2 应用层
2.1 网络应用原理
网络应用:能够运行在不同的端系统和通过网络彼此通信的程序。
- 注:在端系统上运行,而不是在网络核心上运行。
网络应用是计算机网络存在的理由。
2.1.1 应用体系结构(application architecture)
客户-服务器体系结构(client-server architecture)
- server:响应client的请求,总是开启,固定、周知的IP地址。
- client:向server发送请求,clients之间不直接通信。
- 举例:Web,FTP,Telnet,Email。
P2P体系结构(peer-to-peer architecture)
- peer:所有的对等方不总是开启,间断连接,直接通信,对专用服务器依赖很小或没有依赖。
- 自扩展性(self-scalability):对等方的加入会为系统增加服务能力,即系统服务能力一般不会耗尽。
- 缺点:P2P的高度非集中式结构,面临安全性、性能、可靠性等挑战。
- 举例:BitTorrent。
2.1.2 进程通信
进程(process):运行在端系统中的程序。
在两个不同端系统上的进程,通过跨越计算机网络交换报文(message)而相互通信。
2.1.2.1 client进程和server进程
在一对进程之间的通信会话场景中,发起通信 (即在会话开始时发起与其他进程的联系)的进程是client进程 ,在会话开始时等待联系 的进程是server进程。
无论是client-server架构还是P2P架构,在进程间进行通信时,都会分为client进程和server进程(客户端和服务器端进程)。
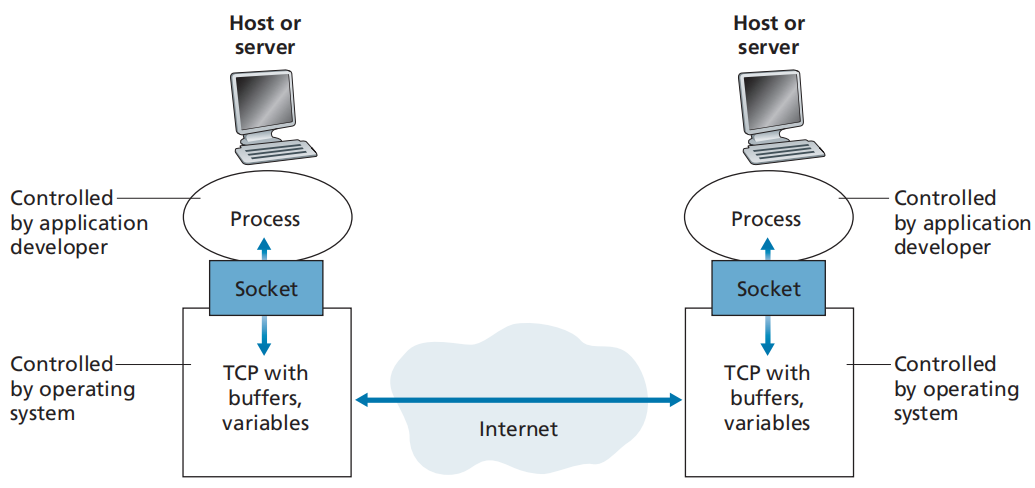
2.1.2.2 进程与计算机网络之间的接口
套接字(socket) /应用编程接口(Application Programming Interface,API):同一台主机内,应用层与运输层之间的接口。
发送方进程通过套接字将报文传递到运输层,该报文在运输层中被分为报文段经过网络运输到接收方的运输层,接收方的运输层去掉运输层首部,并将报文分发到接收方进程的套接字,报文经过接收方进程的套接字被接收方进程接收。
应用程序开发者可以控制套接字的应用层端,但在运输层端,只能做以下控制:
- 选择运输层协议
- 设定几个运输层参数(最大缓存、最大报文段长度等)
2.1.2.3 进程寻址
报文中包含以下两个字段:
- 目的IP地址(IP address):32bits,确定目的主机的地址。
- 目的端口号(port number):确定目的主机上运行的哪个目的进程(为不同的网络应用分配不同的端口号)。
2.1.3 应用程序可以使用的运输服务
可靠数据传输(reliable data transfer)
- 确保发送方发出的数据正确并完全地交付给接收方。
- 容忍丢失的应用(loss-tolerant application):可以不提供可靠数据传输,如交谈式音频/视频等多媒体应用。
