1. 多指令流单数据流
多指令流单数据流(Multiple Instruction Stream, Single Data Stream,简称 MISD)是一种处理器设计概念,它允许处理器在单个时钟周期内从不同的程序流中发射多条指令。这种设计旨在提高处理器的指令级并行性(Instruction-Level Parallelism, ILP),从而提升性能。下面是多指令流单数据流的一些关键特点:
-
指令级并行性:MISD 处理器能够识别并行执行来自不同程序流的指令,这些指令流可以是独立的,不会相互干扰。
-
指令窗口:处理器维护一个较大的指令窗口,用于存储和管理来自不同指令流的指令。
-
执行单元:MISD 处理器包含多个执行单元,可以同时处理多条指令,这些执行单元可以是专用的,也可以是通用的。
-
调度器:MISD 处理器需要一个复杂的调度器来管理来自不同指令流的指令,确保指令执行的顺序和数据依赖性得到正确处理。
-
分支预测:MISD 处理器通常配备先进的分支预测机制,以减少分支指令对性能的影响。
-
寄存器重命名:为了处理多个指令流,ISD 处理器使用寄存器重命名技术来避免不同指令流之间的寄存器冲突。
-
内存访问:ISD 处理器可能会对内存访问进行优化,以支持同时从不同的指令流中加载和存储数据。
-
应用场景:MISD 设计可以用于高性能计算场景,如科学计算、图形处理和人工智能,这些场景可以从指令级并行中获益。
-
挑战:MISD 处理器面临的挑战包括增加的硬件复杂性、功耗和设计难度。此外,软件编译器需要能够识别和利用指令流之间的并行性。
多指令流单数据流处理器的设计目标是提高指令吞吐量,即单位时间内处理器可以执行的指令数量。这种设计可以提高处理器的峰值性能,但同时也需要复杂的硬件支持和优化的编译器来充分利用其潜力。
它和多指令流多数据流的区别?
多指令流单数据流(Multiple Instruction Stream, Single Data Stream,MISD)和多指令流多数据流(Multiple Instruction Stream, Multiple Data Stream,MIMDS)是两种不同的处理器设计概念,它们在指令和数据流的处理方式上有所区别:
-
指令流:
- MISD:处理器可以同时从多个指令流中获取指令,但这些指令流是独立的,不会相互干扰。这意味着处理器可以同时处理来自不同程序或同一程序不同部分的指令。
- MIMD:处理器同样可以同时从多个指令流中获取指令,但这些指令流之间可能存在数据依赖关系,需要更复杂的协调和调度。
-
数据流:
- MISD:尽管处理器可以处理来自多个指令流的指令,但它只有一个数据流,这意味着所有指令流共享相同的数据路径和执行单元。
- MIMD:处理器有多个数据流,允许同时处理多个数据流,这可以进一步提高并行度,因为不同的数据流可以独立地执行。
-
执行单元:
- MISD:可能需要较少的执行单元,因为数据流是单一共用的,执行单元可以被多个指令流共享。
- MIMD:可能需要更多的执行单元,以支持多个数据流的并行处理。
-
调度器复杂性:
- MISD:调度器需要处理来自不同指令流的指令,但数据流的调度相对简单。
- MIMD:调度器必须处理来自多个指令流的指令以及多个数据流的数据,这增加了调度的复杂性。
-
硬件复杂性:
- MISD:硬件设计相对简单,因为数据路径和执行单元是共享的。
- MIMD:硬件设计更复杂,需要更多的资源来支持多个数据流。
-
性能潜力:
- MISD:可以提高指令吞吐量,但可能受限于单个数据流的带宽。
- MIMD:可以提供更高的性能潜力,因为它可以同时处理更多的数据。
-
应用场景:
