目录
- 总览
- 二阶段锁
- OOC
- 处理幻读
- MVC
- 原理
- [写偏差异常(Write Skew Anomaly)](#写偏差异常(Write Skew Anomaly))
- 版本存储(Version-storage)
- [Append Only](#Append Only)
- [Time Travel Storage](#Time Travel Storage)
- [Delta Storage](#Delta Storage)
- 垃圾回收
- [Tuple Level](#Tuple Level)
- [Transition Level](#Transition Level)
- 对比
- 索引管理
- 删除
- 各个数据库的实现方式
- 总结
总览
该笔记包含了原课程中关于并发控制的四节课的内容:
- 并发控制理论(Concurrency Control Theory)
- 二阶段锁并发控制(Two-Phase Locking Concurrency Control)
- 乐观并发控制/基于时间戳(Optimistic Concurrency Control)
- 多版本并发控制(Multiple-Version Concurrency Control)
ACID
并发控制与数据库恢复一体两面,在数据库系统中设计到如下部分:
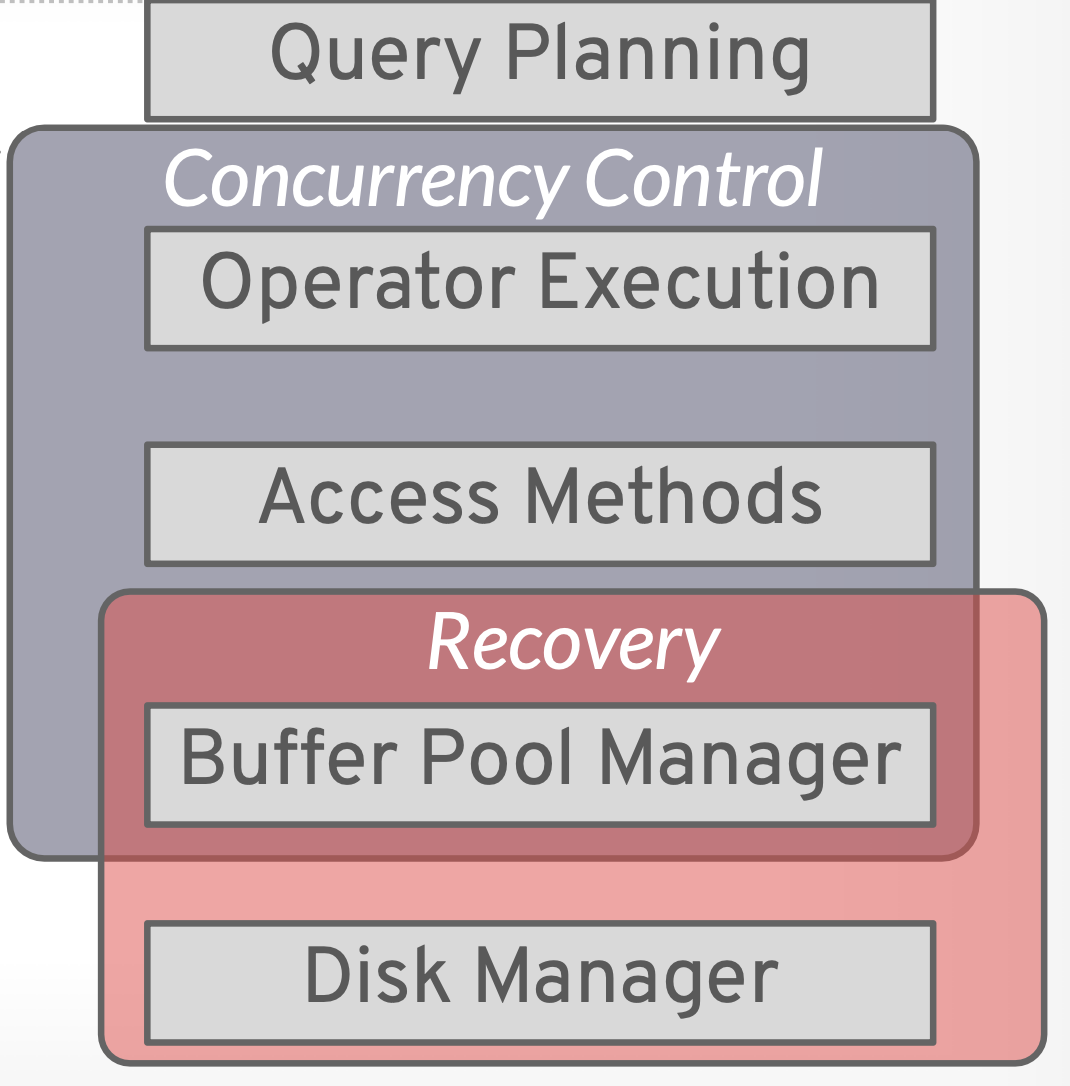
数据库为达成一个目的的语句块称为一个事务,特殊地,一个语句本身就可以视为一个事务。
并发控制与数据库恢复的目标是实现事务的ACID:
- Atomicity:全或无。
- Consistency:数据整体一致;分布式场景下,强一致或最终一致。
- Isolation:事务并行,但是互不干涉。
- Durability:事务提交,就保证修改已经持久化。

串行化与冲突操作
如何确定事务并发的执行结果是满足隔离性(Insolation )的?
答:事务是可串行化的,即并行调度结果和串行调度一致。
串行调度(Serial Schedule):数据库每次只执行一个事务,不并行。
可串行化调度(Serializable Schedule):允许事务并行,但是并行执行的结果可以等效为串行调度。
为什么有的事务是可串行化的,而有的无法串行化?
答:取决于是否包含(读写)冲突操作,存在冲突操作时,往往就是不可串行化的。
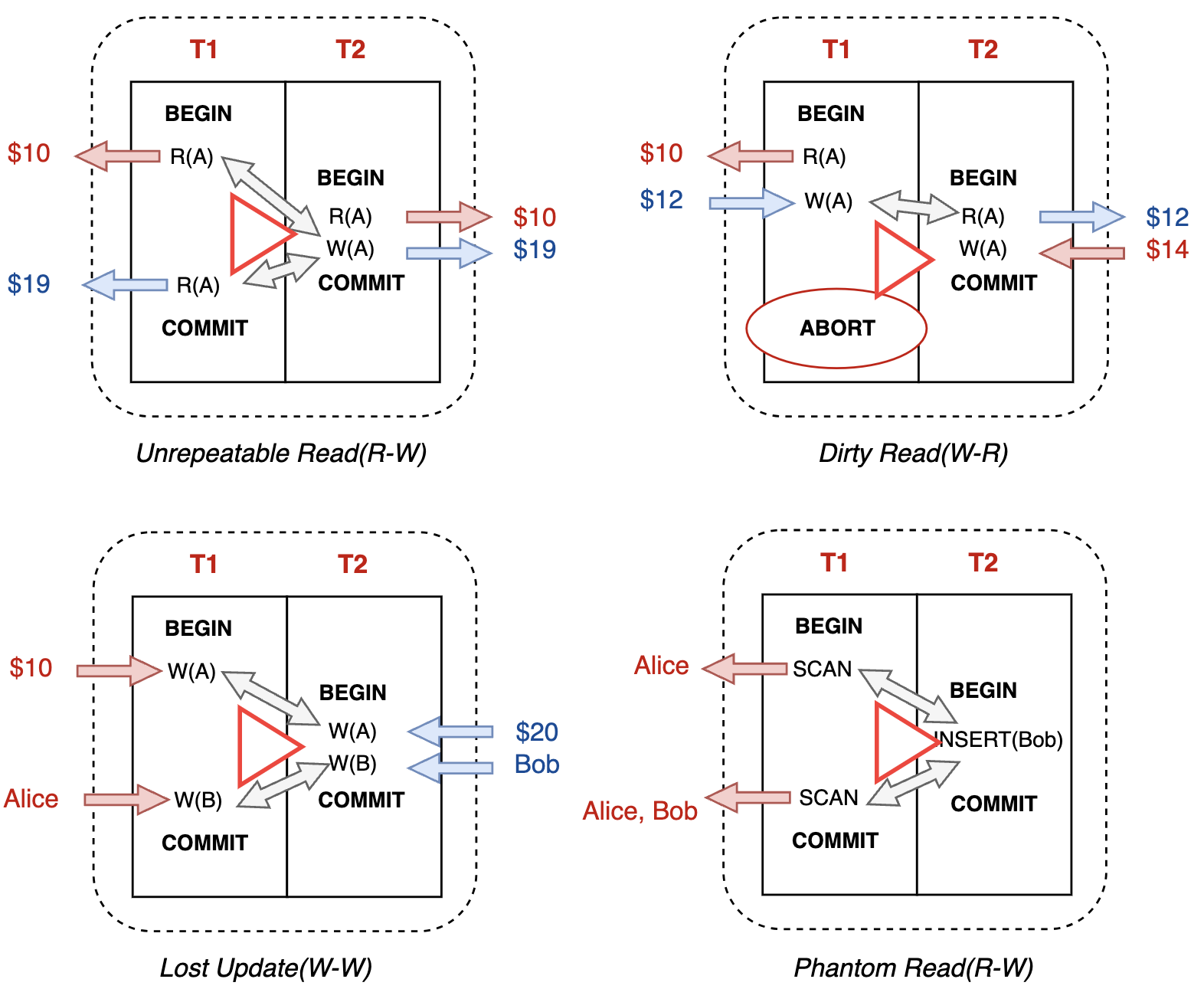
冲突操作带来并发问题:
- 读写冲突(R-W ):不可重复读,幻读严格来说是 *Scan / Insert*
- 写读冲突(W-R):脏页读
- 写写冲突(W-W):更新丢失
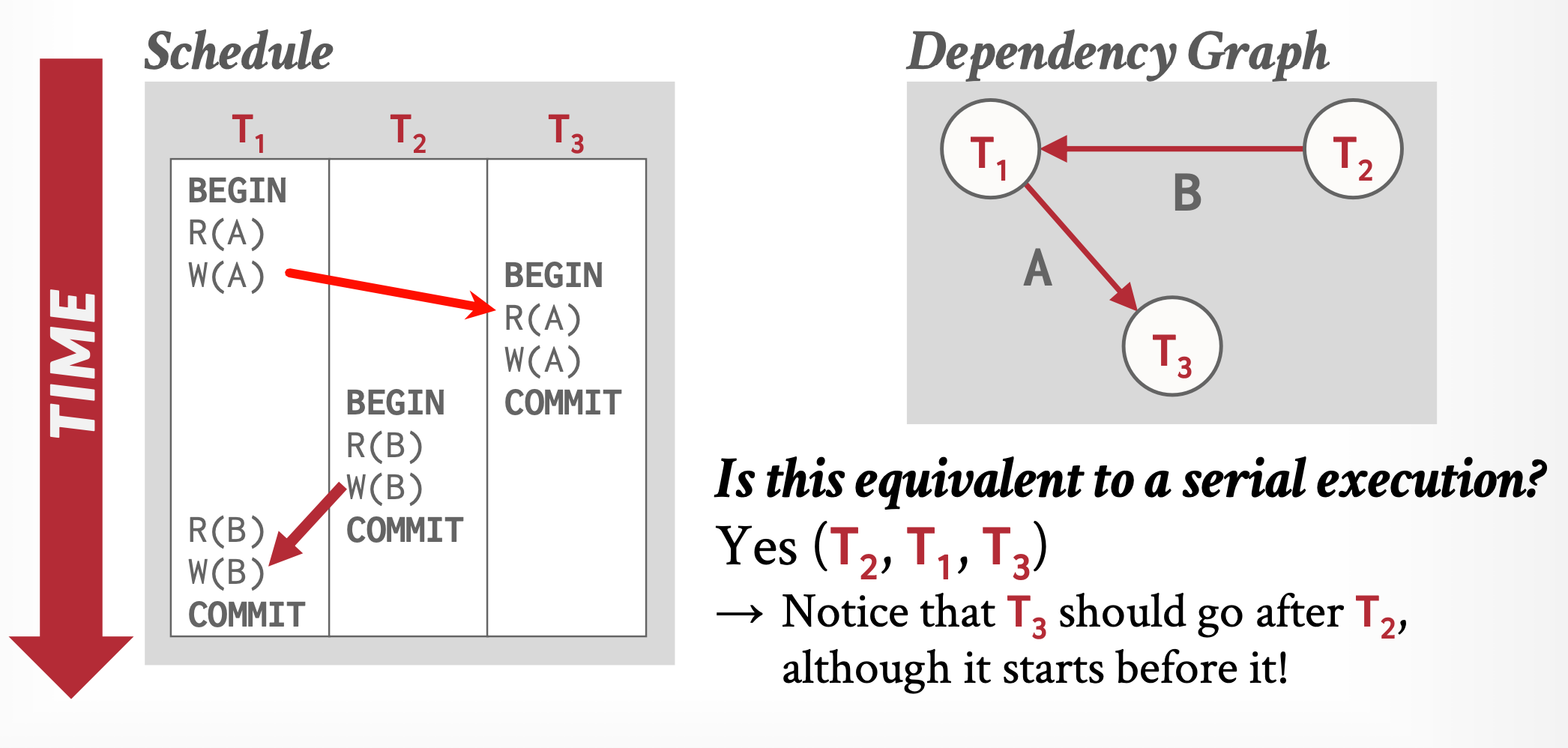
如何判断一组事务是可串行化的?