吞吐量(throughput)
- 可用吞吐量(available throughput):发送进程能够向接收进程交付比特的速率。
- 确保吞吐量(guaranteed throughput):确保可用吞吐量至少为r bps,则应用程序可以申请r bps的确保吞吐量。
- 带宽敏感的应用(bandwidth-sensitive application):具有吞吐量要求的应用程序,如多媒体应用。
- 弹性应用(elastic application):能够根据当前可用的带宽使用可用吞吐量,如Email,FTP,Web。
定时(timing)
- 交互式实时应用程序(interactive real-time application):可能会要求发送方注入套接字的每个比特到达接收方的套接字不迟于某一时间,如因特网电话、虚拟环境、视频会议、多方游戏。
安全(security)
- 发送前加密,接收后解密
2.1.4 因特网提供的运输服务
TCP(详见运输层)
- 面向连接的服务
- 可靠的数据传输服务
- 流量控制
- 拥塞控制
UDP(详见运输层)
- 无连接
- 不可靠
因特网运输协议不能提供吞吐量保证和定时服务
2.1.5 应用层协议
应用层协议:定义了运行在不同端系统上的应用程序进程如何相互传递报文,包括:
- 交换的报文类型(请求报文、响应报文)
- 各种报文类型的语法(报文结构、字段)
- 各字段的语义(字段中信息的含义)
- 确定一个进程何时以及如何发送报文,对报文进行响应的规则
2.2 Web和HTTP
Web :基于client-server架构 的因特网应用,通过交换HTTP报文进行会话,包括以下组成部分:
- Web浏览器(Web browser,是client端)
- Web服务器(Web server,是server端)
- 文档格式标准(HTML)
- 应用层协议(HTTP)
- 可能包括Web缓存(Web cache/proxy server)
HTTP :Web使用的应用层协议 ,是无状态(stateless) 协议,但可以使用cookie ,分为持续连接(persistent connection) 和非持续连接(non-persistent connection) ,基于TCP运输层协议,故可以提供:
- 面向连接的服务
- 可靠的数据传输服务
- 流量控制
- 拥塞控制
2.2.1 HTTP概述
超文本传输协议(HyperText Transfer Protocol,HTTP):通过客户程序和服务器程序实现,定义了HTTP报文结构以及客户和服务器进程报文交换(用户请求Web页面和服务器传输Web页面)的方式。
Web页面 (Web page)是由对象(object,如HTML、CSS、JS文件,JPEG图形等)组成的。多数Web页面含有一个HTML基本文件以及几个引用对象。HTML基本文件通过URL引用其他对象。
URL:主机名+路径名
- 例如:http://www.someSchool.edu/someDepartment/picture.gif