- MISD:适用于需要高指令吞吐量但数据流依赖性较低的场景。
- MIMD:适用于需要高并行度和高数据吞吐量的场景,如高性能计算和图形处理。
-
编译器支持:
- MISD:编译器需要能够识别和优化来自不同指令流的指令。
- MIMD:编译器需要能够处理更复杂的数据流依赖和指令调度。
总的来说,MIMDS 设计提供了更高的并行度和性能潜力,但同时也带来了更高的硬件复杂性和设计挑战。MISD 设计则在保持一定程度的并行度的同时,简化了硬件设计和调度器的复杂性。
指令流
在计算机体系结构和编程领域,"指令流"(Instruction Stream)指的是在程序执行过程中,指令按照特定顺序排列的序列。以下是对指令流的详细解释:
-
指令序列:指令流是由一系列指令组成的序列,这些指令按照程序的逻辑顺序执行。每条指令都包含操作码(Opcode),它指定要执行的操作,以及操作数(Operands),它们是操作的输入。
-
程序执行:在程序执行过程中,处理器从内存中获取指令,解码指令流中的指令,并按照指令的操作码执行相应的操作。
-
控制流:指令流中的指令通常包含控制流指令,如分支(Branch)和跳转(Jump),它们改变指令流的执行顺序。
-
流水线:现代处理器使用流水线技术来提高指令流的执行效率。在流水线中,指令流被分解为多个阶段,允许多个指令同时处于不同的执行阶段。
-
指令级并行(ILP):指令级并行是指处理器能够同时发射、执行和完成多条指令的能力。这是通过分析指令流中的指令依赖关系来实现的,允许处理器在不违反程序顺序的情况下执行指令。
-
指令缓存:为了提高指令流的获取速度,处理器通常使用指令缓存(Instruction Cache)来存储最近或频繁使用的指令。
-
指令调度:处理器中的调度器负责管理指令流,决定哪些指令可以并行执行,以及处理数据依赖和控制依赖。
-
指令集架构(ISA):指令流是基于特定的指令集架构的,它定义了处理器能够理解和执行的指令类型。
指令流是处理器执行程序的基础,它直接影响程序的性能和效率。通过优化指令流的处理,如分支预测、指令级并行和流水线技术,可以显著提高程序的执行速度。
为什么要提高存储器的带宽?带宽是什么,会影响什么?
存储器带宽(Memory Bandwidth)是衡量存储器性能的一个重要指标,它指的是单位时间内存储器能够传输数据的最大量。带宽通常以字节每秒(Bytes per second, Bps)或位每秒(bits per second, bps)来表示。存储器带宽的大小直接影响到计算机系统的性能和响应速度,高带宽意味着系统能够更快地进行数据读写操作,从而提升整体性能。
提高存储器带宽的原因主要包括:
-
提升性能:增加带宽可以显著提升数据处理能力和运算密集型任务的执行效率。
-
满足需求:随着应用程序和数据处理需求的增长,对存储器带宽的要求也随之提高。
-
减少瓶颈:存储器带宽是计算机系统中的一个潜在瓶颈,提高带宽可以减少因存储器速度不足导致的性能瓶颈。
-
适应技术进步:随着新技术的发展,如DDR5、GDDR6等新一代内存技术,对带宽的要求也在增加。
-
优化系统设计:在系统设计阶段,考虑到未来可能的性能需求,预先设计较高的带宽可以提供更好的扩展性和适应性。
影响存储器带宽的因素包括:
- 总线频率:内存的工作频率,即内存时钟频率,与带宽成正比。
- 数据位宽:内存数据总线的宽度,即每次传输可以处理的数据位数。
- 存储体数量:在多体并行系统中,增加存储体可以提高带宽。
- 存储器架构:如低位交叉存储器设计,可以提高存储器的数据传输速率。
提高存储器带宽的方法可以采取以下措施:
-
缩短存取周期:减少存储器完成一次读写操作所需的时间。
-