答:依赖关系图(Dependency Graph)不成环。
(脏读一般是回滚时才考虑)
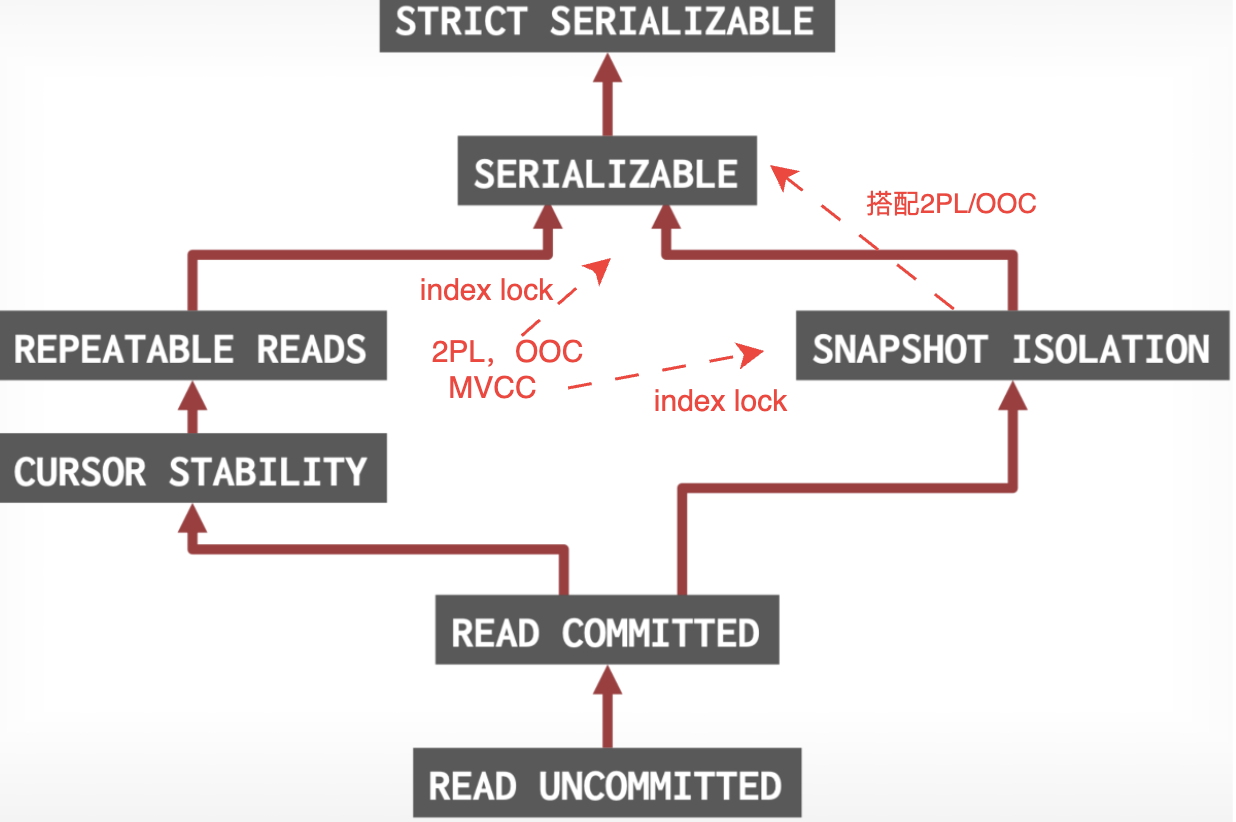
隔离级别
数据不一致问题与隔离级别对照图。
| Dirty Read | Unrepeatable Read | Lost Update | Phantom | |
|---|---|---|---|---|
| Serializable | No | No | No | No |
| Repeatable Read | No | No | No | Maybe |
| Read Committed | No | Maybe | Maybe | Maybe |
| Read Uncommitted | Maybe | Maybe | Maybe | Maybe |
不同数据库支持的隔离级别。
其中比较特殊的是Oracle最高支持的是Snapshot Isolation 而不是Serializable。
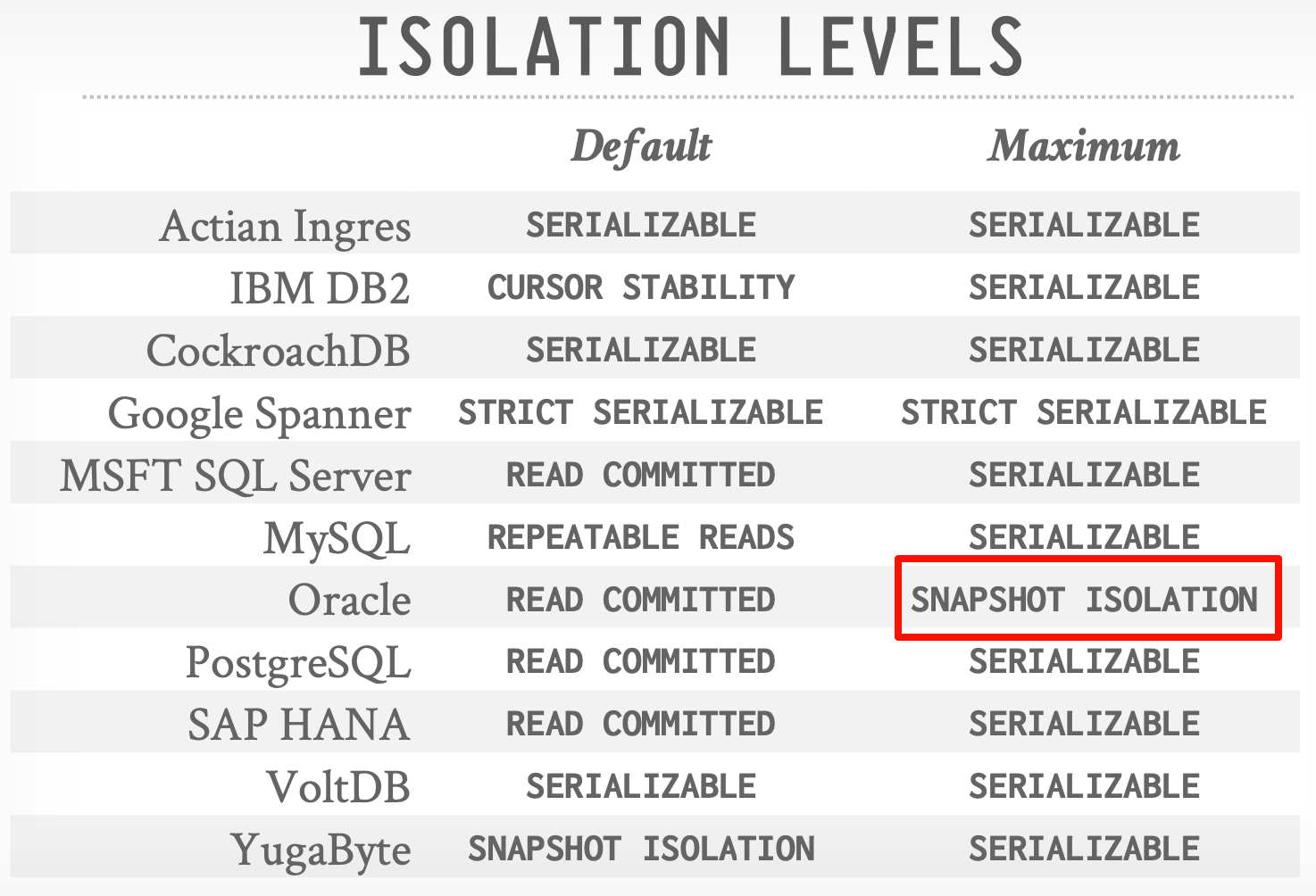
完整的隔离级别层级图。
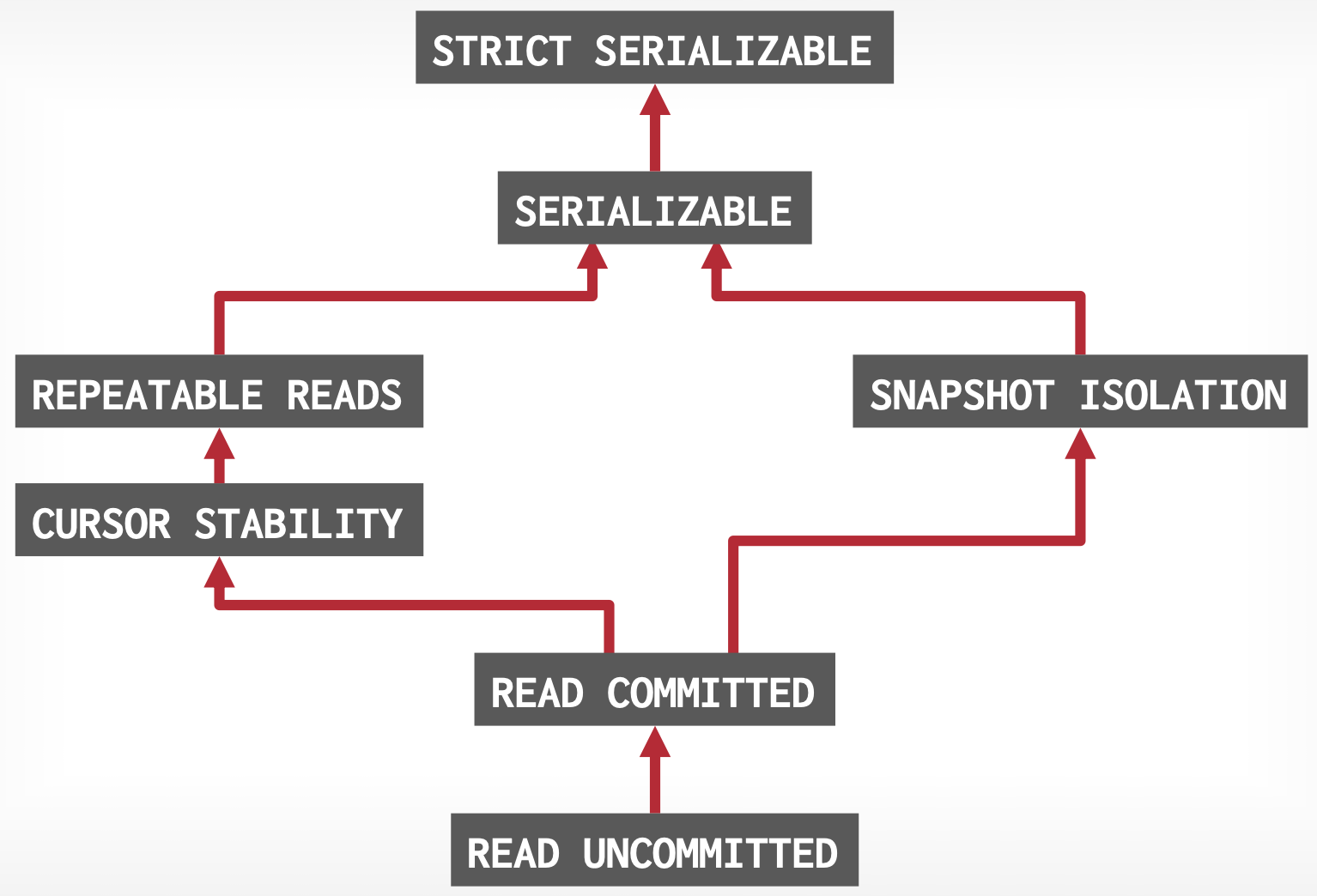
事务的串行化调度和串行化隔离级别的关系:
-
串行化调度(Serializable Schedule):保证事务一致性,指两个事务并发时,效果等价于串行执行,即依赖图不成环。
-
串行化隔离级别(Serializable Level):指不出现上文的四个并发问题。
-
一般认为,满足 串行化隔离级别 时,事务间就可以实现串行化调度。
概念层级
并发控制实现的目标是事务的ACID ,但由于存在冲突操作 ,导致出现一系列并发问题,造成数据不一致,为了权衡性能与并发问题的错误程度,定义了不同的隔离级别 ,为了实现不同的隔离级别,有各样的并发控制机制,如二阶段锁,OOC,索引锁等等。
概念由抽象到具体,从顶层到底层,结构图如下:

下面主要介绍不同的并发控制机制的原理与解决的问题。
二阶段锁
原理
有两类锁,共享锁和互斥锁。
| S-Lock | X-Lock | |
|---|---|---|
| S-Lock | ✓ | ✗ |
| X-Lock | ✗ | ✗ |
二阶段锁如何解决并发问题?
- 最粗的粒度:事务开始就加锁,事务提交时释放锁,此时是严格的串行化,但是效率不高。
- 最细的粒度:操作时加锁,操作结束就释放锁,没有解决依赖图成环的问题,依然是非串行化的。
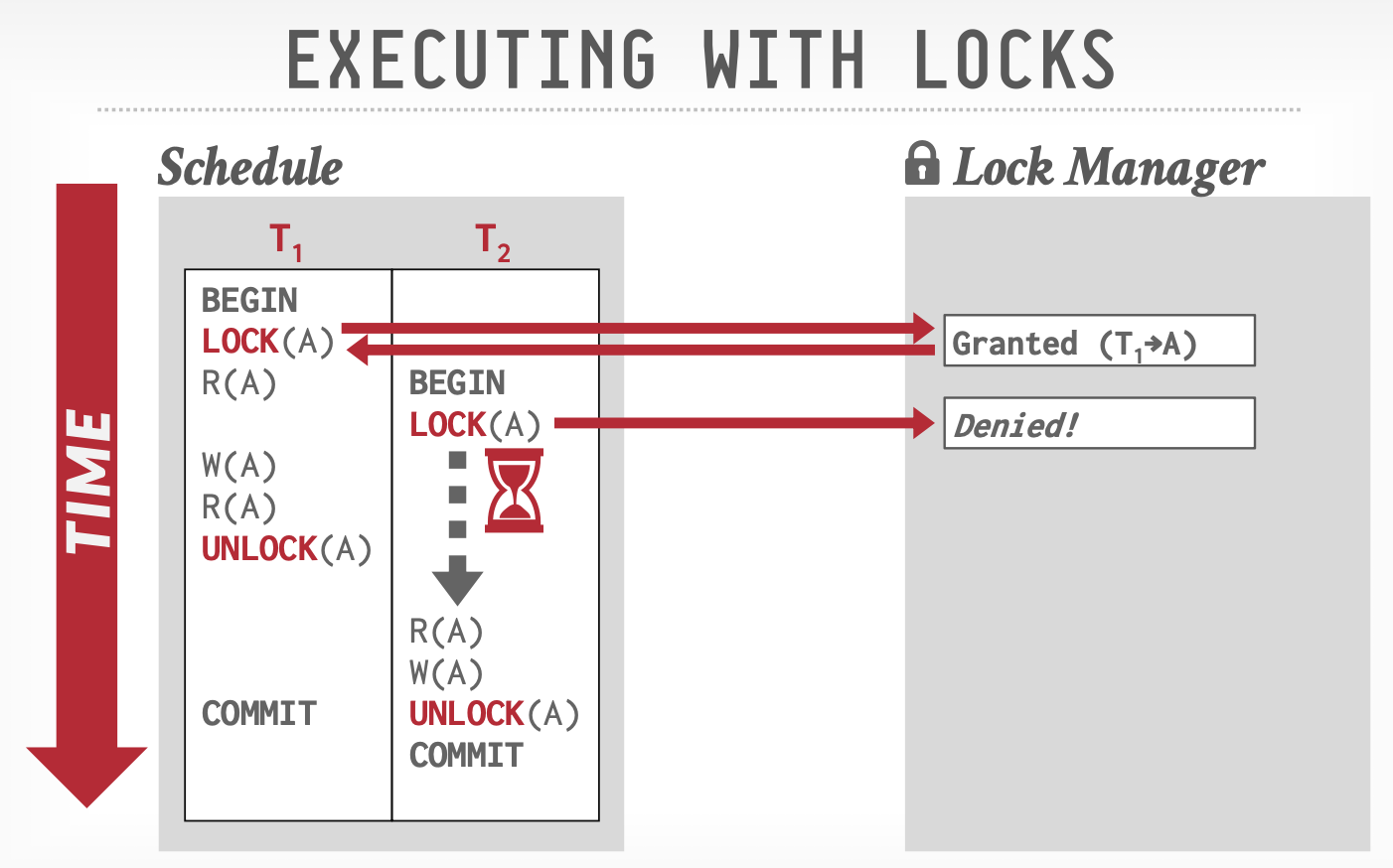
