目录
- [1. 背景](#1. 背景)
- [2. 目标](#2. 目标)
- [3. Pamion 的概念和设计](#3. Pamion 的概念和设计)
- [3.1 架构](#3.1 架构)
- [3.2 统一存储](#3.2 统一存储)
- [3.3 基础概念](#3.3 基础概念)
- [3.3.1 文件布局](#3.3.1 文件布局)
- [3.3.2 Snapshot](#3.3.2 Snapshot)
- [3.3.3 Manifest 文件](#3.3.3 Manifest 文件)
- [3.3.4 数据文件](#3.3.4 数据文件)
- [3.3.5 分区](#3.3.5 分区)
- [3.3.6 一致性保证](#3.3.6 一致性保证)
- [3.4 并发控制](#3.4 并发控制)
- [3.4.1 快照冲突](#3.4.1 快照冲突)
- [3.4.2 文件冲突](#3.4.2 文件冲突)
- [3.5 Catalog](#3.5 Catalog)
- [3.5.1 Filesystem Catalog](#3.5.1 Filesystem Catalog)
- [3.5.2 Hive Catalog](#3.5.2 Hive Catalog)
- [3.5.3 JDBC Catalog](#3.5.3 JDBC Catalog)
- [3.6 表类型](#3.6 表类型)
- [3.6.1 带主键的表格(Table with PK)](#3.6.1 带主键的表格(Table with PK))
- [3.6.2 无主键表(Table w/o PK)](#3.6.2 无主键表(Table w/o PK))
- [3.6.3 视图(View)](#3.6.3 视图(View))
- [3.6.4 格式表(Format Table)](#3.6.4 格式表(Format Table))
- [3.6.5 Object Table](#3.6.5 Object Table)
- [3.6.5 Materialized Table](#3.6.5 Materialized Table)
- [3.7 System Tables](#3.7 System Tables)
- [3.7.1 Data System Table](#3.7.1 Data System Table)
- [3.7.1.1 Snapshots Table](#3.7.1.1 Snapshots Table)
- [3.7.1.2 Schemas Table](#3.7.1.2 Schemas Table)
- [3.7.1.3 Options Table](#3.7.1.3 Options Table)
- [3.7.1.4 Audit log Table](#3.7.1.4 Audit log Table)
- [3.7.1.5 Binlog Table](#3.7.1.5 Binlog Table)
- [3.7.1.6 Read-optimized Table](#3.7.1.6 Read-optimized Table)
- [3.7.1.7 Files Table](#3.7.1.7 Files Table)
- [3.7.1.8 Tags Table](#3.7.1.8 Tags Table)
- [3.7.1.9 Branches Table](#3.7.1.9 Branches Table)
- [3.7.1.10 Consumers Table](#3.7.1.10 Consumers Table)
- [3.7.1.11 Manifests Table](#3.7.1.11 Manifests Table)
- [3.7.1.12 Aggregation fields Table](#3.7.1.12 Aggregation fields Table)
- [3.7.1.13 Partitions Table](#3.7.1.13 Partitions Table)
- [3.7.1.14 Buckets Table](#3.7.1.14 Buckets Table)
- [3.7.1.15 Statistic Table](#3.7.1.15 Statistic Table)
- [3.7.1.13 Table Indexes Table](#3.7.1.13 Table Indexes Table)
- [3.7.2 Global System Table](#3.7.2 Global System Table)
- [3.7.2.1 ALL Options Table](#3.7.2.1 ALL Options Table)
- [3.7.2.2 Catalog Options Table](#3.7.2.2 Catalog Options Table)
- [3.7.1 Data System Table](#3.7.1 Data System Table)
- [3.8 Data Types](#3.8 Data Types)
- [3.9 Spec](#3.9 Spec)
- [3.9.1 Schema](#3.9.1 Schema)
- [3.9.2 Snapshot](#3.9.2 Snapshot)
- [3.9.3 Manifest](#3.9.3 Manifest)
- [3.9.3.1 Manifest List](#3.9.3.1 Manifest List)
- [3.9.3.2 Manifest](#3.9.3.2 Manifest)
- [3.9.3.3 Data Manifest](#3.9.3.3 Data Manifest)
- [3.9.3.4 Index Manifest](#3.9.3.4 Index Manifest)
- [3.9.4 DataFile](#3.9.4 DataFile)
- [3.9.4.1 Partition](#3.9.4.1 Partition)
- [3.9.4.2 Bucket](#3.9.4.2 Bucket)
- [3.9.4.3 Data File](#3.9.4.3 Data File)
- [3.9.4.4 Table with Primary key Data File](#3.9.4.4 Table with Primary key Data File)
- [3.9.4.5 Table w/o Primary key Data File](#3.9.4.5 Table w/o Primary key Data File)
- [3.9.4.6 Changelog File](#3.9.4.6 Changelog File)
- [3.9.5 Table index](#3.9.5 Table index)
- [3.9.5.1 Dynamic Bucket Index](#3.9.5.1 Dynamic Bucket Index)
- [3.9.5.2 Deletion Vectors](#3.9.5.2 Deletion Vectors)
- [3.9.6 File index](#3.9.6 File index)
- [3.9.6.1 Index File](#3.9.6.1 Index File)
- [3.9.6.2 Index: BloomFilter](#3.9.6.2 Index: BloomFilter)
- [3.9.6.3 Index: Bitmap](#3.9.6.3 Index: Bitmap)
- [3.9.6.4 Index: Bit-Slice Index Bitmap](#3.9.6.4 Index: Bit-Slice Index Bitmap)
- [3.9.6.5 BSI 序列化格式 (V1):](#3.9.6.5 BSI 序列化格式 (V1):)
- 4.参考
1. 背景
当前实时的痛点: 流式数据存储无法复用、中间层数据不可查、做不到实时聚合计算
Paimon解决的痛点: 延续了 kappa 架构的特点,一套流处理架构,好处在与,底层 Paimon 的技术支撑使得数据在全链路可查,数仓分层架构得以复用,同时兼顾了离线和实时的处理能力,减少存储和计算的浪费
数据湖能力区别:
主要看场景,hudi适合更新操作较多,iceberg适合schema变更较多场景
hudi 入库和查询数据量大的时候资源耗用较大
架构演进:

2. 目标
Streampark + paimon 架构:
实现建立一个全链路实时流动、可查询和分层可复用的 Pipline
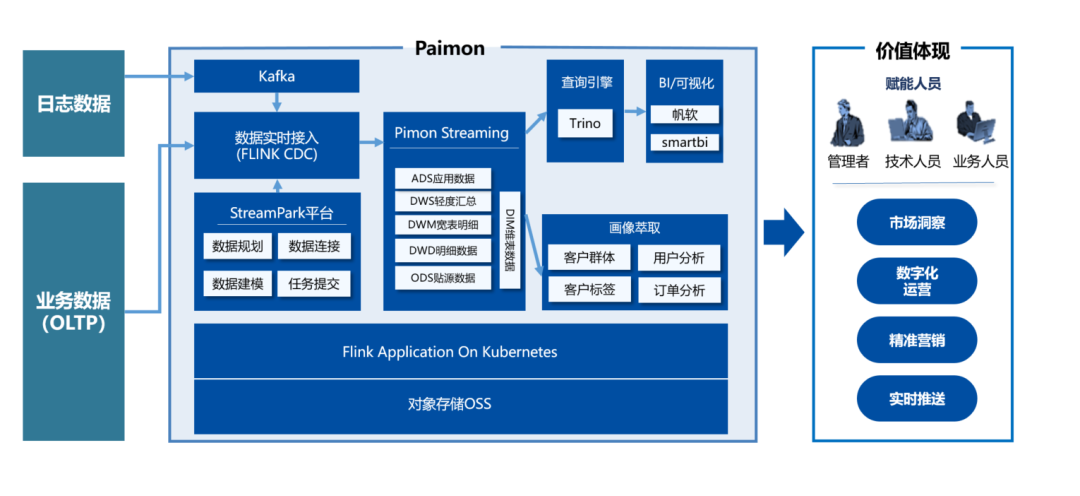
3. Pamion 的概念和设计
3.1 架构
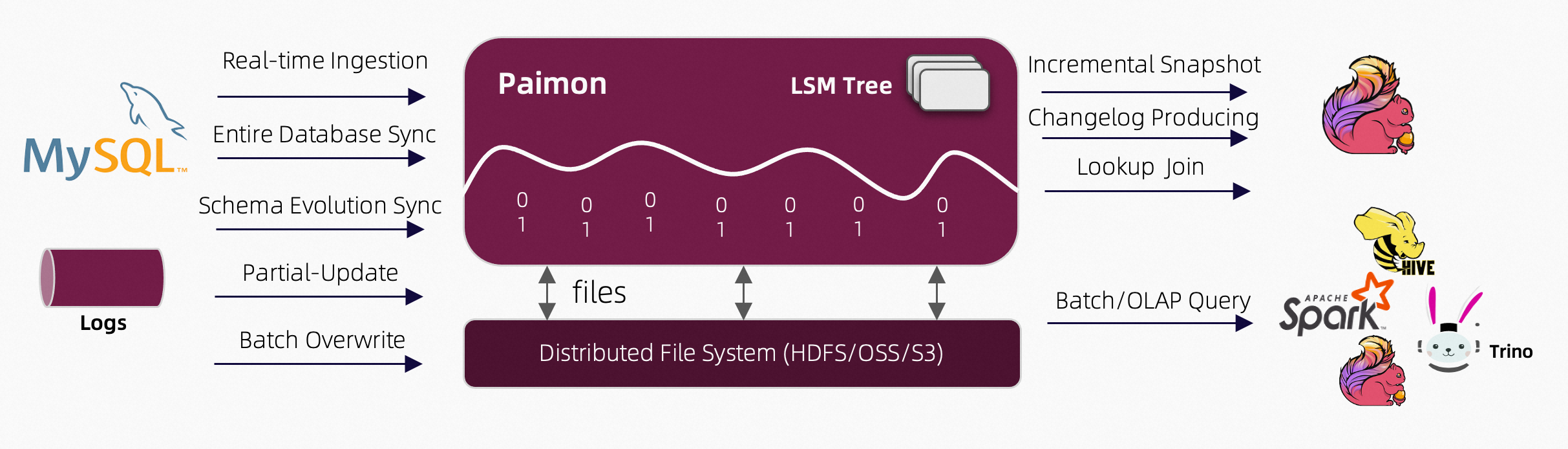
Rread & Write pamion 支持多种方式读写数据 和 olap查询
对于读,支持消费数据:
- 批量模式下,支持从历史快照读
- 流式模式下,支持从最近的offset读
- 混合模式下读取增量快照
写支持: - 流实 cdc数据同步
- 离线数据 批量 insert/overwrite
Ecosystem 除了flink,还支持spark、hive、trino计算引擎
Internal
- 底层存储列式文件在文件系统和对象存储中
- 文件的元数据存储在mainfest文件中,提供大规模存储和数据跳过的能力
- 对于主键表,使用LSM tree 支持大规模数据的更新和高性能查询
3.2 统一存储
Flink 有三种连接器:
- 消息队列, 如kafka, 在pipeline的源和中间阶段使用 ,确保延迟在秒级以下
- OLAP,如clickhouse, 它以流式数据接收梳理的方式,提供给用户即席查询
- 批处理存储,如hive, 支持批处理的各种操作, 包括INSERT OVERWRITE
pamion 提供表抽象,在方式上与传统数据库相同:
- 在batch执行模式下,像hive 支持各种batch sql 操作,查询它的最新快照
- 在streaming模式下,像消息队列,查询它像查询流变更日志,其中的历史数据永远不会过期
3.3 基础概念
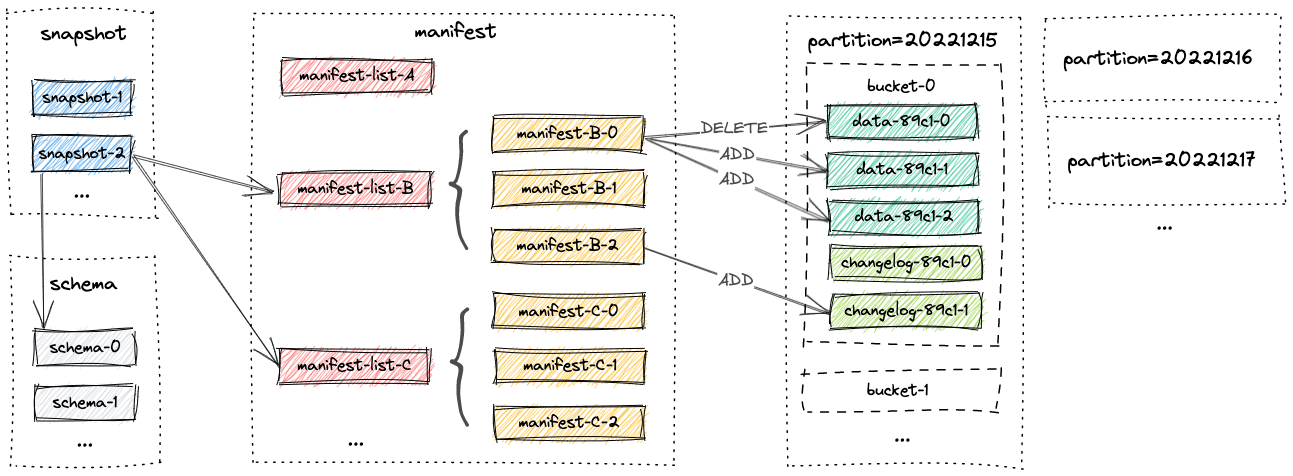
3.3.1 文件布局
表的所有文件都存储在一个基本目录下。Paimon 文件采用分层组织方式。以下图片说明了文件布局。 从快照文件开始,Paimon 读取器可以递归地访问表中的所有记录。
3.3.2 Snapshot
所有snapshot文件都存储在snapshot目录中。
快照文件是一个包含快照信息的json文件,其中包括
- 当前使用的schema文件
- 包含snapshot所有变更的manifest清单
快照捕捉某一时刻表的状态。用户可以通过最新快照访问表的最新数据。通过时间旅行,用户也可以较早的快照访问表的之前的状态
3.3.3 Manifest 文件
所有Manifest列表和Manifest文件都存储在manifest目录中
一个Manifest文件 包含LSM数据文件和变更记录的文件。 举个例子,比如在对应的快照里,创建了哪个LSM文件或者哪个文件被删除。
3.3.4 数据文件
数据按照分区分组,目前,Paimon 支持使用 Parquet(默认)、orc 和 avro 作为数据文件的格式
3.3.5 分区
pamion 采用跟hive 一样的分区概念来分离数据
分区是一种根据特定列(如日期、城市和部门)的值将表划分为相关部分的可选方式。每一张表可以有单个或多个分区键,以标识特定的分区
通过分区,用户可以高效地操作表中的一些记录
3.3.6 一致性保证
Paimon 写 使用两阶段提交协议来原子地批量提交记录到表中。每一次提交都会生成最多两个快照。这取决于增量写入和压缩策略。如果只进行了增量写入而没有触发压缩操作,则只会创建增量快照。如果触发了压缩操作,则会创建增量快照和压缩快照。
对于任何两个writer 同时修改同一table , 只要他们不修改同一分区,它们的提交可以并行发生。 如果他们修改了相同的分区,则只保证快照隔离。也就是说,最终的表状态可能是两个提交的混合,但不会丢失任何变化
3.4 并发控制
Paimon 支持多重乐观锁并发写入作业。
每个作业都会以自己的速度写入数据,基于当前快照: 增量文件(删除或添加文件)在提交时 生成一个新的快照
这里可能有两种类型的提交失败:
1.快照冲突:快照ID已被抢占,表由另一个作业生成了一个新的快照。那我们再提交一次。
2.文件冲突:本作业想要删除的文件已被其他作业删除。此时,作业只能失败。(对于流式作业,它会失败并重新开始,意图性故障转移一次)