- 主机名:www.someSchool.edu
- 路径名:/someDepartment/picture.gif
**Web浏览器(Web browser)**实现了HTTP的客户端,如Internet Explorer、Chrome。
**Web服务器(Web server)**实现了HTTP的服务器端,用于存储Web对象,这些对象用URL寻址。
HTTP工作流程
- HTTP client向HTTP server发起一个TCP连接
- 一旦连接建立,client向它的套接字发送HTTP请求报文,并从它的套接字接收HTTP响应报文
- 类似地,server从它的套接字接收HTTP请求报文,并向它的套接字发送HTTP响应报文
- 传输结束后,TCP连接关闭
分层体系结构的优点:HTTP不必担心数据的丢失,也不必关注TCP从网络的数据丢失和乱序故障中恢复的细节。
无状态协议(stateless protocol):HTTP服务器向客户发送被请求的文件(Web页面),而不存储该客户的任何信息。
client-server架构:Web服务器总是开启,且具有固定的IP地址。
2.2.2 非持续连接和持续连接
HTTP默认使用带流水线的持续连接,但HTTP客户和服务器也能配置成使用非持续连接。
2.2.2.1 非持续连接(non-persistent connection)
对于每一个对象,client在发送请求报文前要先发起TCP连接,server传输数据后要关闭TCP连接。
因此,传输一个页面可能产生并关闭多个TCP连接。
每次传输需要花费两倍的往返时间(Round-Trip Time,RTT)
- RTT:一个短分组从客户到服务器然后再返回客户所花费的时间(包括传播时延、排队时延、分组处理时延)。
- 三次握手(申请TCP连接的过程,其中第三次包含请求报文)+ 一次传输(响应报文)
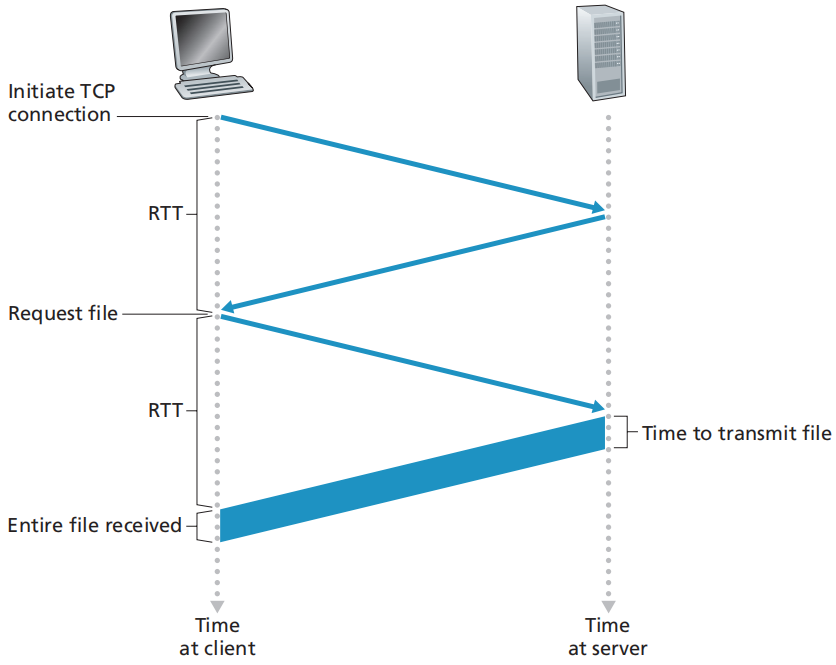
缺点:必须为每一个请求的对象建立和维护一个全新的连接,每一个对象经受两倍RTT的交付时延。
2.2.2.2 持续连接(persistent connection)
在一次TCP连接期间,client发送多个请求报文(可以以流水线方式发送,即不必等待未决请求的响应),server传输多个对象。
通常,若一条连接经过一定时间间隔(可配置的超时间隔)仍未被使用,HTTP服务器关闭TCP连接。
2.2.3 HTTP报文格式
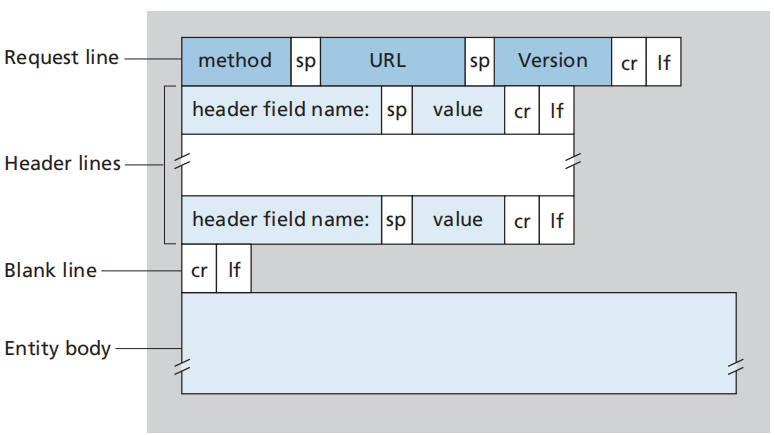
HTTP请求报文
请求行(request line):方法字段(GET, POST, HEAD, PUT, DELETE)、URL字段、HTTP版本字段
首部行(header line):Host(提供给Web cache)、Connection(声名传输结束是否关闭连接)、User-agent(声名用户浏览器类型)、Accept-language(用户想要的语言版本)......
