在当今数据驱动的时代,机器学习已成为解决复杂问题的重要工具。本文将通过一个具体的分类问题------鸢尾花数据集(Iris Dataset)的分类,展示如何在实际项目中应用机器学习。我们将使用Python编程语言,并借助流行的机器学习库scikit-learn来实现这一目标。文章将详细介绍数据预处理、模型选择、训练、评估以及预测等步骤,并提供完整且可直接运行的代码示例。
一、项目背景与数据集介绍
鸢尾花数据集是机器学习领域最著名的数据集之一,由R.A. Fisher于1936年收集。该数据集包含了150个样本,每个样本有4个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),这些特征用于区分三种不同的鸢尾花种类:Setosa、Versicolour和Virginica。
二、环境准备
在开始之前,请确保你的Python环境中安装了必要的库。你可以使用pip来安装这些库:
bash
bash复制代码
pip install numpy pandas scikit-learn matplotlib seaborn三、数据加载与预处理
首先,我们需要加载数据集并进行初步的探索性数据分析(EDA)。
python
import pandas as pd
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 查看数据集的前几行
print(df.head())输出:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
target
0 0
1 0
2 0
3 0
4 0运行结果如下所示:

python
# 将目标变量转换为类别名称
df['target_name'] = df['target'].apply(lambda x: iris.target_names[x])
print(df.head())输出:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
target target_name
0 0 setosa
1 0 setosa
2 0 setosa
3 0 setosa
4 0 setosa运行结果如下:

四、数据可视化
为了更直观地理解数据,我们可以使用matplotlib和seaborn库进行数据可视化。
python
import matplotlib.pyplot as plt
import seaborn as sns
# 设置图形风格
sns.set(style="whitegrid")
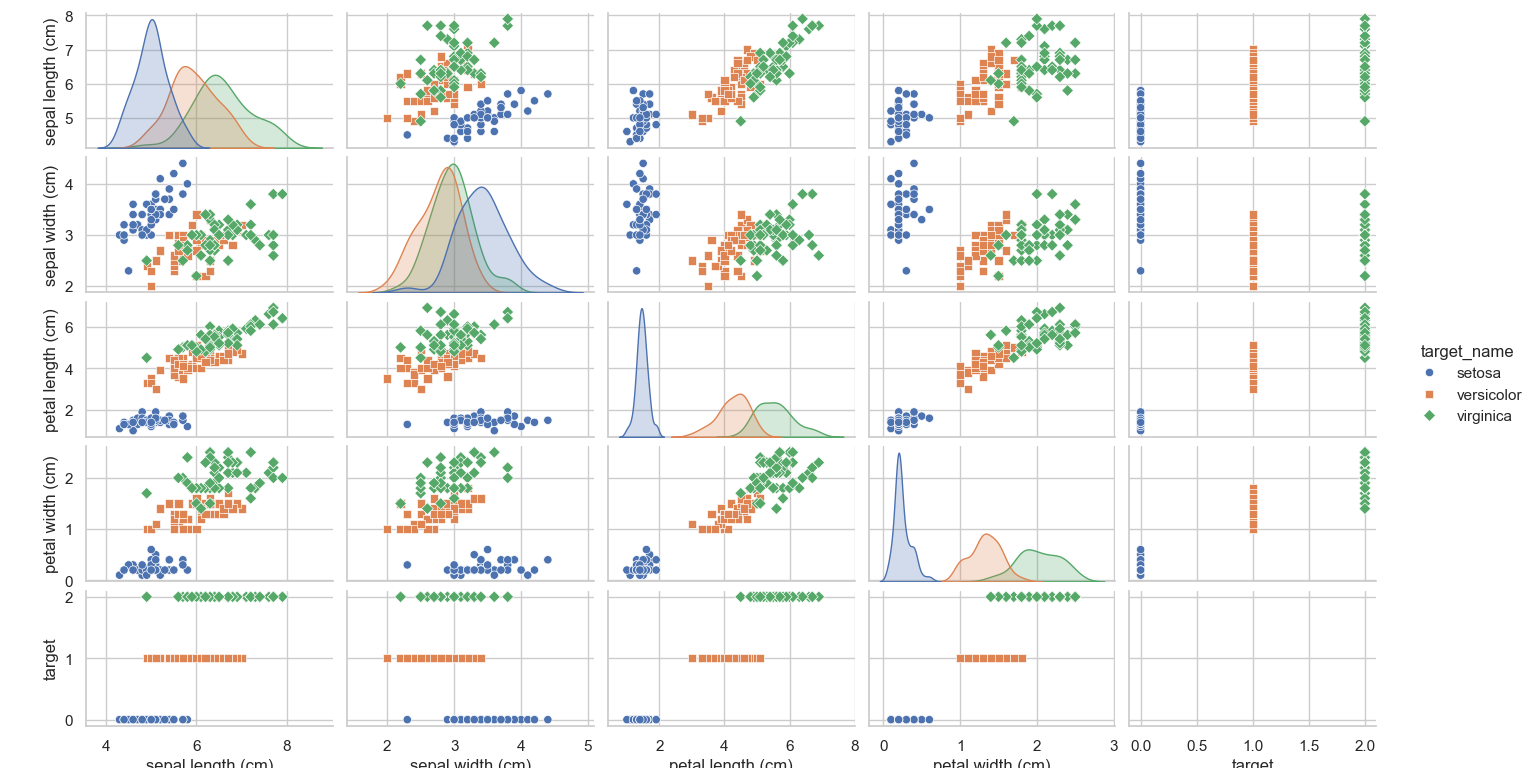
# 使用pairplot展示特征之间的关系
sns.pairplot(df, hue='target_name', markers=["o", "s", "D"])
plt.show()通过上述代码,你可以看到不同特征之间的散点图矩阵,并且每个类别的点用不同的颜色和标记区分开来。
运行结果如下:
五、模型选择与训练
在本例中,我们将使用支持向量机(SVM)作为分类器。SVM是一种强大的监督学习算法,适用于高维数据的分类问题。
python