3.4.1 快照冲突
Paimon 的快照 ID 是唯一的,只要作业将其快照文件写入文件系统,就被视为成功。

但对于对象存储(如OSS和S3),它们的'RENAME'操作不具有原子语义。我们需要配置Hive或 jdbc metastore,并为目录启用
'lock.enabled'选项。这样做可以防止丢失快照。
3.4.2 文件冲突
当Paimon提交一个文件删除(仅是逻辑删除)时,它会检查与最新的快照是否冲突。 如果存在冲突(意味着文件已被逻辑删除),它将无法继续在此提交节点进行操作, 因此它只能故意触发故障转移以重新启动,作业将从文件系统中获取最新的状态,希望解决这种冲突

Paimon 将确保这里没有数据丢失或重复,但如果两个流处理作业同时在写入且发生冲突,你会看到它们不断重启,这并不是一个好现象。
冲突的本质在于删除文件(逻辑上),而删除文件源于压缩,只要我们关闭写入作业的压缩(将'write-only'设置为true),并启动一个单独的作业来执行压缩工作,一切都很顺利。
3.5 Catalog
Paimon提供了目录抽象,用于管理表内容及其元数据。目录抽象提供了 一系列方式来帮助您更好地与计算引擎集成。我们一贯建议您使用catalog来访问Paimon表。
Paimon 目录目前支持三种类型的metastore:
- filesystem 元存储(默认),它将元数据和表文件存储在文件系统中。
- hive 元存储,该元存储还额外存储了元数据。用户可以直接从 Hive 访问表
- jdbc 元存储,它还可以在如 MySQL、Postgres 等关系数据库中存储元数据
3.5.1 Filesystem Catalog
元数据和表文件存储在hdfs:///path/to/warehouse下。

-- Flink SQL
CREATE CATALOG my_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs:///path/to/warehouse'
);3.5.2 Hive Catalog
使用Paimon Hive目录,目录的更改将直接影响相应的Hive元存储。创建在这种目录中的表也可以直接从Hive访问。表中的元数据和表文件存储在
hdfs:///path/to/warehouse下。此外,schema也存储在Hive元存储中。
-- Flink SQL
CREATE CATALOG my_hive WITH (
'type' = 'paimon',
'metastore' = 'hive',
-- 'warehouse' = 'hdfs:///path/to/warehouse', default use 'hive.metastore.warehouse.dir' in HiveConf
);默认情况下,Paimon不会将新创建的分区同步到Hive metasttore中。 用户将在Hive中看到未分区的数据表. 分区下推将由过滤器下推来替代实现
如果您想在 Hive 中查看分区表,并且还想将新创建的分区同步到 Hive 元存储,请将表选项 metastore.partitioned-table 设置为 true。
3.5.3 JDBC Catalog
通过使用Paimon JDBC目录,catalog的更改将直接存储在如SQLite、MySQL、postgres等关系数据库中
-- Flink SQL
CREATE CATALOG my_jdbc WITH (
'type' = 'paimon',
'metastore' = 'jdbc',
'uri' = 'jdbc:mysql://<host>:<port>/<databaseName>',
'jdbc.user' = '...',
'jdbc.password' = '...',
'catalog-key'='jdbc',
'warehouse' = 'hdfs:///path/to/warehouse'
);3.6 表类型
pamion 支持的表类型:
- 带主键的表格(table with pk):具有主键的 Paimon 数据表
- 不带主键的表格(table w/o pk):没有主键的 Paimon 数据表
- 视图(view):需要元存储,SQL 中的视图是一种虚拟表
- 格式表(format-table):文件格式表是指包含多个相同格式文件的目录,对该表的操作允许读取或写入这些文件,兼容 Hive 表
- 对象表(object table):为指定对象存储目录中的非结构化数据对象提供元数据索引
- 物化表(materialized-table):旨在简化批处理和流数据管道,提供一致的开发体验,参见 Flink 物化表
3.6.1 带主键的表格(Table with PK)
主键由一组列组成,这些列包含每条记录的唯一值。Paimon 通过在每个桶内对主键进行排序来强制数据排序,从而实现流式更新和流式变更日志读取。
主键的定义与标准 SQL 类似,它确保在批处理查询期间,相同主键只能有一条数据记录。
Flink SQL 示例
CREATE TABLE my_table (
a INT PRIMARY KEY NOT ENFORCED,
b STRING
) WITH (
'bucket'='8'
);3.6.2 无主键表(Table w/o PK)
如果表未定义主键,则为追加表。与主键表相比,它不具备直接接收变更日志的能力,也无法通过流式 upsert 直接更新数据,只能接收追加数据。
不过,它也支持批处理 SQL:DELETE、UPDATE 和 MERGE-INTO。
CREATE TABLE my_table (
a INT,
b STRING
);3.6.3 视图(View)
当metastore支持视图时(例如 Hive 元存储),可以使用视图。如果没有metasote,则只能使用临时视图,临时视图仅在当前会话中存在。本章主要描述持久化视图。
视图目前会保存原始 SQL。如果需要跨引擎使用视图,可以编写跨引擎的 SQL 语句。例如:
Flink SQL
CREATE VIEW [IF NOT EXISTS] [catalog_name.][db_name.]view_name
[( columnName [, columnName ]* )] [COMMENT view_comment]
AS query_expression;
DROP VIEW [IF EXISTS] [catalog_name.][db_name.]view_name;
SHOW VIEWS;
SHOW CREATE VIEW my_view;3.6.4 格式表(Format Table)
当metstore支持格式表时(例如 Hive 元存储),可以使用格式表。元存储中的 Hive 表将被映射为 Paimon 的格式表,供计算引擎(Spark、Hive、Flink)读写。
格式表是指包含多个相同格式文件的目录,对该表的操作允许读取或写入这些文件,便于检索现有数据并添加新文件。
分区文件格式表类似于标准的 Hive 格式。分区是基于目录结构发现和推断的。
格式表默认启用,可以通过配置 Catalog 选项 'format-table.enabled' 来禁用。
目前仅支持 CSV、Parquet 和 ORC 格式。
CREATE TABLE my_csv_table (
a INT,
b STRING
) WITH (
'type'='format-table',
'file.format'='csv',
'field-delimiter'=','
)3.6.5 Object Table
对象表为指定对象存储存储目录中的非结构化数据对象提供元数据索引。 对象表允许用户分析对象存储中的非结构化数据:
- 使用 Python API 来操作这些非结构化数据,例如将图像转换为 PDF 格式。
- 模型函数也可以用于执行推理,然后可以将这些操作的结果与其他结构化数据在目录中连接起来。
对象表由catalog管理,也可以具有访问权限和管理血缘关系的能力。
-- Create Object Table
CREATE TABLE `my_object_table` WITH (
'type' = 'object-table',
'object-location' = 'oss://my_bucket/my_location'
);
-- Refresh Object Table
CALL sys.refresh_object_table('mydb.my_object_table');
-- Query Object Table
SELECT * FROM `my_object_table`;
-- Query Object Table with Time Travel
SELECT * FROM `my_object_table` /*+ OPTIONS('scan.snapshot-id' = '1') */;3.6.5 Materialized Table
物化表旨在简化批处理和流数据管道,提供一致的开发体验
现在只有Flink SQL集成到物化表中,计划在Spark SQL中也支持它。
CREATE MATERIALIZED TABLE continuous_users_shops
PARTITIONED BY (ds)
FRESHNESS = INTERVAL '30' SECOND
AS SELECT
user_id,
ds,
SUM (payment_amount_cents) AS payed_buy_fee_sum,
SUM (1) AS PV
FROM (
SELECT user_id, order_created_at AS ds, payment_amount_cents
FROM json_source
) AS tmp
GROUP BY user_id, ds;3.7 System Tables
Paimon提供了一套非常丰富的系统表,帮助用户更好地分析和查询Paimon表的状态:
1.查询数据表的状态:数据系统表。
2.查询整个目录的全局状态:全局系统表。
3.7.1 Data System Table
数据系统表包含有关每个Paimon数据表的元数据和信息,例如创建的快照和正在使用的options 。用户可以通过批量查询访问系统表。
目前,Flink、Spark、Trino 和 StarRocks 支持查询系统表。
在某些情况下,表名需要用反引号括起来以避免语法解析冲突,例如三重访问模式:
SELECT * FROM my_catalog.my_db.`my_table$snapshots`;3.7.1.1 Snapshots Table
您可以通过快照表查询表快照的历史信息,包括快照中发生的记录数。
SELECT * FROM my_table$snapshots;
/*
+--------------+------------+-----------------+-------------------+--------------+-------------------------+--------------------------------+------------------------------- +--------------------------------+---------------------+---------------------+-------------------------+----------------+
| snapshot_id | schema_id | commit_user | commit_identifier | commit_kind | commit_time | base_manifest_list | delta_manifest_list | changelog_manifest_list | total_record_count | delta_record_count | changelog_record_count | watermark |
+--------------+------------+-----------------+-------------------+--------------+-------------------------+--------------------------------+------------------------------- +--------------------------------+---------------------+---------------------+-------------------------+----------------+