空行(blank line):分隔
实体体(entity body):GET方法中实体体为空,POST方法中实体体包含用户在表单中的输入值(也可以用GET在URL中包含该输入值------扩展URL)
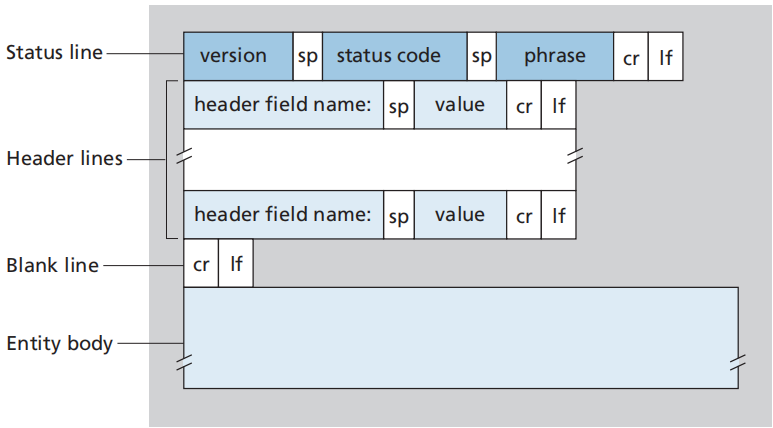
HTTP响应报文
状态行(status line):HTTP版本字段、状态码和响应状态信息(HTTP 状态码 | 菜鸟教程)
首部行(header line):Connection、Date(报文发送时间)、Server(服务器类型)、Last-Modified(对象创建或上一次修改时间)、Content-Length(对象字节数)、Content-Type(对象类型)
空行(blank line)
实体体(entity body):包含了请求的对象本身
2.2.4 cookie
HTTP是无状态协议,服务器无法存储用户信息。
cookie:为了使服务器能够识别用户,cookie允许站点对用户进行跟踪,在无状态的HTTP之上建立了一个用户会话层。
构成
- HTTP请求报文中包含cookie首部行
- HTTP响应报文中包含cookie首部行
- 用户端系统保留一个cookie文件,由浏览器管理
- Web服务器后端数据库存储用户信息
cookie工作流程

2.2.5 Web缓存
Web缓存器(Web cache) 也叫代理服务器(proxy server),代表初始Web服务器满足HTTP请求的网络实体。
Web缓存器有自己的存储空间,用来保存最近请求过的对象的副本。
工作流程
- 浏览器创建对Web缓存的TCP连接,并向Web缓存器发送HTTP请求(此时Web缓存器作为服务器)
- Web缓存器检查本地是否存储了请求对象的副本,若有则向客户发送包含该对象的HTTP响应
- 若无则创建对初始服务器的TCP连接,请求该对象,初始服务器收到请求后发送响应(此时Web缓存器作为客户)
- Web缓存器接收到对象后,在本地存储该对象的副本,并向客户发送包含该副本的HTTP响应
好处
- 减少对客户请求的响应时间(考虑客户与初始服务器之间的瓶颈带宽低于客户与Web缓存器之间的瓶颈带宽)
- 减少一个机构接入到因特网中的通信量(机构不必急于增加带宽,降低费用;减少因特网上Web流量,改善所有应用性能)
内容分发网络(Content Distribute Network,CDN):CDN公司在因特网上安装了许多地理上分散的缓存器,使大量流量实现了本地化。
条件GET(conditional GET):缓存器中对象副本可能是陈旧的
- Web cache向初始服务器发送条件GET请求(包含字段If-modified-since)
- 若请求报文的If-modified-since等于server中对象上一次修改的时间,则server发送不包含该对象的响应报文(304 Not Modified)
- 若请求报文的If-modified-since不等于server中对象上一次修改的时间,则server发送包含该对象的响应报文
2.2.6 HTTP/2
目标:减小感知时延
手段:经单一TCP连接使请求与响应多路复用,提供请求优先次序和服务器推,提供HTTP首部字段的有效压缩
2.2.7 HTTP/3
使用QUIC协议(基于UDP)
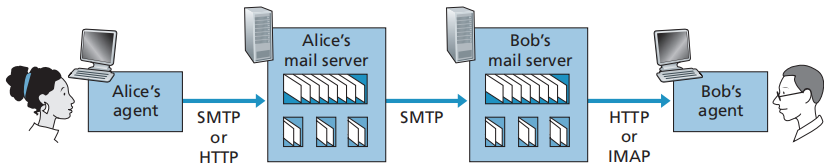
2.3 电子邮件
组成
- 用户代理(user agent)