- 二阶段锁:分为两个阶段,锁获取阶段和锁释放阶段,只有获取完所有锁以后才能释放锁。
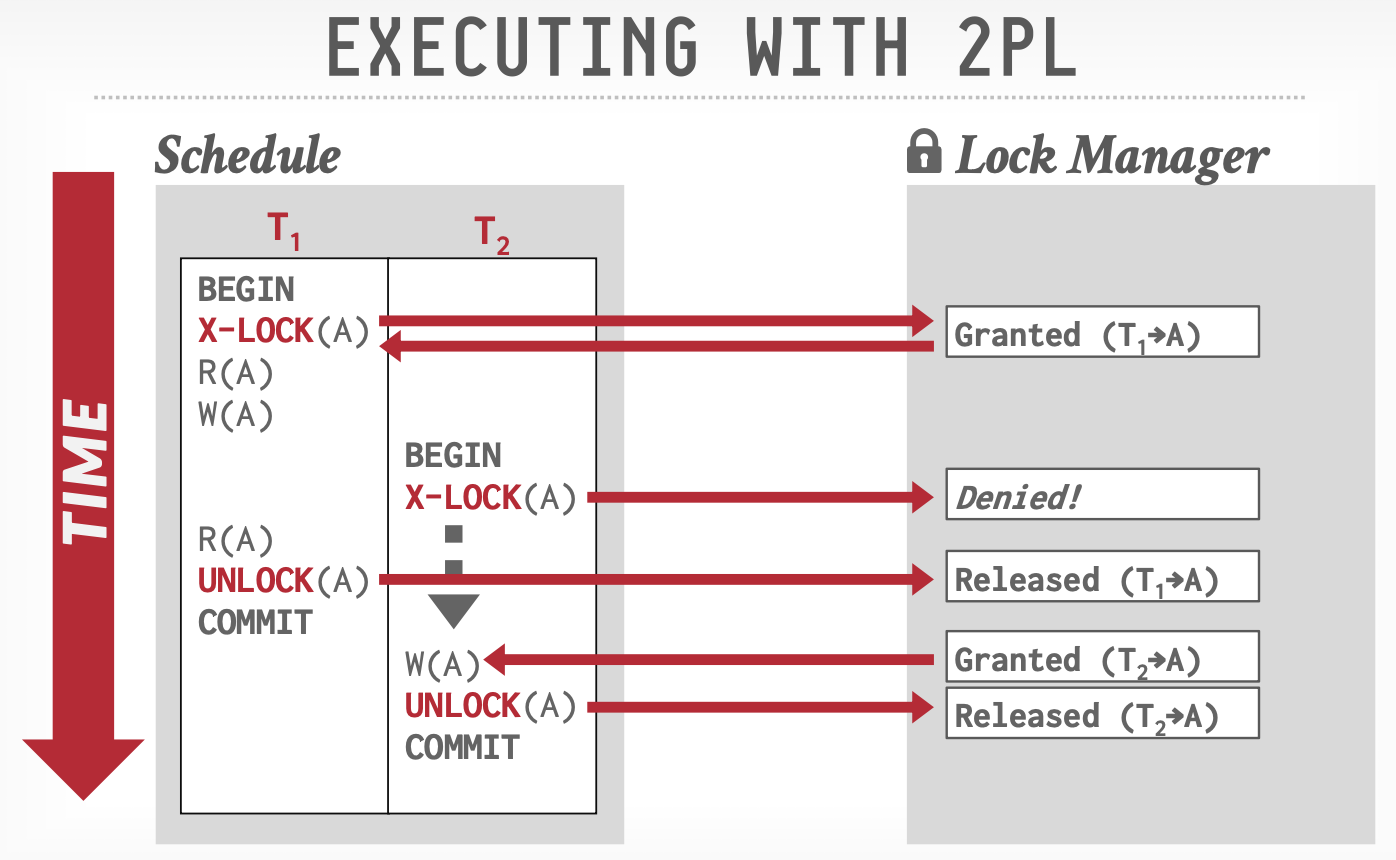
由于获取完所有锁才会释放,所以依赖图不会成环(见"串行化与冲突操作"一节),但是由于我们无法对Abort操作加锁,并且插入或删除元素时也无法加锁,因此二阶段锁可以解决不可重复读和更新丢失,无法解决脏读和幻读。
级联回滚
脏读会带来级联回滚(Cascading Abort)的问题,见下图。
\(T_2\)读取了\(T_1\)未提交的数据,导致\(T_1\)回滚时,\(T_2\)也需要回滚。

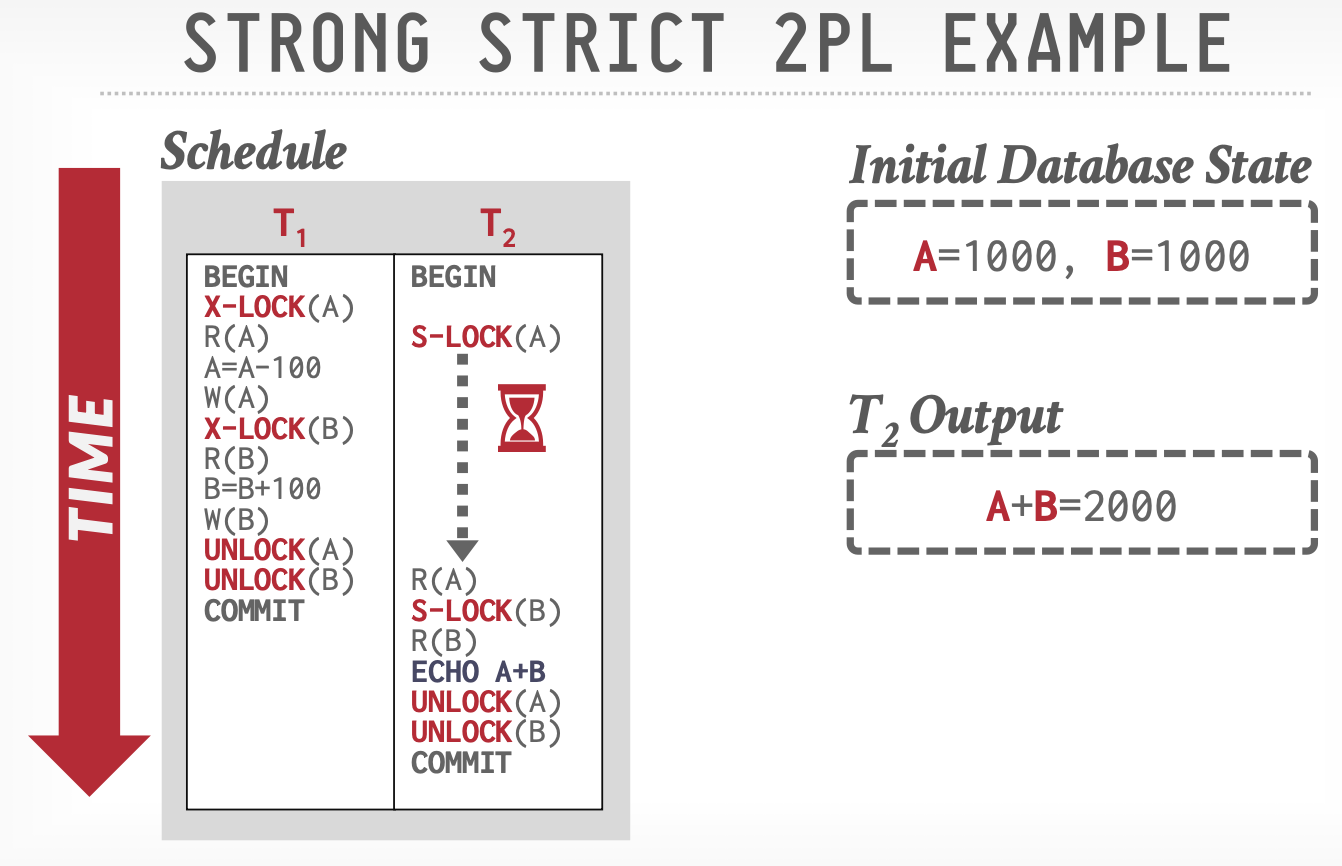
强二阶段锁
强二阶段锁(String Strict 2PL):不是操作结束后立刻解锁,而是在事务提交时统一解锁。
解决了脏读问题。因为由于事务提交前不释放锁,所以另一个事务无法读到刚修改的数据。
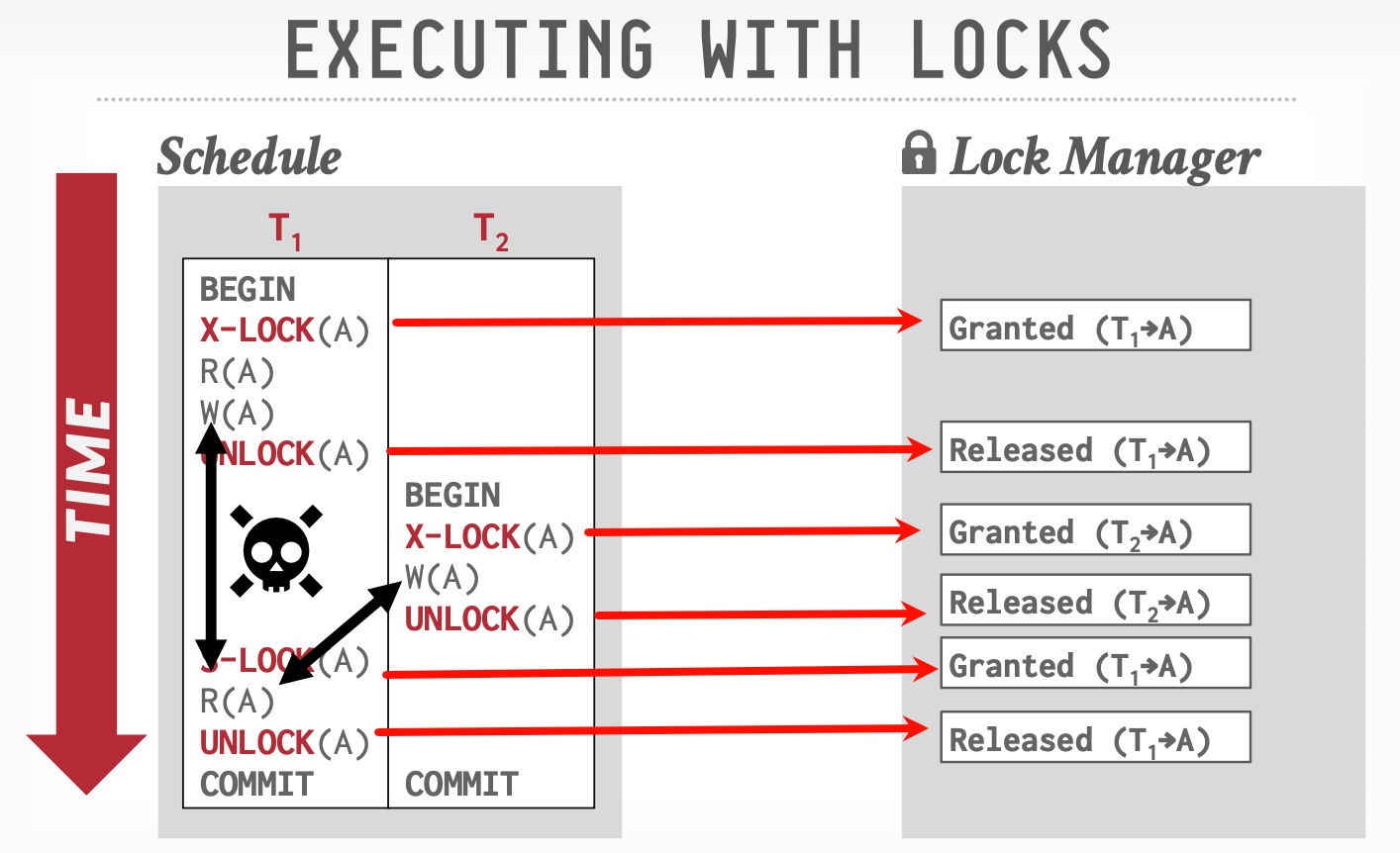
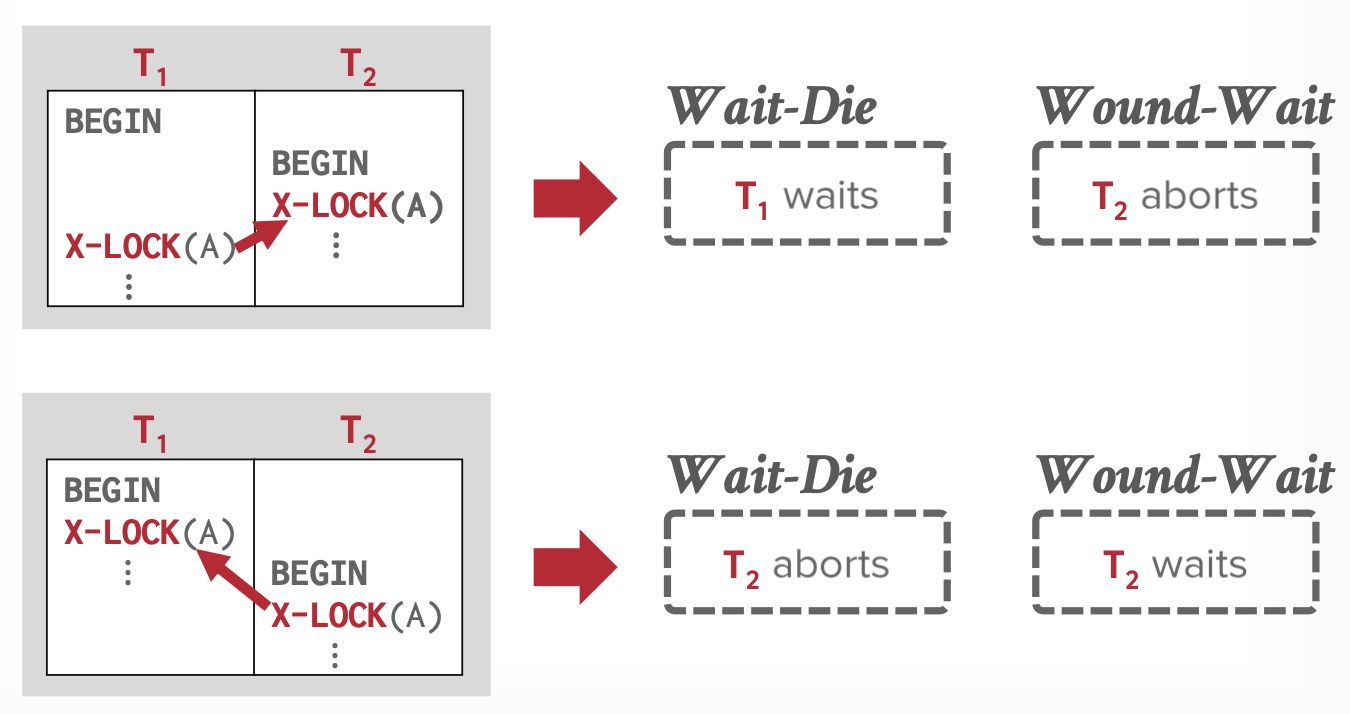
死锁检测和避免
一个死锁的例子:锁交错。
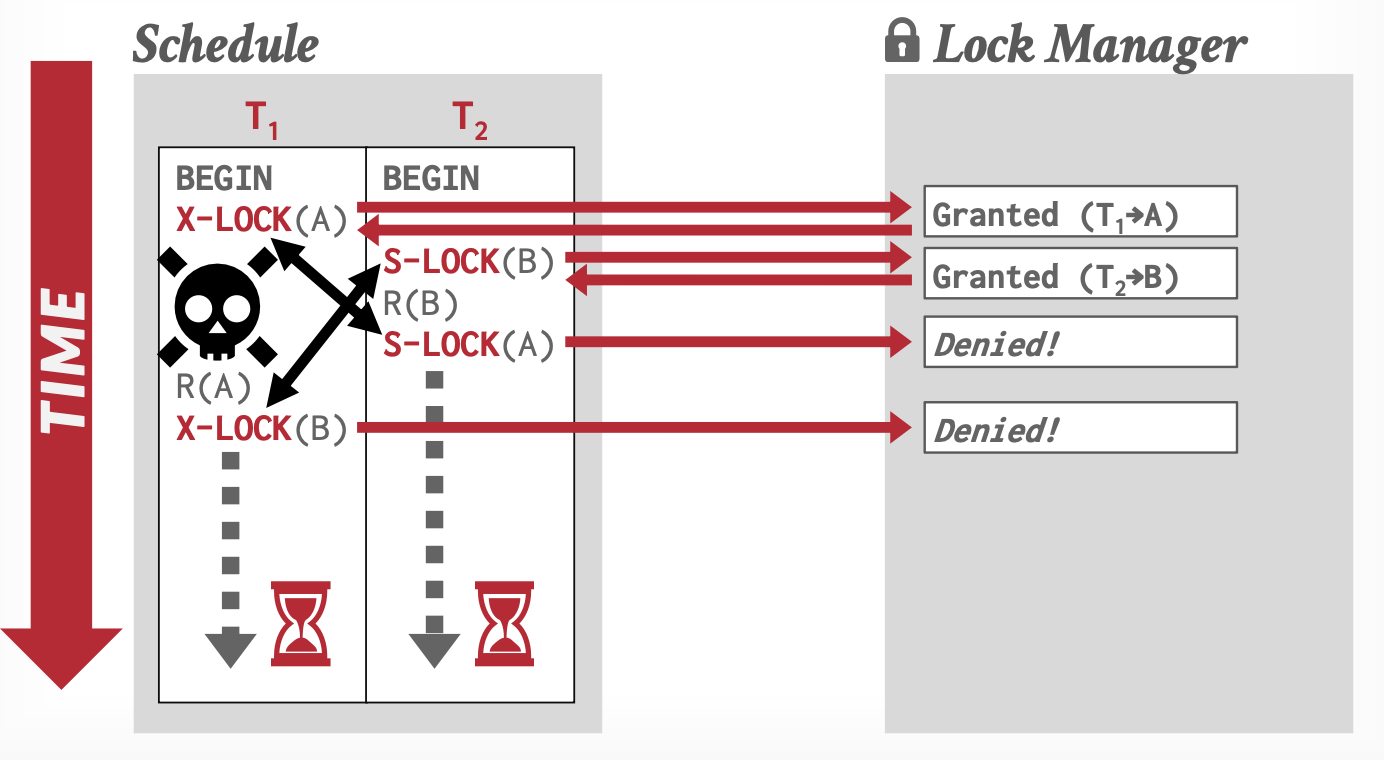
死锁检测:检测是否成环
时序图上体现为交叉,在依赖图上体现为环。
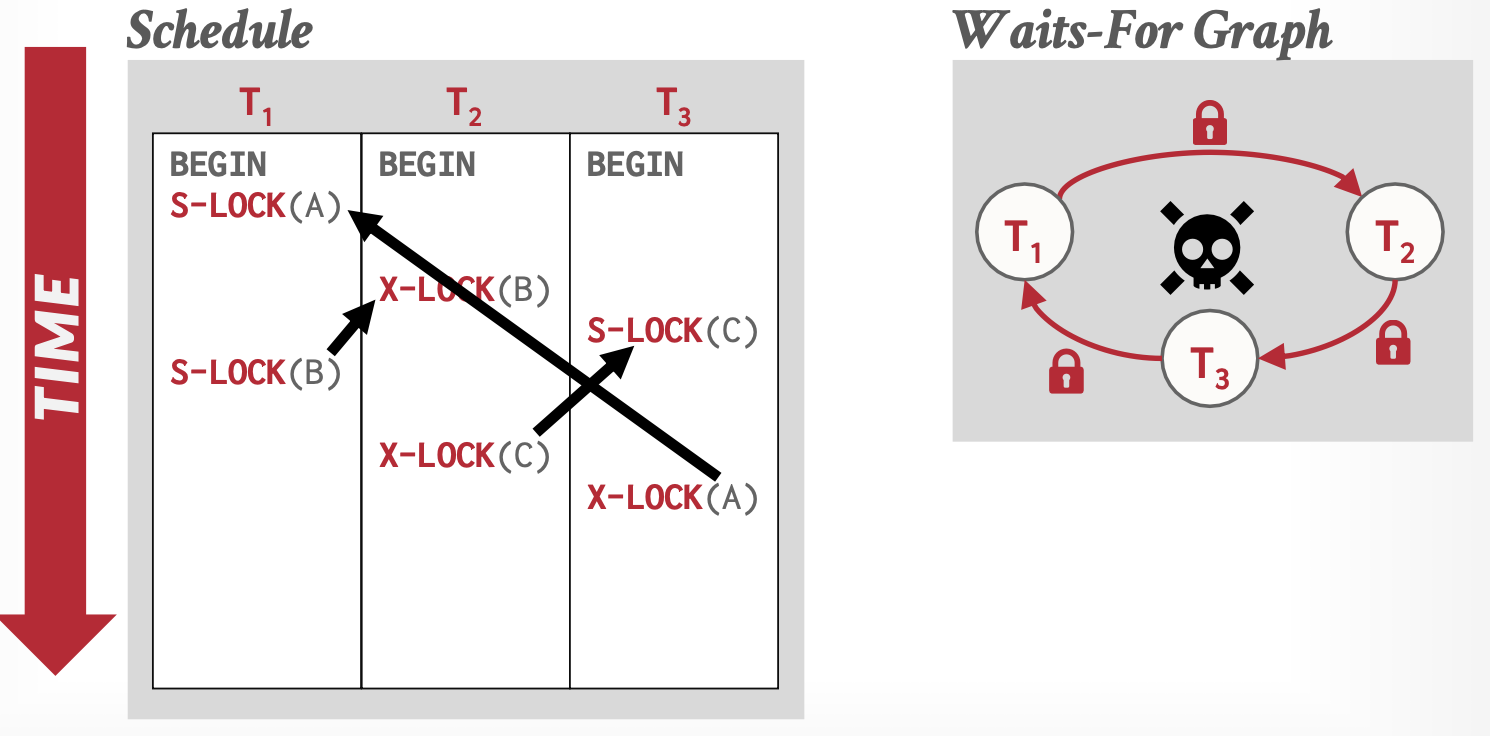
处理方式:选择一个事务进行回滚。
如何选择:依照年龄,执行进度,锁数量等。
如何回滚:全部回滚;部分回滚:设置savepoint,回滚到savepoint。
死锁避免:设置优先级,保证锁单向传递,不产生交错
- 事务的开始时间越早,优先级越高
- 分类:非抢占式(Wait-Die ),抢占式(Wound-Wait)
| 高->低 | 低->高 | |
|---|---|---|
| 非抢占式 | 高优先级等待【爱幼】 | 低优先级放弃 |
| 抢占式 | 高优先级抢占 | 低优先级等待【尊老】 |
没有双向等待,也就不会产生交错,也就不会有死锁。
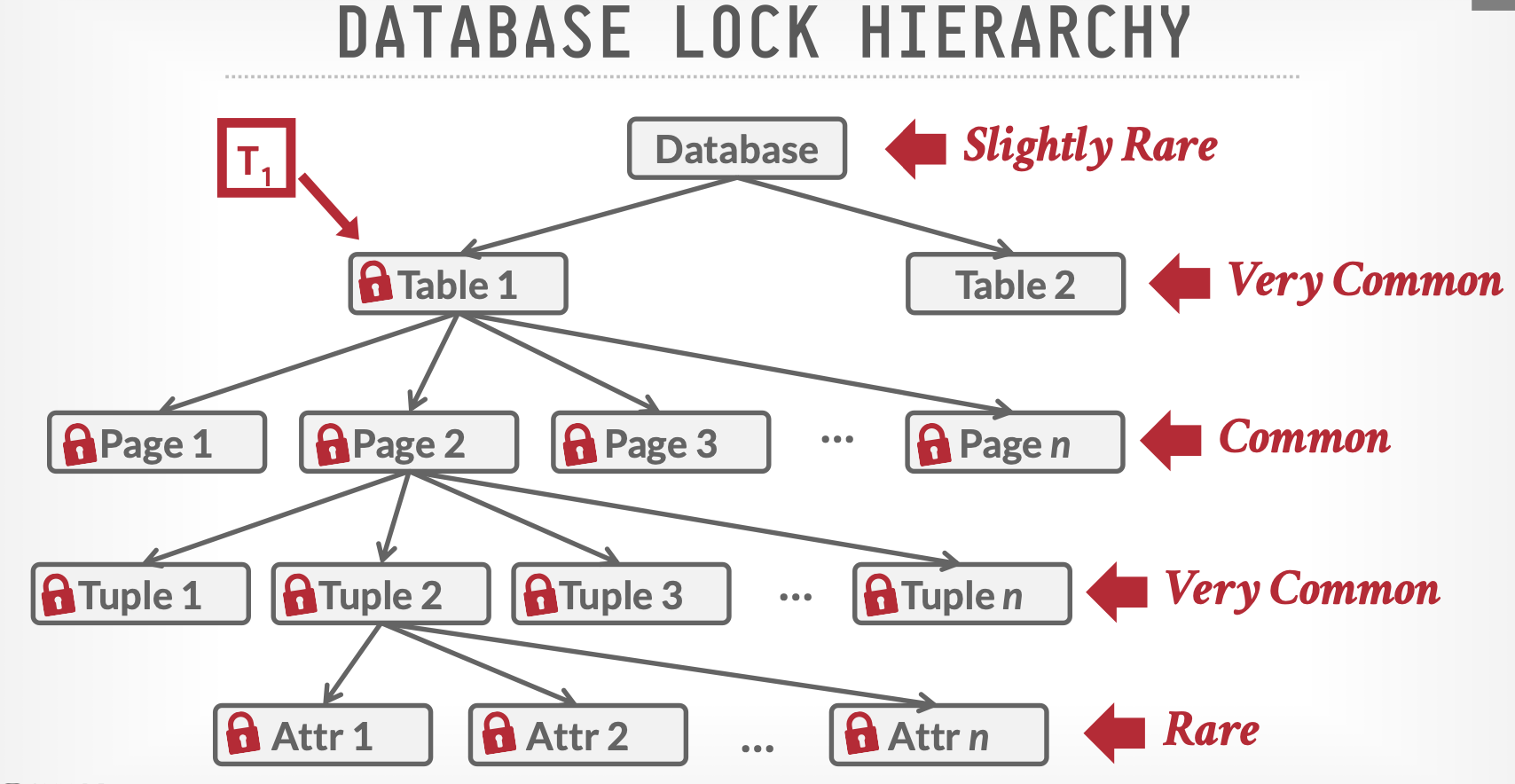
锁层级
数据库需要维护不同层级(Hierarchical)的锁来保证并发度。
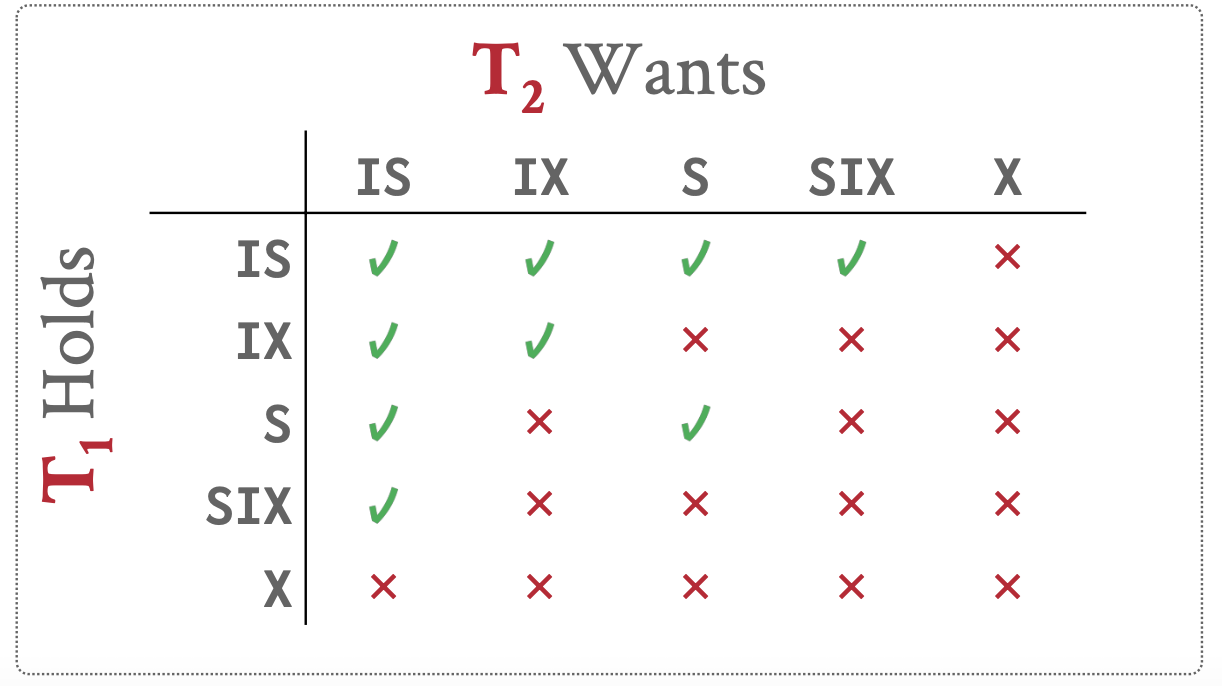
意向锁:在给子层级加锁时,给父层级加意向锁,兼容矩阵如下。
实践应用
Select ... For Update
sql
BEGIN;
SELECT balance FROM Accounts WHERE account_id = 1 FOR UPDATE;