| 2 | 0 | 7ca4cd28-98e... | 2 | APPEND | 2022-10-26 11:44:15.600 | manifest-list-31323d5f-76e6... | manifest-list-31323d5f-76e6... | manifest-list-31323d5f-76e6... | 2 | 2 | 0 | 1666755855600 |
| 1 | 0 | 870062aa-3e9... | 1 | APPEND | 2022-10-26 11:44:15.148 | manifest-list-31593d5f-76e6... | manifest-list-31593d5f-76e6... | manifest-list-31593d5f-76e6... | 1 | 1 | 0 | 1666755855148 |
+--------------+------------+-----------------+-------------------+--------------+-------------------------+--------------------------------+------------------------------- +--------------------------------+---------------------+---------------------+-------------------------+----------------+
2 rows in set
*/通过查询快照表,您可以了解该表的相关提交和过期信息,并可以通过数据实现时间旅行。
3.7.1.2 Schemas Table
您可以通过schemas表查询表的历史schemas。
SELECT * FROM my_table$schemas;
/*
+-----------+--------------------------------+----------------+--------------+---------+---------+-------------------------+
| schema_id | fields | partition_keys | primary_keys | options | comment | update_time |
+-----------+--------------------------------+----------------+--------------+---------+---------+-------------------------+
| 0 | [{"id":0,"name":"word","typ... | [] | ["word"] | {} | | 2022-10-28 11:44:20.600 |
| 1 | [{"id":0,"name":"word","typ... | [] | ["word"] | {} | | 2022-10-27 11:44:15.600 |
| 2 | [{"id":0,"name":"word","typ... | [] | ["word"] | {} | | 2022-10-26 11:44:10.600 |
+-----------+--------------------------------+----------------+--------------+---------+---------+-------------------------+
3 rows in set
*/你可以将快照表和模式表连接起来,以获取给定快照的字段。
SELECT s.snapshot_id, t.schema_id, t.fields
FROM my_table$snapshots s JOIN my_table$schemas t
ON s.schema_id=t.schema_id where s.snapshot_id=100;3.7.1.3 Options Table
您可以通过选项表查询从DDL中指定的表选项信息。未显示的选项将是默认值
SELECT * FROM my_table$options;
/*
+------------------------+--------------------+
| key | value |
+------------------------+--------------------+
| snapshot.time-retained | 5 h |
+------------------------+--------------------+
1 rows in set
*/3.7.1.4 Audit log Table
如果您需要审核表中的更改日志,可以使用audit_log系统表。通过audit_log表,您可以在获取表增量数据时获取rowkind列。您可以使用此列进行过滤和其他操作以完成audit。
rowkind 有四个值:
+I: 插入操作。
-U: 使用更新行之前的旧内容进行更新操作。
+U: 更新操作,使用更新行的最新内容。
-D: 删除操作。
SELECT * FROM my_table$audit_log;
/*
+------------------+-----------------+-----------------+
| rowkind | column_0 | column_1 |
+------------------+-----------------+-----------------+
| +I | ... | ... |
+------------------+-----------------+-----------------+
| -U | ... | ... |
+------------------+-----------------+-----------------+
| +U | ... | ... |
+------------------+-----------------+-----------------+
3 rows in set
*/3.7.1.5 Binlog Table
您可以通过binlog表查询binlog。在binlog系统表中,更新前和更新后的内容将被打包在一行中。
SELECT * FROM T$binlog;
/*
+------------------+----------------------+-----------------------+
| rowkind | column_0 | column_1 |
+------------------+----------------------+-----------------------+
| +I | [col_0] | [col_1] |
+------------------+----------------------+-----------------------+
| +U | [col_0_ub, col_0_ua] | [col_1_ub, col_1_ua] |
+------------------+----------------------+-----------------------+
| -D | [col_0] | [col_1] |
+------------------+----------------------+-----------------------+
*/3.7.1.6 Read-optimized Table
如果您需要极端的读取性能并且可以接受读取稍微旧的数据, 您可以使用ro(读取优化)系统表。 读取优化系统表通过仅扫描不需要合并的文件来提高读取性能。
对于主键表,ro 系统表只扫描最顶层的文件。 也就是说,ro 系统表只产生最新完全压缩的结果。
对于追加表,由于所有文件都可以在不合并的情况下读取, ro 系统表的行为就像普通的追加表。
SELECT * FROM my_table$ro;3.7.1.7 Files Table
您可以使用特定的快照查询表中的文件。
-- Query the files of latest snapshot
SELECT * FROM my_table$files;
/*
+-----------+--------+--------------------------------+-------------+-----------+-------+--------------+--------------------+---------+---------+------------------------+-------------------------+-------------------------+---------------------+---------------------+-----------------------+
| partition | bucket | file_path | file_format | schema_id | level | record_count | file_size_in_bytes | min_key | max_key | null_value_counts | min_value_stats | max_value_stats | min_sequence_number | max_sequence_number | creation_time |
+-----------+--------+--------------------------------+-------------+-----------+-------+--------------+--------------------+---------+---------+------------------------+-------------------------+-------------------------+---------------------+---------------------+-----------------------+
| [3] | 0 | data-8f64af95-29cc-4342-adc... | orc | 0 | 0 | 1 | 593 | [c] | [c] | {cnt=0, val=0, word=0} | {cnt=3, val=33, word=c} | {cnt=3, val=33, word=c} | 1691551246234 | 1691551246637 |2023-02-24T16:06:21.166|
| [2] | 0 | data-8b369068-0d37-4011-aa5... | orc | 0 | 0 | 1 | 593 | [b] | [b] | {cnt=0, val=0, word=0} | {cnt=2, val=22, word=b} | {cnt=2, val=22, word=b} | 1691551246233 | 1691551246732 |2023-02-24T16:06:21.166|
| [2] | 0 | data-83aa7973-060b-40b6-8c8... | orc | 0 | 0 | 1 | 605 | [d] | [d] | {cnt=0, val=0, word=0} | {cnt=2, val=32, word=d} | {cnt=2, val=32, word=d} | 1691551246267 | 1691551246798 |2023-02-24T16:06:21.166|
| [5] | 0 | data-3d304f4a-bcea-44dc-a13... | orc | 0 | 0 | 1 | 593 | [c] | [c] | {cnt=0, val=0, word=0} | {cnt=5, val=51, word=c} | {cnt=5, val=51, word=c} | 1691551246788 | 1691551246152 |2023-02-24T16:06:21.166|