- 邮件服务器(mail server):接收方在服务器中有一个邮箱(mailbox)
- 简单邮件传输协议(Simple Mail Transfer Protocol,SMTP):基于TCP
邮件传输协议SMTP
- 客户端:发送方邮件服务器
- 服务器端:接收方邮件服务器
- 一般不使用中间邮件服务器(邮件不在中间的某个邮件服务器中存留)
- 也可以使用SMTP将邮件从用户代理上传到邮件服务器
邮件访问协议
- POP3(Post Office Protocol 3,邮局协议版本3):从邮件服务器下载邮件到本地用户代理,并将邮件服务器上的邮件删除。
- IMAP(Internet Mail Access Protocol,因特网邮件访问协议):通过用户代理访问服务器上的邮件,多种操作同步,反馈同步,也可以下载到本地。
- HTTP:通过基于Web的电子邮件或手机上的客户端(Gmail)管理邮件,包括上传和拉取。
协议使用
- 发送方用户代理-发送方邮件服务器(push操作):SMTP/HTTP
- 发送方邮件服务器-接收方邮件服务器:SMTP
- 接收方邮件服务器-接收方用户代理(pull操作,接收方用户主动拉取邮件):POP3/IMAP/HTTP
2.4 DNS
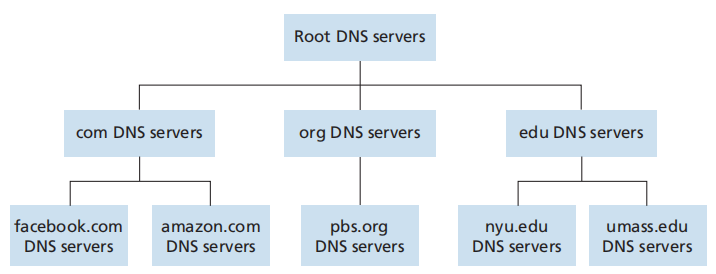
域名系统(Domain Name System,DNS):提供主机名到IP地址转换的目录服务。
组成
-
分层的DNS服务器实现的分布式数据库(Distributed, Hierarchical Database)
- 根DNS服务器(root)
- 顶级域DNS服务器(Top-Level Domain,TLD)
- 权威DNS服务器(authoritative)
- *本地DNS服务器(local):不属于DNS服务器的层次结构,是DNS缓存(接收到DNS响应后,将响应中包含的映射缓存在本地存储器中),可以减少时延和因特网中DNS报文的数量
-
主机查询该数据库的应用层协议DNS:基于UDP,为了减少时延
分布式的原因
集中式的缺点:
单点故障(single point of failure):该DNS的崩溃将导致整个网络的瘫痪
通信容量(traffic volume):单个DNS服务器将处理所有DNS查询
时延:客户距离集中式数据库较远将导致严重的时延
维护(maintenance):存储的DNS记录数量庞大,更新困难,可扩展性差
提供服务
- 主机名-IP地址
- 主机别名-规范主机名、IP地址:有着复杂主机名的主机可以拥有一个或多个主机别名(host aliasing),规范主机名(canonical hostname)即主机名
- 邮件服务器别名-规范主机名、IP地址
- 负载分配:一个IP地址集合与同一个规范主机名对应,对该主机名的DNS请求,服务器在响应中循环这些IP地址,从而循环分配了负载
工作流程
- 应用程序调用DNS客户端(在客户主机上),并指明需要被转换的主机名(包含在URL中)
- DNS客户端发送DNS查询报文(使用UDP经端口53传输)
- DNS服务器使用迭代查询(iterative query)和/或递归查询(recursive query),最终向DNS客户端发送包含目的IP地址的DNS响应报文
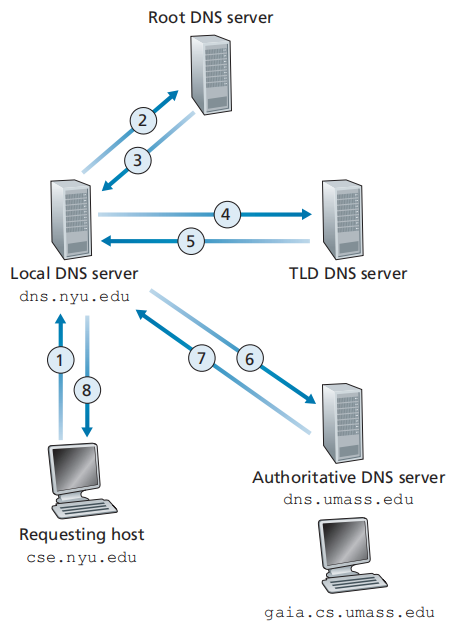

(左图从请求主机到本地DNS服务器的查询是递归的,其余查询是迭代的;右图是递归查询的例子)