UPDATE Accounts SET balance = balance - 100 WHERE account_id = 1;
COMMIT;扣减余额时,先select再update:
- select时,
account=1的tuple上的是S锁,父结点上的是IS锁; - update时,
accnount=1的tuple需要上X锁,父结点升级为ISX锁; - 所以可以通过
Select ... For Update,一开始就给tuple上X,给父结点上ISX锁
Select ... Skip Locked
可以跳过锁,避免阻塞。
例如:
sql
SELECT task_id, task_data
FROM task_queue
WHERE status = 'pending'
FOR UPDATE SKIP LOCKED
LIMIT 1;- 一个任务表存储了待处理任务,每个任务由不同的线程负责处理:
- 每个线程获取一个未锁定的任务进行处理;
- 已被其他线程锁定的任务会被跳过,从而提高并发处理效率
实现的隔离级别
- SERIALIZABLE:强二阶段锁+幻读预防措施(如索引锁,见后文)。
- REPEATABLE READS:强二阶段锁。
OOC
乐观的并发控制(Optimistic Concurrency Control)。
原理
假设大多数时候没有冲突,先执行操作,操作结束后再进行一次验证。
- 如果确实没有冲突,提交事务,写入结果
- 如果有冲突,回滚,重新进行
三个阶段
- 读取(Read Phase):每个事务有一个私有的存储空间,当访问元组时,将访问结果读取到该空间中,后续的操作都在该空间进行。
- 验证(Validation Phase ):赋予事务一个时间戳 ,并校验是否有冲突,即是否满足下面的条件。
- \(WriteSet(T1) ∩ ReadSet(T2) = Ø\)
- 如果此时事务2还处于读取阶段,那么还需要满足:\(WriteSet(T1) ∩ WriteSet(T2) = Ø\)
- 写入(Write Phase):写入结果,此时修改其他事务可见。
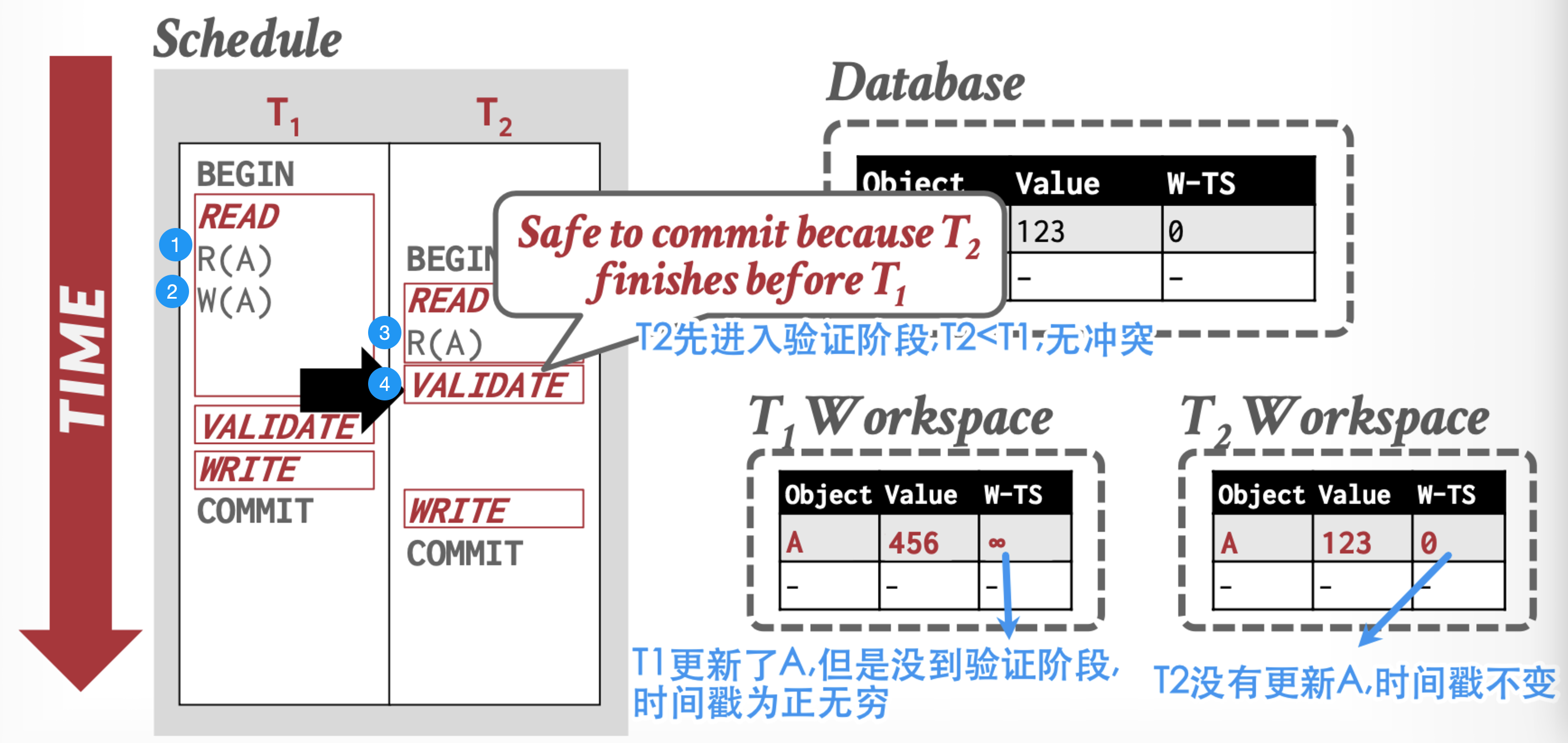
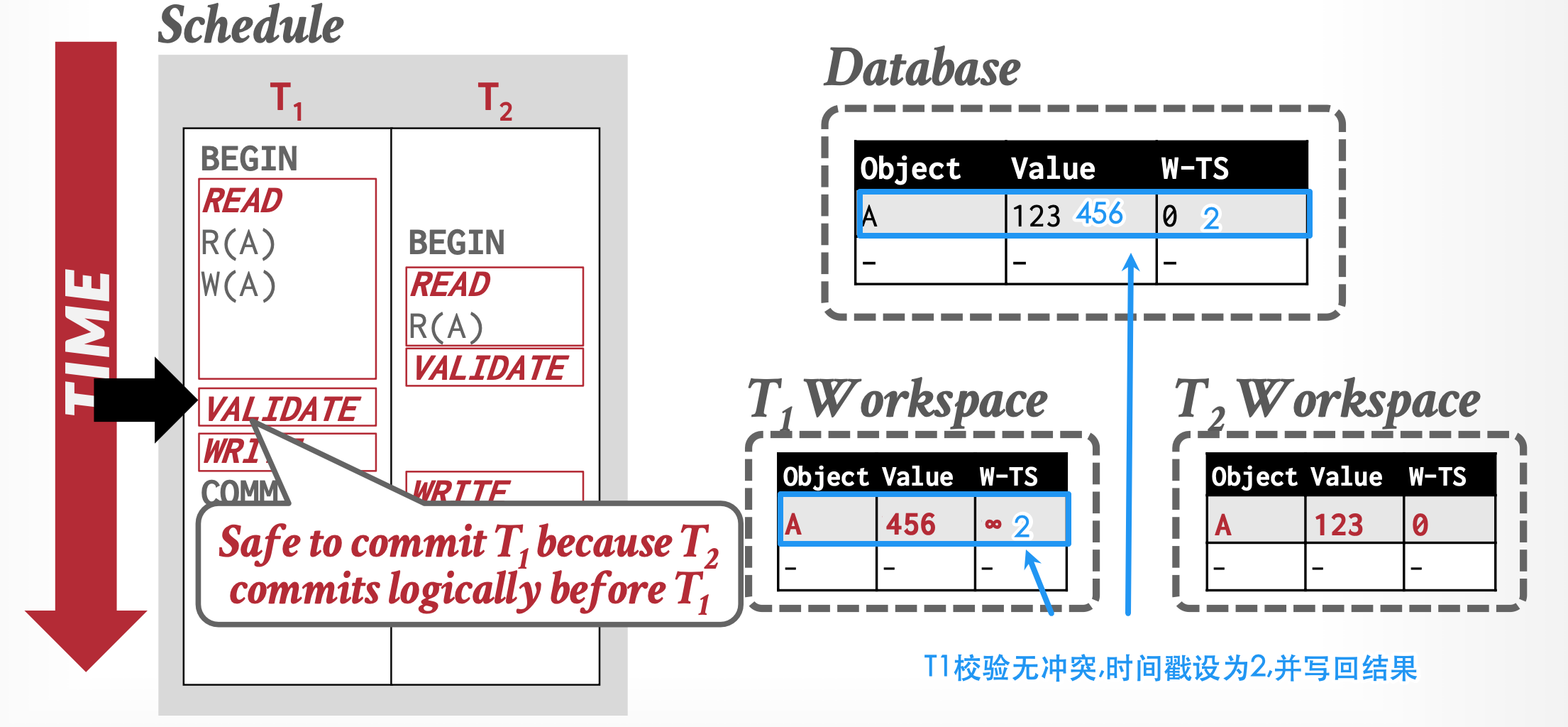
实现的隔离级别
如何解决并发问题:并发问题的图示见上文"串行化与冲突操作"一节
当处于验证阶段时,如果\(T_1<T_2\):
-
由于读的是副本:不会出现脏读 和不可重复读问题。
-
由于读的是副本:如果\(WriteSet(T1) ∩ ReadSet(T2) ≠ Ø\)