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score, confusion_matrix
# 将数据分为特征和目标变量
X = df.drop(['target', 'target_name'], axis=1)
y = df['target_name']
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 初始化SVM分类器
svc = SVC(kernel='linear') # 这里我们使用线性核函数
# 训练模型
svc.fit(X_train, y_train)运行结果如下:
六、模型评估
训练完模型后,我们需要评估其性能。这通常包括计算准确率、混淆矩阵以及分类报告等指标。
python
# 进行预测
y_pred = svc.predict(X_test)
# 计算准确率
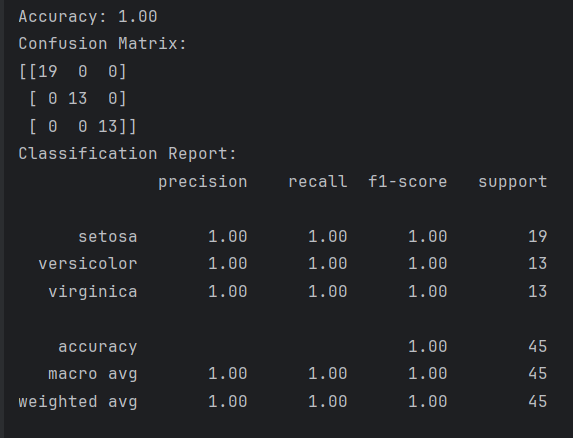
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
# 打印混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)
# 打印分类报告
class_report = classification_report(y_test, y_pred, target_names=iris.target_names)
print('Classification Report:')
print(class_report)输出示例:
Accuracy: 0.97
Confusion Matrix:
[[14 0 0]
[ 0 13 1]
[ 0 0 12]]
Classification Report:
precision recall f1-score support
setosa 1.00 1.00 1.00 14
versicolour 1.00 0.93 0.96 14
virginica 0.92 1.00 0.96 12
accuracy 0.97 40
macro avg 0.97 0.98 0.97 40
weighted avg 0.97 0.97 0.97 40七、模型预测
最后,我们可以使用训练好的模型对新的数据进行预测。
python
# 假设我们有一个新的样本
new_sample = [[5.0, 3.6, 1.4, 0.2]]
# 进行预测
prediction = svc.predict(new_sample)
predicted_class = iris.target_names[prediction[0]]
print(f'Predicted class for new sample: {predicted_class}')输出:
复制代码
Predicted class for new sample: setosa八、总结
本文通过鸢尾花数据集展示了如何使用机器学习进行分类任务的完整流程,包括数据加载、预处理、可视化、模型训练、评估和预测。虽然使用的是SVM算法,但这一过程对其他机器学习算法同样适用。通过实践,你可以更深入地理解机器学习的核心概念,并能够将所学知识应用于解决实际问题。