最近我给 FastGPT 用户交流群里接入了 AI 日报,每天早上 10 点会自动向群里推送 AI 日报,让群里的小伙伴们第一时间了解到昨天 AI 领域都发生了哪些大事。
效果大概是这个样子的:

如果你对 FastGPT 感兴趣,可以直接扫码入群:

除此之外,我还同步一份到公司的飞书群里,这样公司的小伙伴们也能及时了解到 AI 领域的最新动态。
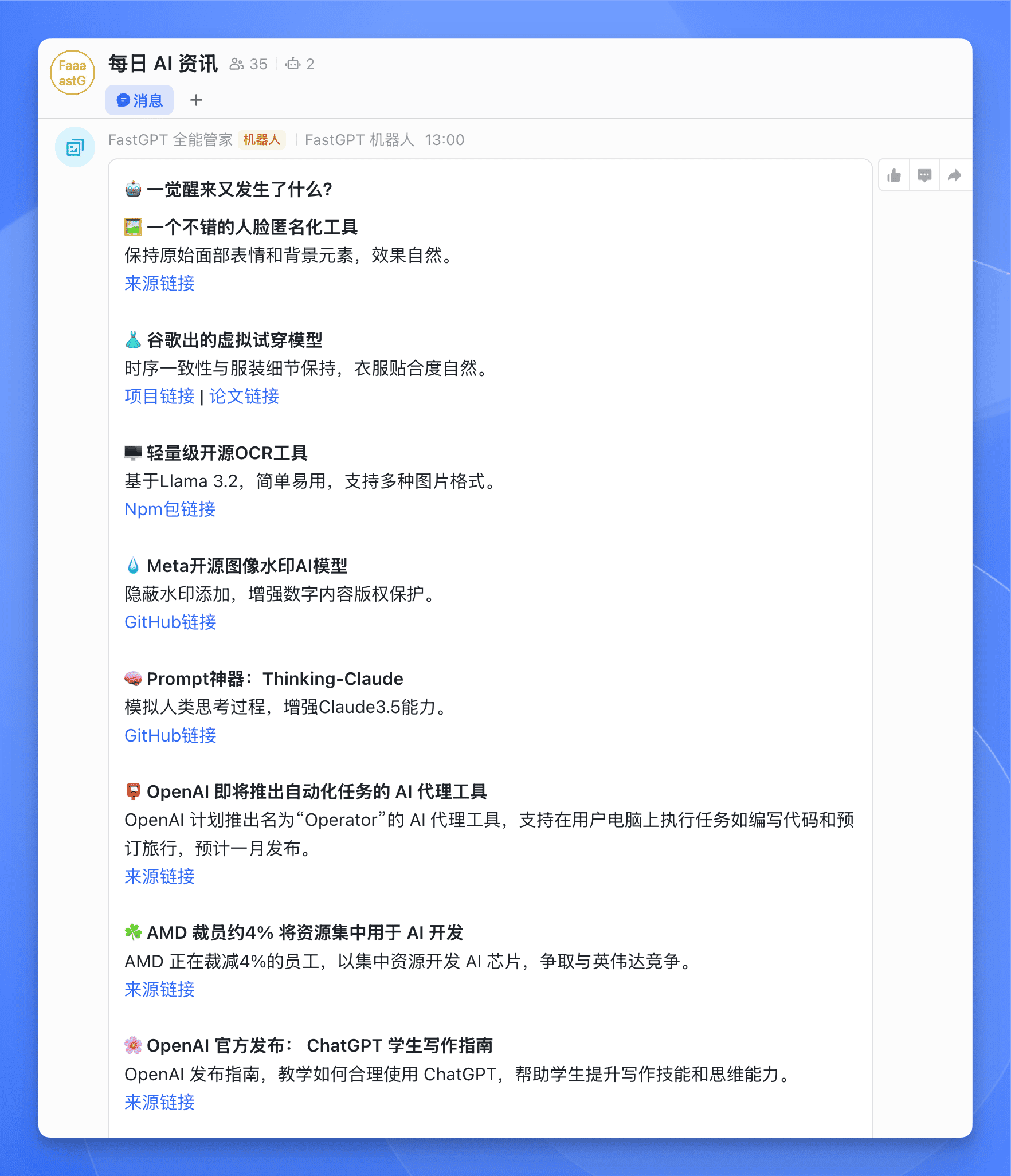
每一条资讯除了提供标题和概要之外,还附上了相关链接,方便大家进一步了解。
你以为这就完了?
我还给公司飞书群里每天发送一份 AI 领域的最新论文摘要,帮助研发同学汲取最新的科研成果。