| [1] | 0 | data-10abb5bc-0170-43ae-b6a... | orc | 0 | 0 | 1 | 595 | [a] | [a] | {cnt=0, val=0, word=0} | {cnt=1, val=11, word=a} | {cnt=1, val=11, word=a} | 1691551246722 | 1691551246273 |2023-02-24T16:06:21.166|
| [4] | 0 | data-2c9b7095-65b7-4013-a7a... | orc | 0 | 0 | 1 | 593 | [a] | [a] | {cnt=0, val=0, word=0} | {cnt=4, val=12, word=a} | {cnt=4, val=12, word=a} | 1691551246321 | 1691551246109 |2023-02-24T16:06:21.166|
+-----------+--------+--------------------------------+-------------+-----------+-------+--------------+--------------------+---------+---------+------------------------+-------------------------+-------------------------+---------------------+---------------------+-----------------------+
6 rows in set
*/
-- You can also query the files with specific snapshot
SELECT * FROM my_table$files /*+ OPTIONS('scan.snapshot-id'='1') */;
/*
+-----------+--------+--------------------------------+-------------+-----------+-------+--------------+--------------------+---------+---------+------------------------+-------------------------+-------------------------+---------------------+---------------------+-----------------------+
| partition | bucket | file_path | file_format | schema_id | level | record_count | file_size_in_bytes | min_key | max_key | null_value_counts | min_value_stats | max_value_stats | min_sequence_number | max_sequence_number | creation_time |
+-----------+--------+--------------------------------+-------------+-----------+-------+--------------+--------------------+---------+---------+------------------------+-------------------------+-------------------------+---------------------+---------------------+-----------------------+
| [3] | 0 | data-8f64af95-29cc-4342-adc... | orc | 0 | 0 | 1 | 593 | [c] | [c] | {cnt=0, val=0, word=0} | {cnt=3, val=33, word=c} | {cnt=3, val=33, word=c} | 1691551246234 | 1691551246637 |2023-02-24T16:06:21.166|
| [2] | 0 | data-8b369068-0d37-4011-aa5... | orc | 0 | 0 | 1 | 593 | [b] | [b] | {cnt=0, val=0, word=0} | {cnt=2, val=22, word=b} | {cnt=2, val=22, word=b} | 1691551246233 | 1691551246732 |2023-02-24T16:06:21.166|
| [1] | 0 | data-10abb5bc-0170-43ae-b6a... | orc | 0 | 0 | 1 | 595 | [a] | [a] | {cnt=0, val=0, word=0} | {cnt=1, val=11, word=a} | {cnt=1, val=11, word=a} | 1691551246267 | 1691551246798 |2023-02-24T16:06:21.166|
+-----------+--------+--------------------------------+-------------+-----------+-------+--------------+--------------------+---------+---------+------------------------+-------------------------+-------------------------+---------------------+---------------------+-----------------------+
3 rows in set
*/3.7.1.8 Tags Table
您可以通过标签表查询表标签的历史信息,包括哪些快照是基于标签的,以及一些快照的历史信息。您还可以通过名称获取所有标签名称,并按名称进行时间旅行以访问特定标签数据。
SELECT * FROM my_table$tags;
/*
+----------+-------------+-----------+-------------------------+--------------+--------------+
| tag_name | snapshot_id | schema_id | commit_time | record_count | branches |
+----------+-------------+-----------+-------------------------+--------------+--------------+
| tag1 | 1 | 0 | 2023-06-28 14:55:29.344 | 3 | [] |
| tag3 | 3 | 0 | 2023-06-28 14:58:24.691 | 7 | [branch-1] |
+----------+-------------+-----------+-------------------------+--------------+--------------+
2 rows in set
*/3.7.1.9 Branches Table
您可以查询表中的分支。
SELECT * FROM my_table$branches;
/*
+----------------------+-------------------------+
| branch_name | create_time |
+----------------------+-------------------------+
| branch1 | 2024-07-18 20:31:39.084 |
| branch2 | 2024-07-18 21:11:14.373 |
+----------------------+-------------------------+
2 rows in set
*/3.7.1.10 Consumers Table
你可以查询所有包含下一个快照的消费者。
SELECT * FROM my_table$consumers;
/*
+-------------+------------------+
| consumer_id | next_snapshot_id |
+-------------+------------------+
| id1 | 1 |
| id2 | 3 |
+-------------+------------------+
2 rows in set
*/3.7.1.11 Manifests Table
你可以查询最新快照或当前表指定的快照中包含的所有清单文件。
-- Query the manifest of latest snapshot
SELECT * FROM my_table$manifests;
/*
+--------------------------------+-------------+------------------+-------------------+---------------+
| file_name | file_size | num_added_files | num_deleted_files | schema_id |
+--------------------------------+-------------+------------------+-------------------+---------------+
| manifest-f4dcab43-ef6b-4713... | 12365| 40 | 0 | 0 |
| manifest-f4dcab43-ef6b-4713... | 1648 | 1 | 0 | 0 |
+--------------------------------+-------------+------------------+-------------------+---------------+
2 rows in set
*/
-- You can also query the manifest with specified snapshot
SELECT * FROM my_table$manifests /*+ OPTIONS('scan.snapshot-id'='1') */;
/*
+--------------------------------+-------------+------------------+-------------------+---------------+
| file_name | file_size | num_added_files | num_deleted_files | schema_id |
+--------------------------------+-------------+------------------+-------------------+---------------+
| manifest-f4dcab43-ef6b-4713... | 12365| 40 | 0 | 0 |
+--------------------------------+-------------+------------------+-------------------+---------------+
1 rows in set
*/
- You can also query the manifest with specified tagName
SELECT * FROM my_table$manifests /*+ OPTIONS('scan.tag-name'='tag1') */;
/*
+--------------------------------+-------------+------------------+-------------------+---------------+
| file_name | file_size | num_added_files | num_deleted_files | schema_id |