\(T_2\)理应看到\(T_1\)的更新值,但是由于\(T_1\)还没有把结果写入磁盘,所以\(T_2\)读的是副本,而不是\(T_1\)的更新值。
所以此时存在数据不一致问题,因此要保证\(WriteSet(T1) ∩ ReadSet(T2) = Ø\)
-
\(WriteSet(T1) ∩ WriteSet(T2) = Ø\):解决更新丢失问题。
-
没有解决幻读问题。
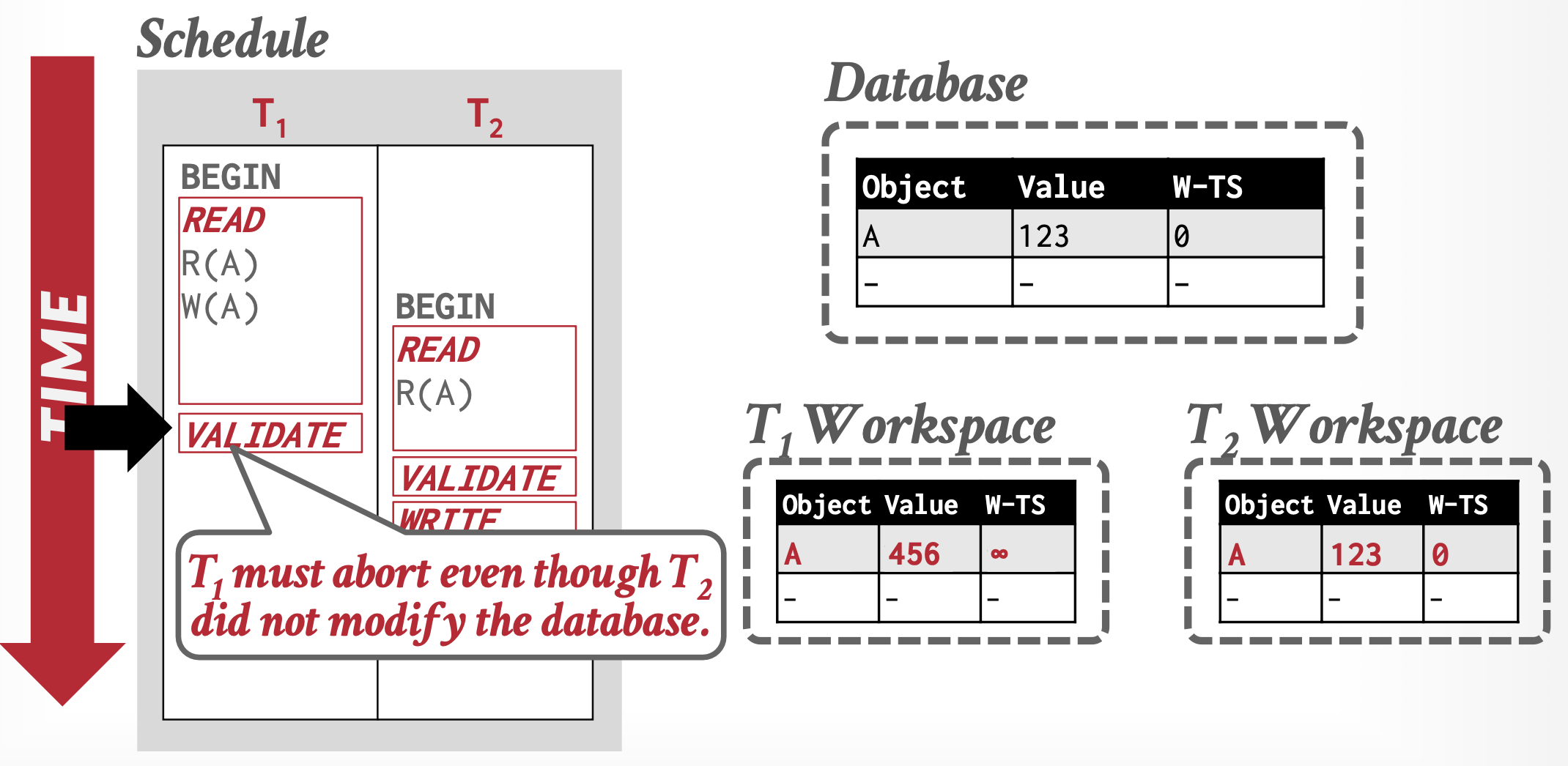
反例1:\(WriteSet(T1) ∩ ReadSet(T2) ≠ Ø\),此时\(T_2\)没有读到\(T_1\)的更新。
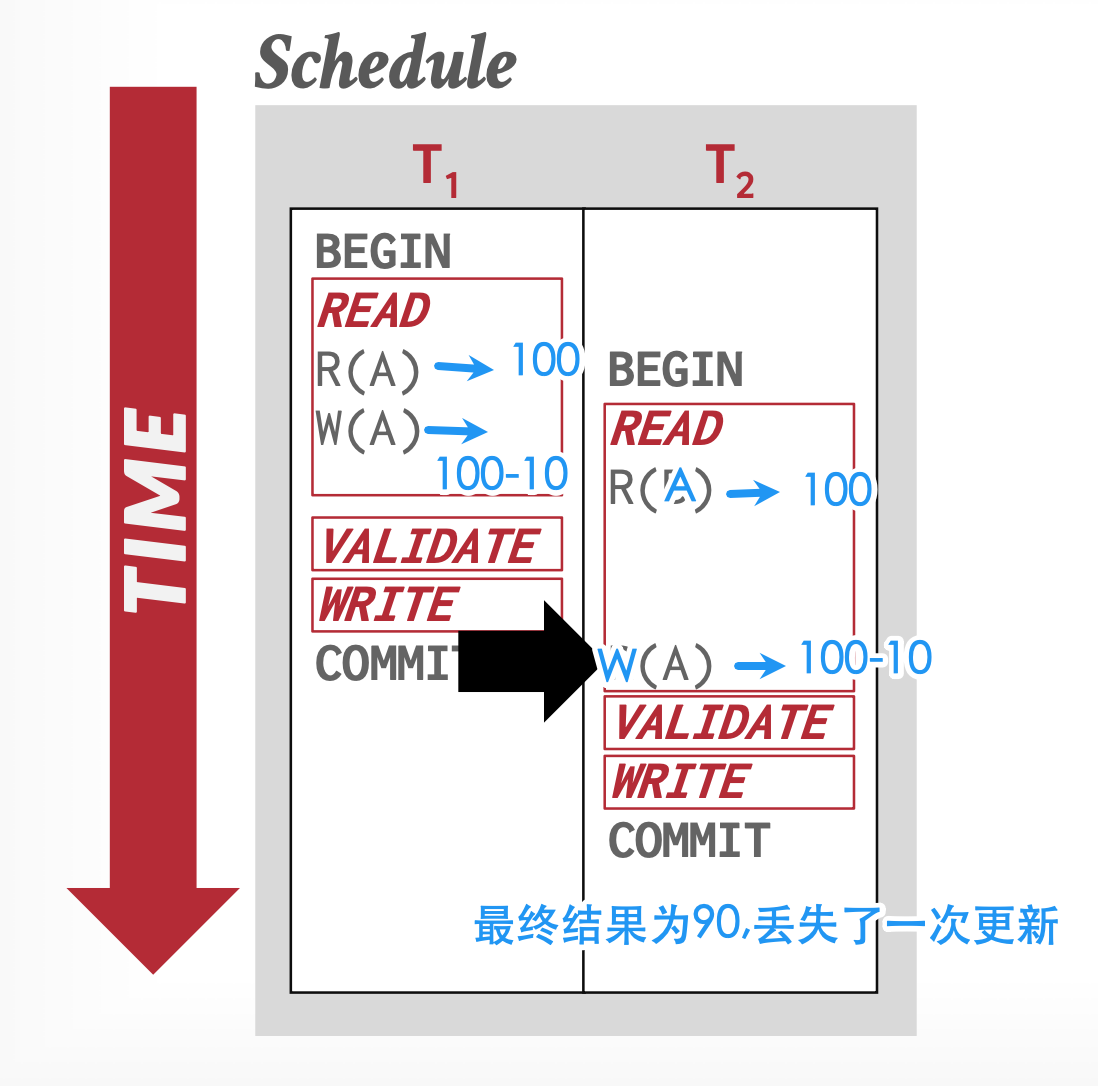
反例2:\(WriteSet(T1) ∩ WriteSet(T2) ≠ Ø\),可能出现更新丢失问题。
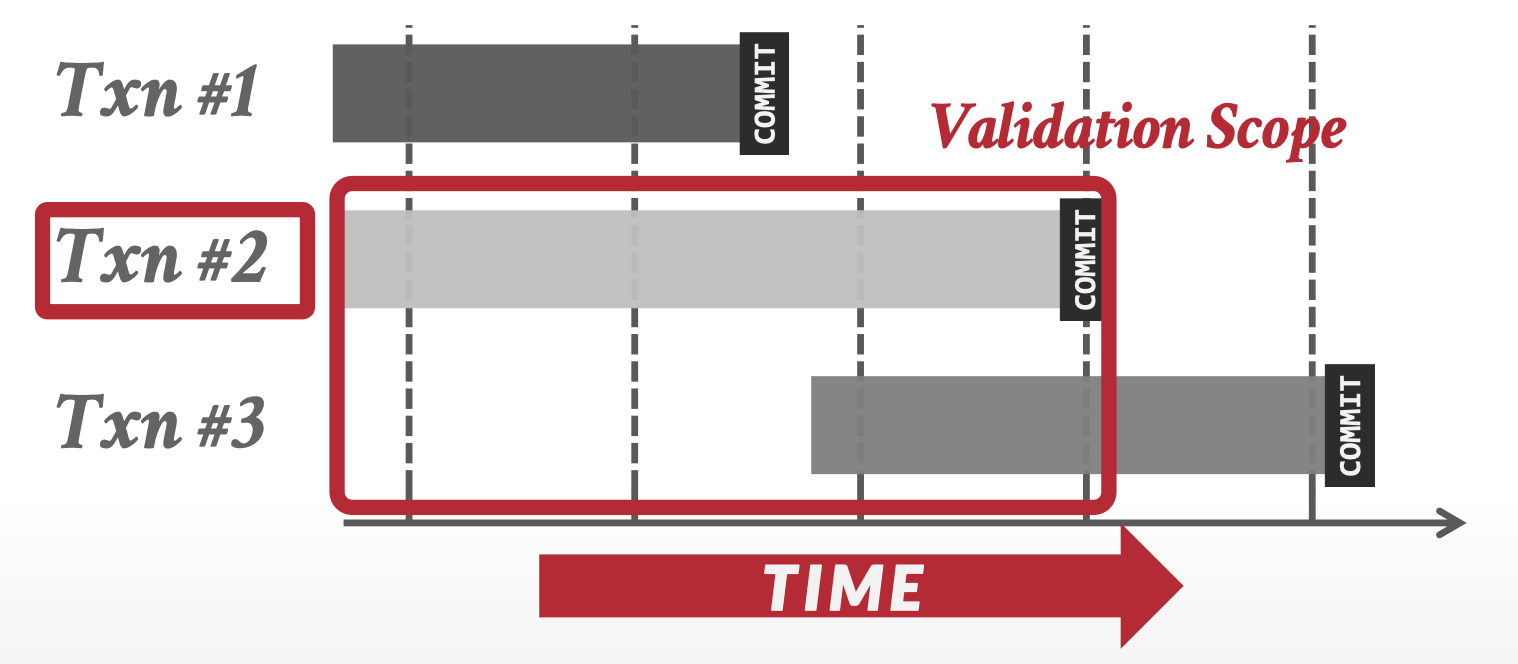
注:在验证阶段,我么都是与未提交的事务进行校验,称为前向校验(Forward Validation)。
当然也可以与已提交的事务进行校验,称为后向校验(Backward Validation)。

总结:
- SERIALIZABLE:OOC+幻读预防措施(如索引锁,见后文)。
- REPEATABLE READS:OOC。
处理幻读
主要采用索引锁(Index Lock)的方式。
在插入数据时,锁住索引见的间隙(Gap),从而阻止插入或删除。
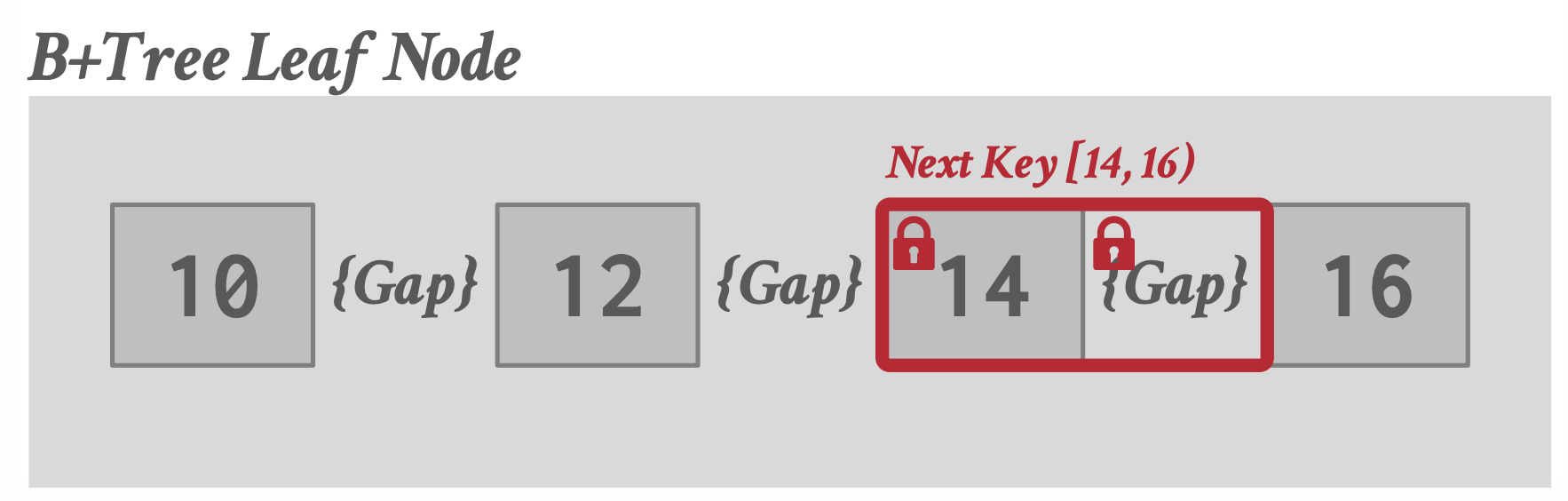
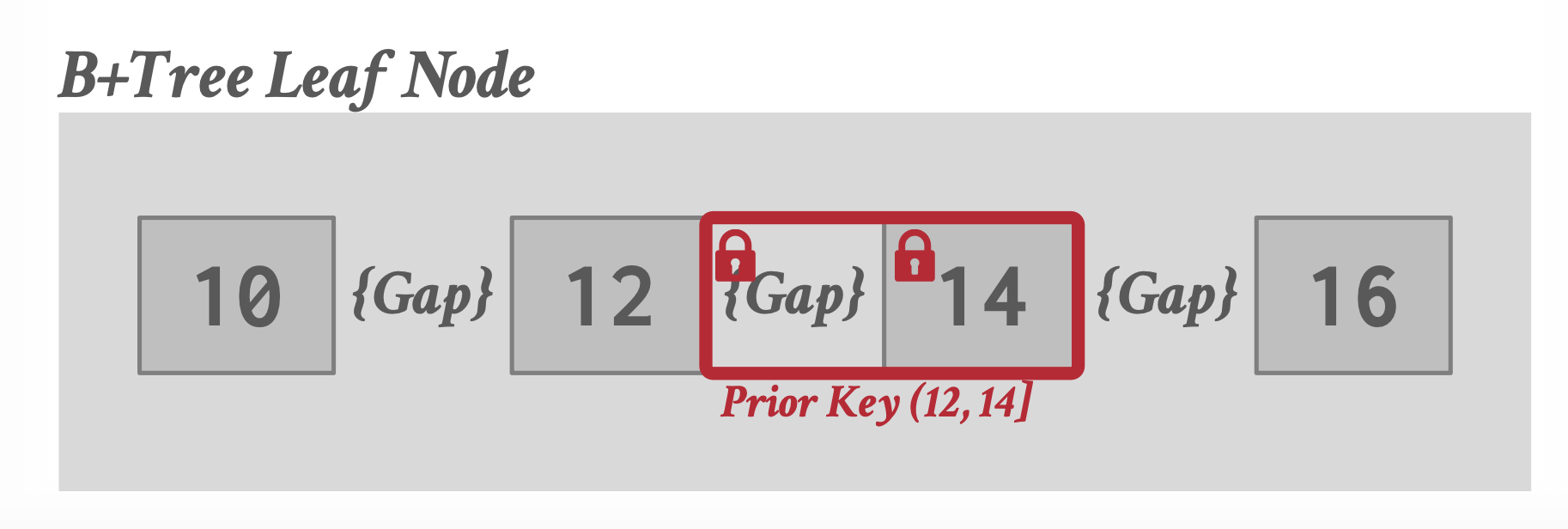
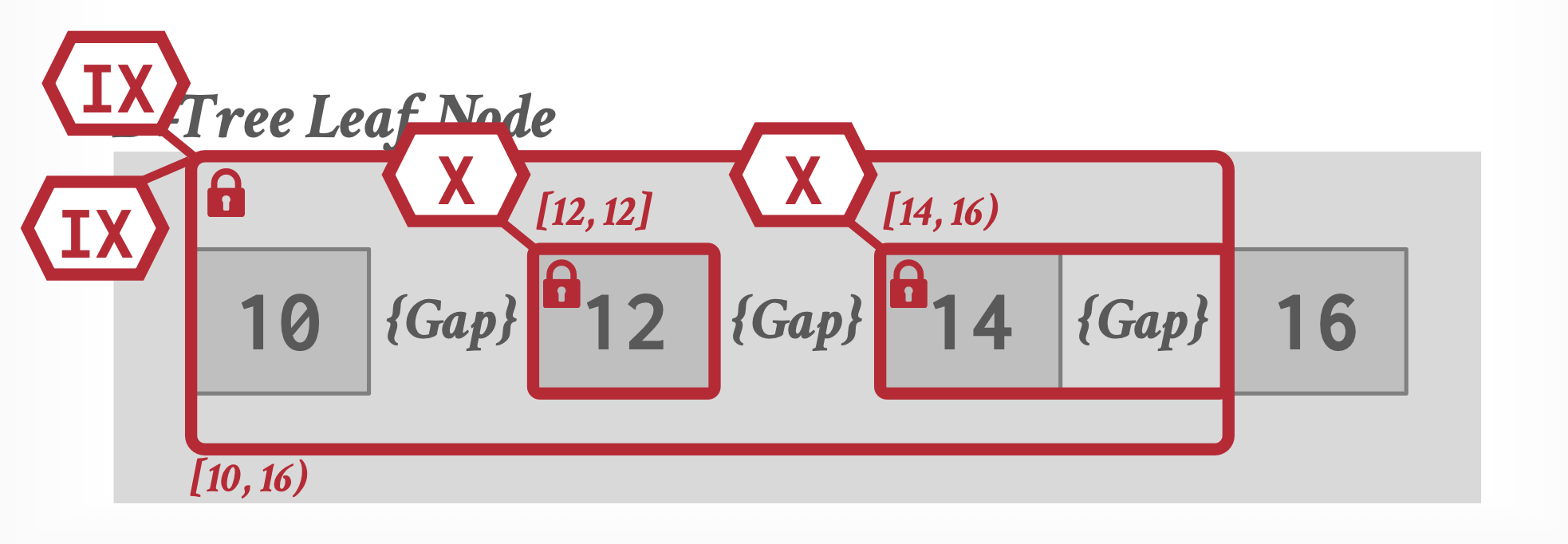
更进一步:给索引锁也加上意向锁这个层级。
MVC
原理
基本思想:事务通过元组(Tuple)的版本,判断可见性。
-
版本:解决我能看到谁
- 三元组
[begin-Txn, end-Txn, value] - 读操作:置
begin-Txn - 写操作:置新值
begin-Txn,旧值end-Txn
- 三元组
-
事务活动表:解决我能不能访问我看到的,必要时借助锁
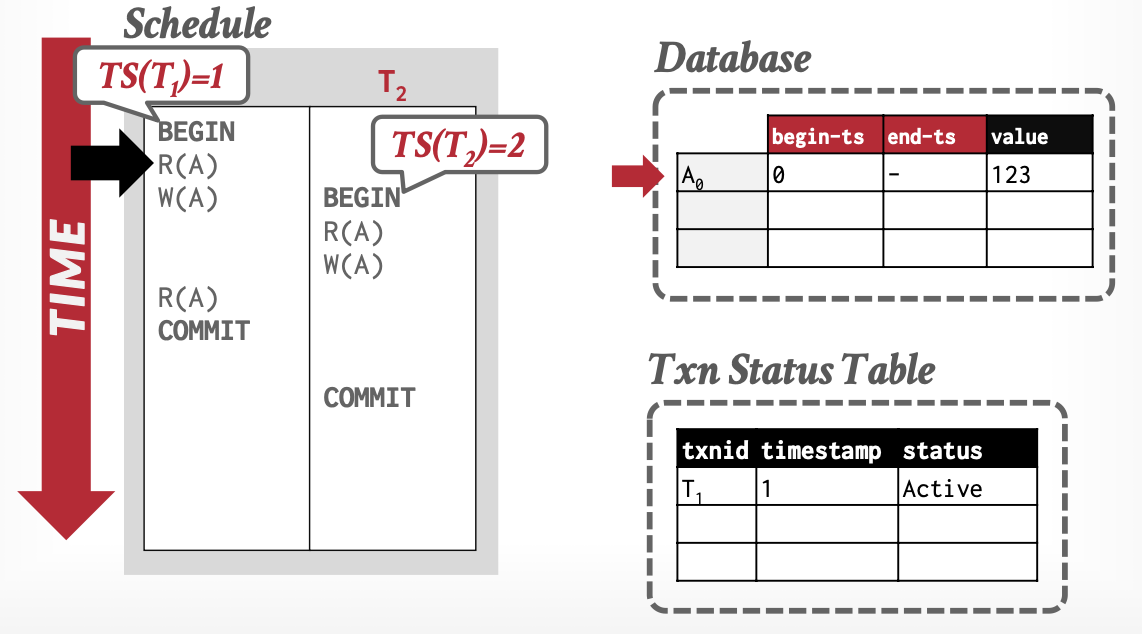
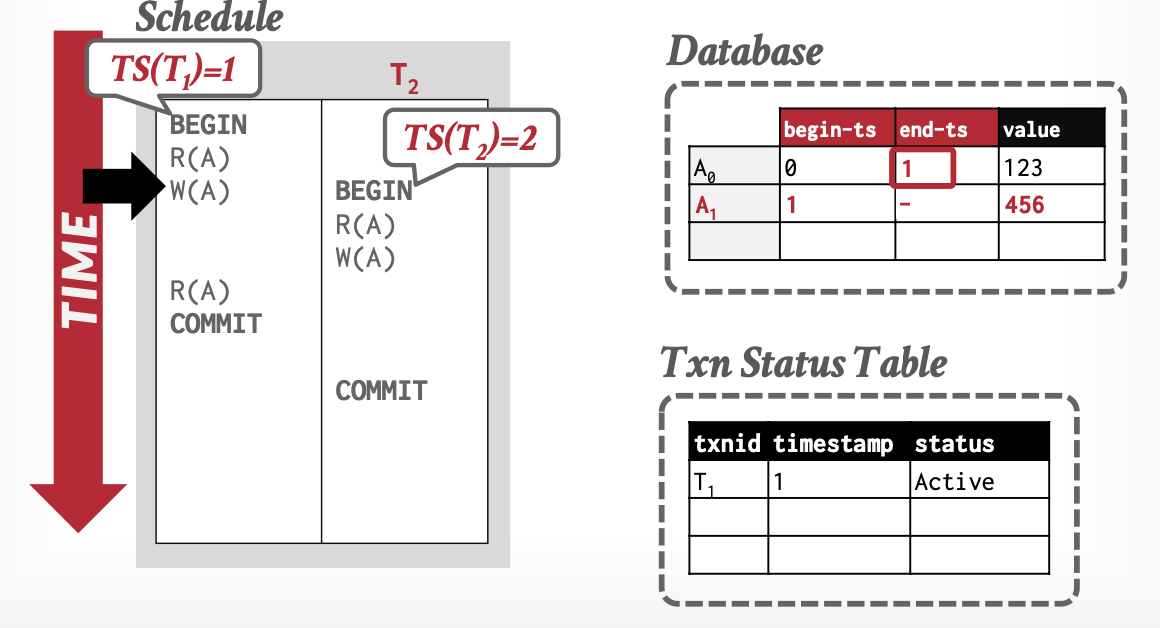
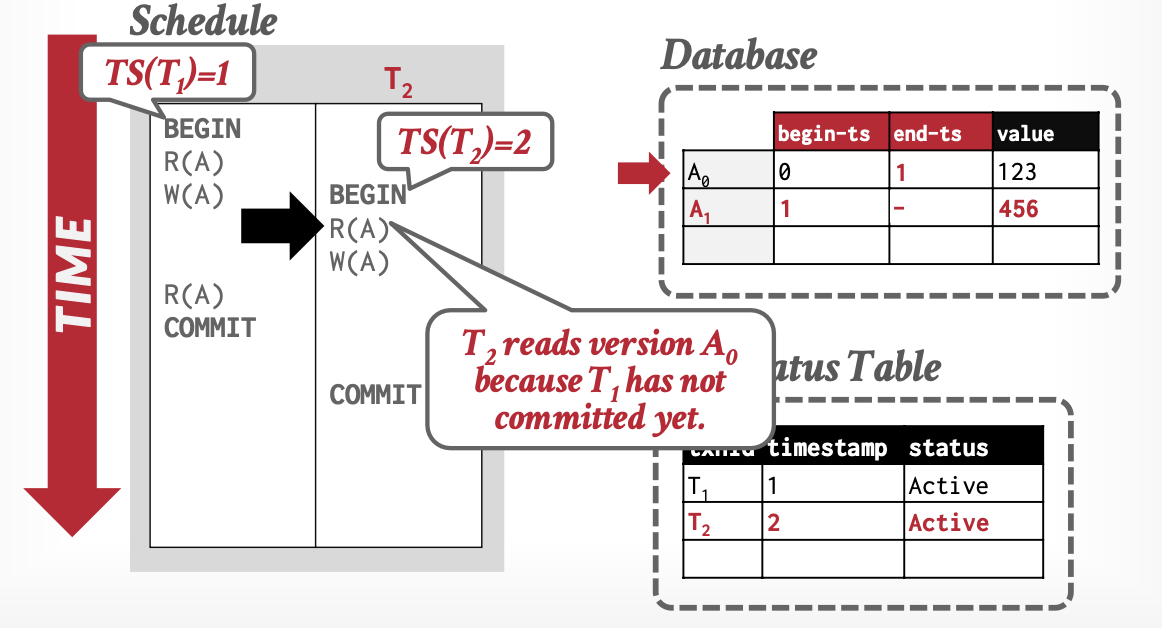
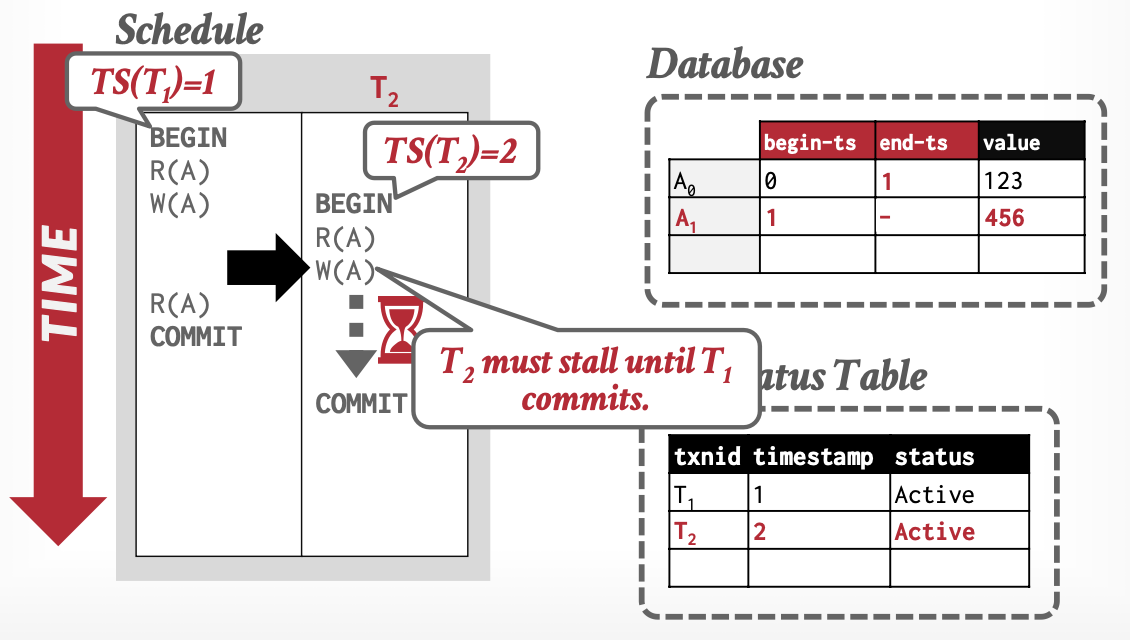