增加存储字长:使每个存取周期可读/写更多的二进制位数。
-
增加存储体:在多体并行系统中,增加存储体可以提高带宽。
-
优化内存频率和通道配置:提高内存的工作频率和优化通道配置可以增加带宽。
-
数据传输优化:通过数据压缩与解压缩的优化策略,可以提高数据传输效率。
-
使用高速存储器:采用更高速的存储器,如NVMe、3D XPoint等。
-
合理设置内存通道及总线宽度:增加内存通道数量和总线宽度可以提升带宽。
通过这些方法,可以显著提升存储器的数据处理能力,满足现代计算机系统对高速数据传输的需求。
2. 分析下图
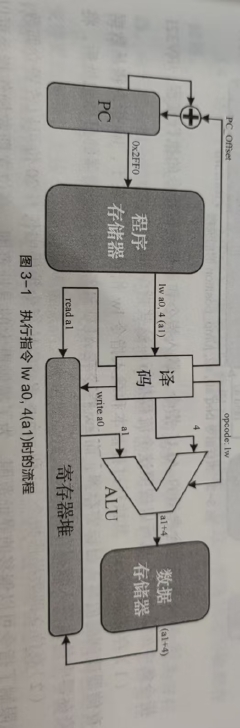
这两张图片展示了一个简化的计算机系统模型,包括程序计数器(PC)、算术逻辑单元(ALU)、存储器以及指令执行的流程。下面是对每张图片内容的分析:
第一张图片:程序计数器(PC)和存储器的关系
-
程序计数器(PC) :这是处理器中的一个寄存器,用于存储下一条将要执行的指令的地址。在这张图中,PC 指向存储器中的一个特定地址
0x2FF0。 -
PC_Offset:这可能表示程序计数器的偏移量,用于计算下一条指令的地址。在这个例子中,偏移量可能是指令长度或者是基于当前指令的特定偏移。
-
存储器:存储器用于存储程序指令和数据。图中显示了程序指令存储在存储器中。
-
执行指令 :图中显示了一个指令
read a1正在被执行。这可能意味着从地址a1读取数据。
第二张图片:指令执行流程
-
指令解码 :指令首先被解码,以确定其操作码(opcode),这里是
lw,代表加载字(load word)指令。 -
寄存器堆 :指令中的寄存器部分(如
a0)被写入或读取。在这个例子中,a0被写入。 -
ALU(算术逻辑单元) :ALU 执行算术或逻辑操作。在这个流程中,ALU 计算
a1 + 4,这可能是为了计算数据的内存地址。 -
存储器 :ALU 的结果(
a1 + 4)被用来从存储器中读取数据。这里,数据从存储器的地址a1 + 4被加载。 -
数据和存储器:显示了数据如何从存储器中被加载到寄存器堆。
这两张图片共同描述了一个典型的指令执行周期,包括指令的获取、解码、执行以及结果的存储。这种模型是理解计算机体系结构中指令如何被处理和执行的基础。
3. 流水线冲突与K级单发射理想流水线
在计算机体系结构中,流水线(Pipelining)是一种提高处理器性能的技术,它允许多个指令在不同的阶段并行执行。流水线中的"冲突"(Hazard)是指在指令执行过程中由于资源竞争或数据依赖而产生的延迟或阻塞。而"K级单发射"(K-out-of-N)是指在流水线中每个时钟周期可以发射的指令数量。
-
流水线冲突:
- 数据冲突:当多条指令需要访问同一数据或寄存器时,可能会发生冲突。例如,如果一条指令正在写入数据,而另一条指令需要读取相同的数据,这就需要解决数据冲突。
- 控制冲突:分支指令可能会改变程序的执行流程,导致后续指令的执行路径不确定,从而引发控制冲突。
- 结构冲突:当多条指令需要同一功能单元(如ALU)时,可能会发生结构冲突。
-
K级单发射:
- 这是流水线设计中的一个参数,表示每个时钟周期可以发射的指令数量。例如,如果一个处理器是5级单发射的,那么它每个时钟周期可以发射5条指令。
- K级单发射可以提高指令吞吐量,即单位时间内处理器可以执行的指令数量。这有助于提高处理器的并行度和性能。
-
理想流水线:
- 理想流水线是指没有冲突、延迟或瓶颈的流水线。在这样的流水线中,指令可以无阻碍地通过各个阶段,每个阶段都在处理不同的指令。
- 理想流水线通常作为性能分析的参考模型,但在实际中很难实现,因为各种冲突和延迟是不可避免的。