+--------------------------------+-------------+------------------+-------------------+---------------+
| manifest-f4dcab43-ef6b-4713... | 12365| 40 | 0 | 0 |
+--------------------------------+-------------+------------------+-------------------+---------------+
1 rows in set
*/
- You can also query the manifest with specified timestamp in unix milliseconds
SELECT * FROM my_table$manifests /*+ OPTIONS('scan.timestamp-millis'='1678883047356') */;
/*
+--------------------------------+-------------+------------------+-------------------+---------------+
| file_name | file_size | num_added_files | num_deleted_files | schema_id |
+--------------------------------+-------------+------------------+-------------------+---------------+
| manifest-f4dcab43-ef6b-4713... | 12365| 40 | 0 | 0 |
+--------------------------------+-------------+------------------+-------------------+---------------+
1 rows in set
*/3.7.1.12 Aggregation fields Table
您可以通过聚合字段表查询表的历史聚合数据。
SELECT * FROM my_table$aggregation_fields;
/*
+------------+-----------------+--------------+--------------------------------+---------+
| field_name | field_type | function | function_options | comment |
+------------+-----------------+--------------+--------------------------------+---------+
| product_id | BIGINT NOT NULL | [] | [] | <NULL> |
| price | INT | [true,count] | [fields.price.ignore-retrac... | <NULL> |
| sales | BIGINT | [sum] | [fields.sales.aggregate-fun... | <NULL> |
+------------+-----------------+--------------+--------------------------------+---------+
3 rows in set
*/3.7.1.13 Partitions Table
您可以查询表中的分区文件。
SELECT * FROM my_table$partitions;
/*
+---------------+----------------+--------------------+--------------------+------------------------+
| partition | record_count | file_size_in_bytes| file_count| last_update_time|
+---------------+----------------+--------------------+--------------------+------------------------+
| [1] | 1 | 645 | 1 | 2024-06-24 10:25:57.400|
+---------------+----------------+--------------------+--------------------+------------------------+
*/3.7.1.14 Buckets Table
您可以查询表中的桶文件。
SELECT * FROM my_table$buckets;
/*
+---------------+--------+----------------+--------------------+--------------------+------------------------+
| partition | bucket | record_count | file_size_in_bytes| file_count| last_update_time|
+---------------+--------+----------------+--------------------+--------------------+------------------------+
| [1] | 0 | 1 | 645 | 1 | 2024-06-24 10:25:57.400|
+---------------+--------+----------------+--------------------+--------------------+------------------------+
*/3.7.1.15 Statistic Table
您可以通过统计表查询统计信息。
SELECT * FROM T$statistics;
/*
+--------------+------------+-----------------------+------------------+----------+
| snapshot_id | schema_id | mergedRecordCount | mergedRecordSize | colstat |
+--------------+------------+-----------------------+------------------+----------+
| 2 | 0 | 2 | 2 | {} |
+--------------+------------+-----------------------+------------------+----------+
1 rows in set
*/3.7.1.13 Table Indexes Table
您可以通过索引表查询为动态桶表生成的索引文件(index_type = HASH)和删除向量(index_type = DELETION_VECTORS)。
SELECT * FROM my_table$table_indexes;
/*
+--------------------------------+-------------+--------------------------------+--------------------------------+----------------------+----------------------+--------------------------------+
| partition | bucket | index_type | file_name | file_size | row_count | dv_ranges |
+--------------------------------+-------------+--------------------------------+--------------------------------+----------------------+----------------------+--------------------------------+
| [2024-10-01] | 0 | HASH | index-70abfebf-149e-4796-9f... | 12 | 3 | <NULL> |
| [2024-10-01] | 0 | DELETION_VECTORS | index-633857e7-cdce-47d2-87... | 33 | 1 | [(data-346cb9c8-4032-4d66-a... |
+--------------------------------+-------------+--------------------------------+--------------------------------+----------------------+----------------------+--------------------------------+
2 rows in set
*/3.7.2 Global System Table
全局系统表包含paimon中所有表的统计信息。为了方便搜索,我们创建了一个名为
sys的参考系统数据库。 我们可以在flink中通过sql显示所有全局系统表:
USE sys;
SHOW TABLES;3.7.2.1 ALL Options Table
此表类似于选项表,但它显示了所有数据库中的所有表选项。
SELECT * FROM sys.all_table_options;
/*
+---------------+--------------------------------+--------------------------------+------------------+
| database_name | table_name | key | value |
+---------------+--------------------------------+--------------------------------+------------------+
| my_db | Orders_orc | bucket | -1 |
| my_db | Orders2 | bucket | -1 |
| my_db | Orders2 | sink.parallelism | 7 |
| my_db2| OrdersSum | bucket | 1 |
+---------------+--------------------------------+--------------------------------+------------------+
7 rows in set
*/3.7.2.2 Catalog Options Table
您可以通过目录选项表查询目录的选项信息。未显示的选项将是默认值。您可以参考配置。
SELECT * FROM sys.catalog_options;
/*
+-----------+---------------------------+
| key | value |
+-----------+---------------------------+
| warehouse | hdfs:///path/to/warehouse |
+-----------+---------------------------+
1 rows in set
*/3.8 Data Types
数据类型描述了表生态系统中值的逻辑类型。它可以用来声明操作的输入和/或输出类型
| 数据类型 | 描述 |
|---|---|
| BOOLEAN | 布尔数据类型,具有(可能)三值逻辑:TRUE、FALSE 和 UNKNOWN。 |
| CHAR | 固定长度字符字符串的数据类型。可以使用 CHAR(n) 声明,其中 n 是代码点的数量,范围为 1 到 2,147,483,647。如果不指定长度,则 n 等于 1。 |