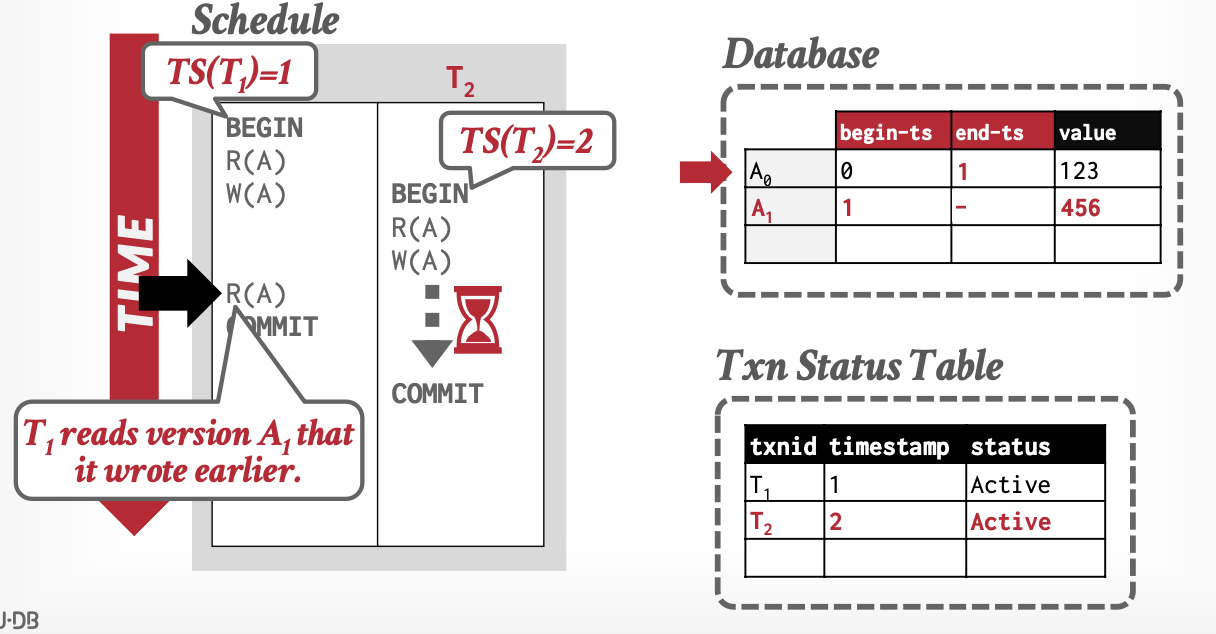
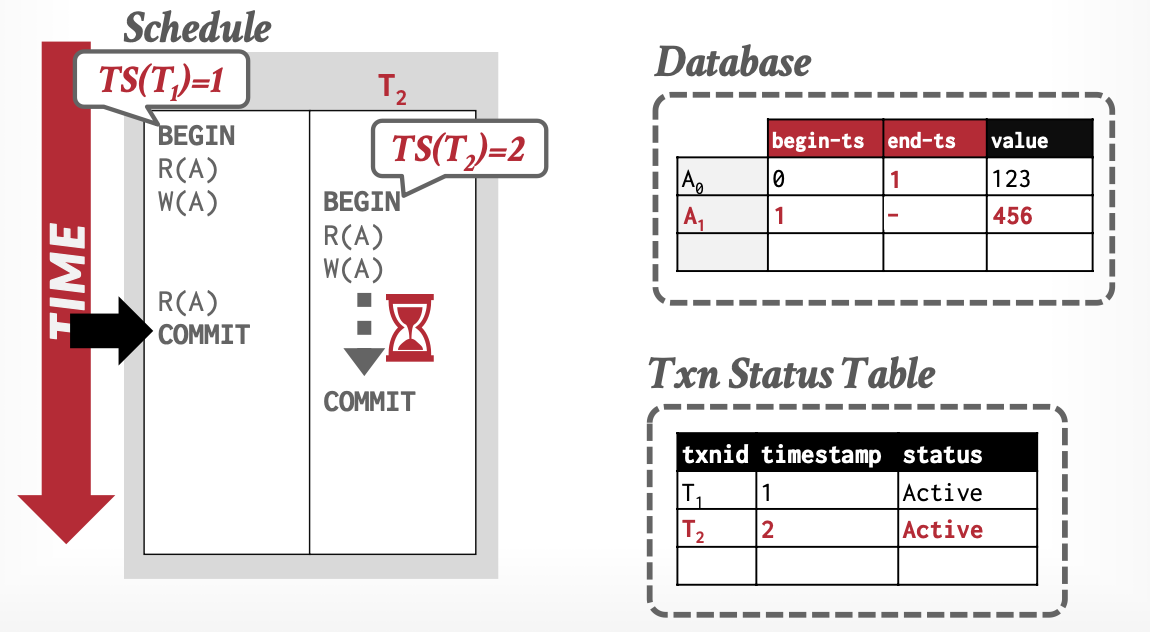
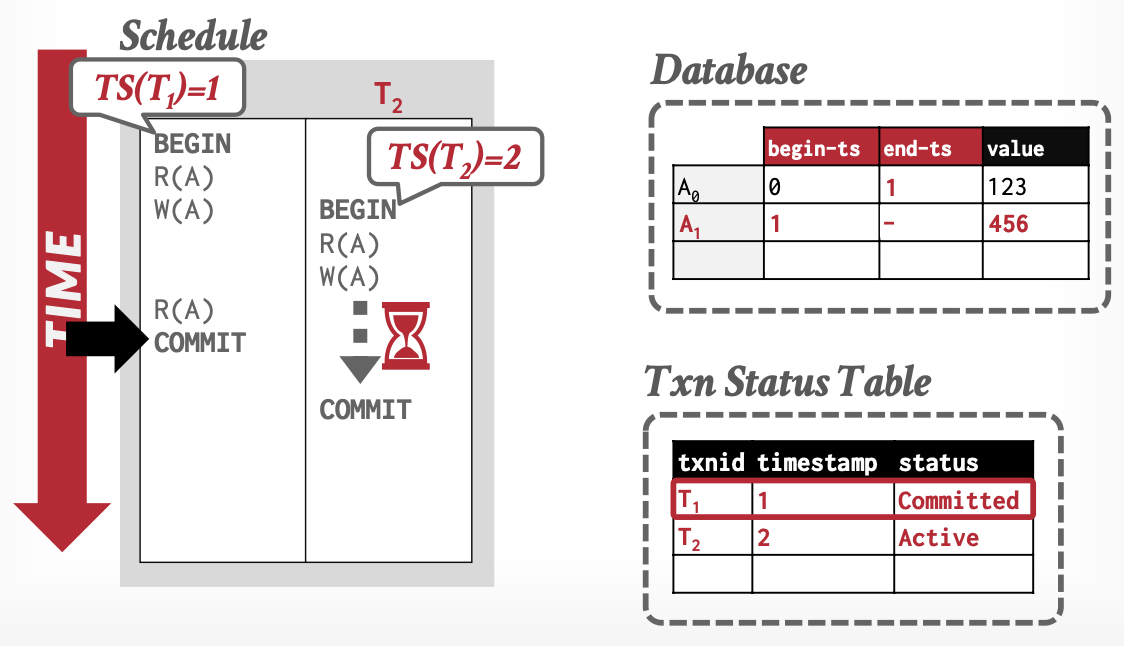
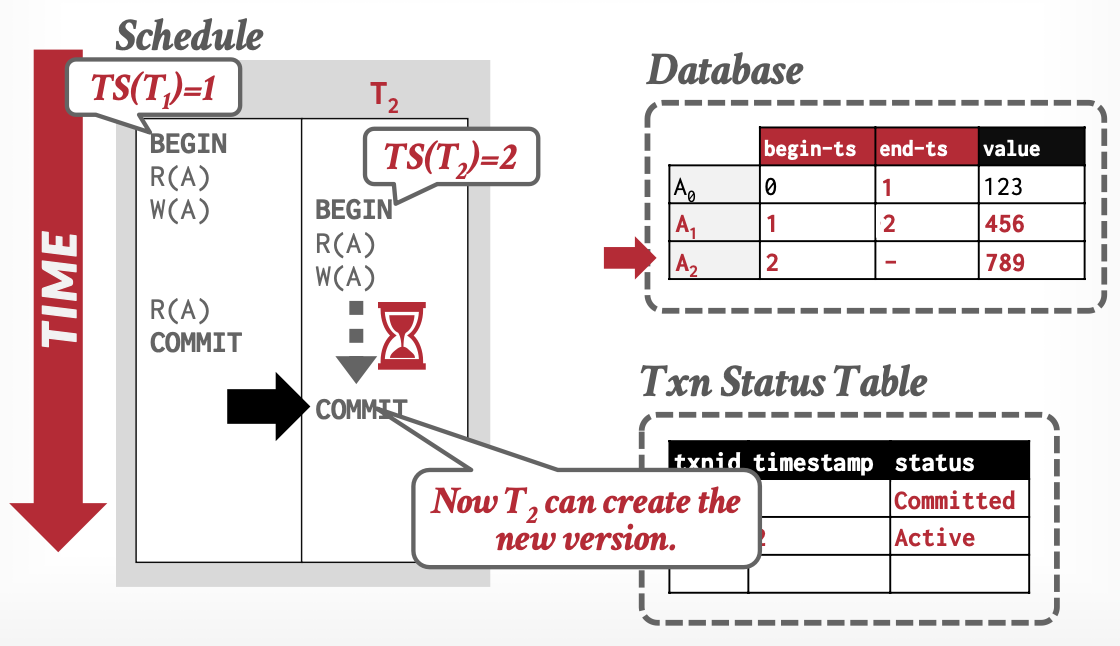
从上述例子中,可以看出MVCC解决了
-
脏读,不可重复读
-
更新丢失
-
幻读依然没有解决,需要结合索引锁等机制
写偏差异常(Write Skew Anomaly)
只检测直接的写冲突,无法捕获事务之间的隐式逻辑依赖,导致会违背全局约束。
假设有一个医院的医生值班系统,要求 任何时刻至少有一名医生值班。表 Shifts 记录了当前医生是否值班:
| DoctorID | OnDuty |
|---|---|
| 1 | Yes |
| 2 | Yes |
-
T1: 医生 1 决定取消自己的值班,读取当前值班情况,发现医生 2 仍在值班,于是提交一个事务将自己从值班中移除。
-
T2: 医生 2 决定取消自己的值班,读取当前值班情况,发现医生 1 仍在值班,于是提交一个事务将自己从值班中移除。
过程:
- T1 和 T2 基于同一个快照读取 Shifts 表,发现当前有另一名医生在值班(医生 2 和医生 1)。
- T1 和 T2 分别更新自己的记录,将 OnDuty 设置为 No。
- 两个事务没有直接修改相同的记录,因此快照隔离认为没有写冲突,允许它们同时提交。
- 提交后,Shifts 表中所有医生的 OnDuty 均为 No,违反了至少 2 名医生值班的约束。
版本存储(Version-storage)
元组的版本信息如何存储:
- Append only:新旧版本在同一张表空间
- Time travel storage:新旧版本分开
- Delta Storage:不存储实际值,而是存储增量delta
Append Only
每个逻辑元组的所有物理版本都存储在一个相同的表空间中。
不同逻辑元组的物理版本之间用链表串联。
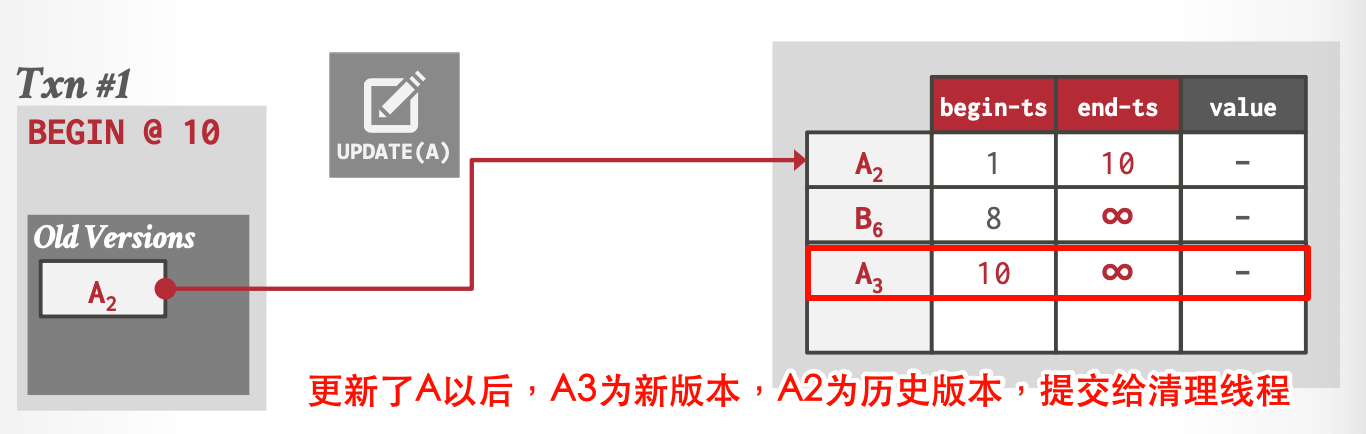
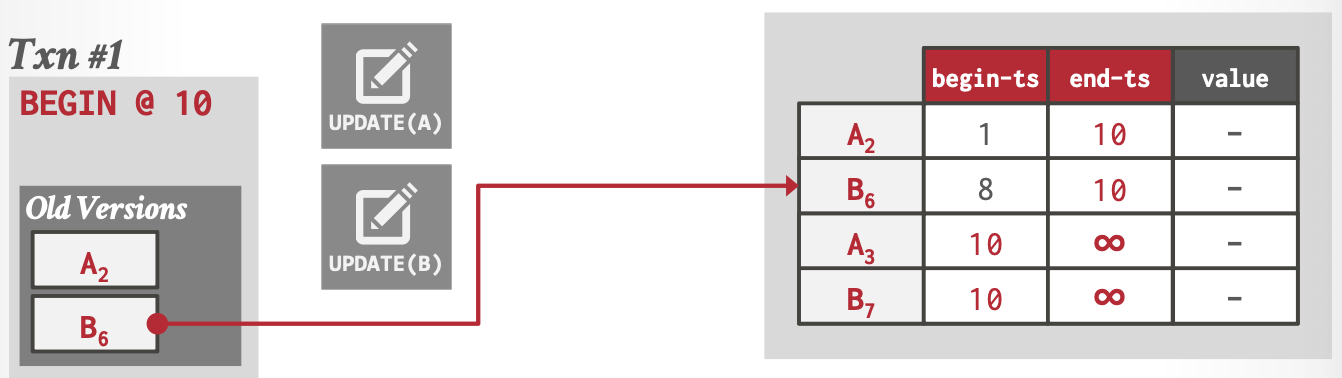
当更新时,添加一个新的物理版本到的表空间中,如下图所示(省略了begin_Txn和end_Txn)。
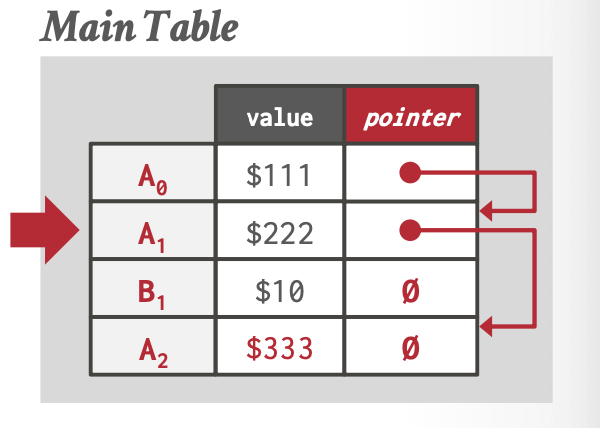
链表的串联顺序可以是由旧到新 Oldest-to-Newest (O2N) ,也可以是由新到旧 Newest-to-Oldest (N2O)。