DNS记录和报文
DNS报文
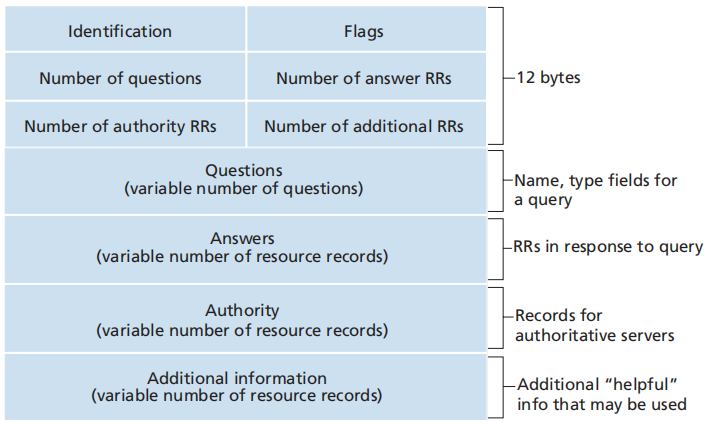
资源记录(Resource Record,RR):提供了主机名到IP地址的映射,是一个四元组(Name,Value,Type,TTL)
-
TTL:记录的生存时间
-
Type:记录类型
-
Type = A,Name为主机名,Value为该主机名对应的IP地址
-
Type = NS,Name为域,Value为知道如何获取该域中主机IP地址的权威DNS服务器的主机名
-
Type = CNAME,Name为主机别名,Value为该主机别名对应的规范主机名
-
Type = MX,Name为邮件服务器别名,Value为该邮件服务器别名对应的规范主机名
-
2.5 P2P文件分发
在P2P文件分发中,每个对等方能够向任何其他对等方重新分发它已经收到的文件的任何部分,从而在分发过程中协助服务器。
分发时间(distribution time):所有对等方得到分发的文件副本所需要的时间。
2.5.1 自扩展性的分析
考虑以下情况:
一个服务器,N个对等方,服务器要向所有对等方分发一个长度为F的文件,服务器上传时间为u_s,第i个对等方下载时间为d_i,上传时间为u_i,完成文件分发的时间为D。
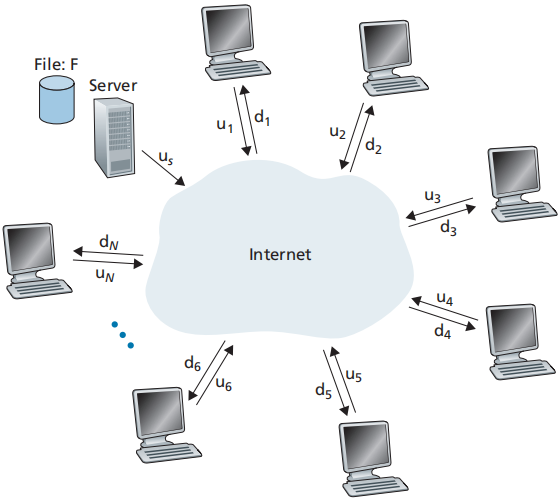
client-server架构:随着对等放数量的增加,分发时间呈线性增长且无界
D_{cs}\\geq max{ \\frac{NF}{u_s}, \\frac{F}{d_{min}} }
P2P架构:随着对等放数量的增加,分发时间增速趋缓且有界
D_{P2P}\\geq max{ \\frac F {u_s},\\frac F {d_{min}},\\frac {NF}{u_s+\\sum_{i=1}\^{N} u_i} }
2.5.2 BitTorrent
BitTorrent:是一种用于文件分发的P2P协议
洪流(torrent):参与一个特定文件分发的所有对等方的集合
块(chunk):一个洪流中的对等方彼此下载等长度的文件块
工作流程
-
每个洪流有一个基础设施节点追踪器(tracker),新对等方向追踪器注册自己,并周期性地通知追踪器自己仍在洪流中
-
新对等方首次加入洪流时没有块,追踪器从洪流中随机选择对等方的子集,并将它们的IP地址发给新对等方
-
新对等方试图与已知对等方建立并行的TCP连接,这些与它成功建立TCP连接的对等方称为它的邻近对等方
-
新对等方周期性地询问每个邻近对等方拥有的块列表,并基于**最稀缺优先(rarest first)**技术向它当前没有的块发出请求
- 最稀缺优先:优先向邻居中副本数量最少的块发出请求
- 好处:大致均衡每个块在洪流中的副本数目
-
若有其他对等方向它发起请求,它将优先选择当前能够以最高速率向它提供数据的邻居
- 持续测量接收到每个邻居发送的比特的速率,选出以最高速率流入的几个邻居,它们被称为疏通(unchoked),优先响应疏通中的对等方的请求
- 每过一段时间,还要随机选择另一个邻居(不在疏通中)的请求
- 好处:能够发现更好的伴侣,使对等方以趋向于找到彼此的协调的速率上载,这种机制被称为"一报还一报"(tit-for-tat)
-
一旦某个对等方获得了整个文件,它可能离开洪流,或是留在洪流中继续为其他对等方上载块;任何对等方可能在未获取完整文件时就离开洪流,并可能在以后重新加入洪流