为什么我要做这么一个日报呢?
因为现在 AI 领域的发展速度实在是太快了,每天都有新的论文、新的技术、新的产品发布,如果不持续关注,真的很容易被时代抛弃。
但是网上的信息量实在是太多太杂了,往往读上几十分钟都感觉没啥收获,但是又怕自己错过什么信息。
所以我就想,如果能开发个机器人,自动爬取并总结一些最新的信息,将简化后的信息每天定时发给我,如果感兴趣可以再进一步搜索,这样我就能每天都能高效获取到有价值的信息了。
有了需求之后,再进一步分析,可以发现这个需求主要的难点有两个:
- 写一个爬虫,爬取对应网站的信息
- 将获取到的信息,通过工作流编排总结归纳
恰好这两个需求分别可以被两个工具快速解决。
创建爬虫
首先,我需要创建一个爬虫,爬取对应网站的信息。
这就需要用到一个牛叉的开源项目 Crawl4ai。
这个项目性能超快,还能输出适合大语言模型的格式,比如 JSON、清理过的 HTML 和 markdown。它还支持同时爬取多个网址,能提取所有媒体标签 (图片、音频、视频),以及所有内外部链接。目前 star 数已经超过 1.5k。

问题来了,这个项目是基于 Python 开发的,而我既不懂 Python,也不会写爬虫。
这个倒是难不倒我,我可以用 Cursor 嘛,让它帮我写就好了。
但是我一想到写完之后还要打包部署,以及配置域名解析、申请 SSL 证书等各种繁琐的事情,瞬间就头大。
嘿嘿,这个问题也可以解决,直接用 Sealos Devbox 就好了,Devbox 直接摒弃了各种繁琐的配置,开箱即用,让你写完爬虫就能直接上线,啥都不需要配置。
我用 Devbox 和 Cursor 半个小时就写完了爬虫并且上线了,你就说快不快吧?
直接来看步骤。
创建开发环境
首先进入 Sealos 桌面,然后打开 Debox 应用,创建一个新项目。Devbox 支持多种主流语言与框架,这里我们需要开发爬虫服务,所以直接选择 Python 作为运行环境。

点击创建,几秒钟即可启动开发环境。
接下来在操作选项中点击 Cursor,将会自动打开本地的 Cursor 编程 IDE。

接着会提示安装 Devbox 插件,安装后即可自动连接开发环境。

Cursor 打开开发环境之后,执行 ./entrypoint.sh 就能看到项目成功跑起来了。

是不是非常简单?直接省略了配置域名解析、申请 SSL 证书,配置网关等与开发无关的繁琐操作,爽!
开发爬虫
接下来,我们就可以开始写爬虫了。
整个开发过程 Cursor 都可以全权代理,你只需要告诉他你要做什么,Cursor 就能帮你完成。

可以看到 Cursor 已经帮我们写好了 crawler 这个基础函数,只要填上需要爬取的地址,就能自动爬取。
它甚至还帮我们想好了下一步应该做什么,即添加一个新的路由来处理请求。

于是我顺着他的话继续往下问。


它也是非常快速地帮我们修改出了路由,这样我们就可以通过请求某个接口实现对应网站的爬取了。
接下来我想优化一下性能,便直接让它在代码上改,也是很快地帮我们优化好了。

最终爬取的效果如下:

有标题,有内容,有时间,有链接,这不就齐活了嘛。
整个开发过程我一行代码都没有写,都是 Cursor 帮我写的,包括爬虫库的使用、路由接口的编排、性能的优化等等,你说爽不爽?
上线爬虫
这个爬虫服务不需要一直运行,只需要每天定时运行一会儿,等我发完了日报就可以关闭了。最重要的是这样省钱啊,每天运行一小会儿,一个月下来也没多少钱,比自己买服务器划算多了。
而 Sealos 正好是按量付费的,运行多长时间就花多长时间的钱,用多少资源就花多少资源的钱,非常划算。
我们需要往 entrypoint.sh 这个文件中写入项目的启动命令 (因为 Devbox 项目发布之后的启动命令就是执行 entrypoint.sh 脚本)。