| VARCHAR / STRING | 可变长度字符字符串的数据类型。使用 VARCHAR(n) 声明,n 是最大代码点数,范围同上。STRING 是 VARCHAR(2147483647) 的同义词。 |
| BINARY | 固定长度二进制字符串(=字节序列)的数据类型。使用 BINARY(n) 声明,n 是字节数,范围同上。如果不指定长度,则 n 等于 1。 |
| VARBINARY / BYTES | 可变长度二进制字符串(=字节序列)的数据类型。使用 VARBINARY(n) 声明,n 是最大字节数,范围同上。BYTES 是 VARBINARY(2147483647) 的同义词。 |
| DECIMAL | 具有固定精度和比例的十进制数字的数据类型。使用 DECIMAL(p, s) 声明,p 是数字中的位数(精度),s 是小数点右边的位数(比例)。p 范围为 1 到 38,s 范围为 0 到 p,默认 p 为 10,s 为 0。 |
| TINYINT | 1 字节带符号整数,值从 -128 到 127。 |
| SMALLINT | 2 字节带符号整数,值从 -32,768 到 32,767。 |
| INT | 4 字节带符号整数,值从 -2,147,483,648 到 2,147,483,647。 |
| BIGINT | 8 字节带符号整数,值从 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807。 |
| FLOAT | 4 字节单精度浮点数。与 SQL 标准相比,此类型不接受参数。 |
| DOUBLE | 8 字节双精度浮点数。 |
| DATE | 包含年月日的日期,值范围从 0000-01-01 到 9999-12-31。 |
| TIME | 不带时区的时间,包含小时:分钟:秒.分数,最高到纳秒精度。使用 TIME(p) 声明,p 是分数秒位数(精度),范围为 0 到 9,默认 p 等于 0。 |
| TIMESTAMP | 不带时区的时间戳,包含年月日 小时:分钟:秒.分数,最高到纳秒精度。使用 TIMESTAMP(p) 声明,p 是分数秒位数(精度),范围为 0 到 9,默认 p 等于 6。 |
| TIMESTAMP WITH TIME ZONE | 带有时区的时间戳,包含年月日 小时:分钟:秒.分数 时区,最高到纳秒精度。该类型允许根据会话时区解释 UTC 时间戳。 |
| ARRAY | 同一子类型元素的数组。与 SQL 标准相比,数组的最大基数固定为 2,147,483,647。任何有效类型都可以作为子类型。 |
| MAP<kt, vt> | 关联数组,将键(包括 NULL)映射到值(包括 NULL)。不允许重复键;每个键最多映射到一个值。 |
| MULTISET | 多重集(=包)。与集合不同,它允许每个元素的多个实例。每个唯一值(包括 NULL)被映射到某个多重性。 |
| ROW<n0 t0, n1 t1, ...> | 字段序列的数据类型。字段由字段名、字段类型和可选描述组成。表行的最具体类型是行类型。在这种情况下,行中的每一列对应于行类型中具有相同序号位置的字段。还可以提供字段描述以简化复杂结构的处理。 |
3.9 Spec
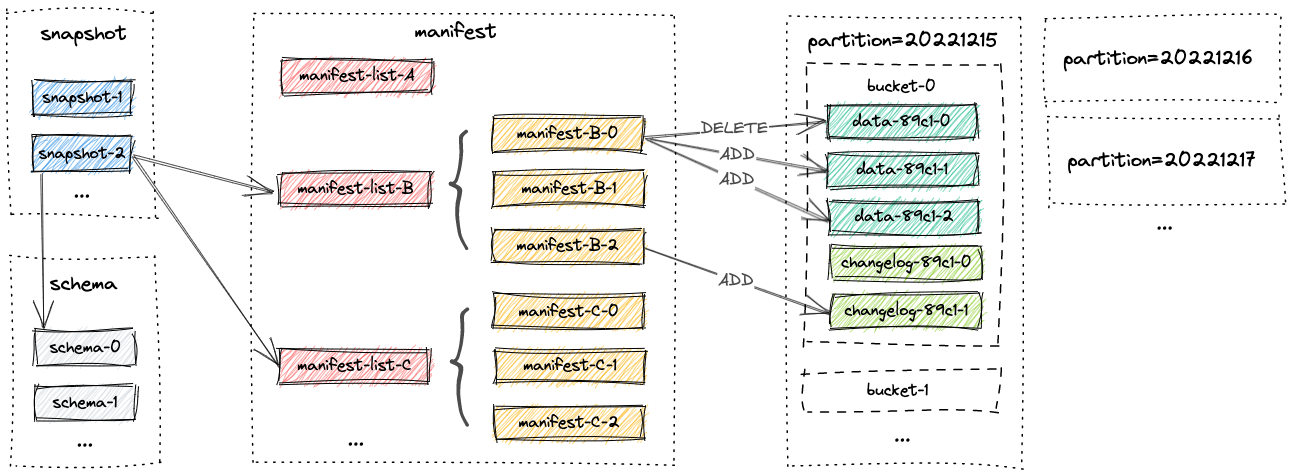
Paimon的底层文件结构和设计
Terms:
- Schema: fields, primary keys definition, partition keys definition and options.
- Snapshot: 在某个特定时间点提交的所有数据的入口。
- Manifest list: 包括多个清单文件
- Manifest: 包括多个数据文件或变更日志文件。
- Data File: 数据文件包含增量记录。
- Changelog File: 包含由变更日志生成器产生的记录。
- Global Index: 桶或分区的索引
- Data File Index: 数据文件的索引
使用 Paimon 运行 Flink SQL:
CREATE CATALOG my_catalog WITH (
'type' = 'paimon',
'warehouse' = '/your/path'
);
USE CATALOG my_catalog;
CREATE TABLE my_table (
k INT PRIMARY KEY NOT ENFORCED,
f0 INT,
f1 STRING
);
INSERT INTO my_table VALUES (1, 11, '111');查看磁盘:
warehouse
└── default.db
└── my_table
├── bucket-0
│ └── data-59f60cb9-44af-48cc-b5ad-59e85c663c8f-0.orc
├── index
│ └── index-5625e6d9-dd44-403b-a738-2b6ea92e20f1-0
├── manifest
│ ├── index-manifest-5d670043-da25-4265-9a26-e31affc98039-0
│ ├── manifest-6758823b-2010-4d06-aef0-3b1b597723d6-0
│ ├── manifest-list-9f856d52-5b33-4c10-8933-a0eddfaa25bf-0
│ └── manifest-list-9f856d52-5b33-4c10-8933-a0eddfaa25bf-1
├── schema
│ └── schema-0
└── snapshot
├── EARLIEST
├── LATEST
└── snapshot-13.9.1 Schema
Schema的版本从0开始,目前保留所有版本的方案。可能会有依赖于旧版本方案的旧文件,因此其删除应谨慎进行。
模式文件是JSON,它包括:
1.fields: 数据字段列表,数据字段包含id、name、type,字段ID用于支持模式演变。
2.partitionKeys: 字段名称列表,表分区定义,不能修改
3.primaryKeys: 字段名称列表,表的主键定义,不能修改
4.options:map<string, string>,无序,表格的选项,包括许多功能和优化
Example:
{
"version" : 3,
"id" : 0,
"fields" : [ {
"id" : 0,
"name" : "order_id",
"type" : "BIGINT NOT NULL"
}, {
"id" : 1,
"name" : "order_name",
"type" : "STRING"
}, {
"id" : 2,
"name" : "order_user_id",
"type" : "BIGINT"
}, {
"id" : 3,
"name" : "order_shop_id",
"type" : "BIGINT"
} ],
"highestFieldId" : 3,
"partitionKeys" : [ ],
"primaryKeys" : [ "order_id" ],
"options" : {
"bucket" : "5"
},
"comment" : "",
"timeMillis" : 1720496663041
}兼容性
对于旧版本:
版本1:如果没有bucket键,应该将bucket -> 1放入选项中。
版本1和2:如果没有file.format键,应该将file.format -> orc放入选项中。
DataField:
DataField 表示表中的一列。
1.id: int, 列ID, 自动递增, 用于模式演变。
2.name:字符串,列名。
3.type:数据类型,它与SQL类型字符串非常相似。
4.description:字符串
更新模式:
更新模式应生成一个新的schema文件。
warehouse
└── default.db
└── my_table
├── schema
├── schema-0
├── schema-1
└── schema-2snapshot中有一个关于模式的引用。数值最高的模式文件通常是最新模式文件。
旧schema文件不能直接删除,因为可能存在引用旧schema文件的旧数据文件。在读取表时,需要依赖它们进行schema演变读取。
3.9.2 Snapshot
每次提交都会生成一个快照文件,快照文件的版本从1开始,并且必须是连续的。 EARLIEST 和 LATEST 是快照列表开始和结束的提示文件,它们可能不准确。 当提示文件不准确时,读取器会扫描所有快照文件以确定开始和结束
warehouse
└── default.db
└── my_table
├── snapshot
├── EARLIEST
├── LATEST
├── snapshot-1
├── snapshot-2
└── snapshot-3写入提交将抢占下一个快照ID,一旦快照文件成功写入,此提交将 可见。
快照文件是JSON,它包括:
1.version: 快照文件版本,当前为3。
2.id: 快照ID,与文件名相同。
3.schemaId: 此提交对应的schema版本
4.baseManifestList: 一个记录所有从先前快照中更改的清单
5.deltaManifestList: 一个记录此快照中所有新更改的清单
6.changelogManifestList:一个记录在此快照中生成的所有变更日志的清单,如果没有生成变更日志则为null
7.indexManifest:记录该表所有索引文件的清单,如果没有表索引文件则为空
8.commitUser:通常由UUID生成,用于流式写入的恢复,一个流式写入作业对应一个用户
9.commitIdentifier:与流式写入对应的transaction ID,每个transaction 可能会因不同的commitKinds而产生多个提交
10.commitKind: 此快照中的更改类型,包括 append, compact, overwrite and analyze
11.timeMillis:提交时间毫秒
12.logOffsets:提交日志偏移量
13.totalRecordCount: 此快照中发生的所有更改的记录数
14.deltaRecordCount:此快照中所有新变化记录的数量
15.changelogRecordCount: 记录在此快照中生成的所有变更记录的数量。
16.watermark:输入记录的水印,来自Flink水印机制,如果没有水印则为Long.MIN_VALUE。
17.statistics:此表统计信息的文件名
3.9.3 Manifest
├── manifest
└── manifest-list-51c16f7b-421c-4bc0-80a0-17677f343358-13.9.3.1 Manifest List
Manifest List 包含多个 manifest 文件的元数据。其名称包含 UUID,它是一个 avro 文件,其模式为:
1._FILE_NAME: STRING, manifest file name._FILE_NAME: 字符串,清单文件名。
2._FILE_SIZE: BIGINT, manifest file size._FILE_SIZE: BIGINT,清单文件大小。
3._NUM_ADDED_FILES: BIGINT, number added files in manifest._NUM_ADDED_FILES: BIGINT,清单中添加的文件数量。
4._NUM_DELETED_FILES: BIGINT, number deleted files in manifest._NUM_DELETED_FILES: BIGINT, manifest 中删除的文件数量。
5._PARTITION_STATS: SimpleStats, partition stats, the minimum and maximum values of partition fields in this manifest are beneficial for skipping certain manifest files during queries, it is a SimpleStats._PARTITION_STATS: SimpleStats, 分区统计,此清单中分区字段的最低和最高值对于在查询期间跳过某些清单文件是有益的,它是一个SimpleStats。