Time Travel Storage
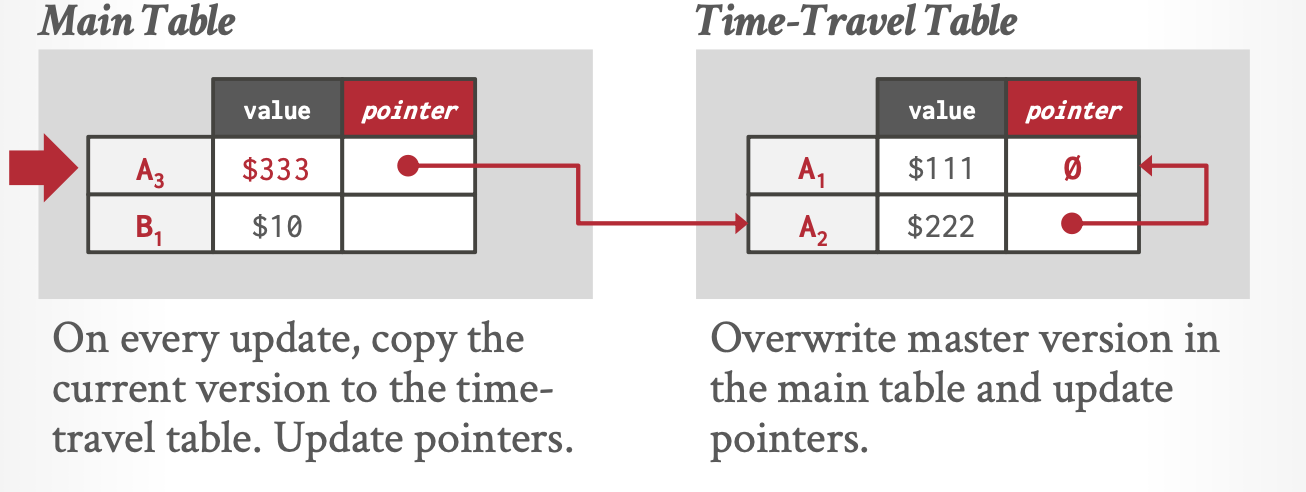
有一张主表和一张历史版本表,当更新的时候,把旧版本写入历史版本表中,然后新版本写到主表上。
比如写入\(A_3\)时,先写把\(A_2\)写到历史版本表,维护相应指针,然后把\(A_3\)写入主表。
Delta Storage
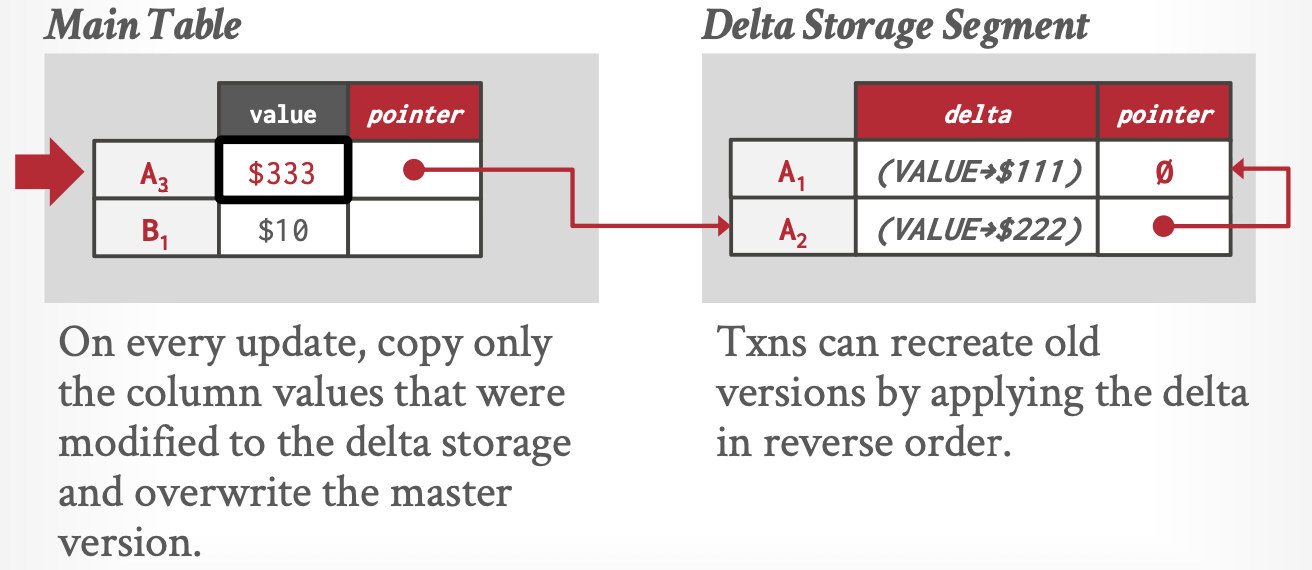
依然是有猪逼哦啊和历史版本表,但是历史版本表存储增量而不是实际值。
如 \(A_1=111 \rightarrow A_2 = 222 \rightarrow A_3 = 333\)的版本记录记录如下。
垃圾回收
事务的所有历史版本记录那都是存放在表空间中,久而久之就会不断堆积,所以对于没有用的版本记录,需要及时回收。
可回收的版本记录:
- 活跃事务都不可见的版本。
- 终止(abort)的事务的版本。
垃圾回收的目标:找到上述两类过期版本,并将它们安全地删除。
垃圾回收的两个层级:
- 元组层级(Tuple Level)
- 事务层级(Transaction Level)
Tuple Level
Background Vacuuming
后台清理线程集中化清理,适用于所有版本存储方式。
清理现场扫描历史版本表,将每个历史版本的begin_Txn和end_Txn与当前所有活跃的事务的id进行比较,判断是否可以清理。
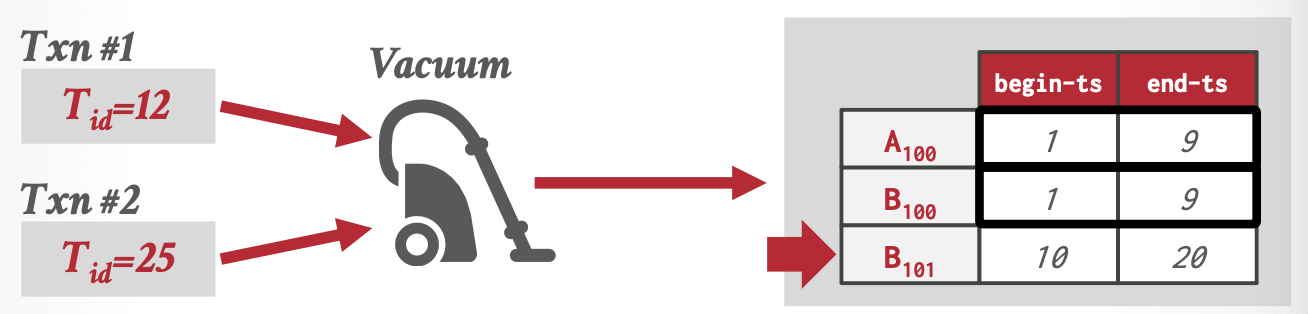
如上图,清除了\(A_{100}\)和\(B_{100}\)。
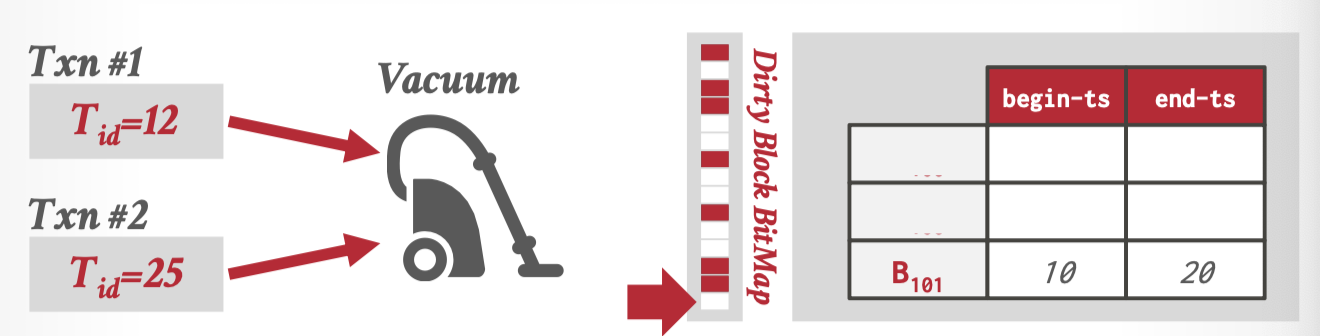
改进:添加脏页位图,快速跳转到代清理的版本。
Cooperative Cleaning
分布式清理,清理任务分摊到每个工作线程,适用于O2N。
全局维护一个事务id(Txn),表示当前活跃事务的最小id,当每个工作线程在自己的历史版本表中寻找自己的可见版本时,顺带清理掉那些全局不可见的版本。

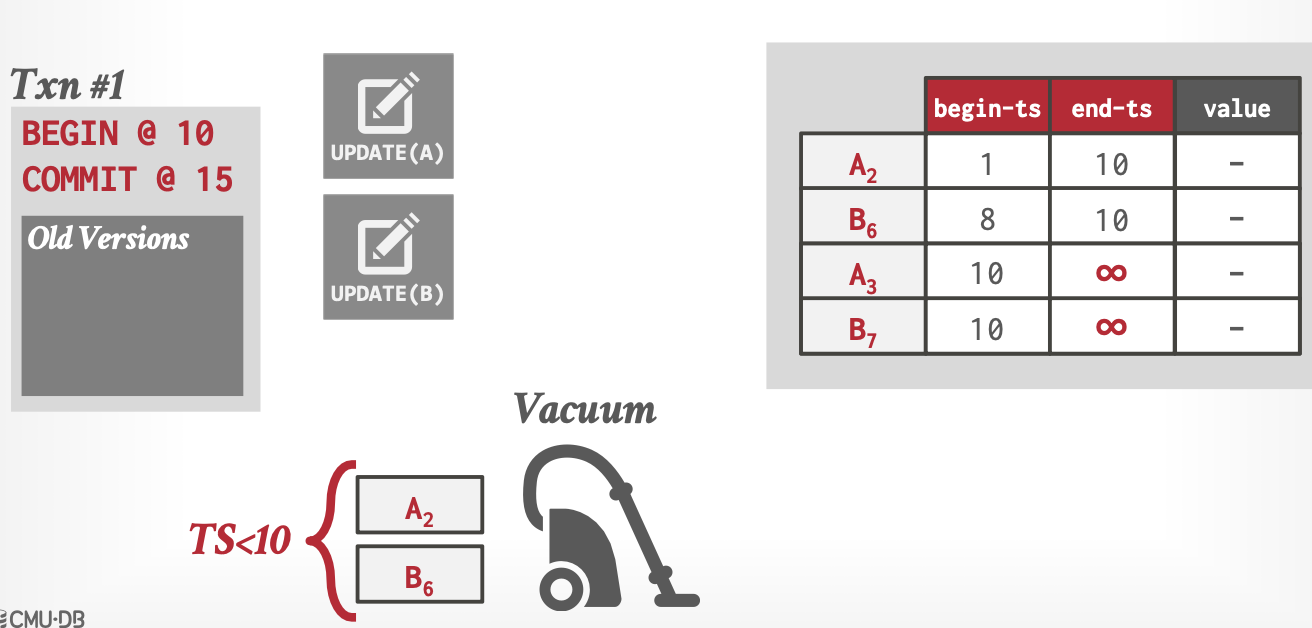
Transition Level
集中化清理,但是旧版本收集分摊到工作线程,适用于所有版本存储方式。
当事务创建了一个新版本后,将旧版本提交给中心清理线程,中心线程统一清理旧版本。
对比
| 属性 | Background Vacuuming | Cooperative Cleaning | Transition Level Vacuuming |