脚本修改完并保存之后,点击【发布版本】:

填写完信息后点击【发版】。

注意:发版会暂时停止 Devbox,发版后会自动启动,请先保存好项目避免丢失数据。
稍等片刻,即可在版本列表中找到发版信息,点击上线后会跳转到部署页面,点击部署应用即可部署到生产环境。
CPU 和内存可以根据自己的项目情况进行调整。


生产环境分配的 HTTPS 域名与开发环境独立,部署后即可通过生产环境域名访问这个爬虫的接口。

接入 FastGPT 工作流
现在有了爬虫接口,获取了资讯信息,就可以借助 AI 来总结提炼其中的核心信息了。
使用 AI 最简单的方式就是 FastGPT 工作流。
以我们要抓取的一个网站为例,直接使用 HTTP 节点接入即可。
在 HTTP 节点中,我们使用 GET 方法请求爬虫接口,并且设置超时时长为三分钟 (防止信息过多)。

因为爬虫接口的原始响应就是一个文章数组,所以我们可以不用自定义输出字段,直接将原始响应发送给 AI 对话节点即可。
这里用到的是李继刚老师研究的结构化提示词,以 lisp 语言的形式极简高效地实现了对 AI 的提示,我实测下来效果相当不错。

然后进行二次排版,将前面获取到的多个来源的文章总结进行进一步的整合和排版,便于输出。

最后调用 FastGPT 的飞书机器人插件,将整合好后的信息输出到公司的飞书群。

接下来配置一下工作流的定时执行,那么每天十点,早报机器人就会自动运行,总结过去 24h 发生的科技大事,然后以简洁准确的报告形式发送到工具群。

整体的工作流大致如下:

省钱
既然 Sealos 是按量付费,那我干嘛要一直运行着爬虫服务?
我只需要每天早上十点运行一次,然后爬取信息,总结信息,发送信息,然后就可以关闭服务了。
这样每天运行爬虫服务的时间也就几分钟,太省钱了哈哈 😄
那么该如何定时开机关机爬虫服务呢?
哈哈,我直接写到 FastGPT 的工作流里,在工作流的最前面和最后面分别接入一个 HTTP 节点,这样就可以在每天运行工作流之前和之后分别运行爬虫服务,然后关闭爬虫服务,我真是太有才了!
具体的步骤如下。
首先从 Sealos 桌面下载 kubeconfig 文件。

然后执行以下命令,将输出的内容作为请求接口时的 Authorization Header 值:
bash
cat kubeconfig.yaml | jq -sRr @uri在 FastGPT 工作流的最前面接入一个 HTTP 节点,URL 填入 Sealos【应用管理】的 API 接口地址:
https://applaunchpad.hzh.sealos.run/api/v1alpha/updateReplica请求方法选择 POST。
在 Header 中添加 Authorization 字段,值为上一步获取到的内容。

然后在 Body 中输入以下内容 (在 x-www-form-urlencoded 中填入参数):

其中 appName 是你的爬虫服务名称,可以在【应用管理】中查看:

而 replica 就是你的服务需要启动的实例数量,一般设置为 1 即可。
下面点击【调试】来测试一下:

搞定!

下面再接入一个 HTTP 节点,URL 填入以下地址:
https://applaunchpad.hzh.sealos.run/api/getAppPodsByAppName这个接口可以获取到当前爬虫服务运行的 Pod 信息,然后我们就可以根据 Pod 信息来判断爬虫到底有没有启动成功。
请求方法选择 GET。

在 Header 中添加 Authorization 字段,值和前面一样。
然后在 Params 中输入以下内容:

其中 name 是你的爬虫服务名称。
输出字段添加一个变量 data[0].status.containerStatuses[0].state.running,类型为 String。

再添加一个没用的【变量更新】节点,然后再接到【判断器】节点。
- 如果变量
data[0].status.containerStatuses[0].state.running存在,则表示爬虫服务还没运行成功,则接回到前面的【获取爬虫服务状态】节点,继续获取服务状态。 - 如果变量
data[0].status.containerStatuses[0].state.running不存在,则表示爬虫服务已经运行成功,则接入后面的 HTTP 节点开始调用爬虫服务。