6._SCHEMA_ID: BIGINT, schema id when writing this manifest file._SCHEMA_ID: BIGINT, 写此清单文件时的模式ID。
3.9.3.2 Manifest
Manifest 包含多个数据文件或变更日志文件或表索引文件的元数据。其名称包含 UUID,它是一个 avro 文件。
文件更改保存在Manifest中,文件可以添加或删除。Manifest应按有序方式排列,同一文件可能被多次添加或删除。应读取最后一个版本。这种设计可以使提交更轻,以支持由压缩生成的文件删除。
3.9.3.3 Data Manifest
Data Manifest 包括多个数据文件或变更日志文件的元数据。
├── manifest
└── manifest-6758823b-2010-4d06-aef0-3b1b597723d6-0The schema is:
1._KIND: TINYINT, ADD or DELETE, _KIND: TINYINT, 添加或删除,
2._PARTITION: BYTES, partition spec, a BinaryRow._PARTITION: BYTES, 分区规范,一个二进制行。
3._BUCKET: INT, bucket of this file._BUCKET: INT, 该文件的桶。
4._TOTAL_BUCKETS: INT, total buckets when write this file, it is used for verification after bucket changes._TOTAL_BUCKETS: INT, 写入此文件时的总桶数,用于桶变更后的验证。
5._FILE: data file meta._FILE: 数据文件元信息。
The data file meta is:
1._FILE_NAME: STRING, file name._FILE_NAME: 字符串,文件名。
2._FILE_SIZE: BIGINT, file size._FILE_SIZE: BIGINT, 文件大小。
3._ROW_COUNT: BIGINT, total number of rows (including add & delete) in this file._ROW_COUNT: BIGINT,此文件中行数(包括添加和删除)的总数。
4._MIN_KEY: STRING, the minimum key of this file._MIN_KEY: 字符串,此文件的最小键。
5._MAX_KEY: STRING, the maximum key of this file._MAX_KEY: 字符串,此文件的最大键。
6._KEY_STATS: SimpleStats, the statistics of the key._KEY_STATS: SimpleStats,关键统计。
7._VALUE_STATS: SimpleStats, the statistics of the value._VALUE_STATS: SimpleStats,值的统计。
8._MIN_SEQUENCE_NUMBER: BIGINT, the minimum sequence number._MIN_SEQUENCE_NUMBER: BIGINT,最小序列号。
9._MAX_SEQUENCE_NUMBER: BIGINT, the maximum sequence number._MAX_SEQUENCE_NUMBER: BIGINT,最大序列号。
10._SCHEMA_ID: BIGINT, schema id when write this file._SCHEMA_ID: BIGINT, 写入此文件时的模式ID。
11._LEVEL: INT, level of this file, in LSM._LEVEL: INT, 此文件在LSM中的级别。
12._EXTRA_FILES: ARRAY, extra files for this file, for example, data file index file._EXTRA_FILES: ARRAY, 该文件的额外文件,例如数据文件索引文件。
13._CREATION_TIME: TIMESTAMP_MILLIS, creation time of this file._CREATION_TIME: TIMESTAMP_MILLIS, 此文件的创建时间。
14._DELETE_ROW_COUNT: BIGINT, rowCount = addRowCount + deleteRowCount.
15._EMBEDDED_FILE_INDEX: BYTES, if data file index is too small, store the index in manifest._EMBEDDED_FILE_INDEX: 字节,如果数据文件索引过小,则在清单中存储索引。
16._FILE_SOURCE: TINYINT, indicate whether this file is generated as an APPEND or COMPACT file._FILE_SOURCE: TINYINT,表示此文件是作为追加文件还是紧凑文件生成的。
17._VALUE_STATS_COLS: ARRAY, statistical column in metadata._VALUE_STATS_COLS: ARRAY, 元数据中的统计列。
18._EXTERNAL_PATH: external path of this file, null if it is in warehouse._EXTERNAL_PATH: 此文件的外部路径,如果文件在仓库中则为空。
3.9.3.4 Index Manifest
Index Manifest包括多个表索引文件的元数据。
├── manifest
└── index-manifest-5d670043-da25-4265-9a26-e31affc98039-0The schema is:模式是:
1._KIND: TINYINT, ADD or DELETE,_KIND: TINYINT, 添加或删除,
2._PARTITION: BYTES, partition spec, a BinaryRow._PARTITION: BYTES, 分区规范,一个二进制行。
3._BUCKET: INT, bucket of this file._BUCKET: INT, 该文件的桶。
4._INDEX_TYPE: STRING, "HASH" or "DELETION_VECTORS"._INDEX_TYPE: 字符串,"HASH" 或 "DELETION_VECTORS"。
5._FILE_NAME: STRING, file name._FILE_NAME: 字符串,文件名。
6._FILE_SIZE: BIGINT, file size._FILE_SIZE: BIGINT, 文件大小。
7._ROW_COUNT: BIGINT, total number of rows._ROW_COUNT: BIGINT,总行数。
8._DELETIONS_VECTORS_RANGES: Metadata only used by "DELETION_VECTORS", is an array of deletion vector meta, the schema of each deletion vector meta is:
a.f0: the data file name corresponding to this deletion vector.f0:与该删除向量相对应的数据文件名。
b.f1: the starting offset of this deletion vector in the index file.f1:此删除向量在索引文件中的起始偏移量。
c.f2: the length of this deletion vector in the index file.f2:索引文件中此删除向量的长度。
d._CARDINALITY: the number of deleted rows._CARDINALITY: 删除的行数。
3.9.4 DataFile
3.9.4.1 Partition
通过Flink SQL考虑分区表:
CREATE TABLE part_t (
f0 INT,
f1 STRING,
dt STRING
) PARTITIONED BY (dt);
INSERT INTO part_t VALUES (1, '11', '20240514');文件系统目录将是:
part_t
├── dt=20240514
│ └── bucket-0
│ └── data-ca1c3c38-dc8d-4533-949b-82e195b41bd4-0.orc
├── manifest
│ ├── manifest-08995fe5-c2ac-4f54-9a5f-d3af1fcde41d-0
│ ├── manifest-list-51c16f7b-421c-4bc0-80a0-17677f343358-0
│ └── manifest-list-51c16f7b-421c-4bc0-80a0-17677f343358-1
├── schema
│ └── schema-0
└── snapshot
├── EARLIEST
├── LATEST
└── snapshot-1Pamion采用了与Apache Hive相同的分区概念来分离数据。分区文件将被放置在单独的分区目录中。
3.9.4.2 Bucket
所有Paimon表的存储都依赖于桶,数据文件存储在桶目录中。Paimon中各种表类型与桶之间的关系
主键表:
1.bucket = -1:默认模式,动态桶模式通过索引文件记录键对应的桶。索引记录主键哈希值与桶之间的对应关系。
2.bucket = 10:数据根据桶键的哈希值(默认为主键)分布到相应的桶中。
Append Table:
- bucket = -1:默认模式,忽略桶的概念,尽管所有数据都写入bucket-0,但读取和写入的并行性不受限制。
- bucket = 10: 您还需要定义 bucket-key,数据将根据 bucket-key 的哈希值分布到相应的桶中。
3.9.4.3 Data File
数据文件的名称是 data-\({uuid}-\){id}.${format}。对于追加表,文件存储了表的数据,但不添加任何新列。但对于主键表,每行数据存储了额外的系统列
3.9.4.4 Table with Primary key Data File
1.主键列,KEY 前缀到键列,这是为了避免与表中的列发生冲突。这是可选的, Paimon 版本 1.0 及以上将检索 value_columns 中的主键字段。
2._VALUE_KIND: TINYINT,行被删除或添加。类似于RocksDB,每行数据都可以被删除或添加,这将用于更新主键表
3._SEQUENCE_NUMBER: BIGINT,这个数字用于在更新时进行比较,确定哪个数据先到,哪个数据后到。
4.Value columns。表中声明的所有列。
例如,表格的数据文件:
CREATE TABLE T (
a INT PRIMARY KEY NOT ENFORCED,
b INT,
c INT
);其文件有6列:_KEY_a、_VALUE_KIND、_SEQUENCE_NUMBER、a、b、c。
.当 data-file.thin-mode 启用时,其文件有 5 列:_VALUE_KIND、_SEQUENCE_NUMBER、a、b、c。
3.9.4.5 Table w/o Primary key Data File
Value columns: 表中声明的所有列。
例如,表格的数据文件:
CREATE TABLE T (
a INT,
b INT,
c INT
);其文件有 3 列:a、b、c。
3.9.4.6 Changelog File
更改日志文件和数据文件完全相同,它只对主键表生效。类似于数据库中的二进制日志,记录表中的数据变化。
3.9.5 Table index
表索引文件位于index目录中。
3.9.5.1 Dynamic Bucket Index
动态桶索引用于存储主键哈希值与桶之间的对应关系。
其结构非常简单,仅将哈希值存储在文件中:
HASH_VALUE | HASH_VALUE | HASH_VALUE | HASH_VALUE | ...