在实际的处理器设计中,为了减少冲突和提高性能,会采用多种技术和策略,如:
- 分支预测:提前预测分支指令的结果,减少控制冲突。
- 乱序执行:允许指令乱序执行,但保持程序的正确性。
- 超标量执行:通过超标量发射和执行指令来隐藏延迟。
- 寄存器重命名:通过寄存器重命名技术来解决数据冲突。
这些技术和策略的目的是使流水线尽可能接近理想状态,提高处理器的效率和性能。
K级单发射理想流水线的定义和功能
K级单发射理想流水线是一种理论上的流水线模型,它描述了一个流水线在没有冲突和延迟的理想状态下的执行情况。在这种模型中,每个时钟周期可以发射K条指令,这些指令能够无冲突地顺利通过流水线的各个阶段。以下是K级单发射理想流水线的定义和功能:
-
定义:K级单发射理想流水线是指在流水线的每个周期内可以发射K条指令,且这些指令在整个流水线中无冲突地顺利执行。
-
功能:
- 高吞吐量:理想流水线能够在每个周期发射多条指令,从而提高处理器的指令吞吐量。
- 无冲突执行:在理想状态下,流水线的各个阶段都能连续工作,不会出现数据冲突或控制冲突。
- 无延迟:指令在流水线中不会遇到任何延迟,每个阶段都能及时处理指令,没有停顿(stall)。
- 资源利用:流水线的各个功能单元能够被充分利用,没有闲置的资源。
-
特点:
- 阶段数相同:所有指令经过相同的流水线阶段。
- 各段时延相同:各段传输延迟一致,不存在等待现象。
- 无资源冲突:设计时考虑最慢的处理过程,以避免资源冲突。
-
实际应用:理想流水线模型通常用于性能分析和理论计算,它提供了一个上限,展示了在没有冲突和延迟的情况下,流水线的最大性能潜力。在实际的处理器设计中,由于数据冲突、控制冲突和结构限制,很难达到这种理想状态。
-
性能参数:
- 吞吐率(Throughput):理想情况下,吞吐量可以达到K倍于单发射单数据流的性能。
- 加速比(Speedup):相对于非流水线(非流水)系统,理想流水线的加速比可以达到K倍。
- 效率(Efficiency):在理想情况下,流水线的效率可以达到100%。
K级单发射理想流水线的概念有助于理解流水线的潜在性能和设计目标,但在实际应用中,需要通过各种技术和策略(如分支预测、乱序执行、寄存器重命名等)来减少冲突和延迟,以接近理想状态。
纠正自己的一个想法
在一个周期内可以发送多条指令的概念并不是因为存在多个处理器同时工作,而是因为流水线技术允许多个指令在流水线的不同阶段同时进行处理。这里的关键点在于理解流水线的工作原理和多发射(Multi-Issue)的概念:
-
流水线(Pipelining):流水线是处理器内部的一种组织方式,它将指令执行过程分解为多个阶段,如取指(Fetch)、解码(Decode)、执行(Execute)、访存(Memory Access)、写回(Write-back)等。每个阶段可以同时处理不同的指令。
-
多发射(Multi-Issue):多发射处理器设计允许在一个时钟周期内将多条指令发送到流水线的不同阶段。这意味着在一个周期内,可以有多个指令处于流水线的不同阶段。
-
并行性(Concurrency):在多发射流水线中,指令的执行是并行的。例如,当一条指令在执行阶段时,另一条指令可能在解码阶段,而第三条指令可能在取指阶段。这种并行性允许在一个周期内同时处理多条指令。
-
资源分配:为了实现多发射,处理器需要有足够的硬件资源,如寄存器、执行单元和流水线阶段,来同时处理多条指令。
-
指令调度:处理器中的调度器负责决定哪些指令可以并行执行,以及它们的执行顺序。这需要复杂的逻辑来确保指令之间的数据依赖和控制依赖得到正确处理。
-
