTION_FRAME_LENGTH - 8)
/* Save non-volatiles in KEXCEPTION_FRAME */
mov [rsp + ExRbp], rbp
.savereg rbp, ExRbp
mov [rsp + ExRbx], rbx
.savereg rbx, ExRbx
mov [rsp +ExRdi], rdi
.savereg rdi, ExRdi
mov [rsp + ExRsi], rsi
.savereg rsi, ExRsi
......省略
ENDM
MACRO(RESTORE_EXCEPTION_STATE)
/* Restore non-volatile registers */
mov rbp, [rsp + ExRbp]
mov rbx, [rsp + ExRbx]
mov rdi, [rsp + ExRdi]
mov rsi, [rsp + ExRsi]
mov r12, [rsp + ExR12]
mov r13, [rsp + ExR13]
mov r14, [rsp + ExR14]
mov r15, [rsp + ExR15]
movaps xmm6, [rsp + ExXmm6]
......省略
/* Clean stack and return */
add rsp, KEXCEPTION_FRAME_LENGTH - 8
ENDM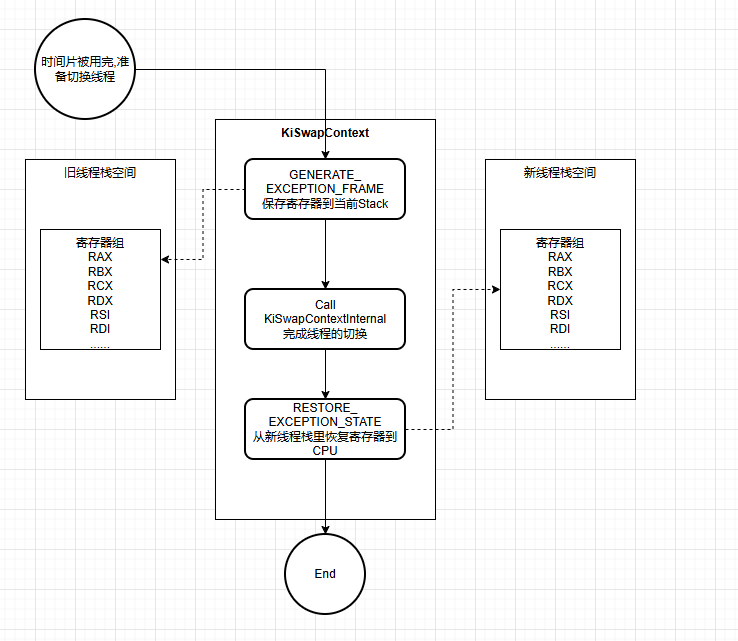
https://github.com/reactos/reactos/blob/master/ntoskrnl/ke/amd64/ctxswitch.S
线程调度模型(究极简化版)
在上面说到的逻辑核数据结构_KPRCB中,有三个属性。
单链表的DeferredReadyListHead,双链表的WaitListHead, 二维数组形态的DispatcherReadyListHead。
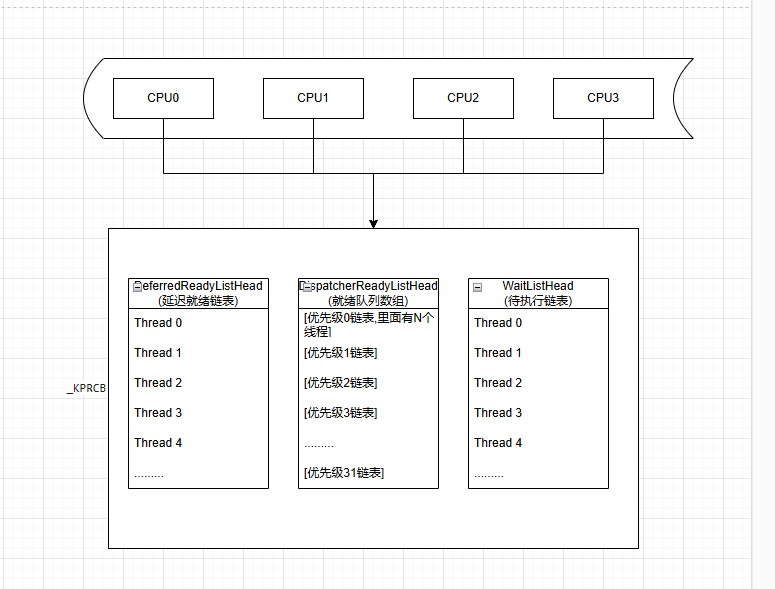
简单来说,当线程切换时,逻辑核从DispatcherReadyListHead根据线程优先级切换高优先级线程。如果线程主动放弃了时间片(thread.yield/thread.sleep),则会把线程放入DeferredReadyListHead。WaitListHead则用于存放那些正在等待某些事件发生的线程,如等待 I/O 操作完成、等待某个信号量或者等待互斥体等
眼见为实
直接看源码
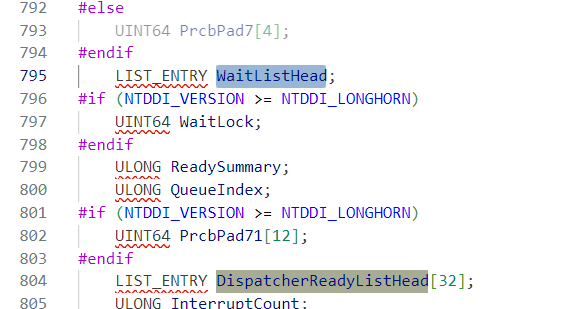
可以看到DispatcherReadyListHead大小为32,主要是因为windows将线程优先级设为了0-31不同的级别。
https://github.com/reactos/reactos/blob/master/sdk/include/ndk/amd64/ketypes.h
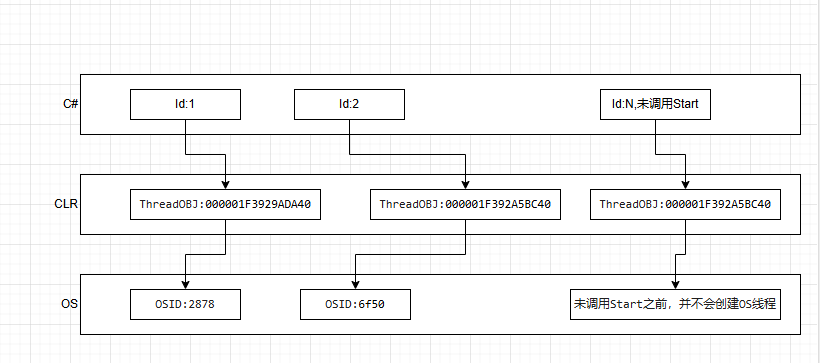
C#线程结构模型
C#线程的底层是CLR托管线程,而CLR的承载是操作系统线程。因此它们都有一一对应的关系。

分别对应C#线程(Thread.CurrentThread.ManagedThreadId),CLR线程,OS线程
线程在创建过程中会经历两个阶段
static void Main(string[] args)
{
var testThread = new Thread(DoWork);// 这个阶段只会在CLR中创建Thread,在OS上没有创建
testThread.Start();//CLR底层会调用系统api,创建OS线程
}