最后发送完日报后,再接入一个 HTTP 节点来关闭爬虫服务。参数和前面的【自动开启爬虫服务】节点一样,只需要把 replica 设置为 0 即可。
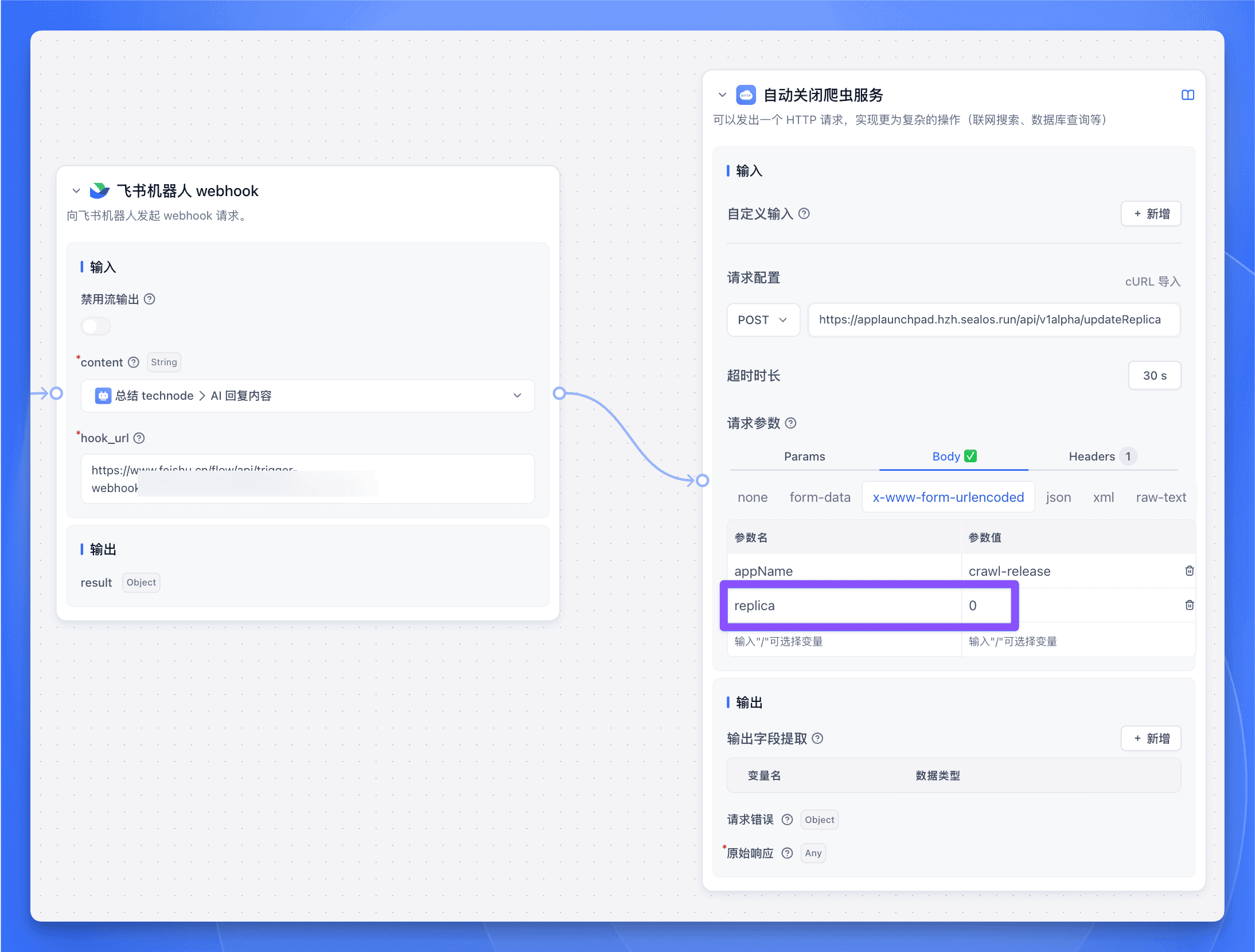
这样就搞定了,每天早上十点,爬虫服务会自动运行,发送完日报后会自动关闭,爽!
总结
好啦!到这里我们就完成了一个自动化的爬虫服务,它会在每天早上十点准时上班 (启动),完成工作 (发送日报) 后就自动下班 (关闭),比我们还自觉呢!😂
如果你也想搭建一个这样的 "自动打工人",可以参考以下资源:
快去试试吧,让 AI 帮你完成这些重复性的工作,解放双手享受生活!🎉