乱序执行(Out-of-Order Execution):在一些高级处理器中,指令可以乱序执行,即不按照程序中的顺序执行,而是按照它们可以被处理器执行的顺序执行。这进一步提高了并行性和吞吐量。
-
超标量(Superscalar):超标量处理器是一种具有多个执行单元的处理器,它可以在一个周期内执行多条指令,这些指令可能来自不同的流水线阶段。
总结来说,一个周期内可以发送多条指令是因为现代处理器采用了流水线和多发射技术,允许多个指令在流水线的不同阶段同时进行处理,而不是因为存在多个处理器。这种设计提高了处理器的指令吞吐量和性能。
等于在同一个流水线的不同阶段的操作都是基于指令,我之前理解的狭隘了,以为是指单纯的译码或取指的某个阶段
4. 多发射技术与超标量技术
多发射(multiple issue)技术旨在允许处理器在一个时钟周期内译码并发射多条指令到待执行单元中,使得每个周期可以产生多条准备好进入执行阶段的指令
所谓超标量技术,是指处理器拥有多个并行的流水线执行单元,从而使得处理器每个周期可以完成多条指令的执行阶段
多发射技术和超标量技术是现代微处理器设计中用于提高指令吞吐量和性能的两种关键技术。它们允许处理器在单个时钟周期内执行多于一条的指令,从而提高处理器的效率和性能。下面是对这两种技术的详细解释:
-
多发射(Multi-Issue)技术:
- 多发射技术指的是在一个时钟周期内,处理器可以同时发射多条指令到不同的执行单元。这种设计允许更充分地利用处理器的硬件资源,提高指令的并行度。
- 多发射处理器通过增加硬件资源(如更多的译码器、执行单元等)来实现在一个周期内处理多条指令的能力。这需要复杂的调度器来管理指令的发射和执行,以避免资源冲突和数据依赖问题。
- 多发射技术可以是超标量处理器设计的一部分,但也可以单独实现。它通过在每个周期内发射多条指令,提高了指令级并行(ILP)。
-
超标量(Superscalar)技术:
- 超标量技术是一种特定的多发射技术,它涉及到在单个处理器核心内实现多条并行的流水线。超标量处理器在一个时钟周期内可以执行多条指令,这些指令可以来自不同的流水线阶段。
- 超标量设计通过增加处理器内部的流水线数量,允许同时处理多条指令。这种设计以空间换取时间,即通过增加硬件资源来提高处理器的性能。
- 超标量处理器的关键特点包括乱序执行(Out-of-Order Execution),即指令可以乱序执行,只要最终结果与顺序执行时相同。这需要复杂的重排序逻辑来确保指令的正确顺序。
-
区别:
- 多发射可以泛指任何在一个周期内发射多条指令的技术,而超标量特指具有多条流水线的处理器设计。
- 超标量技术通常涉及到更复杂的硬件设计,包括乱序执行和动态调度,而多发射技术可能更侧重于增加发射的指令数量。
- 超标量处理器的性能提升通常比多发射处理器更为显著,因为它涉及到更深层次的并行执行和资源利用。
-
实际应用:
- 现代高性能处理器,如Intel和AMD的x86系列,广泛采用了多发射和超标量技术。这些技术使得处理器能够在单个时钟周期内执行多条指令,显著提高了处理器的吞吐吐量和响应速度。
- 在实际应用中,这些技术允许处理器更有效地处理复杂的计算任务,如图形处理、科学计算和人工智能等。
-
挑战:
- 实现多发射和超标量技术需要解决指令之间的数据依赖和控制依赖问题,这可能需要复杂的调度算法和硬件支持。
- 随着发射数量的增加,处理器的功耗和热量管理也变得更加复杂,需要先进的冷却技术和电源管理策略。
总的来说,多发射和超标量技术是提高处理器性能的重要手段,它们通过在一个时钟周期内执行多条指令来提升处理器的吞吐量和效率。这些技术在现代处理器设计中发挥着核心作用,推动了计算能力的巨大进步。
5. 局部预测器的缺陷
它只考虑了每一条指令各自的局部历史,而没有考虑分支指令之间的相关性