HASH_VALUE 是主键的哈希值。4 个字节,BIT_ENDIAN。
3.9.5.2 Deletion Vectors
删除文件用于存储每个数据文件中已删除记录的位置。每个桶都有一个用于主键表的删除文件。

删除文件是一个二进制文件,格式如下:
- 首先,以字节为单位记录版本。当前版本为1。
- .然后,按顺序记录<序列化bin的大小,序列化bin,序列化bin的校验和>。
- 大小和校验和是 BIT_ENDIAN 整数。
对于每个序列化的箱子: - 首先,通过一个int(BIT_ENDIAN)记录一个常量魔法数。当前魔法数为1581511376。
- 然后,记录序列化的bitmap。它是一个RoaringBitmap(org.roaringbitmap.RoaringBitmap)。
3.9.6 File index
定义 file-index.${index_type}.columns,Paimon 将为每个文件创建相应的索引文件。如果索引文件太小,它将直接存储在 manifest 中,或者在数据文件的目录中。每个数据文件对应一个索引文件,该索引文件具有独立的文件定义,可以包含具有多个列的不同类型的索引。
3.9.6.1 Index File
文件索引文件格式。将所有列和偏移量放在头部。
_____________________________________ _____________________
| magic |version|head length |
|-------------------------------------|
| column number |
|-------------------------------------|
| column 1 | index number |
|-------------------------------------|
| index name 1 |start pos |length |
|-------------------------------------|
| index name 2 |start pos |length |
|-------------------------------------|
| index name 3 |start pos |length |
|-------------------------------------| HEAD
| column 2 | index number |
|-------------------------------------|
| index name 1 |start pos |length |
|-------------------------------------|
| index name 2 |start pos |length |
|-------------------------------------|
| index name 3 |start pos |length |
|-------------------------------------|
| ... |
|-------------------------------------|
| ... |
|-------------------------------------|
| redundant length |redundant bytes |
|-------------------------------------| ---------------------
| BODY |
| BODY |
| BODY | BODY
| BODY |
|_____________________________________| _____________________
*
magic: 8 bytes long, value is 1493475289347502L, BIT_ENDIAN
version: 4 bytes int, BIT_ENDIAN
head length: 4 bytes int, BIT_ENDIAN
column number: 4 bytes int, BIT_ENDIAN
column x name: 2 bytes short BIT_ENDIAN and Java modified-utf-8
index number: 4 bytes int (how many column items below), BIT_ENDIAN
index name x: 2 bytes short BIT_ENDIAN and Java modified-utf-8
start pos: 4 bytes int, BIT_ENDIAN
length: 4 bytes int, BIT_ENDIAN
redundant length: 4 bytes int (for compatibility with later versions, in this version, content is zero)
redundant bytes: var bytes (for compatibility with later version, in this version, is empty)
BODY: column index bytes + column index bytes + column index bytes + .......3.9.6.2 Index: BloomFilter
定义 'file-index.bloom-filter.columns'。
布隆过滤器索引的内容很简单:
- numHashFunctions 4字节整型,BIT_ENDIAN
- bloom filter bytes布隆过滤器字节
.这个类使用(64位)长哈希。仅存储数字哈希函数(一个整数)和 bit set字节。使用xx哈希对哈希字节类型(如varchar、binary等)进行哈希,对数值类型使用指定数字哈希。
3.9.6.3 Index: Bitmap
定义 'file-index.bitmap.columns'。
位图文件索引格式 (V1):
Bitmap file index format (V1)
+-------------------------------------------------+-----------------
| version (1 byte) |
+-------------------------------------------------+
| row count (4 bytes int) |
+-------------------------------------------------+
| non-null value bitmap number (4 bytes int) |
+-------------------------------------------------+
| has null value (1 byte) |
+-------------------------------------------------+
| null value offset (4 bytes if has null value) | HEAD
+-------------------------------------------------+
| value 1 | offset 1 |
+-------------------------------------------------+
| value 2 | offset 2 |
+-------------------------------------------------+
| value 3 | offset 3 |
+-------------------------------------------------+
| ... |
+-------------------------------------------------+-----------------
| serialized bitmap 1 |
+-------------------------------------------------+
| serialized bitmap 2 |
+-------------------------------------------------+ BODY
| serialized bitmap 3 |
+-------------------------------------------------+
| ... |
+-------------------------------------------------+-----------------
*
value x: var bytes for any data type (as bitmap identifier)
offset: 4 bytes int (when it is negative, it represents that there is only one value
and its position is the inverse of the negative value)
Integer are all BIT_ENDIAN.3.9.6.4 Index: Bit-Slice Index Bitmap
BSI 文件索引是一个数值范围索引,用于加速范围查询,可以与位图索引一起使用。
定义 'file-index.bsi.columns'。
BSI 文件索引格式 (V1):
BSI file index format (V1)
+-------------------------------------------------+
| version (1 byte) |
+-------------------------------------------------+
| row count (4 bytes int) |
+-------------------------------------------------+
| has positive value (1 byte) |
+-------------------------------------------------+
| positive BSI serialized (if has positive value)|
+-------------------------------------------------+
| has negative value (1 byte) |
+-------------------------------------------------+
| negative BSI serialized (if has negative value)|
+-------------------------------------------------+3.9.6.5 BSI 序列化格式 (V1):
BSI serialized format (V1)
+-------------------------------------------------+
| version (1 byte) |
+-------------------------------------------------+
| min value (8 bytes long) |
+-------------------------------------------------+
| max value (8 bytes long) |
+-------------------------------------------------+
| serialized existence bitmap |
+-------------------------------------------------+
| bit slice bitmap count (4 bytes int) |
+-------------------------------------------------+
| serialized bit 0 bitmap |
+-------------------------------------------------+
| serialized bit 1 bitmap |
+-------------------------------------------------+
| serialized bit 2 bitmap |
+-------------------------------------------------+
| ... |
+-------------------------------------------------+BSI only support the following data type:
| 数据类型 | 是否支持 |
|---|---|
| TinyIntType | true |
| SmallIntType | true |
| IntType | true |
| BigIntType | true |
| DateType | true |
| LocalZonedTimestampType | true |
| TimestampType | true |
| DecimalType(precision, scale) | true |
| FloatType | false |
| DoubleType | false |
| StringType | false |
| VarBinaryType | false |
| BinaryType | false |
| RowType | false |
| MapType | false |
| ArrayType | false |
| BooleanType | false |