|---|---|---|---|
| 触发方式 | 后台任务自动触发 | 事务或查询过程中触发 | 根据事务需求动态触发 |
| 旧版本收集 | 清理线程 | 工作线程 | 工作线程 |
| 旧版本清理 | 清理线程 | 工作线程 | 清理线程 |
| 系统资源开销 | 占用额外资源 | 分散到用户操作中 | 智能调度,可能额外增加开销 |
| 适用场景 | 数据量大,需释放磁盘空间 | 实时查询环境 | 隔离级别需求高的环境 |
| 优缺点平衡 | 减少用户影响但有清理滞后风险 | 实时性好但增加用户操作开销 | 智能性高但复杂度和判断开销增加 |
索引管理
二级索引维护方式
- 逻辑指针(Logical Pointers):二级索引使用每个元组的固定标识符(例如主键)来指向数据。间接访问,需要回表。
- 物理指针(Physical Pointers):直接使用物理地址指向版本链的头部。直接访问,无需回表,但是维护困难。
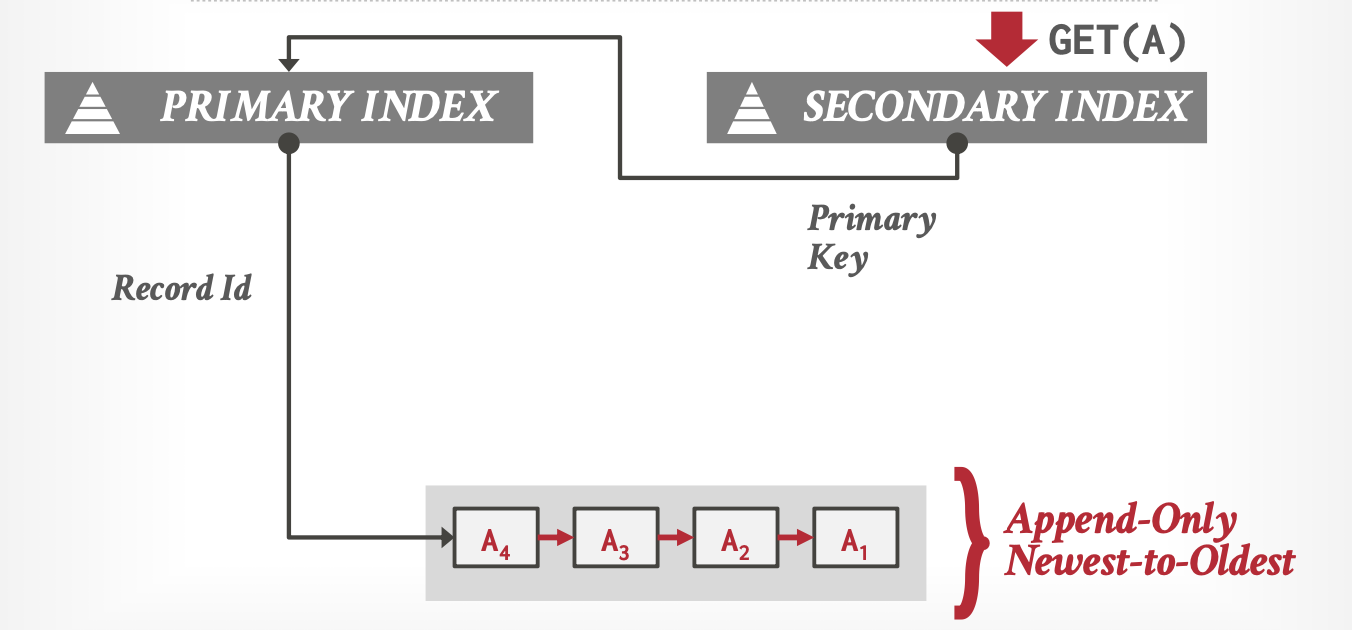
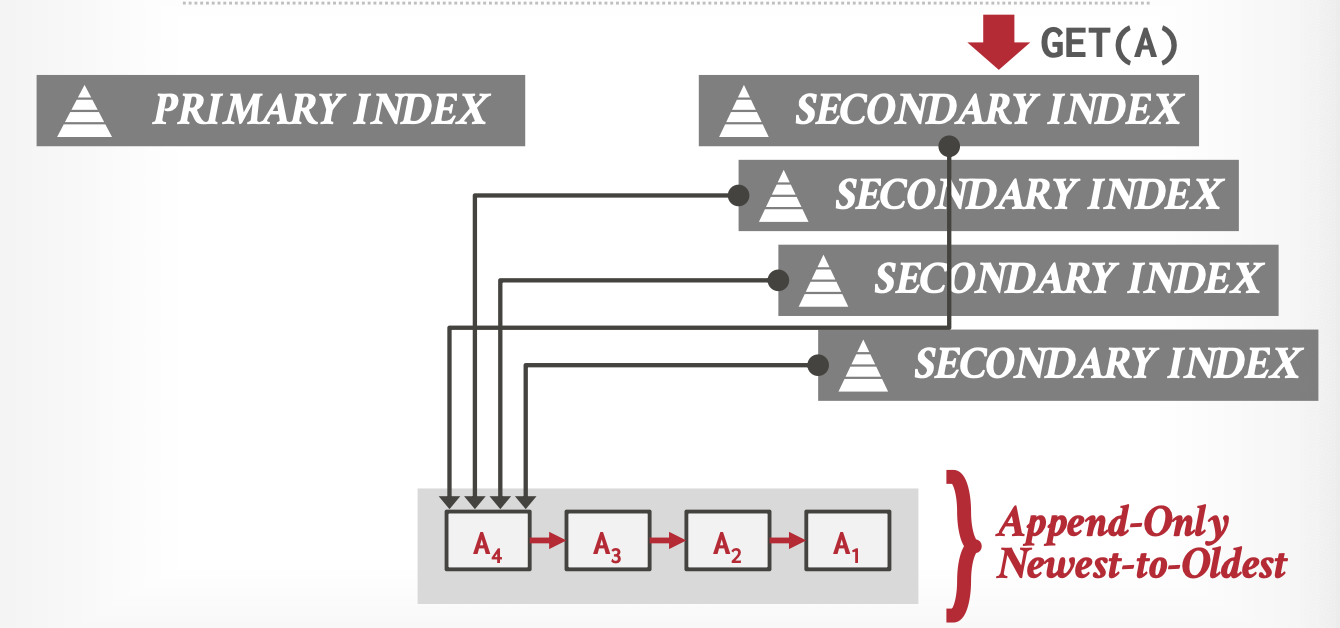
索引重复值问题(Duplicate Key Problem):
MVCC中不同时间的事务会看到元组的不同版本,所以一个元组会有不同的索引,指向不同的物理版本。
如下图,begin_Txn < 30的事务看到的是A已删除,而begin_Txn >= 30的事务看到的是A=30。
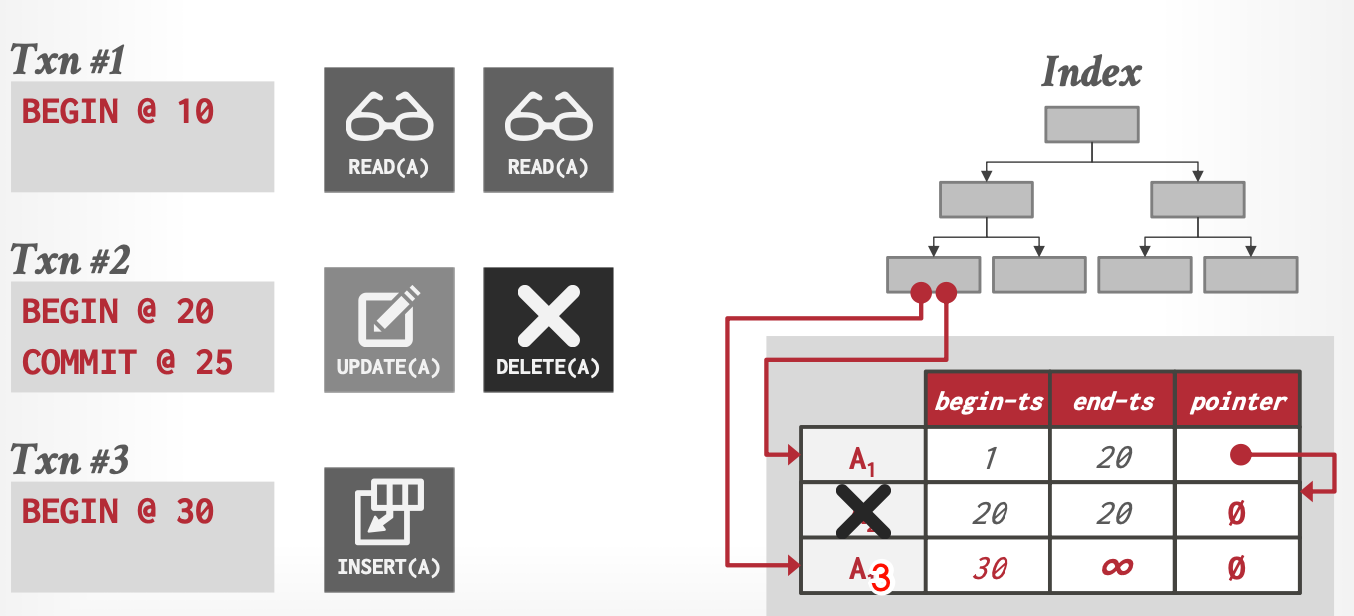
删除
如何表示一个版本被删除。
- 版本上添加一个标识位,标识已删除
- 新建一个空版本标识已删除,

各个数据库的实现方式
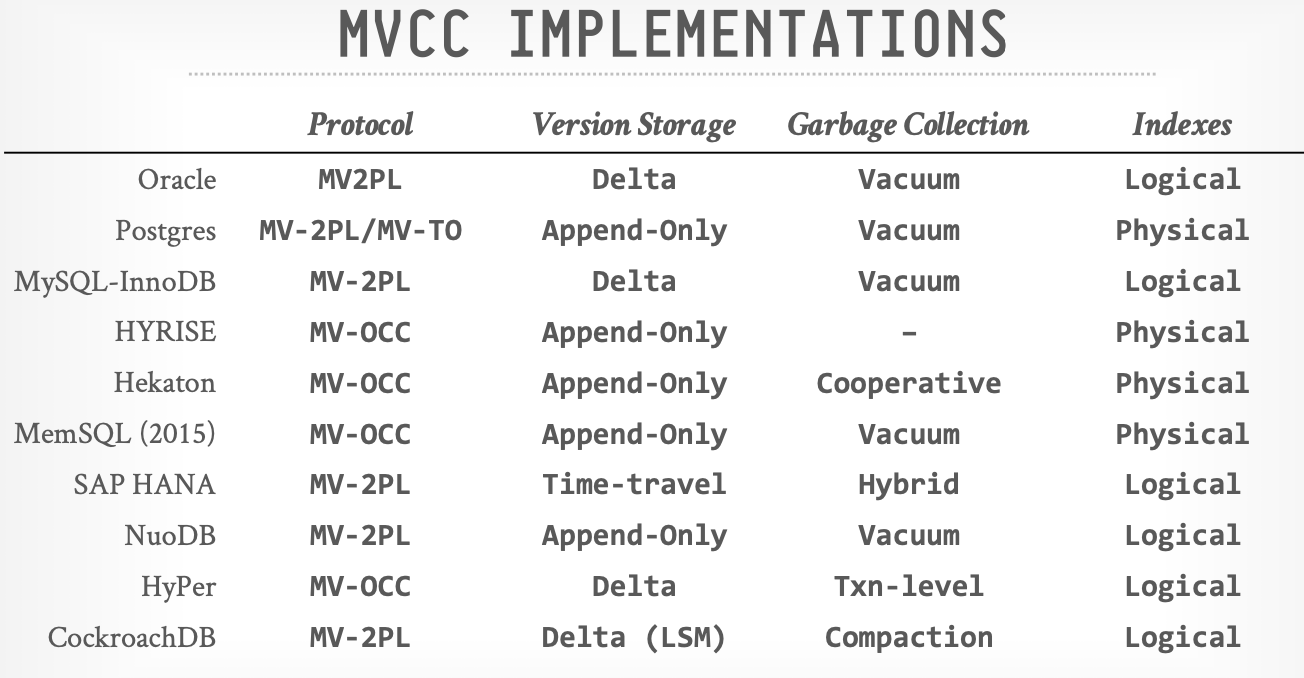
Index Management
- Secondary Indexes
- Logical Pointers
- Physical Pointers
- Multiple key Problem(GC)
总结
2PL,OOC,MVCC都是实现事务ACID的方式。
2PL运用锁来控制并发,比较底层;OOC先执行,后利用时间戳检测,适合冲突少的情况;MVCC利用版本控制,除了可以控制并发正确性,还能进行版本回溯,是当前的主流方式。
强二阶段锁,OOC和MVCC都能避免脏读,不可重复读和更新丢失,但是无法避免幻读,需要额外利用其他机制,如索引锁。
MVCC会有写偏差异常*(Write Skew Anomaly)*,无法实现完全到串行化的隔离级别,往往和其他并发控制机制如2PL,OOC结合使用。